
 Technology peripherals
AI
Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!
Technology peripherals
AI
Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!
Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!

Since Midjourney released v5, significant improvements have been made in the realism of characters and finger details in generated images, and improvements have also been made in the accuracy of prompt understanding, aesthetic diversity and language understanding. progress.
In contrast, although Stable Diffusion is free and open source, you have to write a long list of prompts every time, and generating high-quality images depends on drawing cards multiple times.

Recently, Stability AI officially announced that Stable Diffusion XL, which is under development, has begun testing for the public and is currently available for free trial on the Clipdrop platform.

Trial link: https://clipdrop.co/stable-diffusion
Emad Mostaque, founder and CEO of Stability AI, said that the model is still in the training stage and will be open sourced after the parameters are stable; SD-XL will perform better in image details such as "handshake", Almost completely controllable.
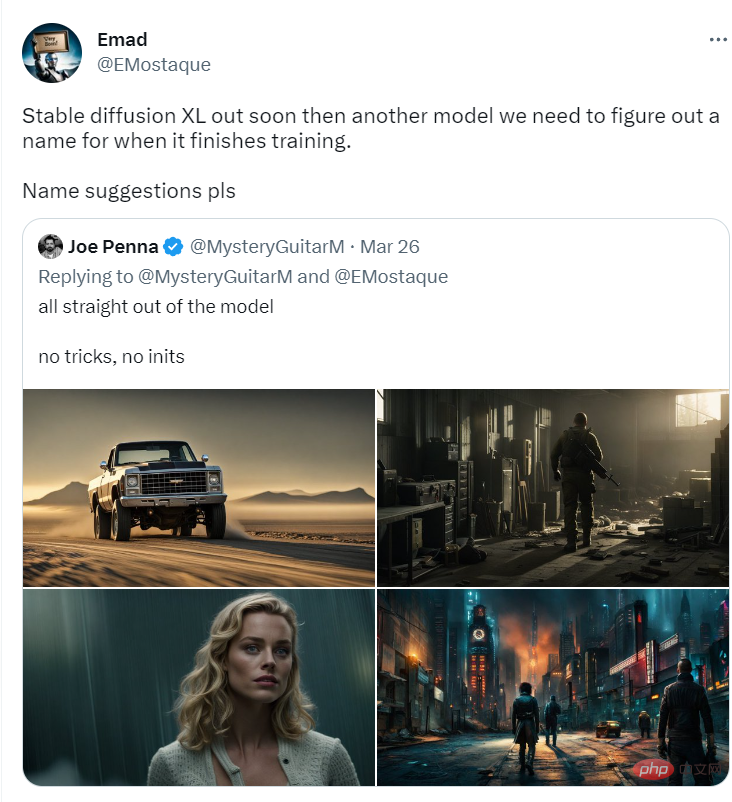
Stable Diffusion XL is not the name of the final release, and it is not v3 because of the architecture of SD-XL and the SD-v2 series The model architecture is very similar.

##Minimalistic home gym with rubber flooring, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mats, high-tech equipment, high detail, organized and efficient.
Simple home gym, rubber floor, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mat, High-tech equipment, high details, organization and efficiency
# The following examples released by SD-XL officially released, we can see that the quality of the image is already very capable.






SD-XL: Open source version of Midjourney
Officials did not reveal much about the specific information of the Stable Diffusion XL model. At present, we only know that it is a model with a similar architecture to the v2 model, but with a larger scale and parameter count.
SD-v2.1 includes 900 million parameters, and SD-XL has about 2.3 billion parameters. Emad said that the official version may additionally release a smaller distilled version.
The improvements of SD-XL compared to previous versions are as follows:
- Use shorter descriptive prompts to generate high quality Image
- can generate an image that fits the prompt better
- The human body structure in the image is more reasonable
- Compared with v2.1 and v1.5 versions (to a lesser extent), the pictures generated by SD-XL are more in line with public aesthetics
- Negative prompt words (negative prompt) are acceptable Option
- The resulting portrait is more realistic
- The text in the image is clearer
It should be noted that SD-XL may not be compatible with previous versions of plug-ins.
Clear and readable text
In the v1 series and v2.1 version of the Stable Diffusion model, it is not possible to generate it in the image The ability to read text.
While the text information generated by SD-XL is not always accurate, it does provide a huge improvement.

##Photo of a woman sitting in a restaurant holding a menu that says “Menu”
A woman is sitting in a restaurant holding a menu with "Menu" written on it

Photo of a man holding a sign that says “Stable Diffusion”
Stable Diffusion" brand
a young female holding a sign that says "Stable Diffusion", highlights in hair, sitting outside restaurant, brown eyes, wearing a dress , side light
A young woman holding a sign that says "Stable Diffusion" with highlighted hair and brown eyes sits outside a restaurant , wearing a skirt, side lights
Better human anatomy
Stable Diffusion has always had many problems with generating human anatomy , having more legs and fewer arms is a very common problem. It is usually necessary to use the inpaint function to further correct the image details; or use ControlNet's Open Pose function to copy the posture of the human body from the reference image.
For example, when SD-v1.5 generates yoga images, distorted human bodies often appear.

##Photo of a woman in yoga outfit, triangle pose, beach in evening, rim lighting
Photo of a woman in yoga clothing, triangle pose, beach at night, edge lighting Although the images generated by SD-XL are not perfect, they have made significant progress in human posture. For example, with the same house theme, SD-XL This produces photos that are more symmetrical and have better visual effects. The SD-XL also offers significant improvements in portrait photos. ##photo shot of a woman Photo SD-XL can better understand the input prompt and generate more accurate Image. For example, taking duotone (two-color) as an example, SD-v1.5 will only generate black and white images, while SD-XL can generate dual-tone images with multiple colors. The ability to understand prompts has improved compared to the v1 model. duotone portrait of a woman Two-tone portrait #Because SD-XL belongs to the v2 series model, the text model size is larger and the prompt words can be understood better than the v1 model. For example, in the example below, the v1.5 model can never understand the two subjects (robots and humans) in the image, but SD-XL The model can generate normal images (although the robot is still not big enough). big robot friend sitting next to a human, ghost in the shell style, anime wallpaper Big robot friends sitting next to humans Ghost in the Shell style anime wallpaper a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background a young man, with dyed hair Very bright, brown eyes, wearing a white shirt and blue jeans, standing on the beach with a volcano in the background In terms of artistic style, SD-XL has not been significantly improved, and it is different from the previous version. For example, two models generate Edward Hopper-style images from different angles. New York city by Edward Hopper ##New York city by Edward Hopper In Leonid Afmov's style, SD-v1.5 is more accurate, SD-XL lacks unmistakable colorful board brushstrokes. ##New York city by Leonid Afremov In the style of William-Adolphe Bouguereau, both V1.5 and SDXL can generate some similar content, among which SD-XL is closer to the classic academic style created by Bouguereau Painting, and more facial detail.
Portrait of a Beauty Drawn by William-Adolphe Bouguereau Style Shift Issue For example, first generate a photo-style image.
A young man with brightly dyed hair and brown eyes wearing a white shirt and blue jeans is standing on the beach with a volcano in the background After adding a yellow scarf, the image style becomes cartoon style.
##a young man, highlights in hair, brown eyes, A young man with brightly dyed hair and brown eyes wearing a yellow scarf and wearing white shirt and blue jeans, standing on a beach with a volcano as the background #The problem may be caused by a preview issue. It is not known whether the issue can be resolved after the official release. . 
More aesthetic

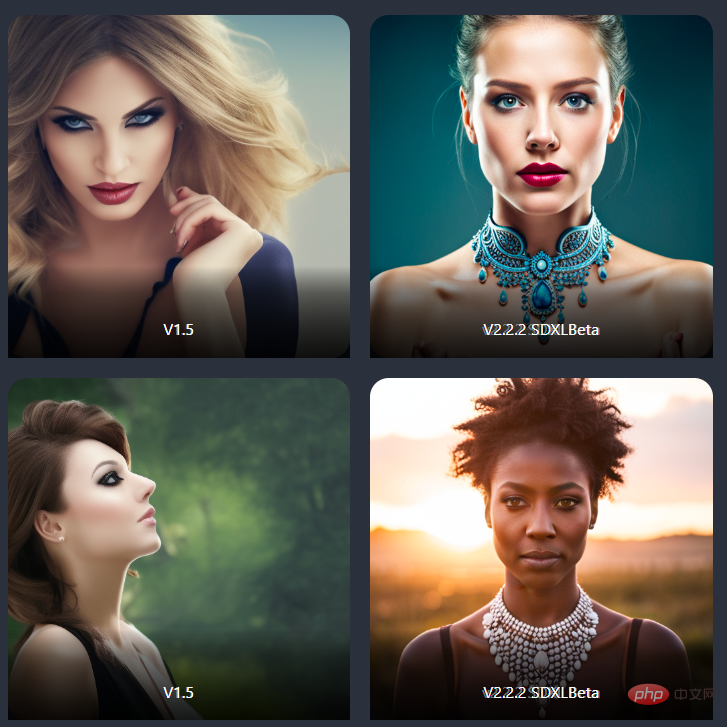
Image that better fits the prompt


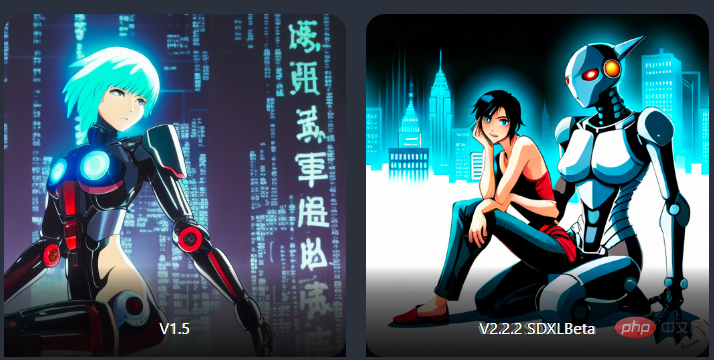

Artistic style


 ##Portrait of beautiful woman by William-Adolphe Bouguereau
##Portrait of beautiful woman by William-Adolphe BouguereauAfter adding some irrelevant keywords, the model The style may change suddenly.
 a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background wearing a yellow scarf,
wearing a yellow scarf,
The above is the detailed content of Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
The source code of 25 AI agents is now public, inspired by Stanford's 'Virtual Town' and 'Westworld'
Aug 11, 2023 pm 06:49 PM
Audiences familiar with "Westworld" know that this show is set in a huge high-tech adult theme park in the future world. The robots have similar behavioral capabilities to humans, and can remember what they see and hear, and repeat the core storyline. Every day, these robots will be reset and returned to their initial state. After the release of the Stanford paper "Generative Agents: Interactive Simulacra of Human Behavior", this scenario is no longer limited to movies and TV series. AI has successfully reproduced this scene in Smallville's "Virtual Town" 》Overview map paper address: https://arxiv.org/pdf/2304.03442v1.pdf
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
