

最近想将一些PDF文件转换为Word文档,第一时间想到W某S系列都有Pdf文档转Word文档的功能,结果还要会员???这里针对不想付费的情况所设计的一套方案。
这里主要用到的第三方模块是pdf2docx,用下面的pip命令安装即可:
pip install pdf2docx
pdf2docx是一个Python模块,可以用来将PDF文件转换成Word文档。它是基于Python的pdfminer和python-docx库开发的,可以在Windows、Linux和Mac系统上运行。
pdf2docx模块可以直接从PDF文件中提取文本和图片,并将其转换成可编辑的Word文档。它可以处理包含复杂布局和格式的PDF文件,并保留原始的字体、颜色、大小和格式等属性。
使用pdf2docx模块非常简单,只需要安装pdf2docx库并导入相应的函数即可。以下是一个简单的示例代码:
import pdf2docx # 将PDF文件转换成Word文档 pdf2docx.parse('example.pdf', 'example.docx')
在上述代码中,我们首先导入pdf2docx模块,然后使用parse函数将PDF文件example.pdf转换成Word文档example.docx。
pdf2docx模块还提供了一些其他的函数和选项,可以根据需要进行配置和使用。以下是一些常用的函数和选项:
parse:将PDF文件转换成Word文档parse_pages:将PDF文件中的一页转换成Word文档parse_images:将PDF文件中的图片提取出来parse_text:将PDF文件中的文本提取出来parse_layout:将PDF文件中的页面布局提取出来
pdf2docx模块还支持一些高级选项,如自定义字体、颜色、大小、格式等,可以根据需要进行配置和使用。
总结:pdf2docx是一个非常实用的Python模块,可以将PDF文件转换成可编辑的Word文档。它基于pdfminer和python-docx库开发,可以处理包含复杂布局和格式的PDF文件,并保留原始的字体、颜色、大小和格式等属性。使用pdf2docx模块非常简单,只需要安装pdf2docx库并导入相应的函数即可。
Python实现批量将PDF转Word文档j,用到pdf2docx和os模块。
1、PDF文档的后缀务必是“.pdf”,否则转换不成功
2、大部分的PDF文档都可用这个程序来转换,如果是图片生成的Pdf文档,则转换不成功,原因是要将图片里的文字转换成文档涉及到人工智能的知识,它已超出这个程序的能力范围。但也不用慌,遇到此情况,可以用QQ的文件助手来帮忙,此处不赘述。
下方代码只需要修改file_path 文件路径即可:
import os
from pdf2docx import Converter
def pdf_docx():
# 获取当前工作目录
file_path = r'C:\Users\test'
# 遍历所有文件
for file in os.listdir(file_path):
# 获取文件后缀
suff_name = os.path.splitext(file)[1]
# 过滤非pdf格式文件
if suff_name != '.pdf':
continue
# 获取文件名称
file_name = os.path.splitext(file)[0]
# pdf文件名称
pdf_name = file_path + '\\' + file
# 要转换的docx文件名称
docx_name = file_path + '\\' + file_name + '.docx'
# 加载pdf文档
cv = Converter(pdf_name)
cv.convert(docx_name)
cv.close()
if __name__ == '__main__':
pdf_docx()控制台实现打印转换的页码进程:
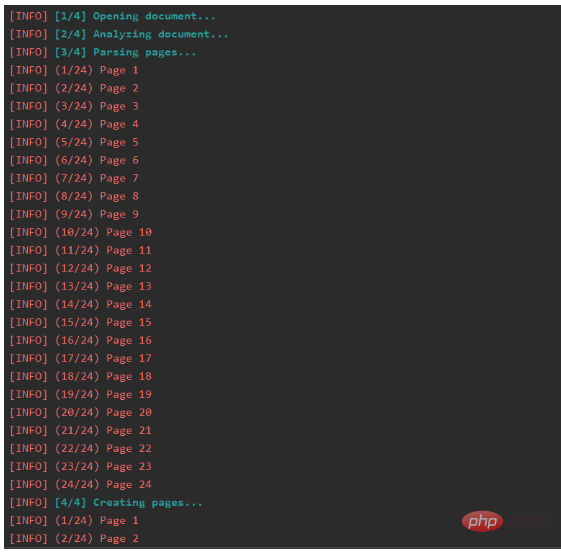
实现了PDF转Word:

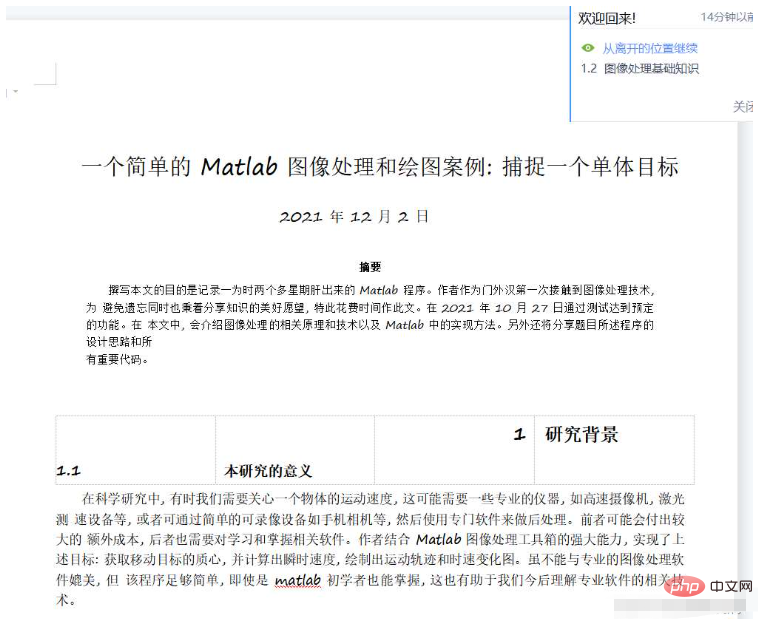
打开的效果:
The above is the detailed content of How to batch convert PDF files to Word documents using Python?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



