
 Technology peripherals
AI
'Lu Zhiwu, a researcher at Renmin University of China, proposed the important impact of ChatGPT on multi-modal generative models'
Technology peripherals
AI
'Lu Zhiwu, a researcher at Renmin University of China, proposed the important impact of ChatGPT on multi-modal generative models'
'Lu Zhiwu, a researcher at Renmin University of China, proposed the important impact of ChatGPT on multi-modal generative models'

The following is the content of Professor Lu Zhiwu’s speech at the ChatGPT and Large Model Technology Conference held by the Heart of the Machine. The Heart of the Machine has edited and organized it without changing the original meaning:

Hello everyone, I am Lu Zhiwu from Renmin University of China. The title of my report today is "Important Enlightenments of ChatGPT on Multimodal Generative Models", which consists of four parts.

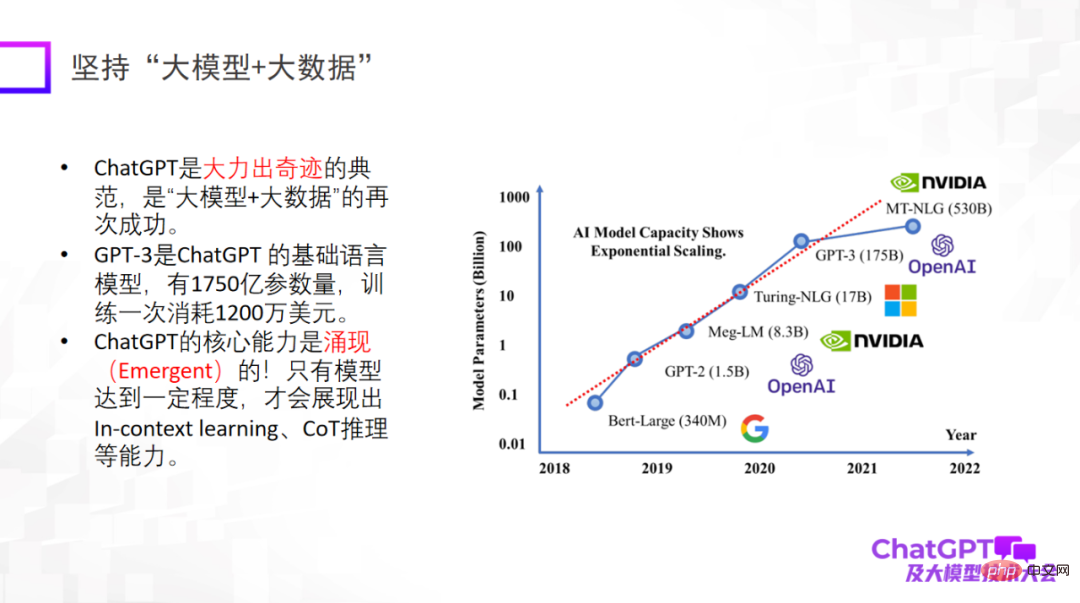
First of all, ChatGPT brings us some inspiration about the innovation of research paradigms. The first point is to use "big model and big data", which is a research paradigm that has been verified repeatedly and is also the basic research paradigm of ChatGPT. It is particularly important to emphasize that only when a large model reaches a certain level will it have emergent capabilities, such as in-context learning, CoT reasoning and other capabilities. These capabilities are very amazing.
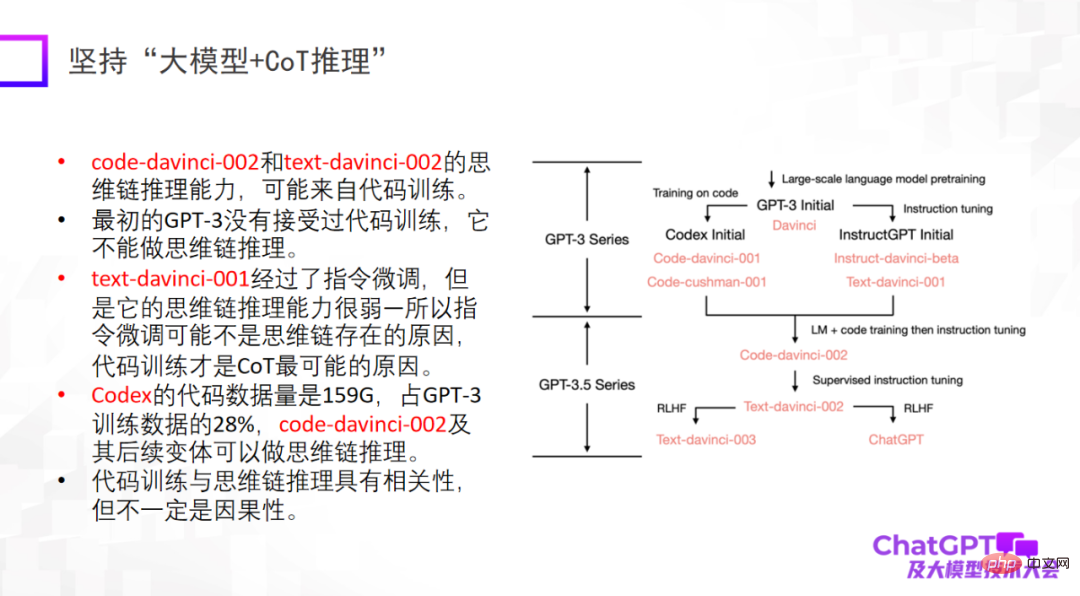
The second point is to insist on "large model reasoning". This is also the point that impressed me most about ChatGPT. Because in the field of machine learning or artificial intelligence, reasoning is recognized as the most difficult, and ChatGPT has also made breakthroughs in this regard. Of course, ChatGPT’s reasoning ability may mainly come from code training, but whether there is an inevitable connection is not yet certain. In terms of reasoning, we should put more effort into figuring out where it comes from, or whether there are other training methods to further enhance its reasoning ability.
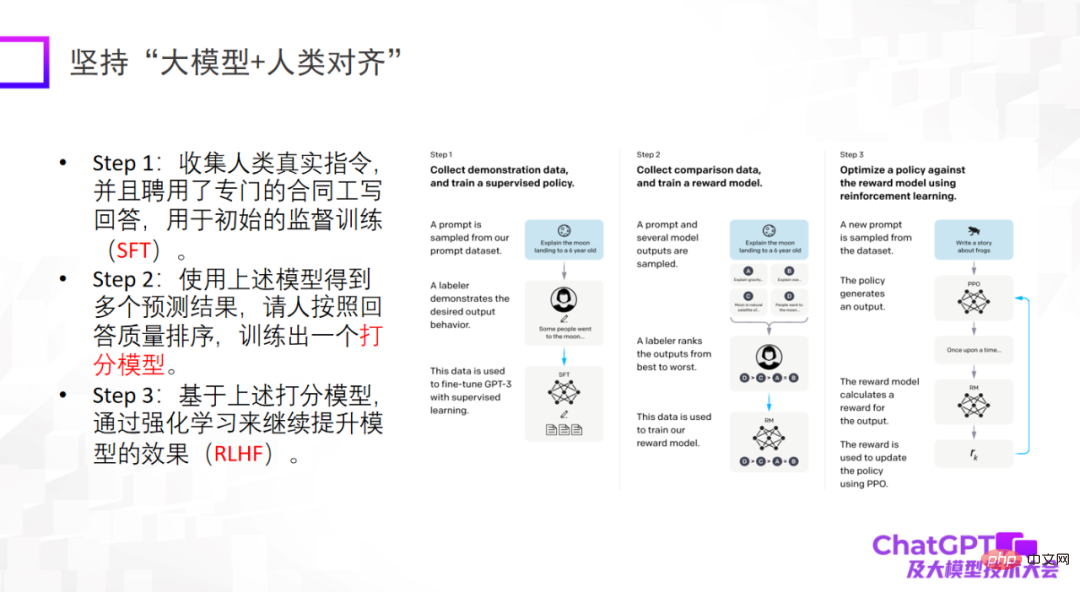
The third point is that the large model must be aligned with humans. This is the important thing ChatGPT gives us from an engineering perspective or a model landing perspective. Enlightenment. If not aligned with humans, the model will generate a lot of harmful information, making the model unusable. The third point is not to raise the upper limit of the model, but the reliability and security of the model are indeed very important.
The advent of ChatGPT has had a great impact on many fields, including myself. Because I have been doing multimodality for several years, I will start to reflect on why we have not made such a powerful model.
ChatGPT is a universal generation in language or text. Let’s take a look at the latest progress in the field of multi-modal universal generation. Multimodal pre-training models have begun to transform into multimodal general generative models, and there have been some preliminary explorations. First, let’s take a look at the Flamingo model proposed by Google in 2019. The following figure is its model structure.
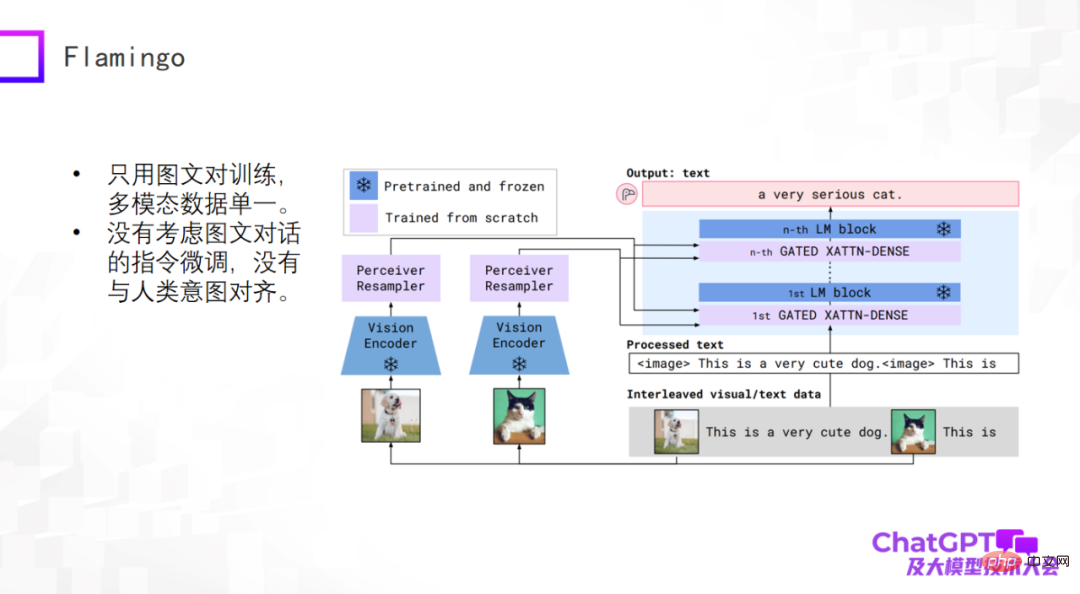
The main body of the Flamingo model architecture is the decoder (Decoder) of the large language model, which is the blue module on the right side of the picture above. In each blue Some adapter layers are added between the color modules, and the Vision Encoder and Perceiver Resampler are added to the left visual part. The design of the entire model is to encode and convert visual things, pass through the adapter, and align them with the language, so that the model can automatically generate text descriptions for images.
Flamingo What are the benefits of such an architectural design? First of all, the blue module in the above picture is fixed (frozen), including the language model Decoder; while the parameter amount of the pink module itself is controllable, so the number of parameters actually trained by the Flamingo model is very small. So don’t think that multi-modal universal generative models are difficult to build. In fact, it’s not that pessimistic. The trained Flamingo model can do many common tasks based on text generation. Of course, the input is multi-modal, such as video description, visual question and answer, multi-modal dialogue, etc. From this perspective, Flamingo can be regarded as a general generative model.
The second example is the newly released BLIP-2 model some time ago. It is improved based on BLIP-1. Its model architecture is very similar to Flamingo, and it basically includes image coding. The decoder and the large language model decoder are fixed, and then a Q-Former with a converter function is added in the middle - from visual to language conversion. So, the part of BLIP-2 that really requires training is the Q-Former.
As shown in the figure below, first input a picture (the picture on the right) into the Image Encoder. The Text in the middle is the question or instruction raised by the user, which is input after Q-Former encoding. Go to a large language model and finally generate the answer, which is probably such a generation process.
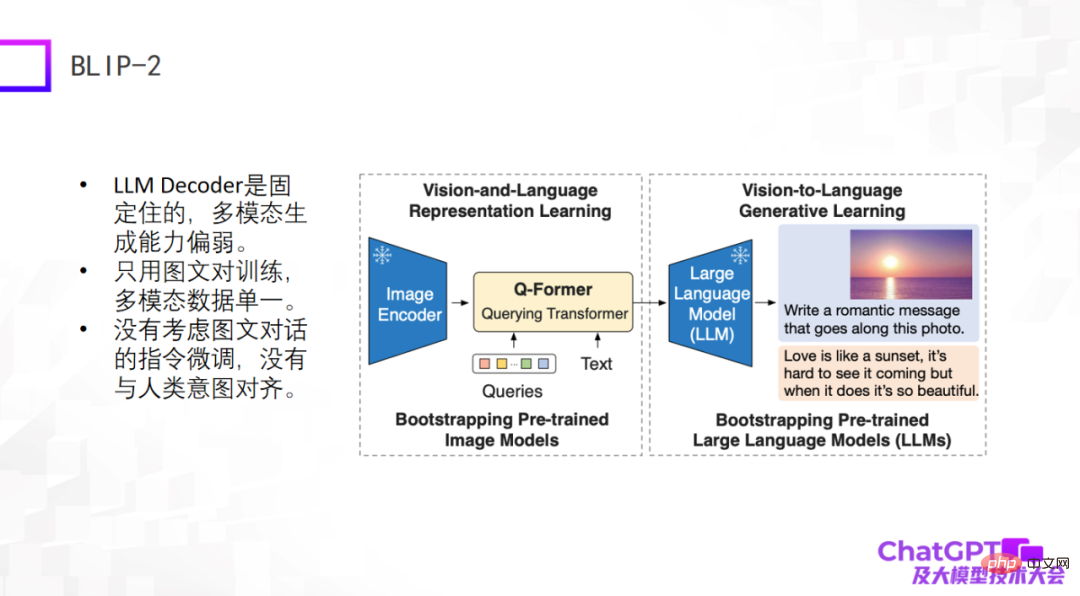
The shortcomings of these two models are obvious, because they appeared relatively early or just appeared, and the engineering methods used by ChatGPT have not been considered. At least there is no instruction fine-tuning for graphic dialogue or multi-modal dialogue, so their overall generation effect is not satisfactory.
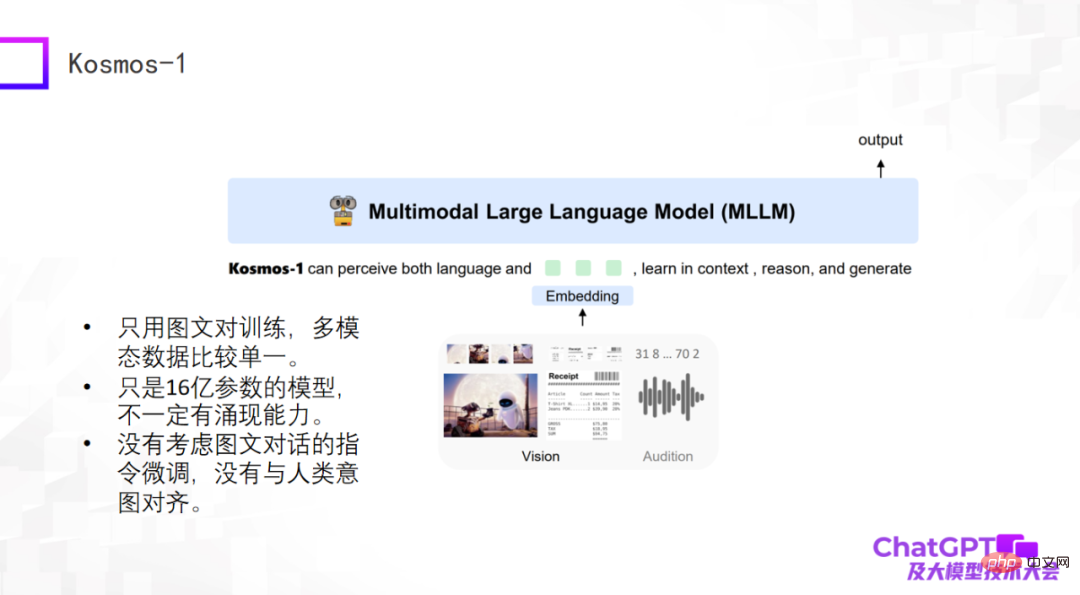
The third one is Kosmos-1 recently released by Microsoft. It has a very simple structure and only uses image and text pairs for training. The multi-modal data is relatively single. The biggest difference between Kosmos-1 and the above two models is that the large language model itself in the above two models is fixed, while the large language model itself in Kosmos-1 needs to be trained, so the Kosmos-1 model The number of parameters is only 1.6 billion, and a model with 1.6 billion parameters may not have the ability to emerge. Of course, Kosmos-1 did not take into account the fine-tuning of commands in graphic dialogue, causing it to sometimes speak nonsense.
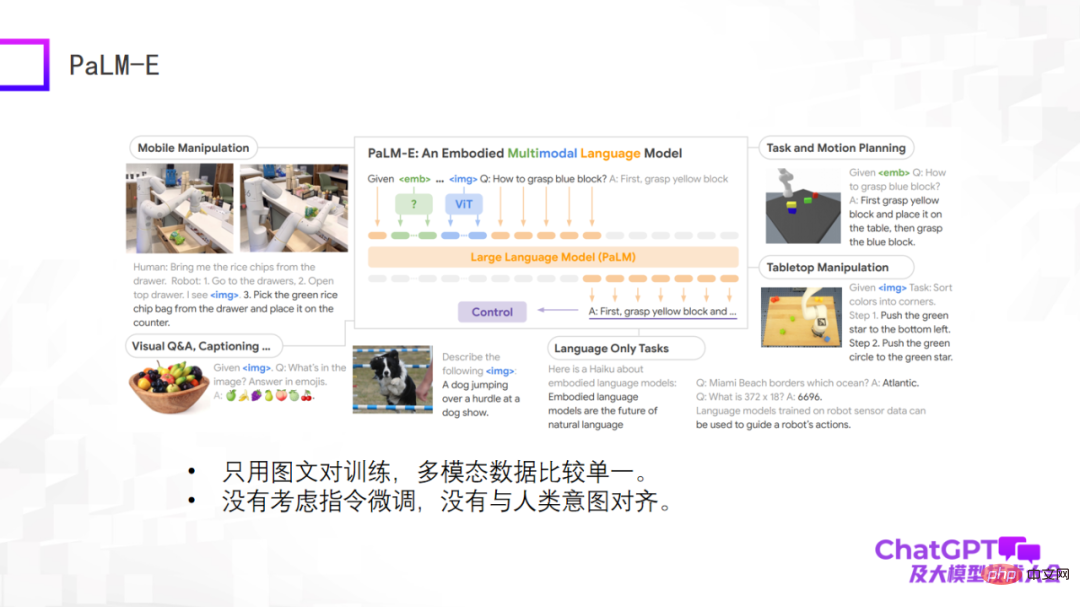
The next example is Google’s multimodal embodied visual language model PaLM-E. The PaLM-E model is similar to the first three examples. PaLM-E also uses the ViT large language model. The biggest breakthrough of PaLM-E is that it finally explores the possibility of implementing multi-modal large language models in the field of robotics. PaLM-E attempts the first step of exploration, but the types of robot tasks it considers are very limited and cannot be truly universal.
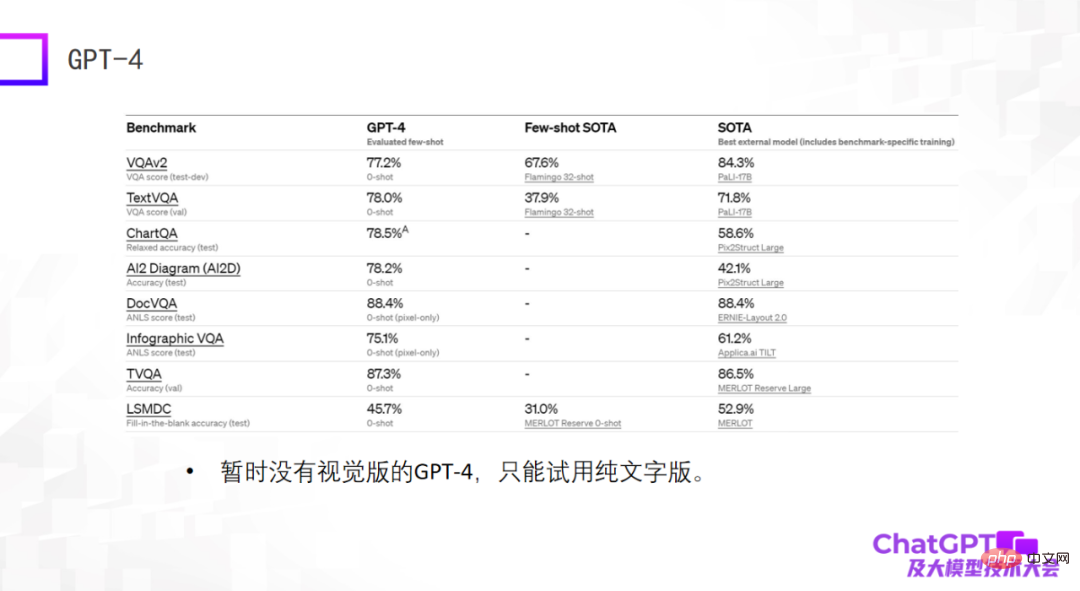
The last example is GPT-4 - it gives particularly amazing results on standard data sets, and many times its results are even better than Currently, fine-tuned SOTA models trained on the dataset are even better. This may come as a shock, but it doesn't actually mean anything. When we were building multi-modal large models two years ago, we discovered that the capabilities of large models cannot be evaluated on standard data sets. Good performance on standard data sets does not mean good results in actual use. There are many differences between the two. Big gap. For this reason, I am slightly disappointed with the current GPT-4, as it only gives results on standard datasets. Moreover, the currently available GPT-4 is not a visual version, but a pure text version.
The above models are generally used for general language generation, and the input is multi-modal input. The following two models are different. Now - not only general language generation, but also visual generation, which can generate both language and images.
The first is Microsoft's Visual ChatGPT, let me briefly evaluate it. The idea of this model is very simple, and it is more of a product design consideration. There are many types of vision-related generation, as well as some visual detection models. The inputs and instructions for these different tasks vary widely. The problem is how to use one model to include all these tasks, so Microsoft designed the Prompt manager, which is used in the core part. OpenAI's ChatGPT is equivalent to translating instructions for different visual generation tasks through ChatGPT. The user's questions are instructions described in natural language, which are translated into instructions that the machine can understand through ChatGPT.
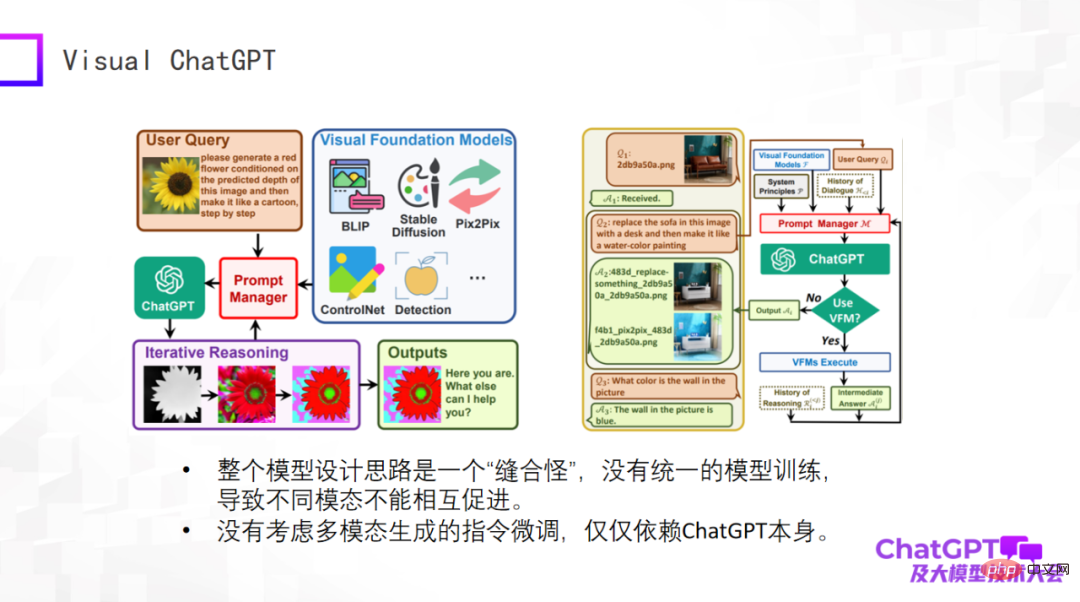
Visual ChatGPT does just such a thing. So it's really good from a product perspective, but nothing new from a model design perspective. Therefore, the overall model is a "stitch monster" from the perspective of the model. There is no unified model training, resulting in no mutual promotion between different modes. Why we do multi-modality is because we believe that data from different modalities must help each other. And Visual ChatGPT does not consider multi-modal generation instruction fine-tuning. Its instruction fine-tuning only relies on ChatGPT itself.
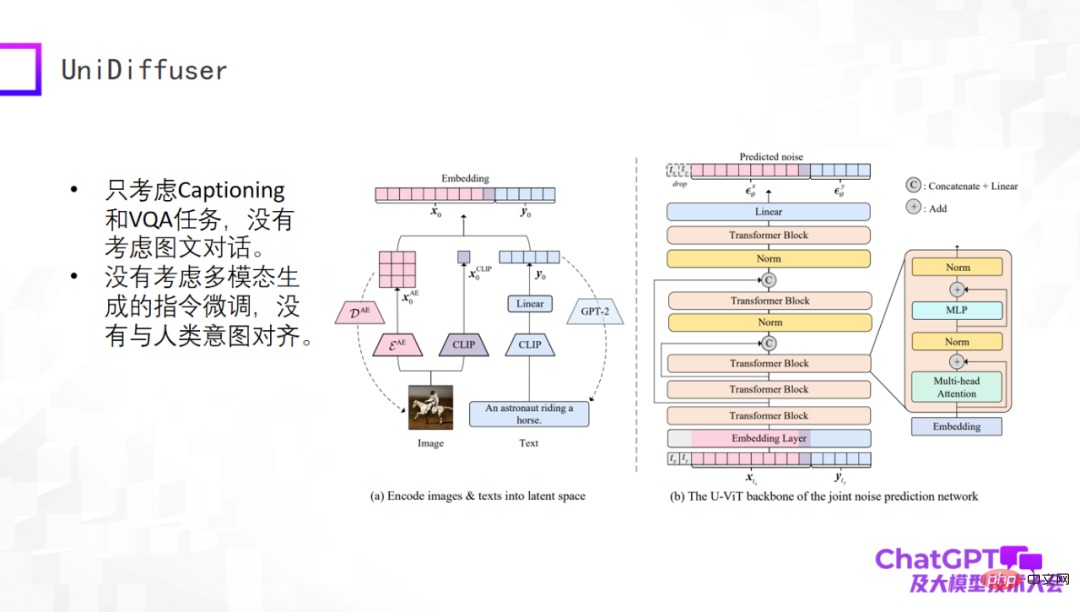
The next example is the UniDiffuser model released by Professor Zhu Jun’s team at Tsinghua University. From an academic perspective, this model can truly generate text and visual content from multi-modal input. This is due to their transformer-based network architecture U-ViT, which is similar to U-Net, the core component of Stable Diffusion, and then generates images. and text generation are unified in a framework. This work itself is very meaningful, but it is still relatively early. For example, it only considers Captioning and VQA tasks, does not consider multiple rounds of dialogue, and does not fine-tune instructions for multi-modal generation.
Having commented so much before, we also made a product called ChatImg, as shown in the picture below. Generally speaking, ChatImg includes an image encoder, a multi-modal image and text encoder, and a text decoder. It is similar to Flamingo and BLIP-2, but we consider more, and there are detailed differences in the specific implementation.
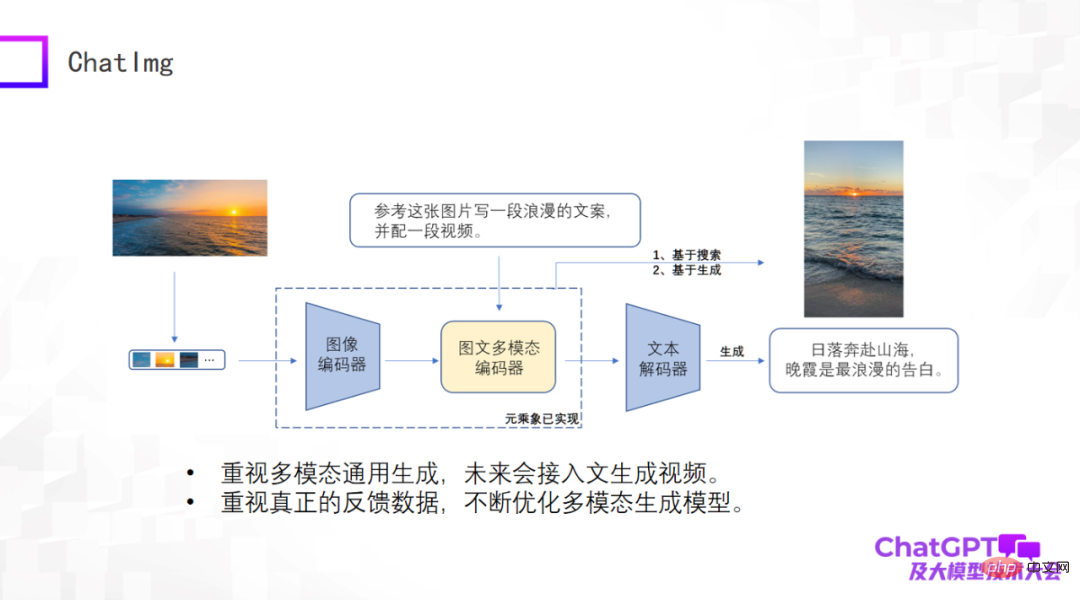
One of the biggest advantages of ChatImg is that it can accept video input. We pay special attention to multi-modal general generation, including text generation, image generation, and video generation. We hope to implement a variety of generation tasks in this framework, and ultimately hope to access text to generate videos.
Second, we pay special attention to real user data. We hope to continuously optimize the generation model itself and improve its capabilities after obtaining real user data, so we released the ChatImg application.
The following pictures are some examples of our tests. As an early model, although there are still some things that are not done well, in general ChatImg can still understand pictures. For example, ChatImg can generate descriptions of paintings in conversations and can also do some in-context learning.
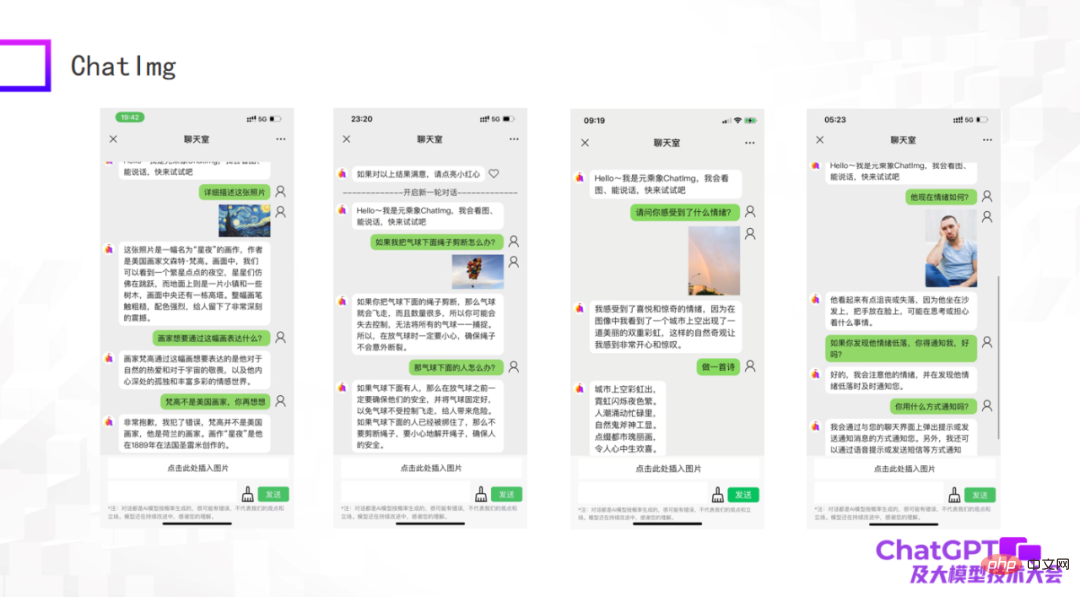
The first example in the picture above describes the painting "Starry Night". In the description, ChatImg said that Van Gogh was an American painter. You tell it Wrong, it can be corrected immediately; the second example ChatImg made physical inferences about the objects in the picture; the third example is a photo I took myself. There are two rainbows in this photo, and it accurately Recognized.
We noticed that the third and fourth examples in the above picture involve emotional issues. This is actually related to the work we are going to do next. We want to connect ChatImg to the robot. Today's robots are usually passive, and all instructions are preset, which makes them seem very rigid. We hope that robots connected to ChatImg can actively communicate with people. How to do this? First of all, the robot must be able to feel people. It may be to objectively see the state of the world and people's emotions, or it may be to obtain a reflection; then the robot can understand and actively communicate with people. Through these two examples, I feel that this goal is achievable.
Finally, let me summarize today’s report. First of all, ChatGPT and GPT-4 have brought innovation to the research paradigm. All of us should actively embrace this change. We cannot complain or make excuses that we have no resources. As long as we face this change, there are always ways to overcome difficulties. Multimodal research does not even require machines with hundreds of cards. As long as corresponding strategies are adopted, a small number of machines can do good work. Second, existing multi-modal generative models all have their own problems. GPT-4 does not yet have an open visual version, and there is still a chance for all of us. Moreover, I think GPT-4 still has a problem, which is what the multi-modal generative model should ultimately look like. It does not give a perfect answer (in fact, it does not reveal any details of GPT-4). This is actually a good thing. People all over the world are very smart and everyone has their own ideas. This may create a new research situation where a hundred flowers bloom. That’s it for my speech, thank you all.

The above is the detailed content of 'Lu Zhiwu, a researcher at Renmin University of China, proposed the important impact of ChatGPT on multi-modal generative models'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
