
 Technology peripherals
AI
'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'
Technology peripherals
AI
'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'
'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'

What if artificial intelligence could read your imagination and turn the images in your mind into reality?

Although this sounds a bit cyberpunk. But a recently published paper has caused a stir in the AI circle.
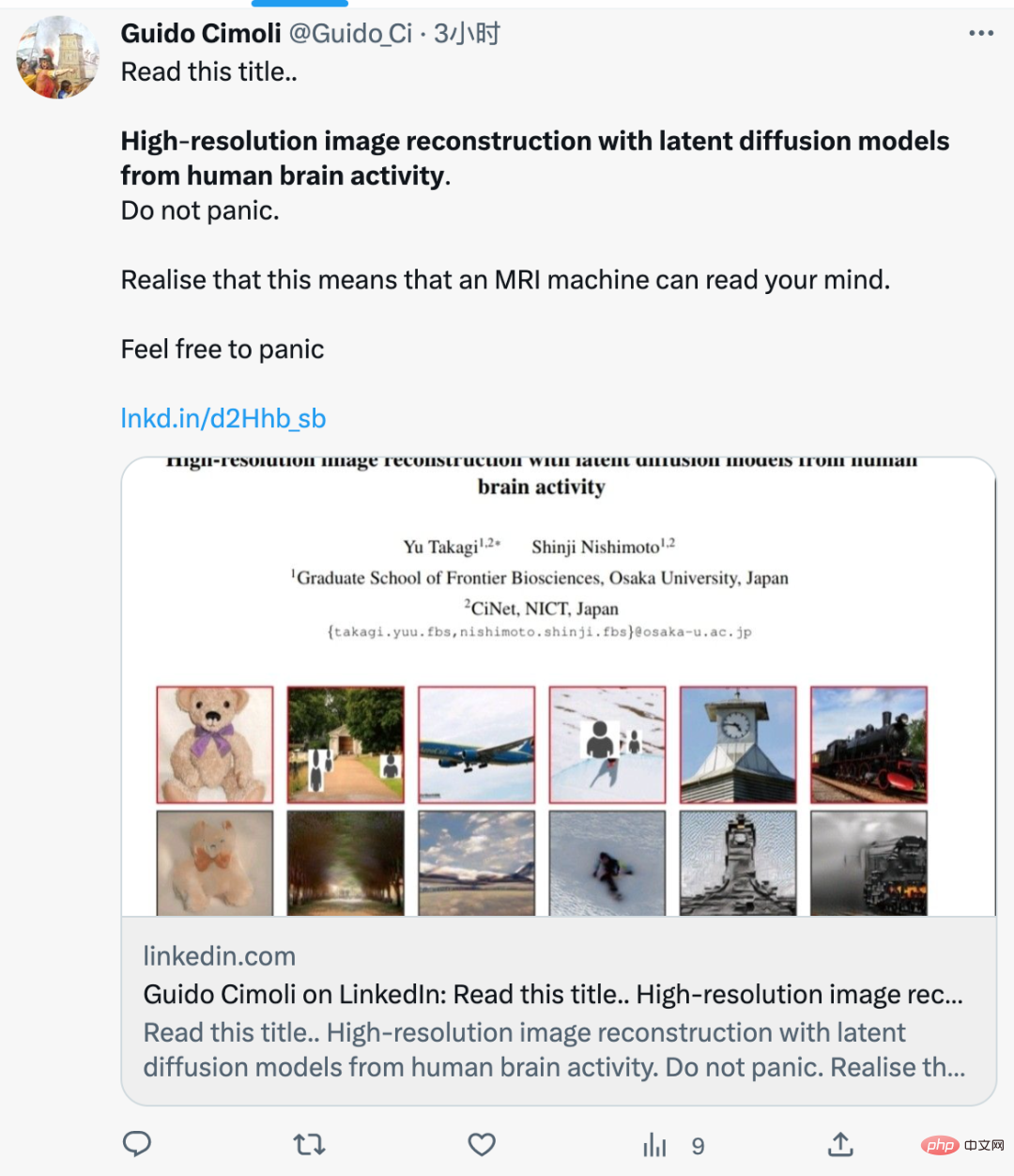
This paper found that they used the recently very popular Stable Diffusion to reconstruct high-resolution brain activity High-efficiency, high-precision images. The authors wrote that unlike previous studies, they did not need to train or fine-tune an artificial intelligence model to create these images.

- ##Paper address: https://www .biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- Webpage address: https://sites.google.com/view/ stablediffusion-with-brain/
How did they do it?
In this study, the authors used Stable Diffusion to reconstruct images of human brain activity obtained through functional magnetic resonance imaging (fMRI). The author also stated that it is also helpful to understand the mechanism of the latent diffusion model by studying different components of brain-related functions (such as the latent vector of image Z, etc.).
This paper has also been accepted by CVPR 2023.
The main contributions of this study include:
- Demonstrating that its simple framework can generate data from brain activities with high semantic fidelity Reconstruct high-resolution (512×512) images in medium without the need to train or fine-tune complex deep generative models, as shown in the figure below;
- by mapping specific components to different brains area, this study quantitatively explains each component of LDM from a neuroscience perspective;
- This study objectively explains how the text-to-image conversion process implemented by LDM combines conditional text expressions semantic information while maintaining the appearance of the original image.
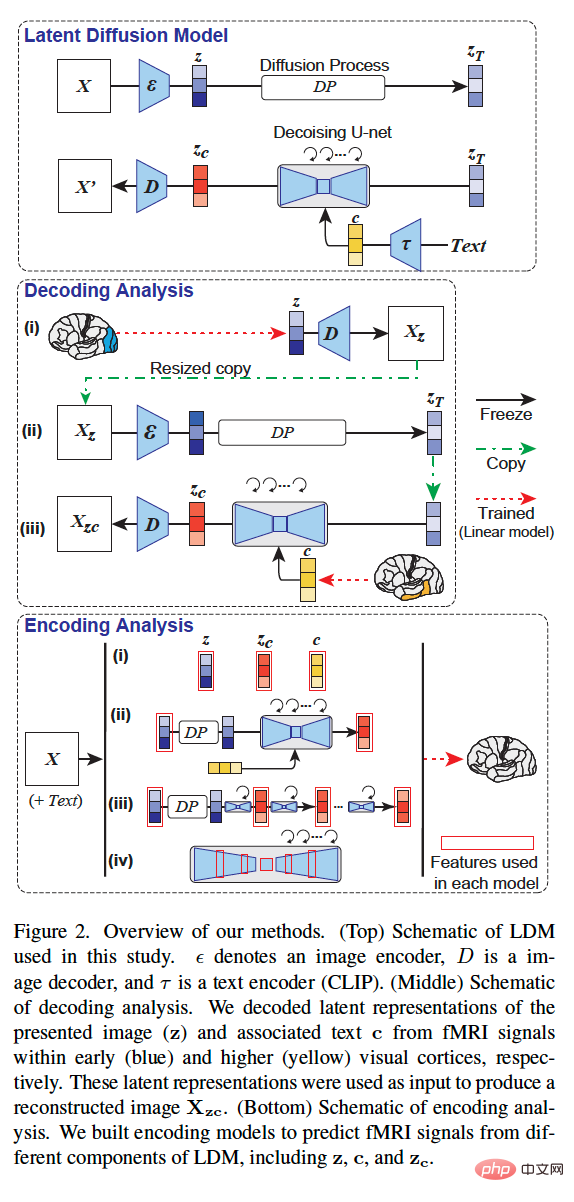
The overall methodology of this study is shown in Figure 2 below. Figure 2 (top) is a schematic diagram of the LDM used in this study, where ε represents the image encoder, D represents the image decoder, and τ represents the text encoder (CLIP).
Figure 2 (middle) is a schematic diagram of the decoding analysis of this study. We decoded the underlying representation of the presented image (z) and associated text c from fMRI signals within early (blue) and advanced (yellow) visual cortex, respectively. These latent representations are used as input to generate the reconstructed image X_zc.
Figure 2 (bottom) is a schematic diagram of the coding analysis of this study. We constructed encoding models to predict fMRI signals from different components of LDM, including z, c, and z_c.
I won’t introduce too much about Stable Diffusion here, I believe many people are familiar with it.
ResultsLet’s take a look at the visual reconstruction results of this study.
Decoding
Figure 3 below shows the visual reconstruction results of a subject (subj01). We generated five images for each test image and selected the image with the highest PSM. On the one hand, the image reconstructed using only z is visually consistent with the original image but fails to capture its semantic content. On the other hand, images reconstructed with only c produce images with high semantic fidelity but are visually inconsistent. Finally, using z_c reconstructed images can produce high-resolution images with high semantic fidelity.

Figure 4 shows the reconstruction of the same image by all testers (all images were generated with z_c) . Overall, the reconstruction quality across testers was stable and accurate.

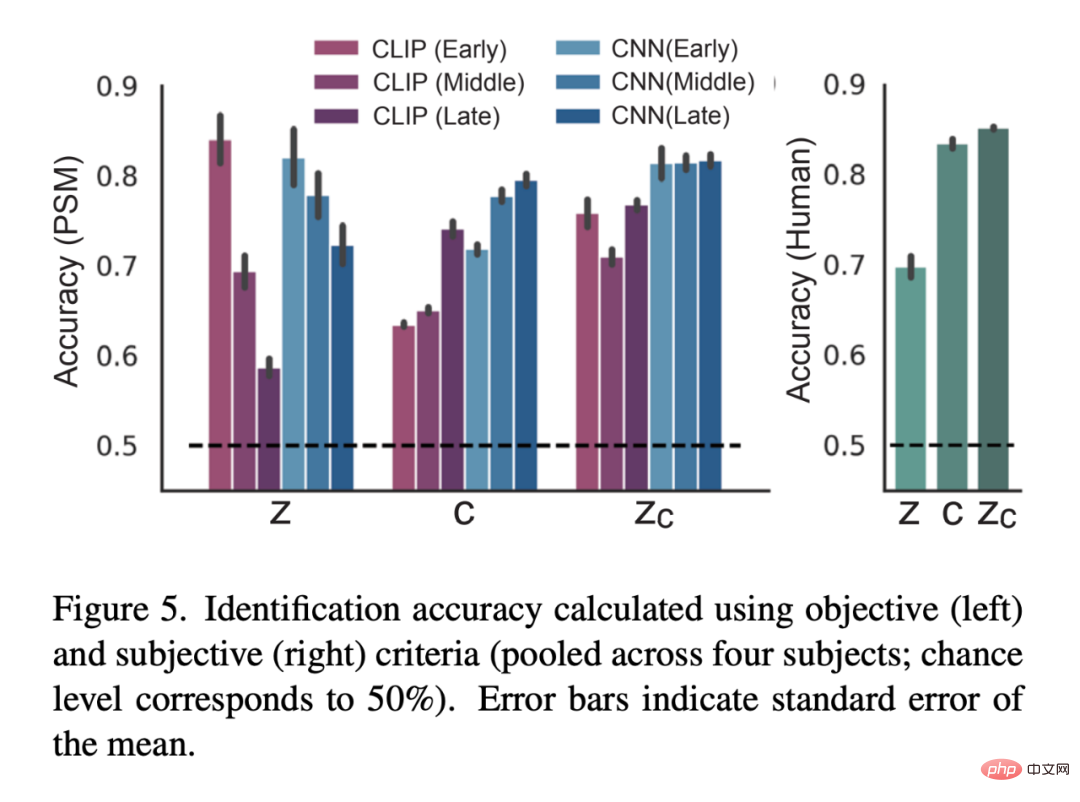
Figure 5 is the result of the quantitative evaluation:
Coding model
## Figure 6 shows the coding model pair related to LDM Prediction accuracy of three latent images: z, the latent image of the original image; c, the latent image of the image text annotation; and z_c, the noisy latent image representation of z after a cross-attention back-diffusion process with c.
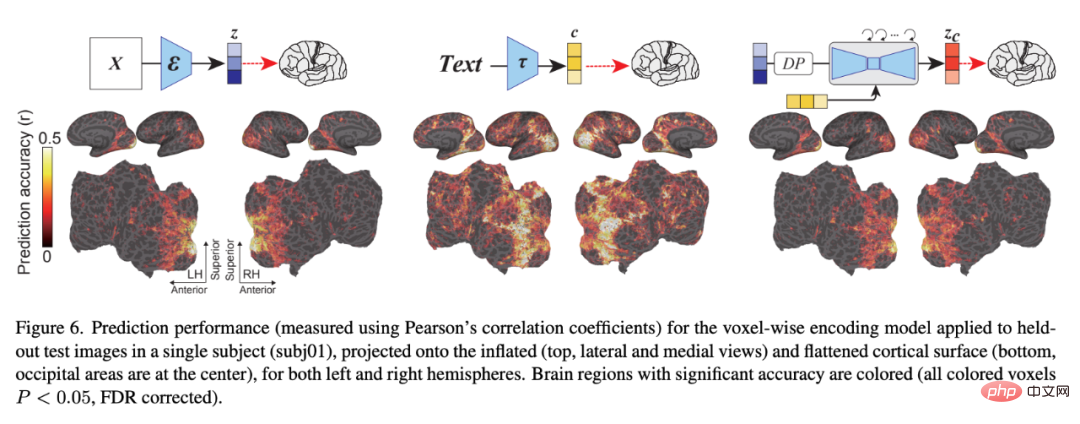
Figure 7 shows that z predicts voxel activity throughout the cortex better than z_c when a small amount of noise is added. Interestingly, z_c predicts voxel activity in high visual cortex better than z when increasing the noise level, indicating that the semantic content of the image is gradually emphasized.

How does the underlying representation of added noise change during the iterative denoising process? Figure 8 shows that in the early stages of the denoising process, the z-signal dominates the prediction of the fMRI signal. At the intermediate stage of the denoising process, z_c predicts activity within high visual cortex much better than z, indicating that most of the semantic content emerges at this stage. The results show how LDM refines and generates images from noise.
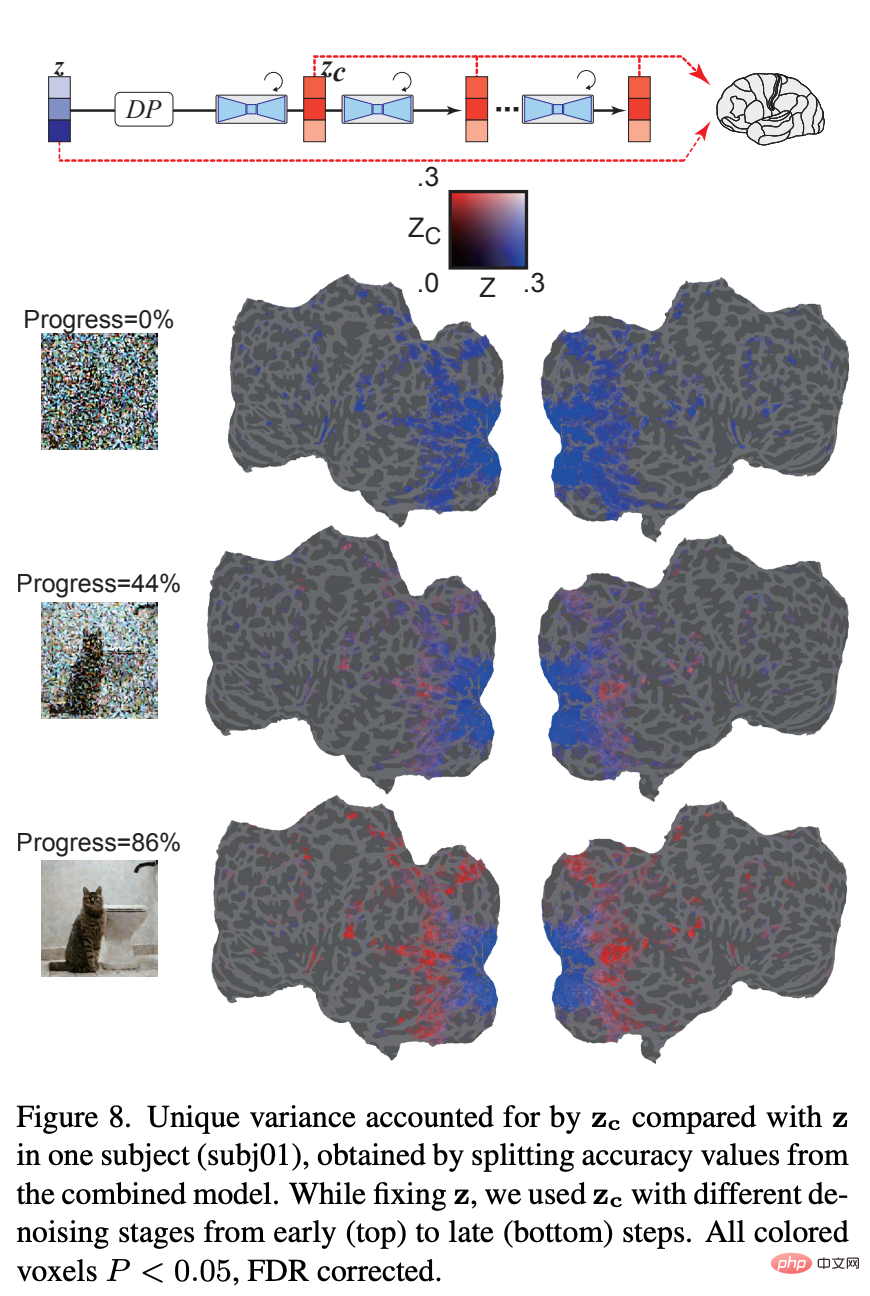
Finally, the researchers explored what information each layer of U-Net is processing. Figure 9 shows the results of different steps of the denoising process (early, mid, late) and the encoding model of different layers of U-Net. In the early stages of the denoising process, U-Net's bottleneck layer (orange) yields the highest prediction performance across the entire cortex. However, as denoising proceeds, the early layers of U-Net (blue) predict activity within early visual cortex, while the bottleneck layers shift to superior predictive power for higher visual cortex.
For more research details, please view the original paper.
The above is the detailed content of 'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
Windows are never one to neglect aesthetics. From the bucolic green fields of XP to the blue swirling design of Windows 11, default desktop wallpapers have been a source of user delight for years. With Windows Spotlight, you now have direct access to beautiful, awe-inspiring images for your lock screen and desktop wallpaper every day. Unfortunately, these images don't hang out. If you have fallen in love with one of the Windows spotlight images, then you will want to know how to download them so that you can keep them as your background for a while. Here's everything you need to know. What is WindowsSpotlight? Window Spotlight is an automatic wallpaper updater available from Personalization > in the Settings app
 A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
Large-scale language models (LLMs) have demonstrated compelling capabilities in many important tasks, including natural language understanding, language generation, and complex reasoning, and have had a profound impact on society. However, these outstanding capabilities require significant training resources (shown in the left image) and long inference times (shown in the right image). Therefore, researchers need to develop effective technical means to solve their efficiency problems. In addition, as can be seen from the right side of the figure, some efficient LLMs (LanguageModels) such as Mistral-7B have been successfully used in the design and deployment of LLMs. These efficient LLMs can significantly reduce inference memory while maintaining similar accuracy to LLaMA1-33B
 How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
With the continuous development of artificial intelligence technology, image semantic segmentation technology has become a popular research direction in the field of image analysis. In image semantic segmentation, we segment different areas in an image and classify each area to achieve a comprehensive understanding of the image. Python is a well-known programming language. Its powerful data analysis and data visualization capabilities make it the first choice in the field of artificial intelligence technology research. This article will introduce how to use image semantic segmentation technology in Python. 1. Prerequisite knowledge is deepening
 Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
3nm process, performance surpasses H100! Recently, foreign media DigiTimes broke the news that Nvidia is developing the next-generation GPU, the B100, code-named "Blackwell". It is said that as a product for artificial intelligence (AI) and high-performance computing (HPC) applications, the B100 will use TSMC's 3nm process process, as well as more complex multi-chip module (MCM) design, and will appear in the fourth quarter of 2024. For Nvidia, which monopolizes more than 80% of the artificial intelligence GPU market, it can use the B100 to strike while the iron is hot and further attack challengers such as AMD and Intel in this wave of AI deployment. According to NVIDIA estimates, by 2027, the output value of this field is expected to reach approximately
 How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
Those who have to work with image files on a daily basis often have to resize them to fit the needs of their projects and jobs. However, if you have too many images to process, resizing them individually can consume a lot of time and effort. In this case, a tool like PowerToys can come in handy to, among other things, batch resize image files using its image resizer utility. Here's how to set up your Image Resizer settings and start batch resizing images with PowerToys. How to Batch Resize Images with PowerToys PowerToys is an all-in-one program with a variety of utilities and features to help you speed up your daily tasks. One of its utilities is images
 iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
With the iOS 17 Photos app, Apple makes it easier to crop photos to your specifications. Read on to learn how. Previously in iOS 16, cropping an image in the Photos app involved several steps: Tap the editing interface, select the crop tool, and then adjust the crop using a pinch-to-zoom gesture or dragging the corners of the crop tool. In iOS 17, Apple has thankfully simplified this process so that when you zoom in on any selected photo in your Photos library, a new Crop button automatically appears in the upper right corner of the screen. Clicking on it will bring up the full cropping interface with the zoom level of your choice, so you can crop to the part of the image you like, rotate the image, invert the image, or apply screen ratio, or use markers
 The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! Written by 7 Chinese researchers at Microsoft, it has 119 pages. It starts from two types of multi-modal large model research directions that have been completed and are still at the forefront, and comprehensively summarizes five specific research topics: visual understanding and visual generation. The multi-modal large-model multi-modal agent supported by the unified visual model LLM focuses on a phenomenon: the multi-modal basic model has moved from specialized to universal. Ps. This is why the author directly drew an image of Doraemon at the beginning of the paper. Who should read this review (report)? In the original words of Microsoft: As long as you are interested in learning the basic knowledge and latest progress of multi-modal basic models, whether you are a professional researcher or a student, this content is very suitable for you to come together.
 I2V-Adapter from the SD community: no configuration required, plug and play, perfectly compatible with Tusheng video plug-in
Jan 15, 2024 pm 07:48 PM
I2V-Adapter from the SD community: no configuration required, plug and play, perfectly compatible with Tusheng video plug-in
Jan 15, 2024 pm 07:48 PM
The image-to-video generation (I2V) task is a challenge in the field of computer vision that aims to convert static images into dynamic videos. The difficulty of this task is to extract and generate dynamic information in the temporal dimension from a single image while maintaining the authenticity and visual coherence of the image content. Existing I2V methods often require complex model architectures and large amounts of training data to achieve this goal. Recently, a new research result "I2V-Adapter: AGeneralImage-to-VideoAdapter for VideoDiffusionModels" led by Kuaishou was released. This research introduces an innovative image-to-video conversion method and proposes a lightweight adapter module, i.e.
