

Backdoor defense method of segmented backdoor training: DBD

The research group of Professor Wu Baoyuan of the Chinese University of Hong Kong (Shenzhen) and the research group of Professor Qin Zhan of Zhejiang University jointly published an article in the field of backdoor defense, which has been successfully accepted by ICLR2022.
In recent years, the backdoor issue has received widespread attention. As backdoor attacks continue to be proposed, it becomes increasingly difficult to propose defense methods against general backdoor attacks. This paper proposes a backdoor defense method based on a segmented backdoor training process.
This article reveals that the backdoor attack is an end-to-end supervised training method that projects the backdoor into the feature space. On this basis, this article divides the training process to avoid backdoor attacks. Comparative experiments were conducted between this method and other backdoor defense methods to prove the effectiveness of this method.
Inclusion conference: ICLR2022
##Article link: https://arxiv.org/pdf/ 2202.03423.pdf
Code link: https://github.com/SCLBD/DBD
1 Background Introduction
The goal of a backdoor attack is to make the model predict correct and clean samples by modifying the training data or controlling the training process, but samples with backdoors are judged as target labels. For example, a backdoor attacker adds a fixed-position white block to an image (i.e., a poisoned image) and changes the label of the image to the target label. After training the model with these poisoned data, the model will determine that the image with a specific white block is the target label (as shown in the figure below).
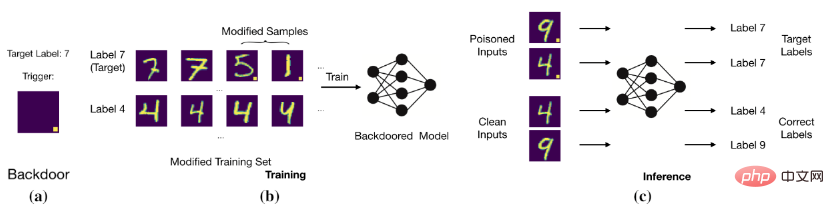 Basic backdoor attack
Basic backdoor attack
The model establishes a trigger and a target tag label).
2 Related work
2.1 Backdoor attack
Existing backdoor attack methods are as follows: poisoning The label modification of images is divided into the following two categories: Poison-Label Backdoor Attack, which modifies the label of the poisoned image, and Clean-Label Backdoor Attack, which maintains the original label of the poisoned image.
1. Poisoning label attack: BadNets (Gu et al., 2019) is the first and most representative poisoning label attack. Later (Chen et al., 2017) proposed that the invisibility of poisoned images should be similar to that of their benign versions, and based on this, a blended attack was proposed. Recently, (Xue et al., 2020; Li et al., 2020; 2021) further explored how to conduct poisoning tag backdoor attacks more covertly. Recently, a more stealthy and effective attack, WaNet (Nguyen & Tran, 2021), was proposed. WaNet uses image distortion as a backdoor trigger, which preserves the image content while deforming it.
2. Clean tag attack: To solve the problem that users can notice backdoor attacks by checking image-tag relationships, Turner et al. (2019) proposed the clean tag attack paradigm, where The target label is consistent with the original label of the poisoned sample. This idea was extended to attack video classification in (Zhao et al., 2020b), who adopted a target-general adversarial perturbation (Moosavi-Dezfooli et al., 2017) as a trigger. Although clean tag backdoor attacks are more subtle than poisoned tag backdoor attacks, their performance is usually relatively poor and may not even create the backdoor (Li et al., 2020c).
2.2 Backdoor Defense
Most of the existing backdoor defenses are empirical and can be divided into five categories, including
1. Detection-based defense (Xu et al, 2021; Zeng et al, 2011; Xiang et al, 2022) checks whether the suspicious model or sample is attacked, and it will deny the use of malicious objects.
2. Preprocessing-based defense (Doan et al, 2020; Li et al, 2021; Zeng et al, 2021) aims to destroy the trigger pattern contained in the attack sample, by A preprocessing module is introduced before inputting images into the model to prevent backdoor activation.
3. Defense based on model reconstruction (Zhao et al, 2020a; Li et al, 2021;) is to eliminate hidden backdoors in the model by directly modifying the model.
4. Triggering comprehensive defense (Guo et al, 2020; Dong et al, 2021; Shen et al, 2021) is to first learn the backdoor, and secondly to eliminate the hidden backdoor by suppressing its impact.
5. Defense based on poisoning suppression (Du et al, 2020; Borgnia et al, 2021) reduces the effectiveness of poisoned samples during the training process to prevent the generation of hidden backdoors
2.3 Semi-supervised learning and self-supervised learning
1. Semi-supervised learning: In many real-world applications, the acquisition of labeled data Often rely on manual labeling, which is very expensive. In comparison, it is much easier to obtain unlabeled samples. In order to harness the power of both unlabeled and labeled samples, a large number of semi-supervised learning methods have been proposed (Gao et al., 2017; Berthelot et al, 2019; Van Engelen & Hoos, 2020). Recently, semi-supervised learning has also been used to improve model security (Stanforth et al, 2019; Carmon et al, 2019), who use unlabeled samples in adversarial training. Recently, (Yan et al, 2021) discussed how to backdoor semi-supervised learning. However, in addition to modifying the training samples, this method also needs to control other training components (such as training loss).
2. Self-supervised learning: The self-supervised learning paradigm is a subset of unsupervised learning, where the model is trained using signals generated by the data itself (Chen et al, 2020a; Grill et al , 2020; Liu et al., 2021). It is used to increase adversarial robustness (Hendrycks et al, 2019; Wu et al, 2021; Shi et al, 2021). Recently, some articles (Saha et al, 2021; Carlini & Terzis, 2021; Jia et al, 2021) explore how to put backdoors into self-supervised learning. However, in addition to modifying training samples, these attacks also require controlling other training components (e.g., training loss).
3 Backdoor Features
We conducted BadNets and clean label attacks on the CIFAR-10 dataset (Krizhevsky, 2009). Supervised learning on toxic datasets and self-supervised learning SimCLR on unlabeled datasets (Chen et al., 2020a).
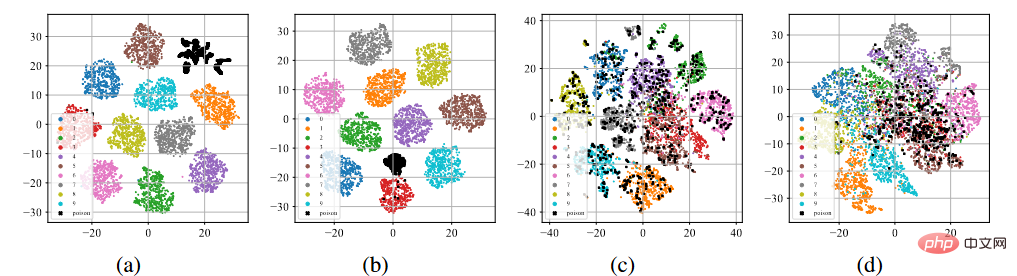
T-sne display of backdoor characteristics
As shown in the picture above (a )-(b), after the standard supervised training process, poisoned samples (represented by black dots) tend to cluster together to form separate clusters regardless of the poisoned label attack or the clean label attack. This phenomenon hints at the success of existing poisoning-based backdoor attacks. Over-learning allows the model to learn the characteristics of backdoor triggers. Combined with an end-to-end supervised training paradigm, the model can reduce the distance between poisoned samples in the feature space and connect the learned trigger-related features with target labels. On the contrary, as shown in Figures (c)-(d) above, on the unlabeled poisoning data set, after the self-supervised training process, the poisoned samples are very close to the samples with original labels. This shows that we can prevent backdoors through self-supervised learning.
4 Backdoor defense based on segmentation
Based on the analysis of backdoor characteristics, we propose backdoor defense in the segmentation training phase. As shown in the figure below, it consists of three main stages, (1) learning a purified feature extractor through self-supervised learning, (2) filtering high-confidence samples through label noise learning, and (3) semi-supervised fine-tuning.
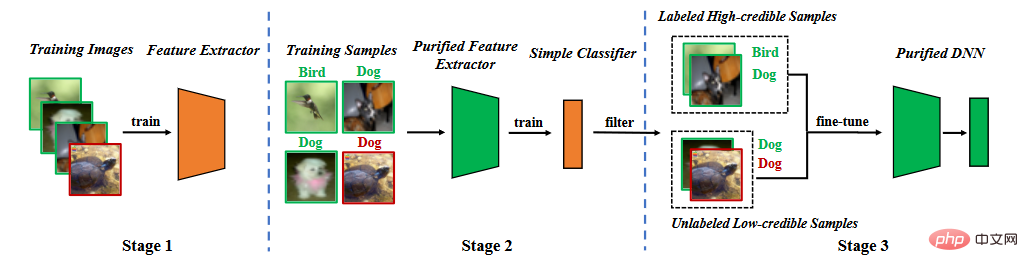 Method flow chart
Method flow chart
4.1 Learning feature extractor
We use the training data set to learn the model. The parameters of the model include two parts, one is the parameters of the backbone model and the other is the parameters of the fully connected layer. We utilize self-supervised learning to optimize the parameters of the backbone model.
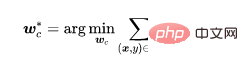
where is the self-supervised loss (for example, NT-Xent in SimCLR (Chen et al, 2020)). Through the previous analysis, we can Know that it is difficult for feature extractors to learn backdoor features.
4.2 Label noise learning filtered samples
Once the feature extractor is trained, we fix the parameters of the feature extractor and use the training data set to further learn the fully connected layer parameters ,
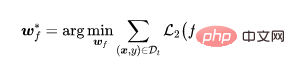
where is the supervised learning loss (for example, cross entropy loss (cross entropy)).
Although such a segmentation process will make it difficult for the model to learn backdoors, it has two problems. First, compared with methods trained through supervised learning, since the learned feature extractor is frozen in the second stage, there will be a certain decrease in the accuracy of predicting clean samples. Secondly, when poisoned label attacks occur, poisoned samples will serve as "outliers", further hindering the second stage of learning. These two issues indicate that we need to remove poisoned samples and retrain or fine-tune the entire model.
We need to determine whether the sample has a backdoor. We believe that it is difficult for the model to learn from backdoor samples, so we use confidence as a distinction indicator. High-confidence samples are clean samples, while low-confidence samples are poisoned samples. Through experiments, it is found that the model trained using symmetric cross-entropy loss has a large loss gap between the two samples, so the degree of discrimination is high, as shown in the figure below.
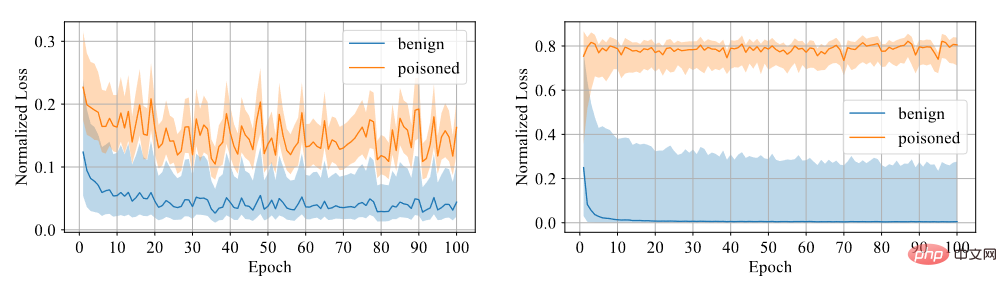
Comparison between symmetric cross entropy loss and cross entropy loss
Therefore, We train a fully connected layer with a fixed feature extractor using symmetric cross-entropy loss, and filter the data set into high-confidence data and low-confidence data by the size of the confidence.
4.3 Semi-supervised fine-tuning
First, we remove labels of low-confidence data. We use semi-supervised learning to fine-tune the entire model.

where is the semi-supervised loss (e.g., the loss function in MixMatch (Berthelot et al, 2019)).
Semi-supervised fine-tuning can not only prevent the model from learning backdoor triggers, but also make the model perform well on clean data sets.
5 Experiment
5.1 Datasets and benchmarks
The article is based on two classic benchmark data All defenses are evaluated on the set, including CIFAR-10 (Krizhevsky, 2009) and ImageNet (Deng et al., 2009) (a subset). The article uses the ResNet18 model (He et al., 2016)
The article studies all defense methods to defend against four typical attacks, namely badnets (Gu et al., 2019), mixed strategy Backdoor attack (blended) (Chen et al, 2017), WaNet (Nguyen & Tran, 2021) and clean label attack with adversary perturbation (label-consistent) (Turner et al, 2019).

Backdoor attack example picture
5.2 Experimental results
The judgment standard of the experiment is that BA is the judgment accuracy of clean samples and ASR is the judgment accuracy of poisoned samples.
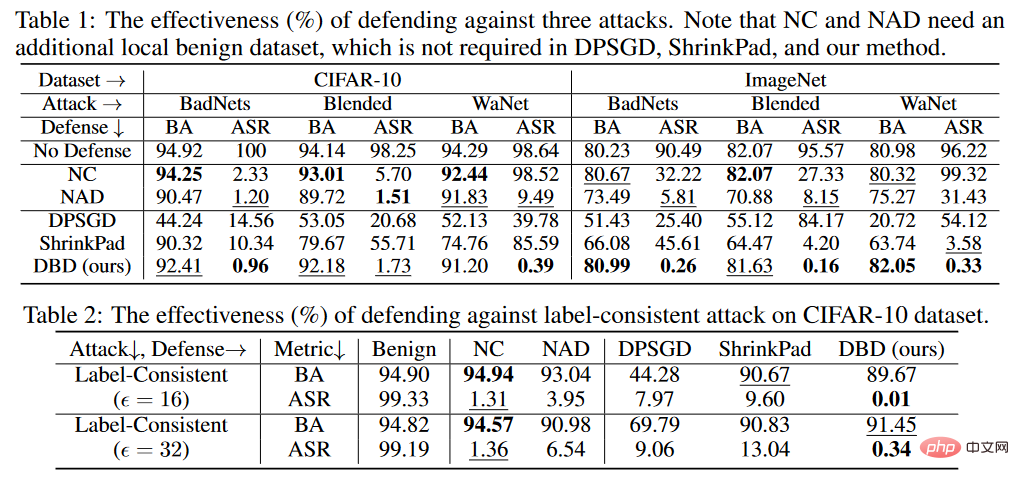
Backdoor defense comparison results
As shown in the table above, DBD significantly outperforms defenses with the same requirements (i.e. DPSGD and ShrinkPad) against all attacks. In all cases, DBD outperforms DPSGD by 20% more BA and 5% lower ASR. The ASR of the DBD model is less than 2% in all cases (less than 0.5% in most cases), verifying that DBD can successfully prevent the creation of hidden backdoors. DBD is compared with two other methods, namely NC and NAD, both of which require the defender to have a clean local data set.
As shown in the table above, NC and NAD outperform DPSGD and ShrinkPad because they employ additional information from local clean data sets. In particular, although NAD and NC use additional information, DBD is better than them. Especially on the ImageNet dataset, NC has limited effect on reducing ASR. In comparison, DBD achieves the smallest ASR, while DBD's BA is the highest or second highest in almost all cases. In addition, compared with the model without any defense training, the BA dropped by less than 2% when defending against poisoning tag attacks. On relatively larger datasets, DBD is even better, as all baseline methods become less effective. These results verify the effectiveness of DBD.
5.3 Ablation experiment
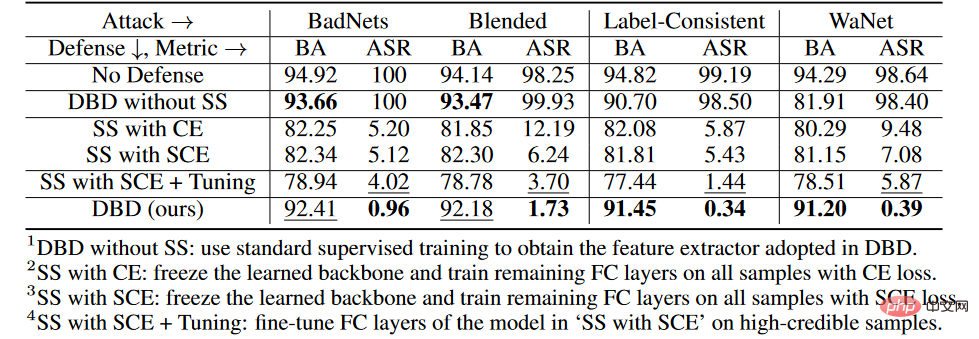
##Ablation experiment at each stage
On the CIFAR-10 dataset, we compared the proposed DBD and its four variants, including
1. DBD without SS will generate backbones from self-supervised learning Replace with the backbone trained in a supervised manner and keep other parts unchanged
2.SS with CE, freeze the backbone learned through self-supervised learning, and run on all training samples Cross-entropy loss for training the remaining fully connected layers
3.SS with SCE, similar to the second variant, but trained using a symmetric cross-entropy loss.
4.SS with SCE Tuning, further fine-tuning the fully connected layer on high-confidence samples filtered by the third variant.
As shown in the table above, decoupling the original end-to-end supervised training process is effective in preventing the creation of hidden backdoors. Furthermore, the second and third DBD variants are compared to verify the effectiveness of SCE loss in defending against poison tag backdoor attacks. In addition, the ASR and BA of the fourth DBD mutation are lower than those of the third DBD mutation. This phenomenon is due to the removal of low-confidence samples. This suggests that employing useful information from low-confidence samples while reducing their side effects is important for defense.
5.4 Resistance to potential adaptive attacks
If attackers know the existence of DBD, they may design adaptive attacks . If the attacker can know the model structure used by the defender, they can design an adaptive attack by optimizing the trigger pattern so that the poisoned sample remains in a new cluster after self-supervised learning, as shown below:
Attack setting
For a classification problem, let represent the clean samples that need to be poisoned, represent the samples with the original label, and be A trained backbone. Given a predetermined generator of poisoned images by an attacker, the adaptive attack aims to optimize the triggering pattern by minimizing the distance between poisoned images while maximizing the distance between the center of the poisoned image and the center of a cluster of benign images with different labels. distance, that is.
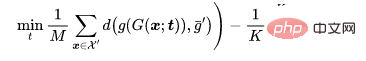
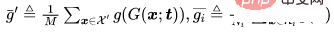 is a distance determination.
is a distance determination.
Experimental results
The BA of the adaptive attack without defense is 94.96%, and the ASR is 99.70%. However, DBD's defense results were BA93.21% and ASR1.02%. In other words, DBD is resistant to such adaptive attacks.
6 Summary
The mechanism of the poisoning-based backdoor attack is to establish a potential connection between the trigger pattern and the target label during the training process. This paper reveals that this connection is primarily due to end-to-end supervised training paradigm learning. Based on this understanding, this article proposes a backdoor defense method based on decoupling. A large number of experiments have verified that DBD defense can reduce backdoor threats while maintaining high accuracy in predicting benign samples.
The above is the detailed content of Backdoor defense method of segmented backdoor training: DBD. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
The familiar open source large language models such as Llama3 launched by Meta, Mistral and Mixtral models launched by MistralAI, and Jamba launched by AI21 Lab have become competitors of OpenAI. In most cases, users need to fine-tune these open source models based on their own data to fully unleash the model's potential. It is not difficult to fine-tune a large language model (such as Mistral) compared to a small one using Q-Learning on a single GPU, but efficient fine-tuning of a large model like Llama370b or Mixtral has remained a challenge until now. Therefore, Philipp Sch, technical director of HuggingFace
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 The model will evolve after merging, and directly win SOTA! Transformer author's new entrepreneurial achievements are popular
Mar 26, 2024 am 11:30 AM
The model will evolve after merging, and directly win SOTA! Transformer author's new entrepreneurial achievements are popular
Mar 26, 2024 am 11:30 AM
Use the ready-made models on Huggingface to "save up" - can you directly combine them to create new powerful models? ! The large Japanese model company sakana.ai was very creative (it was the company founded by one of the "8 Transformers") and came up with such a clever way to evolve and merge models. Not only does the method automatically generate new base models, but its performance is anything but: they achieved state-of-the-art results on relevant benchmarks using a large model of Japanese mathematics with 7 billion parameters, surpassing the 70 billion parameter Llama- 2 and other previous models. Most importantly, deriving such a model does not require any gradient training and therefore requires significantly less computing resources. NVIDIA scientist JimFan praised it after reading it
