
 Technology peripherals
AI
The NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!
Technology peripherals
AI
The NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!
The NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!

3D reconstruction of 2D images has always been a highlight in the CV field.
Different models have been developed to try to overcome this problem.
Today, scholars from the National University of Singapore jointly published a paper and developed a new framework, Anything-3D, to solve this long-standing problem.

##Paper address: https://arxiv.org/pdf/2304.10261.pdf
With the help of Meta’s “divide everything” model, Anything-3D directly makes any divided object come alive.

In addition, by using the Zero-1-to-3 model, you can get corgis from different angles.
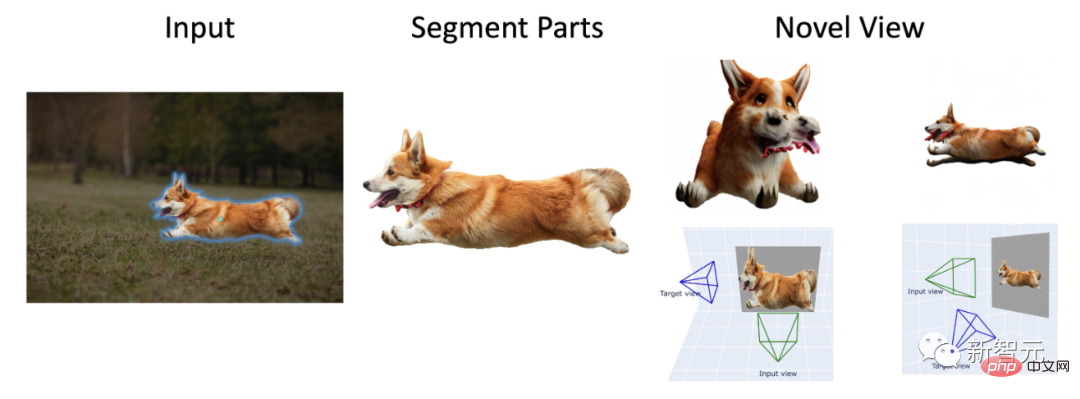
# Even 3D reconstruction of characters can be performed.

It can be said that this one is a real breakthrough.
Anything-3D!In the real world, various objects and environments are diverse and complex. Therefore, without restrictions, 3D reconstruction from a single RGB image faces many difficulties.
Here, researchers from the National University of Singapore combined a series of visual language models and SAM (Segment-Anything) object segmentation models to generate a multi-functional and reliable system— —Anything-3D.
The purpose is to complete the task of 3D reconstruction under the condition of a single perspective.
They use the BLIP model to generate texture descriptions, use the SAM model to extract objects in the image, and then use the text → image diffusion model Stable Diffusion to place the objects into Nerf (neural radiation field) .
In subsequent experiments, Anything-3D demonstrated its powerful three-dimensional reconstruction capabilities. Not only is it accurate, it is also applicable to a wide range of applications.
Anything-3D has obvious effects in solving the limitations of existing methods. The researchers demonstrated the advantages of this new framework through testing and evaluation on various data sets.

In the picture above, we can see, "The picture of Corgi sticking out his tongue and running for thousands of miles" and "The picture of the silver-winged goddess committing herself to a luxury car" , and "Image of a brown cow in a field wearing a blue rope on its head."
This is a preliminary demonstration that the Anything-3D framework can skillfully restore single-view images taken in any environment into a 3D form and generate textures.
This new framework consistently provides highly accurate results despite large changes in camera perspective and object properties.
You must know that reconstructing 3D objects from 2D images is the core of the subject in the field of computer vision, and has great implications for robotics, autonomous driving, augmented reality, virtual reality, and three-dimensional printing. Influence.
Although some good progress has been made in recent years, the task of single-image object reconstruction in an unstructured environment is still a very attractive problem that needs to be solved urgently. .
Currently, researchers are tasked with generating a three-dimensional representation of one or more objects from a single two-dimensional image, including point clouds, grids, or volume representations.
However, this problem is not fundamentally true.
It is impossible to unambiguously determine the three-dimensional structure of an object due to the inherent ambiguity produced by two-dimensional projection.
Coupled with the huge differences in shape, size, texture and appearance, reconstructing objects in their natural environment is very complex. In addition, objects in real-world images are often occluded, which hinders accurate reconstruction of occluded parts.
At the same time, variables such as lighting and shadows can also greatly affect the appearance of objects, and differences in angle and distance can also cause obvious changes in the two-dimensional projection.
Enough about the difficulties, Anything-3D is ready to play.
In the paper, the researchers introduced in detail this groundbreaking system framework, which integrates the visual language model and the object segmentation model to easily turn 2D objects into 3D of.
In this way, a system with powerful functions and strong adaptability becomes. Single view reconstruction? Easy.
Combining the two models, the researchers say, it is possible to retrieve and determine the three-dimensional texture and geometry of a given image.
Anything-3D uses the BLIP model (Bootstrapping language-image model) to pre-train the text description of the image, and then uses the SAM model to identify the distribution area of the object.
Next, use the segmented objects and text descriptions to perform the 3D reconstruction task.
In other words, this paper uses a pre-trained 2D text→image diffusion model to perform 3D synthesis of images. In addition, the researchers used fractional distillation to train a Nerf specifically for images.
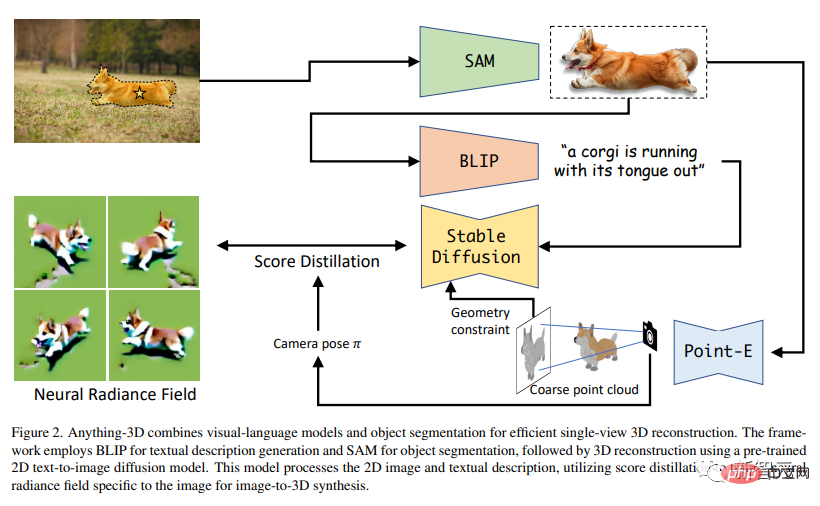
The above figure is the entire process of generating 3D images. The upper left corner is the 2D original image. It first goes through SAM to segment the corgi, then goes through BLIP to generate a text description, and then uses fractional distillation to create a Nerf.
Through rigorous experiments on different data sets, the researchers demonstrated the effectiveness and adaptability of this approach, while outperforming in accuracy, robustness, and generalization capabilities. existing methods.
The researchers also conducted a comprehensive and in-depth analysis of existing challenges in the reconstruction of 3D objects in natural environments, and explored how the new framework can solve such problems.
Ultimately, by integrating the zero-distance vision and language understanding capabilities in the basic model, the new framework can reconstruct objects from various real-world images and generate accurate, complex, and Widely applicable 3D representation.
It can be said that Anything-3D is a major breakthrough in the field of 3D object reconstruction.
Here are more examples:

## Porsche, bright orange excavator crane, little yellow rubber duck with green hat
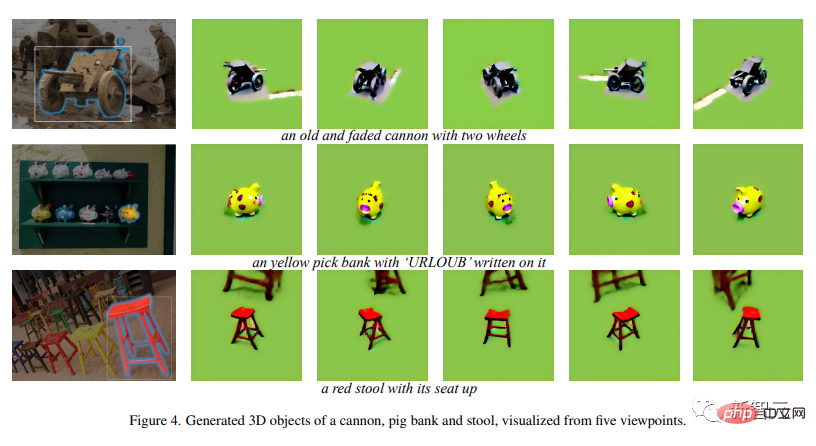
# The cannon faded by the tears of the times, the cute little piggy Mini piggy bank, cinnabar red four-legged high stool
This new framework interactively identifies regions in single-view images and represents them in 2D with optimized text embeddings object. Ultimately, a 3D-aware fractional distillation model is used to efficiently generate high-quality 3D objects.In summary, Anything-3D demonstrates the potential of reconstructing natural 3D objects from single-view images. The researchers said that the quality of the 3D reconstruction of the new framework can be more perfect, and the researchers are constantly working hard to improve the quality of the generation. In addition, the researchers said that quantitative evaluations of 3D datasets such as new view synthesis and error reconstruction are not currently provided, but these will be included in future iterations of work. Meanwhile, the researchers’ ultimate goal is to expand this framework to accommodate more practical situations, including object recovery under sparse views. Wang is currently a tenure-track assistant professor in the ECE Department of the National University of Singapore (NUS). Before joining the National University of Singapore, he was an Assistant Professor in the CS Department of Stevens Institute of Technology. Prior to joining Stevens, I served as a postdoc in Professor Thomas Huang's image formation group at the Beckman Institute at the University of Illinois at Urbana-Champaign. Wang received his PhD from the Computer Vision Laboratory of the Ecole Polytechnique Fédérale de Lausanne (EPFL), supervised by Professor Pascal Fua, and received his Bachelor of Science with First Class Honors from the Department of Computer Science of the Hong Kong Polytechnic University in 2010 Bachelor of Science. About the author

The above is the detailed content of The NUS Chinese team releases the latest model: single-view 3D reconstruction, fast and accurate!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
This AI-assisted programming tool has unearthed a large number of useful AI-assisted programming tools in this stage of rapid AI development. AI-assisted programming tools can improve development efficiency, improve code quality, and reduce bug rates. They are important assistants in the modern software development process. Today Dayao will share with you 4 AI-assisted programming tools (and all support C# language). I hope it will be helpful to everyone. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot is an AI coding assistant that helps you write code faster and with less effort, so you can focus more on problem solving and collaboration. Git
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
On March 3, 2022, less than a month after the birth of the world's first AI programmer Devin, the NLP team of Princeton University developed an open source AI programmer SWE-agent. It leverages the GPT-4 model to automatically resolve issues in GitHub repositories. SWE-agent's performance on the SWE-bench test set is similar to Devin, taking an average of 93 seconds and solving 12.29% of the problems. By interacting with a dedicated terminal, SWE-agent can open and search file contents, use automatic syntax checking, edit specific lines, and write and execute tests. (Note: The above content is a slight adjustment of the original content, but the key information in the original text is retained and does not exceed the specified word limit.) SWE-A
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Go language development mobile application tutorial As the mobile application market continues to boom, more and more developers are beginning to explore how to use Go language to develop mobile applications. As a simple and efficient programming language, Go language has also shown strong potential in mobile application development. This article will introduce in detail how to use Go language to develop mobile applications, and attach specific code examples to help readers get started quickly and start developing their own mobile applications. 1. Preparation Before starting, we need to prepare the development environment and tools. head
 Summary of the five most popular Go language libraries: essential tools for development
Feb 22, 2024 pm 02:33 PM
Summary of the five most popular Go language libraries: essential tools for development
Feb 22, 2024 pm 02:33 PM
Summary of the five most popular Go language libraries: essential tools for development, requiring specific code examples. Since its birth, the Go language has received widespread attention and application. As an emerging efficient and concise programming language, Go's rapid development is inseparable from the support of rich open source libraries. This article will introduce the five most popular Go language libraries. These libraries play a vital role in Go development and provide developers with powerful functions and a convenient development experience. At the same time, in order to better understand the uses and functions of these libraries, we will explain them with specific code examples.
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
 Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Apr 02, 2024 am 11:31 AM
Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Apr 02, 2024 am 11:31 AM
Point cloud, as a collection of points, is expected to bring about a change in acquiring and generating three-dimensional (3D) surface information of objects through 3D reconstruction, industrial inspection and robot operation. The most challenging but essential process is point cloud registration, i.e. obtaining a spatial transformation that aligns and matches two point clouds obtained in two different coordinates. This review introduces the overview and basic principles of point cloud registration, systematically classifies and compares various methods, and solves the technical problems existing in point cloud registration, trying to provide academic researchers outside the field and Engineers provide guidance and facilitate discussions on a unified vision for point cloud registration. The general method of point cloud acquisition is divided into active and passive methods. The point cloud actively acquired by the sensor is the active method, and the point cloud is reconstructed later.
