
 Technology peripherals
AI
Implementing Tsinghua UltraChat multi-round conversations using multiple ChatGPT APIs
Technology peripherals
AI
Implementing Tsinghua UltraChat multi-round conversations using multiple ChatGPT APIs
Implementing Tsinghua UltraChat multi-round conversations using multiple ChatGPT APIs

Since the release of ChatGPT, the popularity of conversation models has only increased during this period. While we admire the amazing performance of these models, we should also guess the huge computing power and massive data support behind them.
As far as data is concerned, high-quality data is crucial, and for this reason OpenAI has put a lot of effort into data and annotation work. Multiple studies have shown that ChatGPT is a more reliable data annotator than humans. If the open source community can obtain large amounts of dialogue data from powerful language models such as ChatGPT, it can train dialogue models with better performance. This is proven by the Alpaca family of models – Alpaca, Vicuna, Koala. For example, Vicuna replicated ChatGPT’s nine-step success by fine-tuning instructions for the LLaMA model using user sharing data collected from ShareGPT. Increasing evidence shows that data is the primary productivity for training powerful language models.
ShareGPT is a ChatGPT data sharing website where users upload ChatGPT answers they find interesting. The data on ShareGPT is open but trivial and needs to be collected and organized by researchers themselves. If there is a high-quality, wide-ranging data set, the open source community will get twice the result with half the effort in developing conversation models.
Based on this, a recent project called UltraChat systematically constructed an ultra-high-quality conversation data set. The project authors tried to use two independent ChatGPT Turbo APIs to conduct conversations to generate multiple rounds of conversation data.
- ## Project address: https://github.com/thunlp/UltraChat
- Dataset address: http://39.101.77.220/
- Dataset interaction address: https://atlas. nomic.ai/map/0ce65783-c3a9-40b5-895d-384933f50081/a7b46301-022f-45d8-bbf4-98107eabdbac
Specifically, the project aims to We are building an open source, large-scale, multi-round dialogue data based on Turbo APIs to facilitate researchers to develop powerful language models with universal dialogue capabilities. In addition, taking into account privacy protection and other factors, the project will not directly use data on the Internet as prompts. In order to ensure the quality of the generated data, the researchers used two independent ChatGPT Turbo APIs in the generation process, in which one model plays the role of the user to generate questions or instructions, and the other model generates feedback.

If you directly use ChatGPT to generate it freely based on some seed conversations and questions, it is prone to problems such as single topics and repeated content, making it difficult to guarantee data. diversity itself. To this end, UltraChat has systematically classified and designed the topics and task types covered by the conversation data, and also conducted detailed prompt engineering for the user model and reply model, which consists of three parts:
- Questions about the World: This part of the conversation comes from broad inquiries about concepts, entities, and objects in the real world. The topics covered cover technology, art, finance and other fields.
- Writing and Creation: This part of the dialogue data focuses on instructing the AI to create a complete text material from scratch, and based on this, follow-up questions or further guidance To improve your writing, content types include articles, blogs, poems, stories, plays, emails, and more.
- Assisted rewriting (Writing and Creation) of existing data: The dialogue data is generated based on existing data. Instructions include but are not limited to rewriting, continuation, translation, induction, reasoning, etc., and the topics covered are also very diverse.
These three parts of data cover most users’ requirements for AI models. At the same time, these three types of data will also face different challenges and require different construction methods.
For example, the main challenge of the first part of the data is how to cover common knowledge in human society as widely as possible in a total of hundreds of thousands of conversations. To this end, the researchers used automatically generated topics and sources from Wikidata Two aspects of entities are filtered and constructed.
The challenges in the second and third parts mainly come from how to simulate user instructions and make the generation of user models as diverse as possible in subsequent conversations without deviating from the ultimate goal of the conversation ( Generate materials or rewrite materials as required), for which the researchers have fully designed and experimented with the input prompts of the user model. After the construction was completed, the authors also post-processed the data to weaken the hallucination problem.
Currently, the project has released the first two parts of the data, with a data volume of 1.24 million, which should be the largest related data set in the open source community. The content contains rich and colorful conversations in the real world, and the final part of the data will be released in the future.
World problem data comes from 30 representative and diverse meta-themes, as shown in the figure below:

- Based on the above meta-themes, this project generated 1100 sub-themes for data construction;
- For each sub-theme , generate up to 10 specific questions;
- Then use the Turbo API to generate new related questions for each of the 10 questions;
- For each question, the two models are iteratively used to generate 3 to 7 dialogue rounds as described above.
Additionally, this project collected the 10,000 most commonly used named entities from Wikidata; used the ChatGPT API to generate 5 meta-questions for each entity; for each meta Questions, 10 more specific questions and 20 related but general questions were generated; 200,000 specific questions, 250,000 general questions and 50,000 meta-questions were sampled, and 3~7 dialogue rounds were generated for each question.
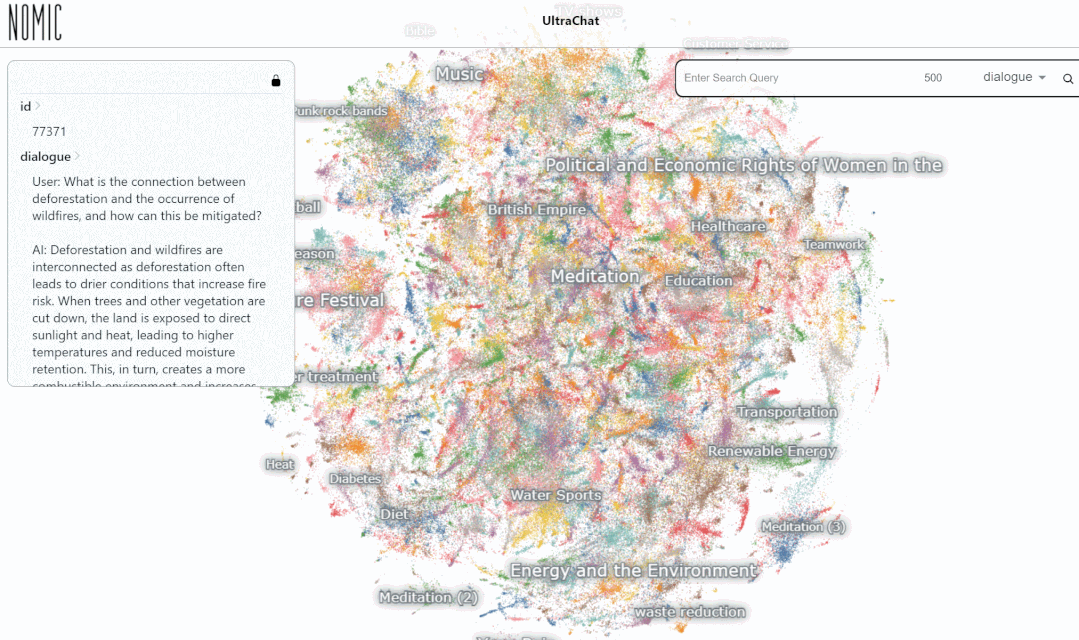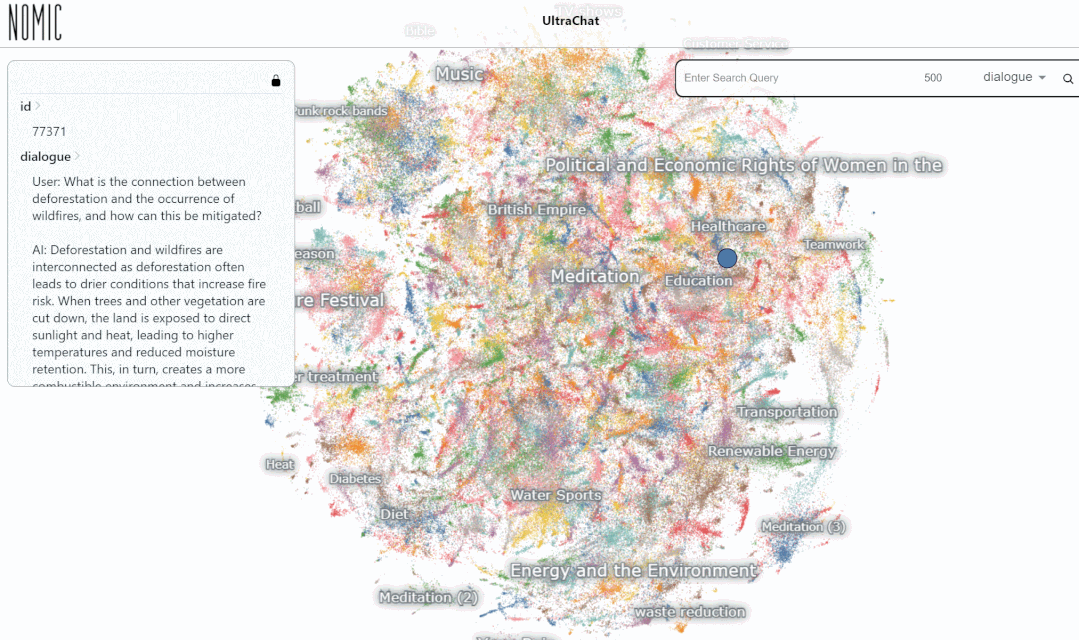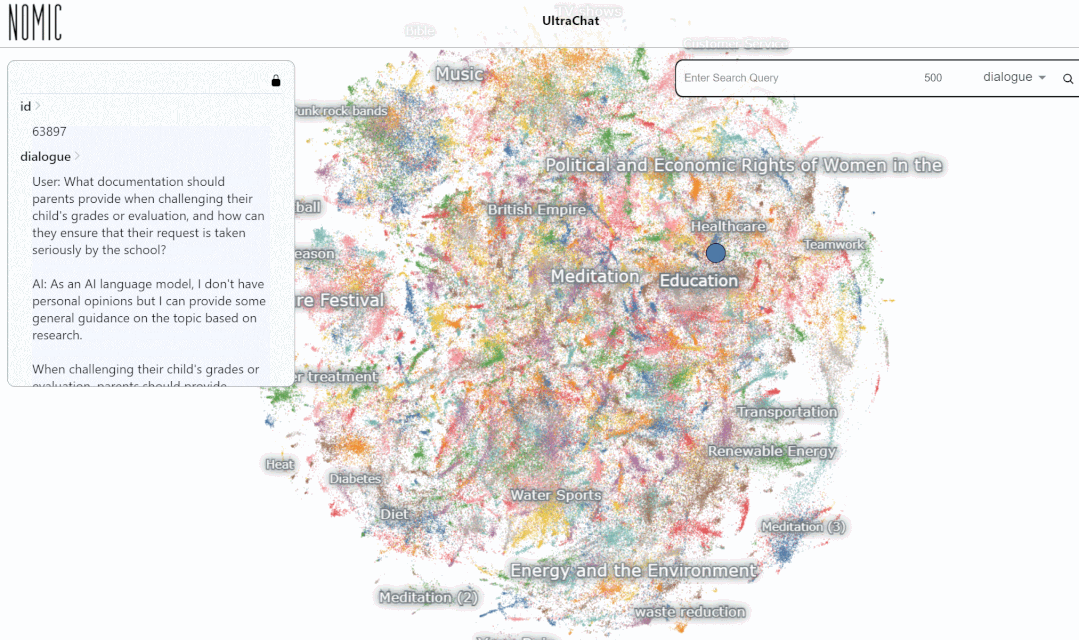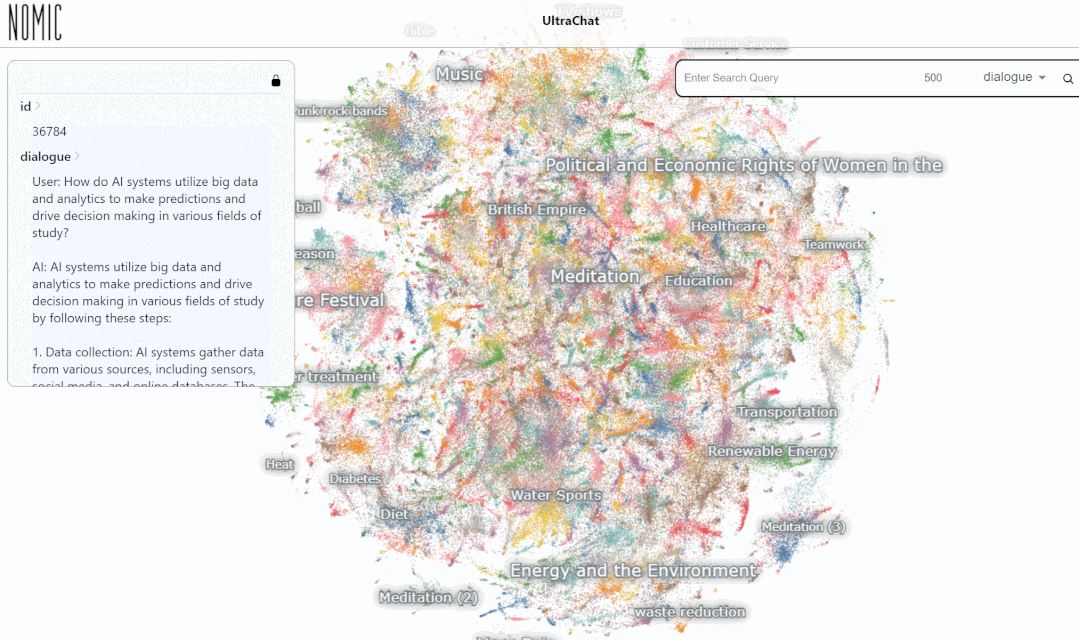
Next let’s look at a specific example:

We tested the data on the UltraChat platform Search results. For example, if you enter "music", the system will automatically search for 10,000 sets of music-related ChatGPT conversation data, and each set is a multi-round conversation

The search results for entering the keyword "mathematics (math)", there are 3346 groups of multi-round conversations:

Currently, UltraChat covers There are already many information fields, including medical, education, sports, environmental protection and other topics. At the same time, the author tried to use the open source LLaMa-7B model to perform supervised instruction fine-tuning on UltraChat, and found that after only 10,000 steps of training, there were very impressive effects. Some examples are as follows:

World Knowledge: List 10 good Chinese and American universities respectively

Imagination question: What are the possible consequences after space travel becomes possible?

Syllogism: Is a whale a fish?

##Hypothetical question: Prove that Jackie Chan is better than Bruce Lee
Overall, UltraChat is a high-quality, wide-ranging ChatGPT conversation data set that can be combined with other data sets to significantly improve the quality of open source conversation models. At present, UltraChat only releases the English version, but it will also release the Chinese version of the data in the future. Interested readers are welcome to explore it.
The above is the detailed content of Implementing Tsinghua UltraChat multi-round conversations using multiple ChatGPT APIs. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
 How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
During Laravel development, it is often necessary to add virtual columns to the model to handle complex data logic. However, adding virtual columns directly into the model can lead to complexity of database migration and maintenance. After I encountered this problem in my project, I successfully solved this problem by using the stancl/virtualcolumn library. This library not only simplifies the management of virtual columns, but also improves the maintainability and efficiency of the code.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
