
 Technology peripherals
AI
'MiniGPT-4 proves its amazing image recognition capabilities and multiple functions: chatting with images, building websites with sketches, etc.'
Technology peripherals
AI
'MiniGPT-4 proves its amazing image recognition capabilities and multiple functions: chatting with images, building websites with sketches, etc.'
'MiniGPT-4 proves its amazing image recognition capabilities and multiple functions: chatting with images, building websites with sketches, etc.'

For humans, understanding the information of a picture is nothing more than a trivial matter. Humans can casually tell the meaning of a picture without thinking. Just like the picture below, the charger that the phone is plugged into is somewhat inappropriate. Humans can see the problem at a glance, but for AI, it is still very difficult.
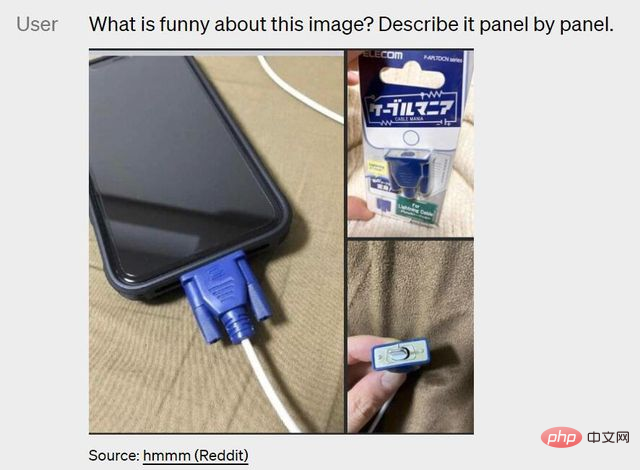
The emergence of GPT-4 has begun to make these problems simpler. It can quickly point out the problem in the picture: VGA cable charging iPhone .
In fact, the charm of GPT-4 is far less than this. What is even more exciting is to use hand-drawn sketches to directly generate websites, draw a scribbled diagram on the draft paper, take a photo, and then send it Give GPT-4 and let it write the website code according to the diagram. Whoosh, GPT-4 writes the web page code.
But unfortunately, this function of GPT-4 is not yet open to the public, and it is impossible to get started and experience it. However, some people can't wait any longer, and a team from King Abdullah University of Science and Technology (KAUST) has developed a similar product to GPT-4 - MiniGPT-4. Team researchers include Zhu Deyao, Chen Jun, Shen Xiaoqian, Li Xiang, and Mohamed H. Elhoseiny, all of whom are from the Vision-CAIR research group of KAUST.

- ##Paper address: https://github.com/Vision-CAIR/MiniGPT- 4/blob/main/MiniGPT_4.pdf
- Paper homepage: https://minigpt-4.github.io/
- Code address: https://github.com/Vision-CAIR/MiniGPT-4
MiniGPT-4 It’s easy to talk just by looking at the pictures
What is the effect of MiniGPT-4? Let's start with a few examples. In addition, in order to have a better experience with MiniGPT-4, it is recommended to use English input for testing.First, let’s examine MiniGPT-4’s ability to describe images. For the picture on the left, the answer given by MiniGPT-4 is roughly "The picture depicts a cactus growing on a frozen lake. There are huge ice crystals around the cactus, and there are snow-capped peaks in the distance..." If you then ask Could this scenario happen in the real world? The answer given by MiniGPT-4 is that this image is not common in the real world and the reason why.



With MiniGPT-4, writing advertising slogans for pictures has become very simple. Ask MiniGPT-4 to write advertising copy for the cup on the left. MiniGPT-4 accurately pointed out the sleepy cat pattern on the cup, which is very suitable for coffee lovers and cat lovers. It also pointed out the material of the cup, etc.:

MiniGPT-4 can also generate recipes based on a picture, turning you into a kitchen expert:

Explain the popular meme:

## Write a poem based on the picture:

In addition, it is worth mentioning that the MiniGPT-4 Demo is now open and can be played online. You can experience it yourself ( It is recommended to use English test):
##Demo address: https://0810e8582bcad31944.gradio.live/
Once the project was released, it attracted widespread attention from netizens. For example, let MiniGPT-4 explain the objects in the picture:
##Method Introduction
MiniGPT-4 consists of a pre-trained ViT and Q-Former visual encoder, a separate linear projection layer, and an advanced Vicuna large language model. MiniGPT-4 only requires training linear layers to align visual features with Vicuna.
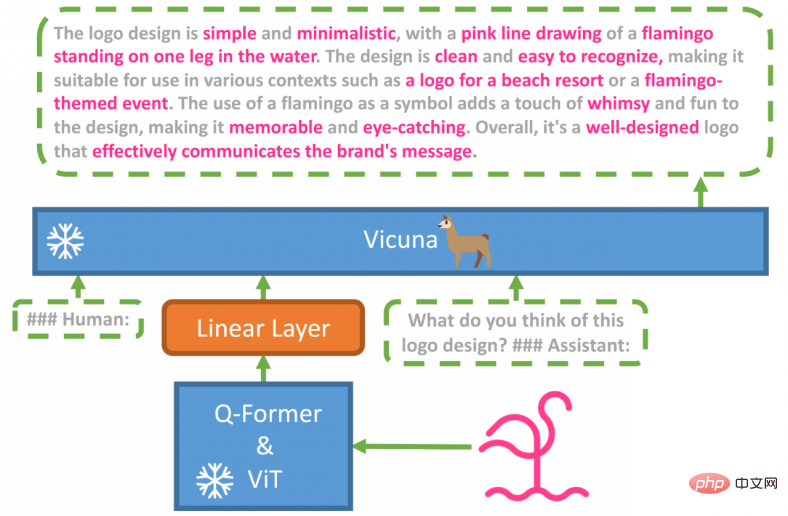 MiniGPT-4 was trained in two stages. The first traditional pre-training stage took 10 hours to train on 4 A100 GPUs using approximately 5 million aligned image-text pairs. After the first stage, Vicuna was able to understand images. But Vicuna's text-generating abilities were greatly affected.
MiniGPT-4 was trained in two stages. The first traditional pre-training stage took 10 hours to train on 4 A100 GPUs using approximately 5 million aligned image-text pairs. After the first stage, Vicuna was able to understand images. But Vicuna's text-generating abilities were greatly affected.
To solve this problem and improve usability, researchers proposed a novel way to create high-quality image-text pairs through the model itself and ChatGPT. Based on this, the study created a small but high-quality dataset (3500 pairs in total).
The second fine-tuning stage is trained on this dataset using conversation templates to significantly improve its generation reliability and overall usability. This stage is computationally efficient and only requires an A100GPU in about 7 minutes to complete.
Other related work:
- VisualGPT: https://github.com/Vision-CAIR/VisualGPT
- ChatCaptioner: https://github.com/Vision-CAIR/ChatCaptioner
In addition, open source code libraries including BLIP2 are also used in the project , Lavis and Vicuna.
The above is the detailed content of 'MiniGPT-4 proves its amazing image recognition capabilities and multiple functions: chatting with images, building websites with sketches, etc.'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to dynamically create an object through a string and call its methods in Python?
Apr 01, 2025 pm 11:18 PM
How to dynamically create an object through a string and call its methods in Python?
Apr 01, 2025 pm 11:18 PM
In Python, how to dynamically create an object through a string and call its methods? This is a common programming requirement, especially if it needs to be configured or run...
 How to use Go or Rust to call Python scripts to achieve true parallel execution?
Apr 01, 2025 pm 11:39 PM
How to use Go or Rust to call Python scripts to achieve true parallel execution?
Apr 01, 2025 pm 11:39 PM
How to use Go or Rust to call Python scripts to achieve true parallel execution? Recently I've been using Python...
 How to solve the problem of missing dynamic loading content when obtaining web page data?
Apr 01, 2025 pm 11:24 PM
How to solve the problem of missing dynamic loading content when obtaining web page data?
Apr 01, 2025 pm 11:24 PM
Problems and solutions encountered when using the requests library to crawl web page data. When using the requests library to obtain web page data, you sometimes encounter the...
 Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
About Pythonasyncio...
 How to recover Debian mail server
Apr 02, 2025 am 07:33 AM
How to recover Debian mail server
Apr 02, 2025 am 07:33 AM
Detailed Steps for Restoring Debian Mail Server This article will guide you on how to restore Debian Mail Server. Before you begin, it is important to remember the importance of data backup. Recovery Steps: Backup Data: Be sure to back up all important email data and configuration files before performing any recovery operations. This will ensure that you have a fallback version when problems occur during the recovery process. Check log files: Check mail server log files (such as /var/log/mail.log) for errors or exceptions. Log files often provide valuable clues about the cause of the problem. Stop service: Stop the mail service to prevent further data corruption. Use the following command: su
 How to operate Zookeeper performance tuning on Debian
Apr 02, 2025 am 07:42 AM
How to operate Zookeeper performance tuning on Debian
Apr 02, 2025 am 07:42 AM
This article describes how to optimize ZooKeeper performance on Debian systems. We will provide advice on hardware, operating system, ZooKeeper configuration and monitoring. 1. Optimize storage media upgrade at the system level: Replacing traditional mechanical hard drives with SSD solid-state drives will significantly improve I/O performance and reduce access latency. Disable swap partitioning: By adjusting kernel parameters, reduce dependence on swap partitions and avoid performance losses caused by frequent memory and disk swaps. Improve file descriptor upper limit: Increase the number of file descriptors allowed to be opened at the same time by the system to avoid resource limitations affecting the processing efficiency of ZooKeeper. 2. ZooKeeper configuration optimization zoo.cfg file configuration
 How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
How to do Oracle security settings on Debian
Apr 02, 2025 am 07:48 AM
To strengthen the security of Oracle database on the Debian system, it requires many aspects to start. The following steps provide a framework for secure configuration: 1. Oracle database installation and initial configuration system preparation: Ensure that the Debian system has been updated to the latest version, the network configuration is correct, and all required software packages are installed. It is recommended to refer to official documents or reliable third-party resources for installation. Users and Groups: Create a dedicated Oracle user group (such as oinstall, dba, backupdba) and set appropriate permissions for it. 2. Security restrictions set resource restrictions: Edit /etc/security/limits.d/30-oracle.conf
 In the ChatGPT era, how can the technical Q&A community respond to challenges?
Apr 01, 2025 pm 11:51 PM
In the ChatGPT era, how can the technical Q&A community respond to challenges?
Apr 01, 2025 pm 11:51 PM
The technical Q&A community in the ChatGPT era: SegmentFault’s response strategy StackOverflow...
