
 Technology peripherals
AI
Microsoft's open source fine-tuned instruction set helps develop a home version of GPT-4, supporting bilingual generation in Chinese and English.
Technology peripherals
AI
Microsoft's open source fine-tuned instruction set helps develop a home version of GPT-4, supporting bilingual generation in Chinese and English.
Microsoft's open source fine-tuned instruction set helps develop a home version of GPT-4, supporting bilingual generation in Chinese and English.

"Instruction" is a key factor in the breakthrough progress of the ChatGPT model, which can make the output of the language model more consistent with "human preferences."
But the annotation of instructions requires a lot of manpower. Even with open source language models, it is difficult for academic institutions and small companies with insufficient funds to train their own ChatGPT.
Recently, Microsoft researchers used the previously proposed Self-Instruct technology, for the first time tried to use the GPT-4 model to automatically generate a language model Required trim instruction data.

Paper link: https://arxiv.org/pdf/2304.03277.pdf
Code link: https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
Experimental results on the LLaMA model based on the Meta open source show that 52,000 English and Chinese instruction-following data generated by GPT-4 outperform instructions generated by previous state-of-the-art models in new tasks Data, the researchers also collected feedback and comparison data from GPT-4 for comprehensive evaluation and reward model training.
Training data
Data collection
The researchers reused the Alpaca model released by Stanford University 52,000 instructions are used, each of which describes the task that the model should perform, and follows the same prompting strategy as Alpaca, taking into account the situation with and without input, as the optional context or input of the task; use Large language models output answers to instructions.

In the Alpaca dataset, the output is generated using GPT-3.5 (text-davinci-003), but in In this paper, the researchers chose to use GPT-4 to generate data, including the following four data sets:
1. English Instruction-Following Data: For each of the 52,000 instructions collected in Alpaca, an English GPT-4 answer is provided.

Future work is to follow an iterative process and build a new data set using GPT-4 and self-instruct .
2. Chinese Instruction-Following Data: Use ChatGPT to translate 52,000 instructions into Chinese, and ask GPT-4 to answer these instructions in Chinese, and This builds a Chinese instruction-following model based on LLaMA and studies the cross-language generalization ability of instruction tuning.
3. Comparison Data: Requires GPT-4 to provide a rating from 1 to 10 for its own reply, and evaluate GPT-4, GPT The responses of the three models -3.5 and OPT-IML are scored to train the reward model.
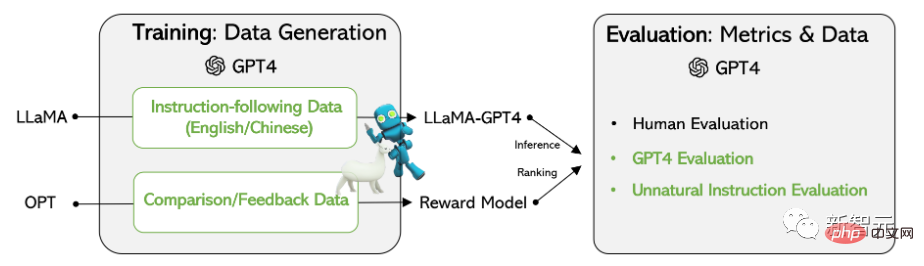
4. The answer to the unnatural instruction: The answer to GPT-4 is 68,000 Decoded on a dataset of (instruction, input, output) triples, this subset is used to quantify the difference in scale between GPT-4 and the instruction-tuned model.
Statistics
The researchers compared the English output reply sets of GPT-4 and GPT-3.5: for each output, the root verb and the direct-object noun were extracted, and in each The frequency of unique verb-noun pairs is calculated over the output sets.
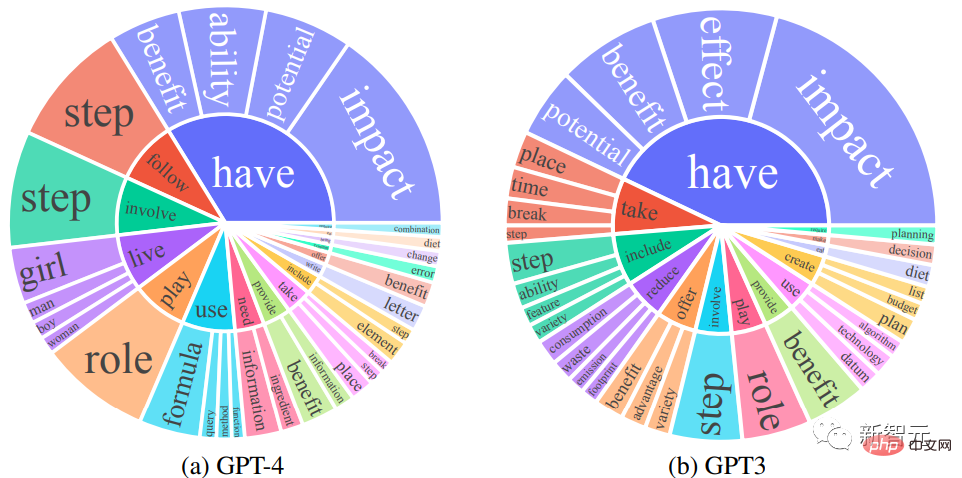
Verb-noun pairs with frequency higher than 10
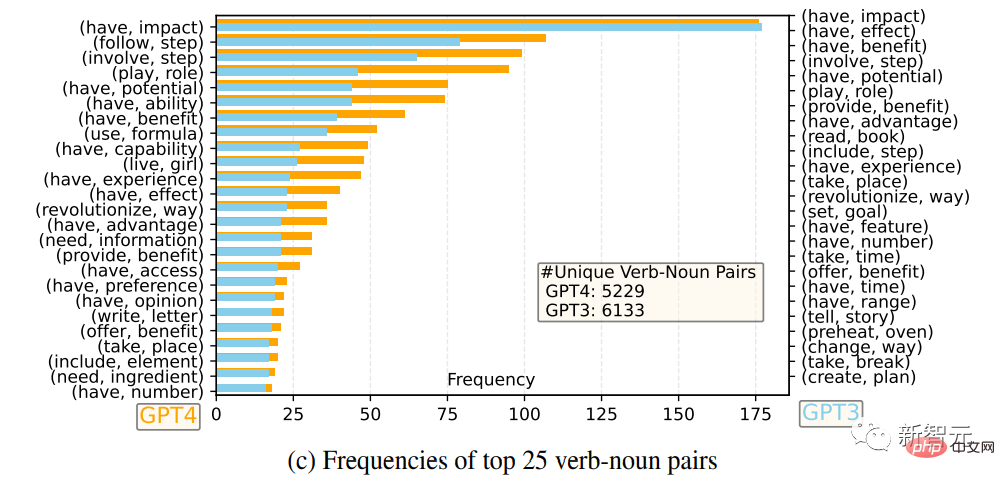
The 25 most frequent verb-noun pairs
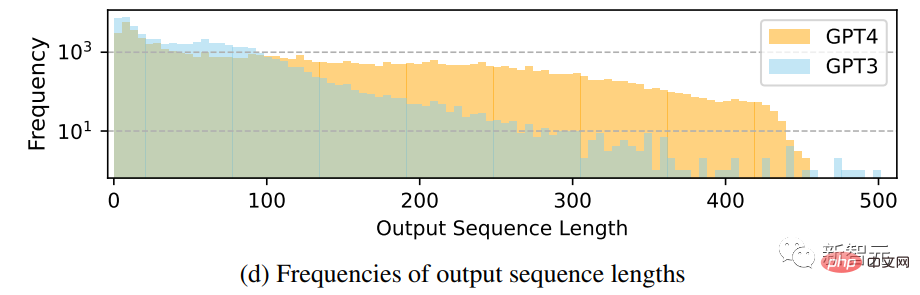
Comparison of frequency distribution of output sequence length
It can be seen that GPT-4 tends to generate more data than GPT-3.5 For long sequences, the long tail phenomenon of GPT-3.5 data in Alpaca is more obvious than the output distribution of GPT-4. This may be because the Alpaca data set involves an iterative data collection process, and similar instruction instances are removed in each iteration. This is not available in current one-time data generation.
Although the process is simple, the instruction-following data generated by GPT-4 exhibits more powerful alignment performance.
Instruction tuning language model
Self-Instruct tuning
Researchers based on LLaMA After 7B checkpoint supervised fine-tuning, two models were trained: LLaMA-GPT4 was trained on 52,000 English instruction-following data generated by GPT-4; LLaMA-GPT4-CN was trained on 52,000 Chinese items generated by GPT-4 Trained on instruction-following data.
Two models were used to study the data quality of GPT-4 and the cross-language generalization properties of instruction-tuned LLMs in one language.
Reward model
Reinforcement Learning from Human Feedback (RLHF) aims to Align LLM behavior with human preferences to make the language model’s output more useful to humans.
A key component of RLHF is reward modeling. The problem can be formulated as a regression task to predict the reward score given the prompt and reply. This approach usually requires large-scale Comparative data, that is, comparing the responses of two models to the same cue.
Existing open source models, such as Alpaca, Vicuna and Dolly, do not use RLHF due to the high cost of labeling comparison data, and recent research shows that GPT-4 can Identify and fix your own errors and accurately judge the quality of your responses.
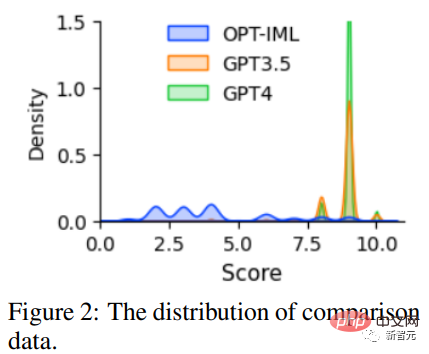
To promote research on RLHF, researchers created comparative data using GPT-4; to evaluate data quality, The researchers trained a reward model based on OPT 1.3B to score different replies: for one prompt and K replies, GPT-4 provides a score between 1 and 10 for each reply.
Experimental Results
Evaluating the performance of self-instruct tuned models for never-before-seen tasks on GPT-4 data remains a difficult task .
Since the main goal is to evaluate the model's ability to understand and comply with various task instructions, to achieve this, the researchers utilized three types of evaluations, confirmed by the results of the study, "Using GPT-4 generated data is an effective method for tuning large language model instructions compared to data automatically generated by other machines.
Human Evaluation
#To evaluate the quality of large language model alignment after tuning this instruction, the researchers followed previously proposed alignment criteria: If An assistant is helpful, honest, and harmless (HHH) if it is aligned with human evaluation criteria, which are also widely used to evaluate the degree to which AI systems are consistent with human values.
Helpfulness: Whether it can help humans achieve their goals, a model that can accurately answer questions is helpful.
Honesty: Whether to provide true information and express its uncertainty when necessary to avoid misleading human users, a model that provides false information is dishonest.
Harmlessness: If it does not cause harm to humans, a model that generates hate speech or promotes violence is not harmless.
Based on the HHH alignment criteria, the researchers used the crowdsourcing platform Amazon Mechanical Turk to conduct manual evaluation of the model generation results.
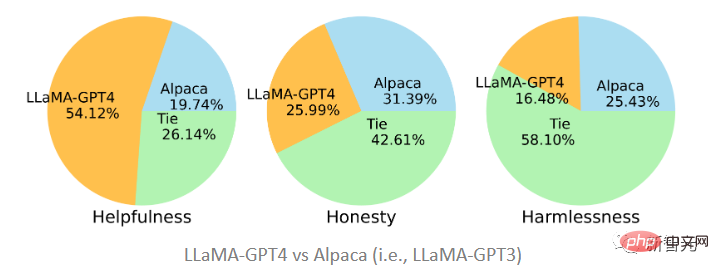
The two models proposed in the article were fine-tuned on the data generated by GPT-4 and GPT-3 respectively. It can be seen that LLaMA-GPT4 is much better than Alpaca (19.74%) fine-tuned on GPT-3 in terms of helpfulness with a proportion of 51.2%. However, under the standards of honesty and harmlessness, it is basically a tie. GPT-3 is slightly better.
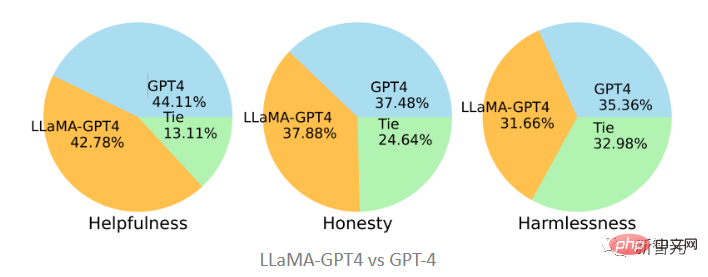
When compared with the original GPT-4, it can be found that the two are quite consistent in the three standards. That is, the performance of LLaMA after tuning the GPT-4 instructions is similar to the original GPT-4.
GPT-4 automatic evaluation
Inspired by Vicuna, researchers also chose to use GPT-4 for evaluation The quality of the responses generated by different chatbot models to 80 unseen questions. Responses were collected from the LLaMA-GPT-4(7B) and GPT-4 models, and answers from other models were obtained from previous research, and then asked GPT-4 scores the reply quality between two models on a scale from 1 to 10 and compares the results with other strong competing models (ChatGPT and GPT-4).
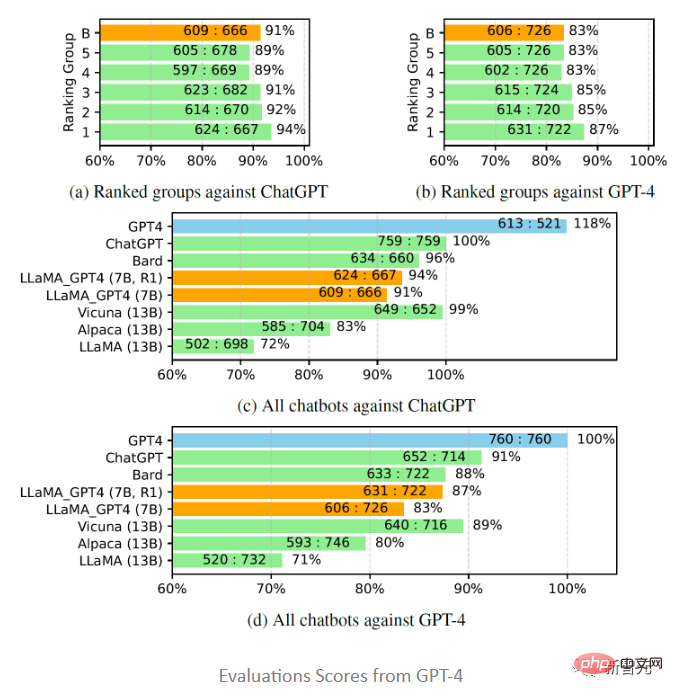
The evaluation results show that feedback data and reward models are effective in improving the performance of LLaMA; using GPT-4 LLaMA performs instruction tuning and often performs better than text-davinci-003 tuning (i.e. Alpaca) and no tuning (i.e. LLaMA); the performance of 7B LLaMA GPT4 exceeds that of 13B Alpaca and LLaMA, but is different from GPT-4 Compared with other large commercial chatbots, there is still a gap.
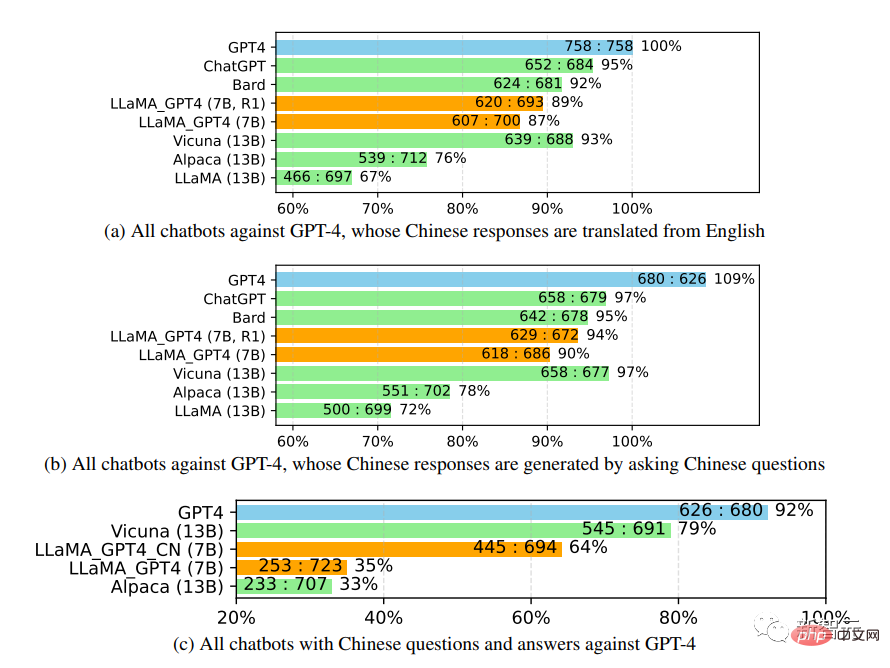
When further studying the performance of the Chinese chatbot, GPT-4 was first used to translate the chatbot’s questions from English as well. Into Chinese, using GPT-4 to obtain the answer, two interesting observations can be obtained:
1. It can be found that the relative score indicators of GPT-4 evaluation are quite consistent. , both in terms of different adversary models (i.e. ChatGPT or GPT-4) and languages (i.e. English or Chinese).
2. Only for the results of GPT-4, the translated replies performed better than the Chinese-generated replies, probably because of GPT-4 It is trained in a richer English corpus than Chinese, so it has stronger English instruction-following capabilities.
Unnatural Instruction Evaluation
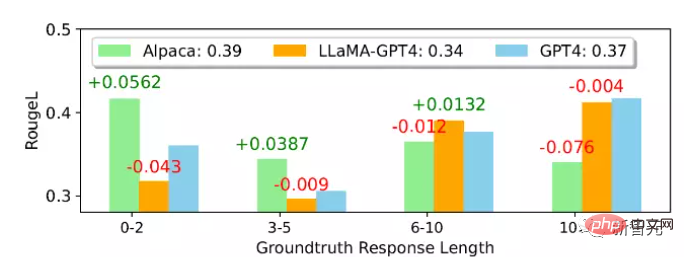
From the average In terms of ROUGE-L score, Alpaca is better than LLaMA-GPT 4 and GPT-4. It can be noticed that LLaMA-GPT4 and GPT4 gradually perform better when the ground truth reply length increases, and finally perform better when the length exceeds 4. High performance means instructions can be followed better when the scene is more creative.
In different subsets, the behavior of LLaMA-GPT4 and GPT-4 is almost the same; when the sequence length is short, both LLaMA-GPT4 and GPT-4 can generate simple Replies that provide basic factual answers but add extra words to make the reply more chat-like may result in a lower ROUGE-L score.
The above is the detailed content of Microsoft's open source fine-tuned instruction set helps develop a home version of GPT-4, supporting bilingual generation in Chinese and English.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
The top exchanges include: 1. Binance, the world's largest trading volume, supports 600 currencies, and the spot handling fee is 0.1%; 2. OKX, a balanced platform, supports 708 trading pairs, and the perpetual contract handling fee is 0.05%; 3. Gate.io, covers 2700 small currencies, and the spot handling fee is 0.1%-0.3%; 4. Coinbase, the US compliance benchmark, the spot handling fee is 0.5%; 5. Kraken, the top security, and regular reserve audit.
 Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Exchanges play a vital role in today's cryptocurrency market. They are not only platforms for investors to trade, but also important sources of market liquidity and price discovery. The world's largest virtual currency exchanges rank among the top ten, and these exchanges are not only far ahead in trading volume, but also have their own advantages in user experience, security and innovative services. Exchanges that top the list usually have a large user base and extensive market influence, and their trading volume and asset types are often difficult to reach by other exchanges.
 Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Assets launches a new AI intelligent trading system to lead the new era of trading efficiency! The well-known comprehensive trading platform Global Assets officially launched its AI intelligent trading system, aiming to use technological innovation to improve global trading efficiency, optimize user experience, and contribute to the construction of a safe and reliable global trading platform. The move marks a key step for global assets in the field of smart finance, further consolidating its global market leadership. Opening a new era of technology-driven and open intelligent trading. Against the backdrop of in-depth development of digitalization and intelligence, the trading market's dependence on technology is increasing. The AI intelligent trading system launched by Global Assets integrates cutting-edge technologies such as big data analysis, machine learning and blockchain, and is committed to providing users with intelligent and automated trading services to effectively reduce human factors.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
After ETH upgrade, novices should adopt the following strategies to avoid losses: 1. Do their homework and understand the basic knowledge and upgrade content of ETH; 2. Control positions, test the waters in small amounts and diversify investment; 3. Make a trading plan, clarify goals and set stop loss points; 4. Profil rationally and avoid emotional decision-making; 5. Choose a formal and reliable trading platform; 6. Consider long-term holding to avoid the impact of short-term fluctuations.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
