
 Technology peripherals
AI
An open environment solution that solves shortcomings such as the Batch Norm layer
Technology peripherals
AI
An open environment solution that solves shortcomings such as the Batch Norm layer
An open environment solution that solves shortcomings such as the Batch Norm layer

The Test-Time Adaptation (TTA) method guides the model to perform rapid unsupervised/self-supervised learning during the test phase. It is currently a powerful and effective tool for improving the out-of-distribution generalization ability of deep models. However, in dynamic open scenarios, insufficient stability is still a major shortcoming of existing TTA methods, which seriously hinders their practical deployment. To this end, a research team from South China University of Technology, Tencent AI Lab and the National University of Singapore analyzed the reasons why the existing TTA method is unstable in dynamic scenarios from a unified perspective, and pointed out that the normalization layer that relies on Batch is leading to instability. One of the key reasons for stability, in addition, some samples with noise/large-scale gradients in the test data stream can easily optimize the model to a degenerate trivial solution. Based on this, a sharpness-sensitive and reliable test-time entropy minimization method SAR is further proposed to achieve stable and efficient test-time model online migration and generalization in dynamic open scenarios. This work has been selected into ICLR 2023 Oral (Top-5% among accepted papers).

- ##Paper title: Towards Stable Test-time Adaptation in Dynamic Wild World
- Paper address: https://openreview.net/forum?id=g2YraF75Tj
- Open source code: https://github.com/ mr-eggplant/SAR
Traditional machine learning technology usually learns on a large amount of training data collected in advance, and then fixes the model for inference prediction. This paradigm often achieves very good performance when the test and training data come from the same data distribution. However, in practical applications, the distribution of test data can easily deviate from the distribution of the original training data (distribution shift). For example, when collecting test data: 1) Weather changes cause the image to contain rain, snow, and fog occlusion; 2) The image is blurred due to improper shooting, or the image contains noise due to sensor degradation; 3) The model was trained based on data collected in northern cities, but was deployed to southern cities. The above situations are very common, but they are often fatal for deep models, because their performance may drop significantly in these scenarios, seriously restricting their use in the real world (especially high-risk applications such as autonomous driving) widespread deployment.
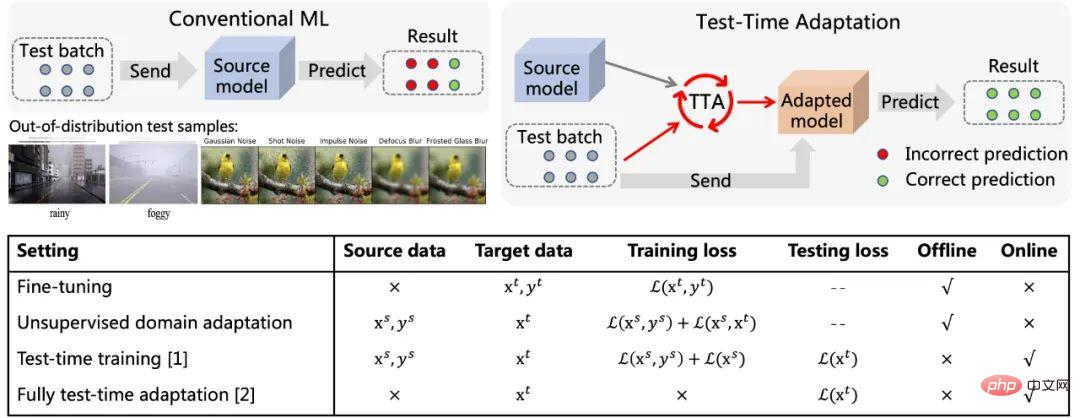
Figure 1 Schematic diagram of Test-Time Adaptation (refer to [5]) and its relationship with the current Comparison of method characteristics
is different from the traditional machine learning paradigm, as shown in Figure 1. After the test sample arrives, Test-Time Adaptation (TTA) is first based on the The data is used to fine-tune the model in a self-supervised or unsupervised manner, and then the updated model is used to make the final prediction. Typical self/unsupervised learning goals include: rotation prediction, contrastive learning, entropy minimization, etc. These methods all exhibit excellent out-of-distribution generalization performance. Compared with the traditional Fine-Tuning and Unsupervised Domain Adaptation methods, Test-Time Adaptation can achieve online migration, which is more efficient and more universal. In addition, the complete test-time adaptation method [2] can be adapted to any pre-trained model without the need for original training data or interference with the original training process of the model. The above advantages have greatly enhanced the practical versatility of the TTA method. Coupled with its excellent performance, TTA has become an extremely hot research direction in migration, generalization and other related fields. Although existing TTA methods have shown great potential in out-of-distribution generalization, this excellent performance is often obtained under some specific test conditions, such as The samples of the data stream within a period of time all come from the same distribution shift type, the true category distribution of the test samples is uniform and random, and each time a mini-batch sample is required before adaptation can be performed. But in fact, these potential assumptions above are difficult to always be satisfied in the real open world. In practice, the test data stream may arrive in any combination, and ideally the model should not make any assumptions about the arriving form of the test data stream. As shown in Figure 2, it is entirely possible for the test data flow to encounter: (a) samples come from different distribution offsets (ie, mixed sample offsets); (b) sample batch size is very small ( Even 1);(c)The true category distribution of samples within a period of time is uneven and changes dynamically. This article refers to the TTA in the above scenario as Wild TTA. Unfortunately, existing TTA methods often appear fragile and unstable in these wild scenarios, with limited migration performance and may even damage the performance of the original model. Therefore, if we want to truly realize the large-scale and in-depth application deployment of the TTA method in actual scenarios, solving the Wild TTA problem is an inevitable and important part. Figure 2 Dynamic open scene during adaptation during model testing This article analyzes the reasons why TTA fails in many Wild scenarios from a unified perspective, and then provides solutions. 1. Why is Wild TTA unstable? (1) Batch Normalization (BN) is one of the key reasons for TTA instability in dynamic scenarios: Existing TTA methods are usually established Based on the adaptive BN statistics, the test data is used to calculate the mean and standard deviation in the BN layer. However, in the three actual dynamic scenarios, the statistical estimation accuracy within the BN layer will be biased, resulting in unstable TTA: To further verify the above analysis, this article considers 3 widely used models (equipped with different BatchLayerGroup Norm), based on two representative TTA methods (TTT [1] and Tent [2]). Analytical verification. The final conclusion is: Batch-independent Norm layers (Group and Layer Norm) circumvent the limitations of Batch Norm to a certain extent, and are more suitable for executing TTA in dynamic open scenarios, and their stability is also higher. Therefore, this article will also conduct method design based on the model equipped with GroupLayer Norm. Why Wild Test-Time Adaptation?
Solution ideas and technical solutions

Figure 3 Different methods and models (different normalization layers) in the mixed distribution partial Move down the performance

##Figure 4 Different methods and models ( Different normalization layers) performance under different batch sizes. The shaded area in the figure represents the standard deviation of the model's performance. The standard deviation of ResNet50-BN and ResNet50-GN is too small and is not significant in the figure (the same as the figure below)

Figure 5 Performance of different methods and models (different normalization layers) under online imbalanced label distribution shift Performance, the larger the Imbalance Ratio on the horizontal axis in the figure, the more serious the label imbalance is.
(2) Online entropy minimization is easy to optimize the model To the degenerate trivial solution, that is, predict any sample to the same class: According to Figure 6 (a) and (b), when the distribution shift is serious (level 5), the online adaptation process suddenly appears Model degradation and collapse phenomenon, that is, all samples (with different real categories) are predicted to the same class; at the same time, the norm of the model gradient increases rapidly before and after the model collapses and then drops to almost 0, see Figure 6 (c), side explanation may It is some large-scale/noise gradient that destroys the model parameters, causing the model to collapse.

Figure 6 Analysis of failure cases in entropy minimization during online testing
2. Sharpness-sensitive and reliable test-time entropy minimization method
In order to alleviate the above model degradation problem, this paper proposes Sharpness-aware and Reliable Entropy Minimization Method (SAR) during testing. It alleviates this problem in two ways: 1) Reliable entropy minimization removes some samples that produce large/noisy gradients from the model adaptive update; 2) Model sharpness optimization makes the model insensitive to certain noise gradients generated in the remaining samples. The specific details are explained as follows:
Reliable entropy minimization: Based on Entropy, an alternative judgment index for gradient selection is established, and high-entropy samples (including those in Figure 6 (d) Samples from areas 1 and 2) are excluded from model adaptation and do not participate in model update:

where x represents the test sample, Θ represents the model parameters, 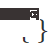 represents the indicator function,
represents the indicator function,  represents the entropy of the sample prediction result,
represents the entropy of the sample prediction result,  represents the super parameter. Only if
represents the super parameter. Only if 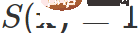
# the sample will participate in the backpropagation calculation.
Sharpness-sensitive entropy optimization: Samples filtered by a reliable sample selection mechanism cannot avoid still containing Figure 6 (d) Region 4 samples, these samples may produce noise/large gradients that continue to interfere with the model. To this end, this article considers optimizing the model to a flat minimum so that it can be insensitive to model updates caused by noise gradients, that is, it will not affect its original model performance. The optimization goal is:
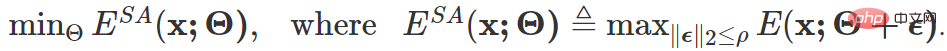
The final gradient update form of the above target is as follows:
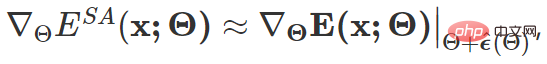
Among them 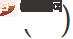 is inspired by SAM [4] and is obtained by approximate solution through first-order Taylor expansion. For details, please refer to the original text and code of this paper .
is inspired by SAM [4] and is obtained by approximate solution through first-order Taylor expansion. For details, please refer to the original text and code of this paper .
At this point, the overall optimization goal of this article is:
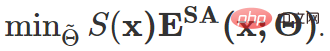
# #In addition, in order to prevent the possibility that the above scheme may still fail under extreme conditions, a model recovery strategy is further introduced: through mobile monitoring of whether the model has degraded or collapsed, it is decided to restore the original values of the model update parameters at the necessary moment.
Experimental evaluationPerformance comparison in dynamic open scenarios
SAR is based on the above three A dynamic open scenario, namely a) mixed distribution shift, b) single sample adaptation and c) online imbalanced class distribution shift, was experimentally verified on the ImageNet-C data set, and the results are shown in Tables 1, 2, and 3 . SAR achieves remarkable results in all three scenarios, especially in scenarios b) and c). SAR uses VitBase as the base model, and its accuracy exceeds the current SOTA method EATA by nearly 10%.
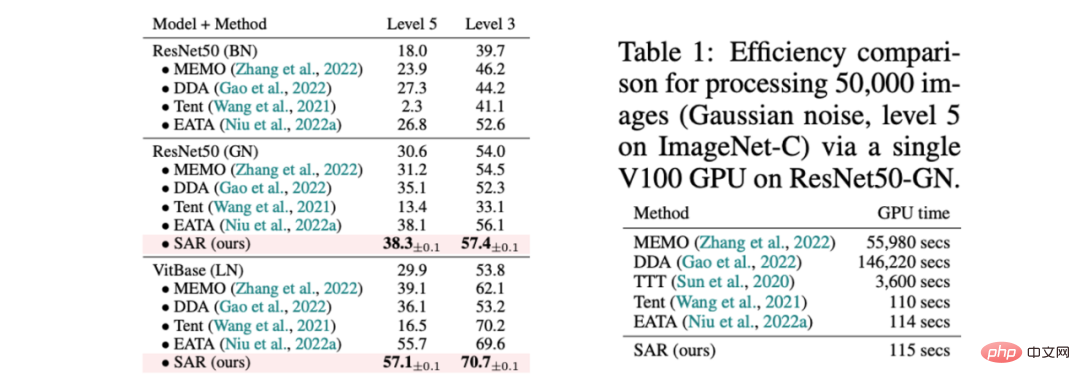
Table 1 SAR mixed with existing methods for 15 corruption types in ImageNet-C Performance comparison in scenarios, corresponding to dynamic scenario (a); and efficiency comparison with existing methods
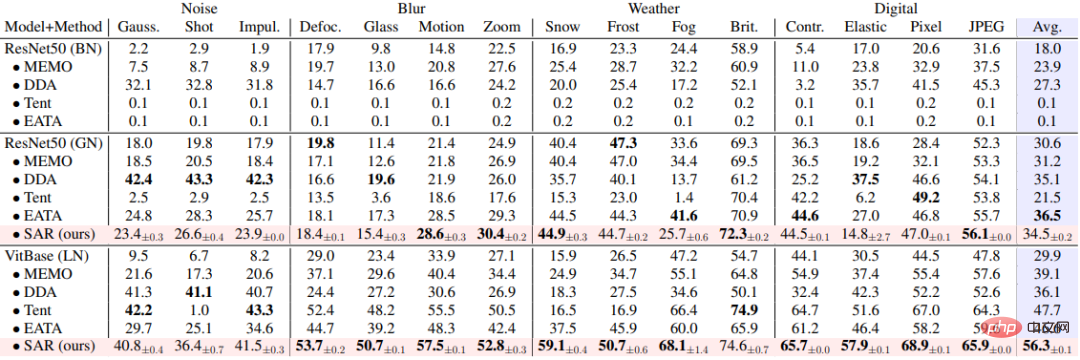
##Table 2 Performance comparison of SAR and existing methods in single sample adaptation scenario on ImageNet-C, corresponding to dynamic scenario (b)
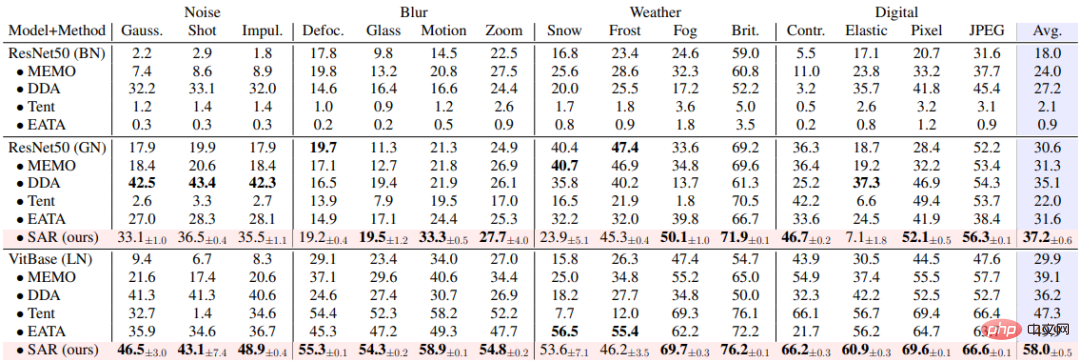
Table 3 Performance comparison between SAR and existing methods in the online non-balanced class distribution shift scenario on ImageNet-C, corresponding Dynamic scene (c)
Ablation experiment
and gradient clipping method Comparison: Gradient clipping is a simple and direct method to avoid large gradients from affecting model updates (or even causing collapse). Here is a comparison with two variants of gradient clipping (ie: by value or by norm). As shown in the figure below, gradient clipping is very sensitive to the selection of the gradient clipping threshold δ. A smaller δ is equivalent to the result of the model not being updated, and a larger δ is difficult to avoid model collapse. In contrast, SAR does not require a complicated hyperparameter filtering process and performs significantly better than gradient clipping.
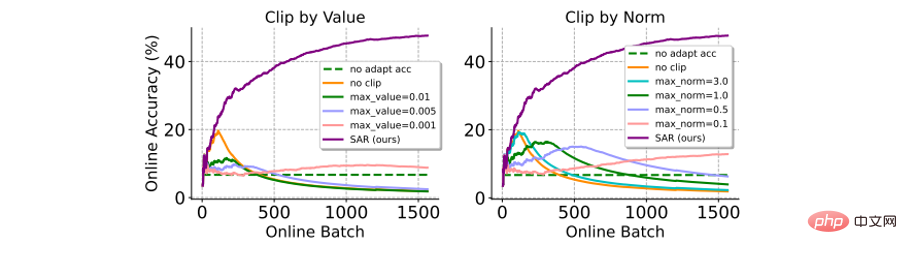
Figure 7 with gradient clipping method in ImageNet-C (shot nosise, level 5 ) on online imbalanced label distribution shift scenario. The accuracy is calculated online based on all previous test samples
The impact of different modules on algorithm performance: as shown in the table below , the synergy of different modules of SAR effectively improves the adaptive stability of the model during testing in dynamic open scenarios.

Table 4 SAR online imbalanced label distribution on ImageNet-C (level 5) Ablation experiment in offset scenario Loss surface sharpness visualization: The result of visualizing the loss function by adding perturbation to the model weight is shown in the figure below. Among them, SAR has a larger area (dark blue area) within the lowest loss contour than Tent, indicating that the solution obtained by SAR is flatter, more robust to noise/larger gradients, and has stronger anti-interference ability. 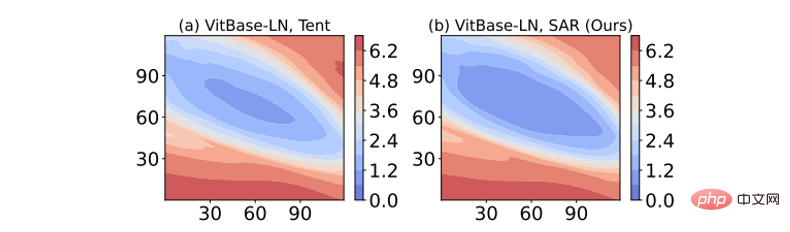
Figure 8 Entropy loss surface visualization
Conclusion
This article is dedicated to solving the problem of adaptive instability during model online testing in dynamic open scenarios. To this end, this article first analyzes the reasons why existing methods fail in actual dynamic scenarios from a unified perspective, and designs complete experiments to conduct in-depth verification. Based on these analyses, this paper finally proposes a sharpness-sensitive and reliable test-time entropy minimization method, which achieves stable and efficient model online test-time adaptation by suppressing the impact of certain test samples with large gradients/noise on model updates. .
The above is the detailed content of An open environment solution that solves shortcomings such as the Batch Norm layer. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
This AI-assisted programming tool has unearthed a large number of useful AI-assisted programming tools in this stage of rapid AI development. AI-assisted programming tools can improve development efficiency, improve code quality, and reduce bug rates. They are important assistants in the modern software development process. Today Dayao will share with you 4 AI-assisted programming tools (and all support C# language). I hope it will be helpful to everyone. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot is an AI coding assistant that helps you write code faster and with less effort, so you can focus more on problem solving and collaboration. Git
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
 Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
On March 3, 2022, less than a month after the birth of the world's first AI programmer Devin, the NLP team of Princeton University developed an open source AI programmer SWE-agent. It leverages the GPT-4 model to automatically resolve issues in GitHub repositories. SWE-agent's performance on the SWE-bench test set is similar to Devin, taking an average of 93 seconds and solving 12.29% of the problems. By interacting with a dedicated terminal, SWE-agent can open and search file contents, use automatic syntax checking, edit specific lines, and write and execute tests. (Note: The above content is a slight adjustment of the original content, but the key information in the original text is retained and does not exceed the specified word limit.) SWE-A
 Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Go language development mobile application tutorial As the mobile application market continues to boom, more and more developers are beginning to explore how to use Go language to develop mobile applications. As a simple and efficient programming language, Go language has also shown strong potential in mobile application development. This article will introduce in detail how to use Go language to develop mobile applications, and attach specific code examples to help readers get started quickly and start developing their own mobile applications. 1. Preparation Before starting, we need to prepare the development environment and tools. head
 Which Linux distribution is best for Android development?
Mar 14, 2024 pm 12:30 PM
Which Linux distribution is best for Android development?
Mar 14, 2024 pm 12:30 PM
Android development is a busy and exciting job, and choosing a suitable Linux distribution for development is particularly important. Among the many Linux distributions, which one is most suitable for Android development? This article will explore this issue from several aspects and give specific code examples. First, let’s take a look at several currently popular Linux distributions: Ubuntu, Fedora, Debian, CentOS, etc. They all have their own advantages and characteristics.
 Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
In September 23, the paper "DeepModelFusion:ASurvey" was published by the National University of Defense Technology, JD.com and Beijing Institute of Technology. Deep model fusion/merging is an emerging technology that combines the parameters or predictions of multiple deep learning models into a single model. It combines the capabilities of different models to compensate for the biases and errors of individual models for better performance. Deep model fusion on large-scale deep learning models (such as LLM and basic models) faces some challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. This article divides existing deep model fusion methods into four categories: (1) "Pattern connection", which connects solutions in the weight space through a loss-reducing path to obtain a better initial model fusion
 Exploring Go language front-end technology: a new vision for front-end development
Mar 28, 2024 pm 01:06 PM
Exploring Go language front-end technology: a new vision for front-end development
Mar 28, 2024 pm 01:06 PM
As a fast and efficient programming language, Go language is widely popular in the field of back-end development. However, few people associate Go language with front-end development. In fact, using Go language for front-end development can not only improve efficiency, but also bring new horizons to developers. This article will explore the possibility of using the Go language for front-end development and provide specific code examples to help readers better understand this area. In traditional front-end development, JavaScript, HTML, and CSS are often used to build user interfaces
