

Learning multiple tasks in an open environment is an important ability of general-purpose agents. As a popular open-world game with infinitely generated complex worlds and a large number of open tasks, Minecraft has become an important testing environment for open learning research in recent years.
Learning complex tasks in Minecraft is a huge challenge for current reinforcement learning algorithms. On the one hand, the agent searches for resources through local observations in an infinite world and faces the difficulty of exploration. On the other hand, complex tasks often require long execution times and require the completion of many implicit subtasks. For example, making a stone pickaxe involves more than ten sub-tasks such as cutting down trees, making wooden pickaxes, and digging rough stones, etc., which requires the agent to perform thousands of steps to complete. The agent can only receive rewards when completing tasks, and it is difficult to learn tasks through sparse rewards.

Picture: The process of making a stone pickaxe in Minecraft.
Current research around the MineRL diamond mining competition generally uses data sets demonstrated by experts, while research such as VPT uses a large number of labeled data learning strategies. In the absence of additional data sets, the task of training Minecraft with reinforcement learning is very inefficient. MineAgent can only complete a few simple tasks using the PPO algorithm; the model-based SOTA method Dreamer-v3 also needs to sample 10 million steps to learn to obtain rough stones when simplifying the environment simulator.
The team from Peking University and Beijing Zhiyuan Artificial Intelligence Research Institute proposed Plan4MC, a method to efficiently solve Minecraft multitasking without expert data. . The author combines reinforcement learning and planning methods to decompose solving complex tasks into two parts: learning basic skills and skill planning. The authors use intrinsic reward reinforcement learning methods to train three types of fine-grained basic skills. The agent uses a large language model to build a skill relationship graph, and obtains task planning through searching on the graph. In the experimental part, Plan4MC can currently complete 24 complex and diverse tasks, and the success rate has been greatly improved compared to all baseline methods.

In Minecraft, players can obtain hundreds of items through exploration. A task is defined as a combination of initial conditions and target items, for example, "Initialize the
workbench and obtain cooked beef." Solving this task includes steps such as "get beef" and "make a furnace with a workbench and rough stone". These subdivided steps are called skills. Humans acquire and combine such skills to complete various tasks in the world, rather than learning each task independently. The goal of Plan4MC is to learn strategies to master a large number of skills and then combine the skills into tasks through planning.
The author built 24 test tasks on the MineDojo simulator, which cover a variety of behaviors (cutting trees, digging rough stones, interacting with animals), a variety of terrains, and involve 37 basic skills. Dozens of steps of skill sets and thousands of steps of environmental interaction are required to complete individual tasks.
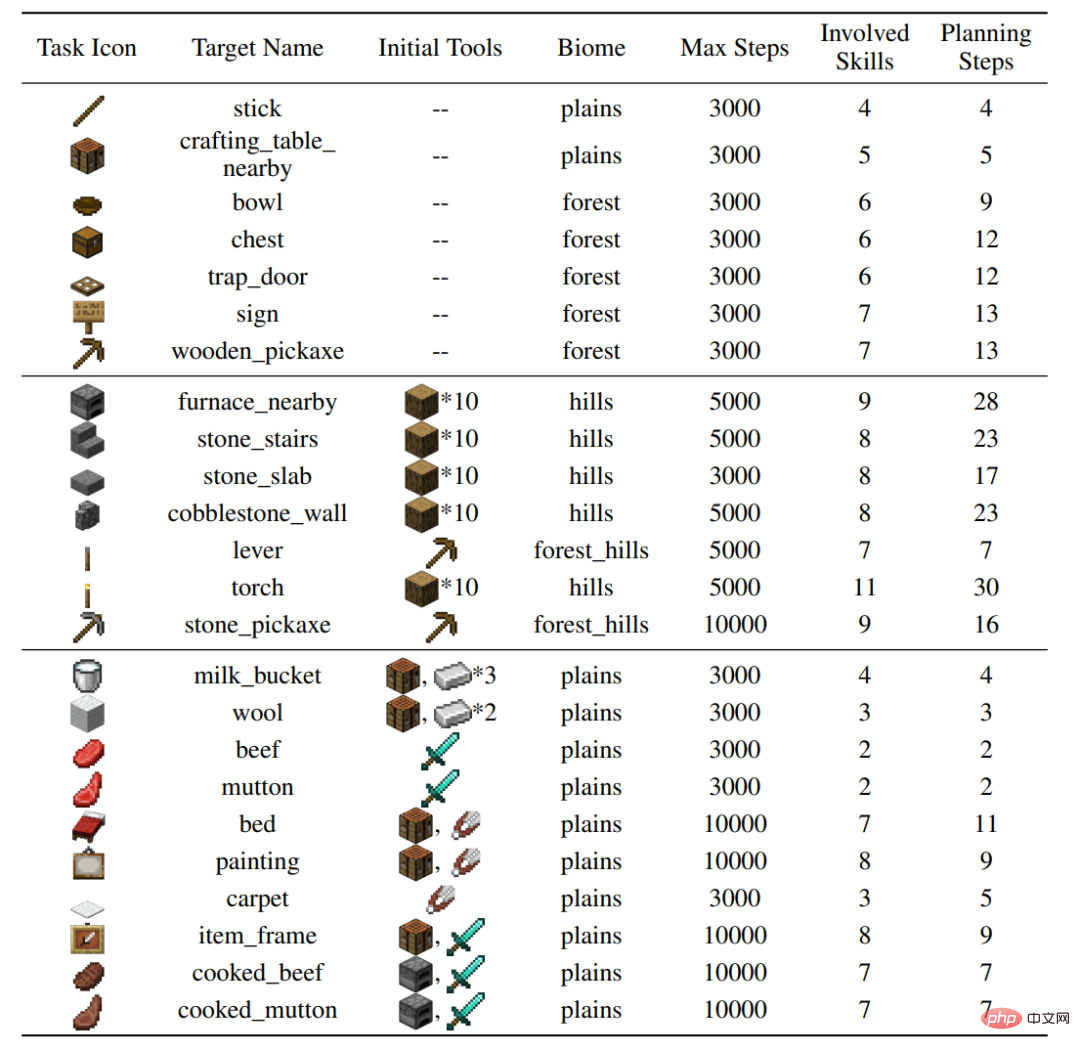
Figure: Settings for 24 tasks
2 , Plan4MC method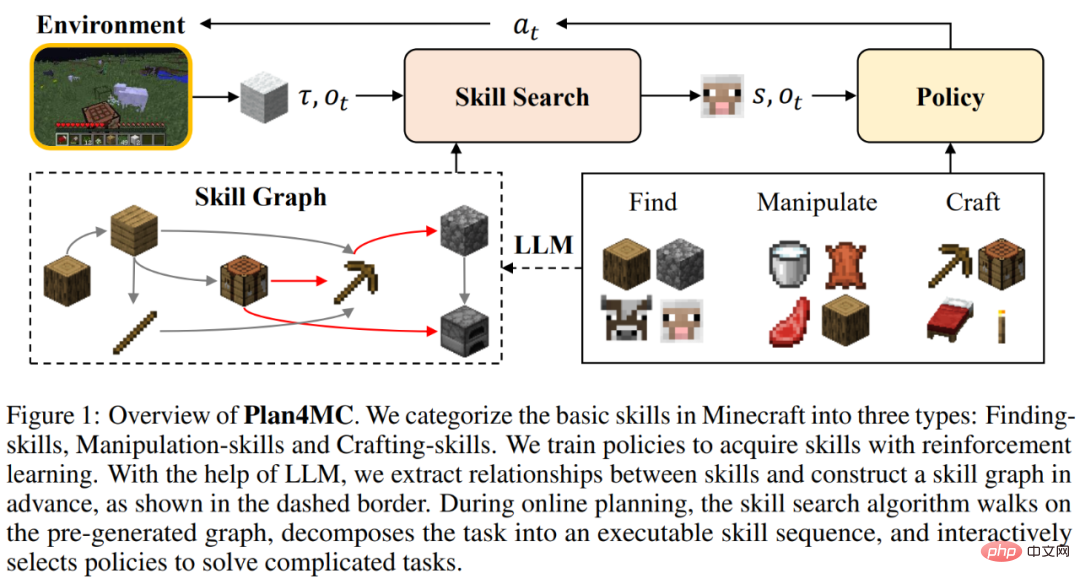
Learning skills
Because reinforcement learning makes it difficult for players to run and explore the world on a large scale during training, many skills still cannot be mastered. The author proposed to separate the steps of exploration and search, and further refine the "tree-cutting" skill into "finding trees" and "obtaining wood". All skills in Minecraft are divided into three categories of fine-grained basic skills:
For each type of skill, the author designs a reinforcement learning model and intrinsic rewards for efficient learning. Searching skills use a hierarchical strategy, in which the upper-level strategy is responsible for giving the target location and increasing the exploration range, and the lower-level strategy is responsible for reaching the target location. Operational skills are trained using the PPO algorithm combined with the intrinsic reward of the MineCLIP model. Synthetic skills only use one action to complete. On the unmodified MineDojo simulator, learning all skills requires only 6.5M steps of interacting with the environment.
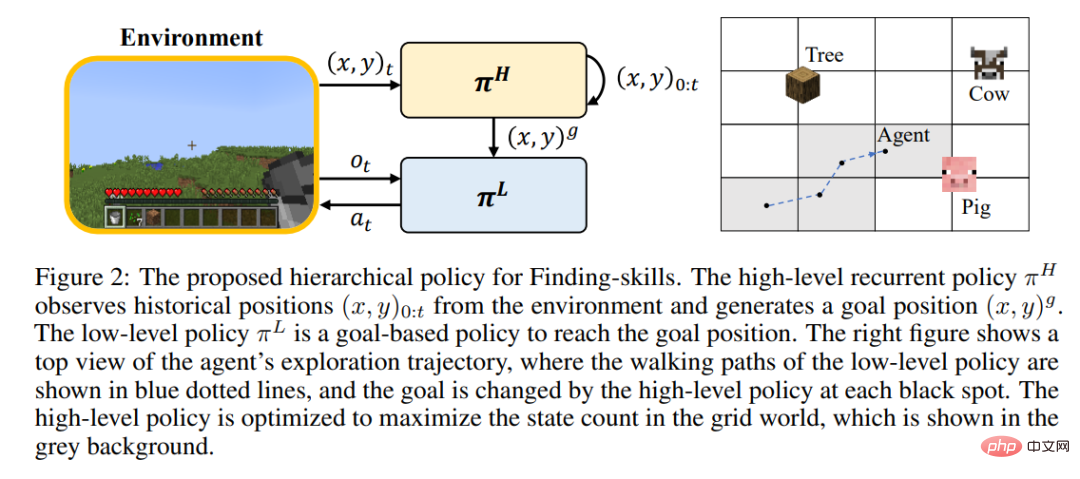
Planning Algorithm
Plan4MC Utilization Skills Plan the dependencies between them. For example, there is the following relationship between obtaining a stone pickaxe and obtaining raw stones, wooden sticks, placed workbench and other skills.

The author generates the relationship between all skills by interacting with the large language model ChatGPT and builds the skills directed acyclic graph. The planning algorithm is a depth-first search on the skill graph, as shown in the figure below.

##Compared with Inner Monologue, DEPS and other interactive planning methods with large language models, Plan4MC can effectively avoid large language models. Errors during model planning.
3. Experimental results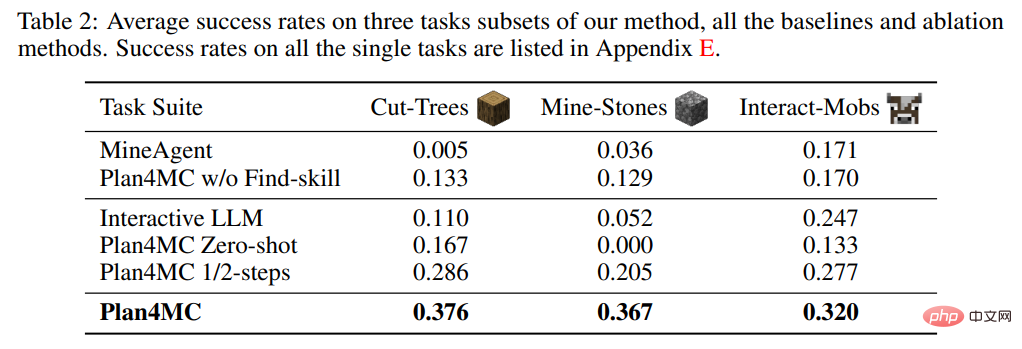
In the research on learning skills, the author introduced the method of not doing MineAgent for task decomposition, and Plan4MC w/o Find-skill, an ablation experiment that does not break down search skills. Table 2 shows that Plan4MC significantly outperforms baseline methods on all three sets of tasks. MineAgent's performance is close to Plan4MC on simple tasks such as milking cows and shearing sheep, but it cannot complete tasks such as cutting down trees and digging rough stones that are difficult to explore. The method without skill segmentation has a lower success rate than Plan4MC on all tasks.
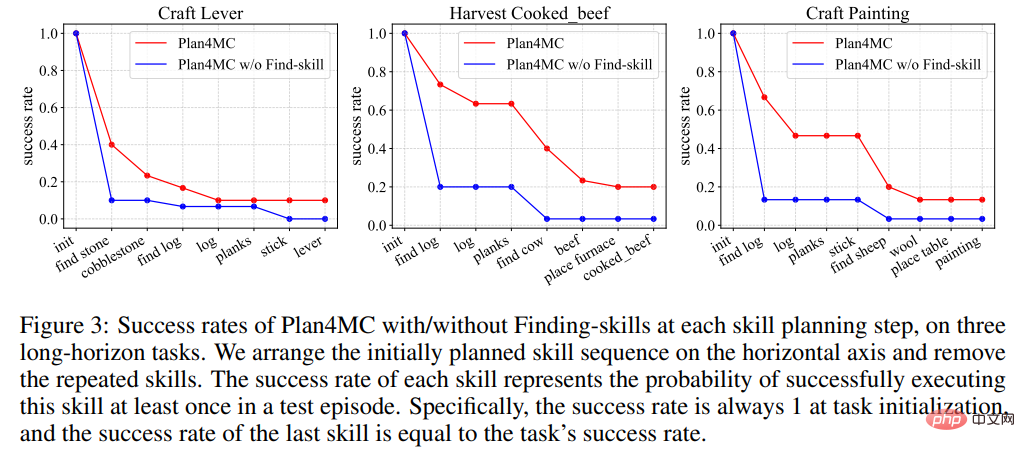
Figure 3 shows that in the process of completing the task, each method has a larger performance in the stage of finding the target. The probability of failure leads to a decline in the success rate curve. The failure probability of the method without skill segmentation at these stages is significantly higher than that of Plan4MC.
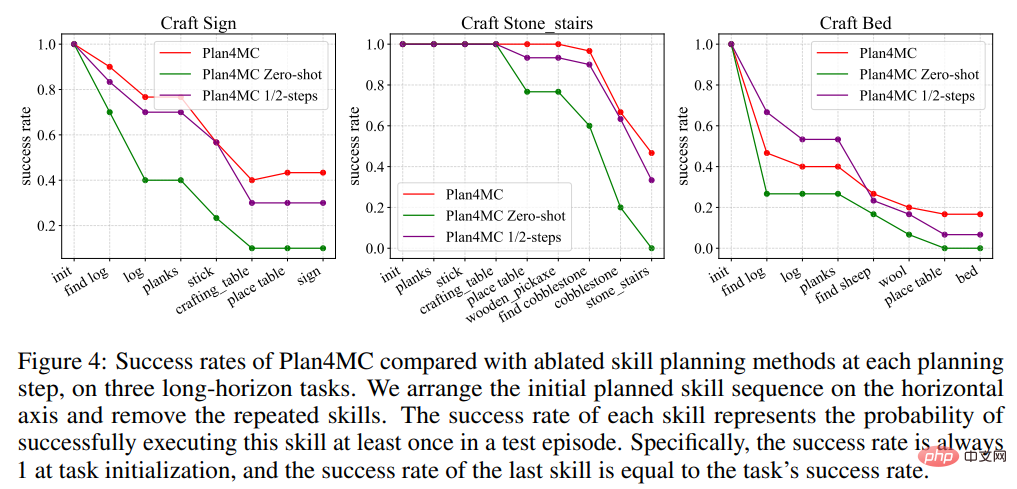
In the research on planning, the author introduced the baseline method Interactive LLM using ChatGPT for interactive planning, and two ablation experiments: the Zero-shot method that does not re-plan when the skill execution fails and the half-used method 1/2-steps method for maximum number of interaction steps. Table 2 shows that Interactive LLM performs close to Plan4MC on the task set of interacting with animals, but performs poorly on the other two task sets that require more planning steps. Zero-shot methods perform poorly on all tasks. The success rate of using half the number of steps is not much lower than that of Plan4MC. It seems that Plan4MC can complete the task efficiently with fewer steps.
The author proposed Plan4MC, which uses reinforcement learning and planning to solve multi-tasks in Minecraft. In order to solve the problems of exploration difficulty and sample efficiency, the author uses reinforcement learning with intrinsic rewards to train basic skills, and uses large language models to build skill graphs for task planning. The authors verified the advantages of Plan4MC compared to various baseline methods including ChatGPT on a large number of difficult Minecraft tasks.
Conclusion: Reinforcement Learning Skills Large Language Model Task planning has the potential to implement the System1/2 human decision-making model described by Daniel Kahneman.
The above is the detailed content of Use ChatGPT and reinforcement learning to play 'Minecraft', Plan4MC overcomes 24 complex tasks. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



