
 Common Problem
TPU vs. GPU: Comparative differences in performance and speed in actual scenarios
Common Problem
TPU vs. GPU: Comparative differences in performance and speed in actual scenarios
TPU vs. GPU: Comparative differences in performance and speed in actual scenarios

In this article, we will compare TPU vs GPU. But before we dive in, here’s what you need to know.
Machine learning and artificial intelligence technologies accelerate the development of intelligent applications. To this end, semiconductor companies continue to create accelerators and processors, including TPUs and CPUs, to handle more complex applications.
Some users are having trouble understanding when a TPU is recommended and when a GPU is used to complete their computer tasks.
The GPU, also known as the Graphics Processing Unit, is your PC’s video card that provides you with a visual and immersive PC experience. For example, if your PC does not detect the GPU, you can follow simple steps.
To better understand these situations, we also need to clarify what a TPU is and how it compares to a GPU.
What is TPU?
A TPU or Tensor Processing Unit is an Application Specific Integrated Circuit (IC), also known as an ASIC (Application Specific Integrated Circuit), used for a specific application. Google created TPU from scratch, began using it in 2015, and made it available to the public in 2018.

#TPU is available as a minor silicon or cloud version. To accelerate machine learning of neural networks using TensorFlow software, cloud TPUs solve complex matrix and vector operations at blazing speeds.
With TensorFlow, the Google Brain team has developed an open source machine learning platform that allows researchers, developers, and enterprises to build and operate AI models using Cloud TPU hardware.
When training complex and robust neural network models, TPU reduces the time to reach accurate values. This means that training a deep learning model that might take weeks takes a fraction of that time using GPUs.
Are TPU and GPU the same?
They are highly different in architecture. The graphics processing unit is a processor in its own right, although it is piped into vectorized numerical programming. GPUs are actually the next generation of Cray supercomputers.
The TPU is a coprocessor that does not execute instructions itself; the code is executed on the CPU, which provides a flow of small operations to the TPU.
When should I use TPU?
TPUs in the cloud are tailored for specific applications. In some cases, you may prefer to use a GPU or CPU to perform machine learning tasks. In general, the following principles can help you evaluate whether a TPU is the best choice for your workload:
- Matrix calculations dominate the model
- In the model's main training loop , there are no custom TensorFlow operations
- They are models trained over weeks or months
- They are large models with a wide range of effective batch sizes.
Now let’s get straight to the TPU vs. GPU comparison.
What is the difference between GPU and TPU?
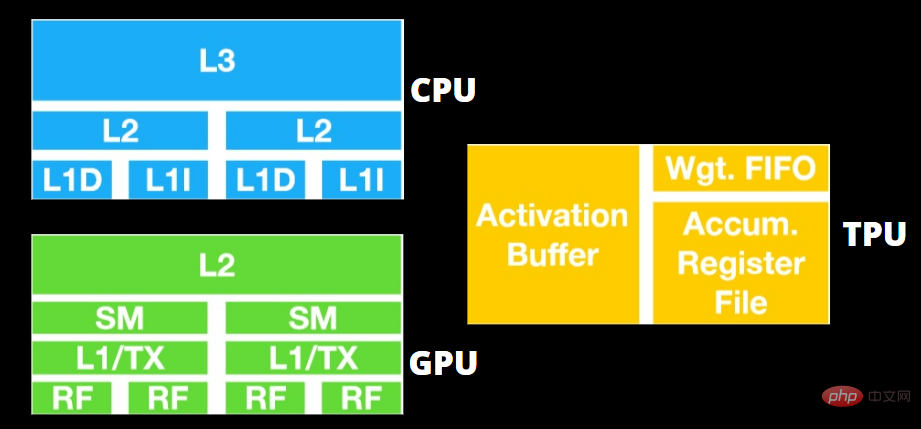
TPU vs. GPU Architecture
The TPU is not a highly complex piece of hardware and feels like a signal processing engine for radar applications rather than a traditional X86 derived architecture.
Although there are many matrix multiplications and divisions, it is more like a coprocessor than a GPU; it only executes commands received by the host.
Because there are so many weights to be input to the matrix multiplication component, the TPU's DRAM runs in parallel as a single unit.
In addition, since the TPU can only perform matrix operations, the TPU board is connected to the CPU-based host system to complete tasks that the TPU cannot handle.
The host is responsible for transferring data to the TPU, preprocessing, and retrieving details from cloud storage.
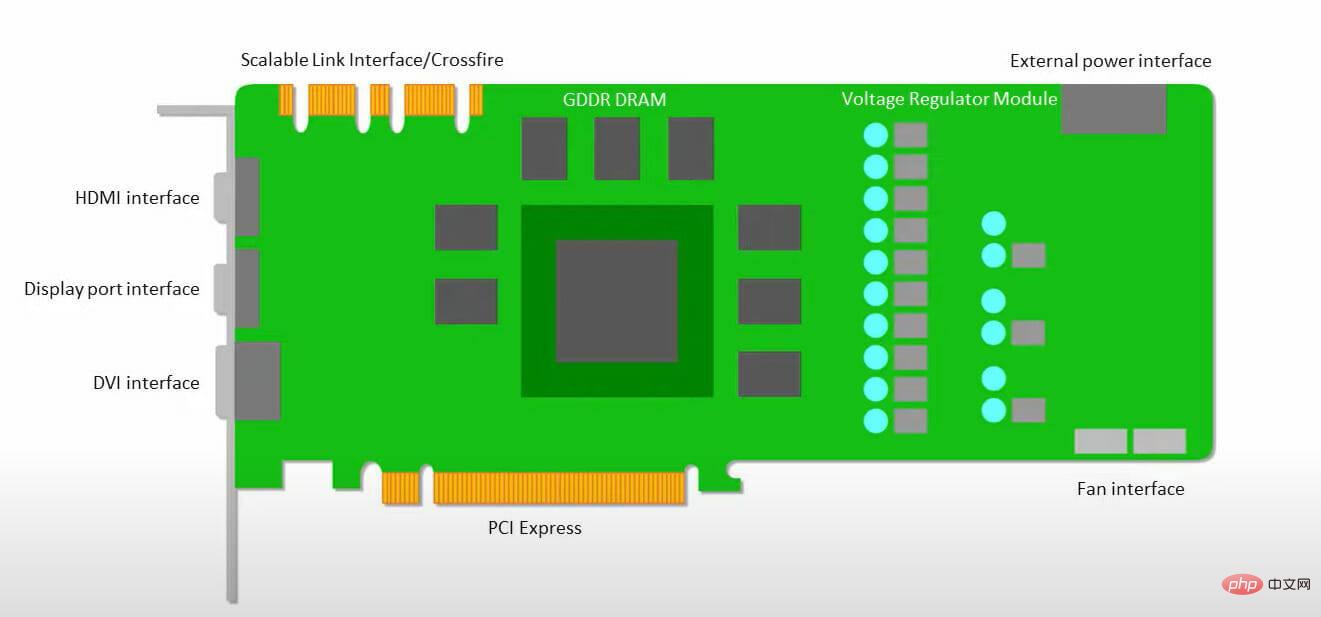
#The GPU is more concerned with having available cores for applications to work on than accessing a low-latency cache.
Many PCs (clusters of processors) with multiple SMs (Streaming Multiprocessors) become single GPU gadgets, each containing a first-level instruction cache layer and accompanying cores.
An SM typically uses two cached shared layers and one cached private layer before fetching data from global GDDR-5 memory. GPU architecture can tolerate memory latency.
The GPU operates with a minimum number of memory cache levels. However, since the GPU has more transistors dedicated to processing, it is less concerned with the time it takes to access data in memory.
Because the GPU is always occupied by enough computation, possible memory access delays are hidden.
TPU vs. GPU Speed
This original TPU generates targeted inference using a learned model rather than a trained model.
TPUs are 15 to 30 times faster than current GPUs and CPUs on commercial AI applications using neural network inference.
In addition, TPU is very energy-efficient, with TOPS/Watt values increased by 30 to 80 times.
So when doing a TPU vs. GPU speed comparison, the odds are stacked in favor of the Tensor Processing Unit.
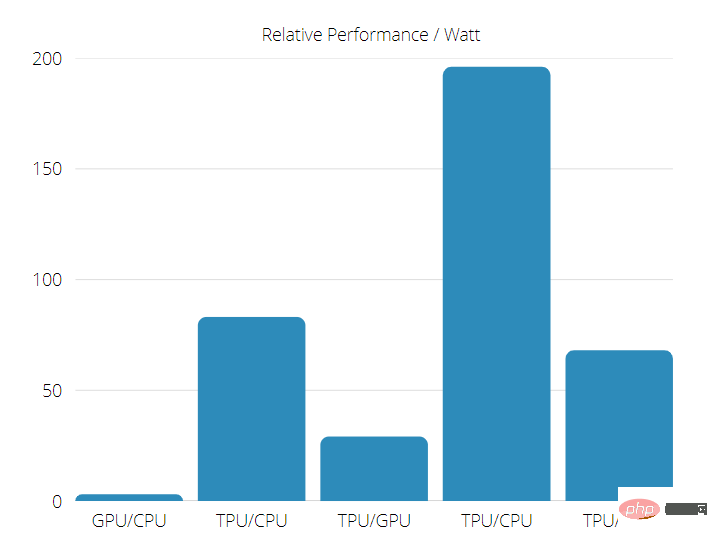
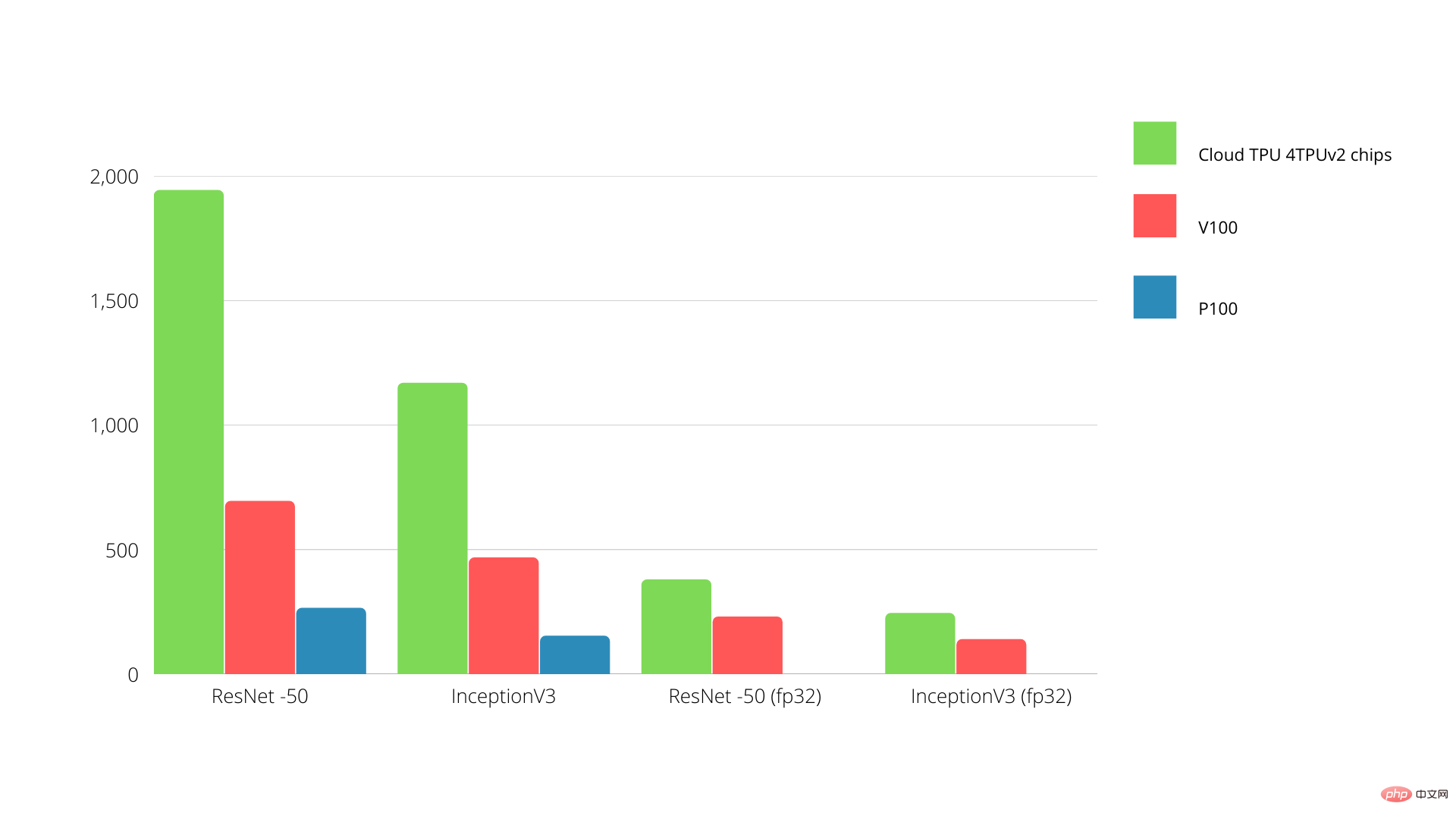
TPU vs. GPU Performance
The TPU is a tensor processing machine designed to accelerate Tensorflow graph computations.
On a single board, each TPU delivers up to 64 GB of high-bandwidth memory and 180 teraflops of floating-point performance.
The comparison between Nvidia GPU and TPU is shown below. The Y-axis represents the number of photos per second, while the X-axis represents the various models.
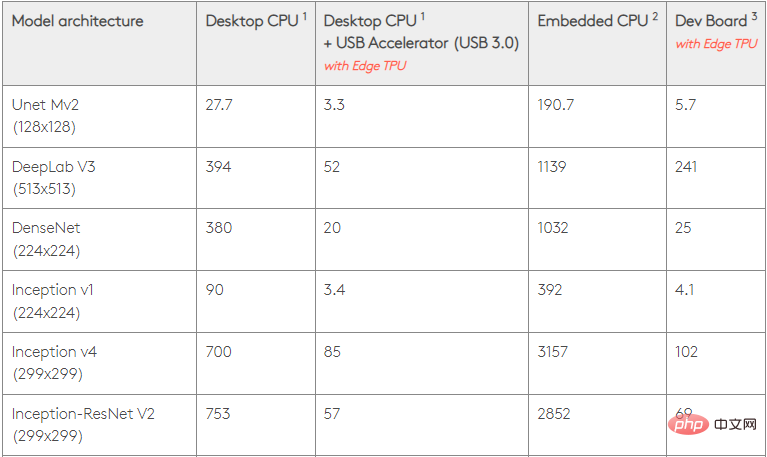
TPU vs. GPU Machine Learning
The following are the training times for CPU and GPU using different batch sizes and each Epoch iteration:
- Number of iterations/epochs: 100, batch size: 1000, total epochs: 25, parameters: 1.84 M, model type: Keras Mobilenet V1 (alpha 0.75).
| Accelerator | GPU (NVIDIA K80) | Thermoplastic Polyurethane |
| Training accuracy (%) | 96.5 | 94.1 |
| Validation accuracy (%) | 65.1 | 68.6 |
| Time per iteration (milliseconds) | 69 | 173 |
| Time per epoch (s) | 69 | 173 |
| Total time (minutes) | 30 | 72 |
- ##Iterations/epoch: 1000, Batch size: 100, Total epochs: 25, Parameters: 1.84 M, and Model type: Keras Mobilenet V1 (alpha 0.75)
| GPU (NVIDIA K80) | Thermoplastic Polyurethane | |
| 97.4 | 96.9 | |
| 45.2 | 45.3 | |
| 185 | 252 | |
| 18 | 25 | |
| 16 | 21 |
The above is the detailed content of TPU vs. GPU: Comparative differences in performance and speed in actual scenarios. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 AMD FSR 3.1 launched: frame generation feature also works on Nvidia GeForce RTX and Intel Arc GPUs
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 launched: frame generation feature also works on Nvidia GeForce RTX and Intel Arc GPUs
Jun 29, 2024 am 06:57 AM
AMD delivers on its initial March ‘24 promise to launch FSR 3.1 in Q2 this year. What really sets the 3.1 release apart is the decoupling of the frame generation side from the upscaling one. This allows Nvidia and Intel GPU owners to apply the FSR 3.
 Beelink EX graphics card expansion dock promises zero GPU performance loss
Aug 11, 2024 pm 09:55 PM
Beelink EX graphics card expansion dock promises zero GPU performance loss
Aug 11, 2024 pm 09:55 PM
One of the standout features of the recently launched Beelink GTi 14is that the mini PC has a hidden PCIe x8 slot underneath. At launch, the company said that this would make it easier to connect an external graphics card to the system. Beelink has n
 The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
Ollama is a super practical tool that allows you to easily run open source models such as Llama2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you have not installed Ollama locally, you can read this article. In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks. Start the nomic-embed-text service when you have successfully installed o
 Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks: REST API request processing: Vert.x is the best, with a request rate of 2 times SpringBoot and 3 times Dropwizard. Database query: SpringBoot's HibernateORM is better than Vert.x and Dropwizard's ORM. Caching operations: Vert.x's Hazelcast client is superior to SpringBoot and Dropwizard's caching mechanisms. Suitable framework: Choose according to application requirements. Vert.x is suitable for high-performance web services, SpringBoot is suitable for data-intensive applications, and Dropwizard is suitable for microservice architecture.
 Desktop resolution affects 'Black Myth: Wukong' frame rate dropped by half? RTX 4060 frame rate test errata
Aug 16, 2024 am 09:35 AM
Desktop resolution affects 'Black Myth: Wukong' frame rate dropped by half? RTX 4060 frame rate test errata
Aug 16, 2024 am 09:35 AM
A few days ago, Game Science released the benchmark software for "Black Myth: Wukong". During the test, we found that when an external monitor is connected (the independent display is directly connected to the video output interface), if the desktop resolution of the monitor is larger than the in-game resolution , the game frame rate will drop very significantly, and in some cases the frame rate will even drop by half. So we restarted the test and found out the reason. This article is about my last test: "2 resolutions x 13 image qualities = 26 test results, RTX4060 in "Black Myth: Wukong" What is the frame rate in ? 》Correction and errata, I would like to apologize to everyone here first. In theory, the RTX4060 will be much higher in "Black Myth: Wukong" than my previous test results.
 It is expected to become the first GPU of Intel's next generation independent graphics, and the bmg_g21 core is the first to appear in LLVM update.
Jun 09, 2024 am 09:42 AM
It is expected to become the first GPU of Intel's next generation independent graphics, and the bmg_g21 core is the first to appear in LLVM update.
Jun 09, 2024 am 09:42 AM
According to news from this site on May 13, X platform person @miktdt discovered that Intel recently added bmg_g21 (BattlemageG21, BMG-G21) core related code to the LLVM document of the oneAPIDPC++ compiler. This is also the first time that code related to the Battlemage architecture independent graphics has appeared in the document, suggesting that the Battlemage G21 GPU is expected to become the first model of Intel's next generation independent graphics. This site noticed that the GPU architecture of bmg_g21 is called intel_gpu_20_1_4 in the document, which shares the same "inte" with the lnl_m (LunarLake-M) processor that is believed to use the nuclear version of the Battlemage architecture.
 PHP array key value flipping: Comparative performance analysis of different methods
May 03, 2024 pm 09:03 PM
PHP array key value flipping: Comparative performance analysis of different methods
May 03, 2024 pm 09:03 PM
The performance comparison of PHP array key value flipping methods shows that the array_flip() function performs better than the for loop in large arrays (more than 1 million elements) and takes less time. The for loop method of manually flipping key values takes a relatively long time.
 How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
Effective techniques for optimizing C++ multi-threaded performance include limiting the number of threads to avoid resource contention. Use lightweight mutex locks to reduce contention. Optimize the scope of the lock and minimize the waiting time. Use lock-free data structures to improve concurrency. Avoid busy waiting and notify threads of resource availability through events.