

Python built-in type dict source code analysis

In-depth understanding of Python's built-in types - dict
Note: This article is based on the notes recorded in the tutorial. Some of the content is the same as the tutorial, because a link needs to be filled in for reprinting, but there is no, so Fill in the original content, if there is any infringement, it will be deleted directly.
This section of "In-depth Understanding of Python's Built-in Types" will introduce you to various commonly used built-in types in Python from the source code perspective.
dict is one of the most commonly used built-in types in daily development, and the operation of the Python virtual machine also relies heavily on dict objects. Mastering the underlying knowledge of dict should be helpful, whether it is understanding the basic knowledge of data structures or improving development efficiency.
1 Execution efficiency
Whether it is Hashmap in Java or dict in Python, they are both very efficient data structures. Hashmap is also a basic test point in Java interviews: arrays, linked lists, and red-black tree hash tables, which are very time efficient. Similarly, dict in Python also has an average complexity of O(1) (O(n) in the worst case) for operations such as insertion, deletion, and search due to its underlying hash table structure. Here we compare list and dict to see how big the difference is between the search efficiency of the two: (The data comes from the original article, you can test it by yourself)
| Container scale | Scale growth coefficient | dict consumption time | dict time consumption growth coefficient | list consumption time | list time-consuming growth coefficient |
|---|---|---|---|---|---|
| 1000 | 1 | 0.000129s | 1 | 0.036s | 1 |
| 10000 | 10 | 0.000172s | 1.33 | 0.348s | 9.67 |
| 100000 | 100 | 0.000216s | 1.67 | 3.679s | 102.19 |
| 1000000 | 1000 | 0.000382s | 2.96 | 48.044s | 1335.56 |
Thinking: The original article here compares the data to be searched as the elements of the list and the key of the dict. I personally think that such a comparison is meaningless. Because list is essentially a hash table, where the key is 0 to n-1, and the value is the element we are looking for; and the dict here uses the element we are looking for as the key, and the value is True (the code in the original article is set like this of). If you really want to compare, you can compare the 0~n-1 of the query list with the corresponding key of the query dict. This is the control variable method, hh. Of course, the essential reason why I personally feel inappropriate here is that the place where list has storage significance is its value part, and the key and value of dict both have certain storage significance. I personally think there is no need to worry too much about the search efficiency of the two. , it is most important to understand the underlying principles of the two and choose to apply them in actual projects.
2 Internal structure
2.1 PyDictObject
Since associative containers are used in a wide range of scenarios, almost all modern programming languages provide some kind of associative container Containers, and pay special attention to key search efficiency. For example, map in the C standard library is an associative container, which is internally implemented based on red-black trees. In addition, there is also the Hashmap in Java just mentioned. The red-black tree is a balanced binary tree that can provide good operation efficiency. The time complexity of key operations such as insertion, deletion, and search is O(logn).
The operation of the Python virtual machine relies heavily on the dict object. The underlying concepts such as name space and object attribute space use dict objects to manage data. Therefore, Python has more stringent efficiency requirements for dict objects. Therefore, dict in Python uses a hash table with efficiency better than O(logn).
The dict object is represented by the structure PyDictObject inside Python. The source code is as follows:
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;Source code analysis:
ma_used: The number of key-value pairs currently saved by the object
- ##ma_version_tag: The current version number of the object, updated every time it is modified (version numbers are also quite common in business development)
- ma_keys: Points to a hash table structure mapped by key objects, type is PyDictKeysObject
- ma_values: Points to an array of all value objects in split mode ( If it is combined mode, the value will be stored in ma_keys, and ma_values is empty at this time)
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};- ##dk_refcnt: Reference counting, related to the implementation of mapping views, similar to object reference counting
- dk_size: Hash table size, must be an integer power of 2, so that modular operations can be optimized into bit operations (
- You can learn about it and combine it with actual business applications
)
dk_lookup: Hash lookup function pointer, you can select the optimal function according to the current state of dict - dk_usable: Key-value array available Number
- dk_nentries: The number of used key-value pairs in the array
- dk_indices: The starting address of the hash table, immediately after the hash table Then the key-value pair array dk_entries, the type of dk_entries is PyDictKeyEntry
- ##2.3 PyDictKeyEntry
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;Copy after login
Source code analysis: me_hash: The hash value of the key object to avoid repeated calculationtypedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;- me_key :Key object pointer
- me_value:Value object pointer
- 2.4 Illustrations and examples
The real core of the dict object lies in PyDictKeysObject, which contains two key arrays: one is the hash index array dk_indices, and the other is the key-value pair array dk_entries . The key-value pairs maintained by dict will be stored in the key-value pair array in first-come, first-served order; and the corresponding slot of the hash index array stores the position of the key-value pair in the array. 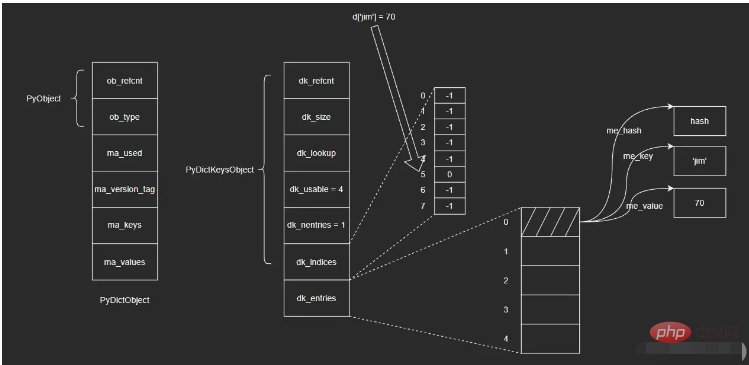
iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码)
这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。
3 容量策略
示例:
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。
为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义:
# define USABLE_FRACTION(n) (((n) << 1)/3)
此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。
4 内存优化
在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色:
entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
由于哈希表必须保持稀疏,最多只有2/3满(太满会导致哈希冲突频发,性能下降),这意味着至少要浪费1/3的内存空间,而一个键值对条目PyDictKeyEntry的大小达到了24字节。试想一个规模为65536的哈希表,将浪费:
65536 * 1/3 * 24 = 524288 B 大小的空间(512KB)
为了尽量节省内存,Python将键值对数组压缩到原来的2/3(原来只能2/3满,现在可以全满),只负责存储,索引由另一个数组负责。由于索引数组indices只需要保存键值对数组的下标,即保存整数,而整数占用的空间很小(例如int为4字节),因此可以节省大量内存。
此外,索引数组还可以根据哈希表的规模,选择不同大小的整数类型。对于规模不超过256的哈希表,选择8位整数即可;对于规模不超过65536的哈希表,16位整数足以;其他以此类推。
对比一下两种方式在内存上的开销:
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
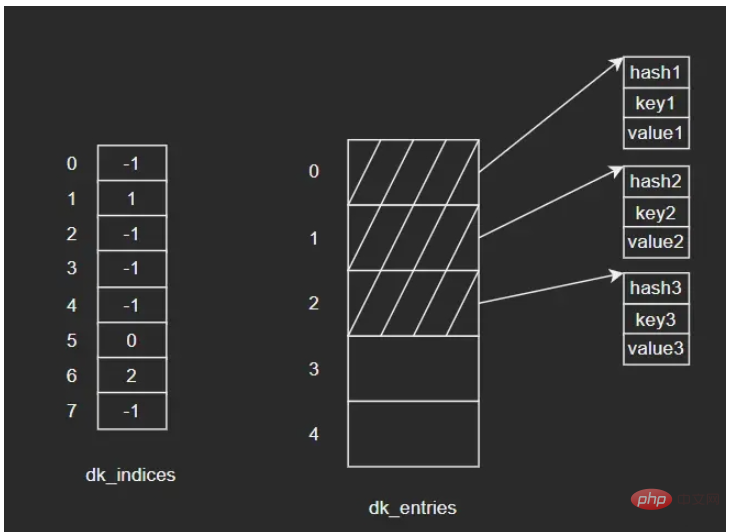
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
The above is the detailed content of Python built-in type dict source code analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
The key to running Jupyter Notebook in VS Code is to ensure that the Python environment is properly configured, understand that the code execution order is consistent with the cell order, and be aware of large files or external libraries that may affect performance. The code completion and debugging functions provided by VS Code can greatly improve coding efficiency and reduce errors.
