
 Technology peripherals
AI
Deep learning giant DeepMind released a paper: urgently teaching AI models to 'become human' to offset the human extinction problem that may be caused by GPT-5.
Technology peripherals
AI
Deep learning giant DeepMind released a paper: urgently teaching AI models to 'become human' to offset the human extinction problem that may be caused by GPT-5.
Deep learning giant DeepMind released a paper: urgently teaching AI models to 'become human' to offset the human extinction problem that may be caused by GPT-5.

The emergence of GPT-4 has scared AI tycoons around the world. The open letter calling for the suspension of GPT-5 training has already been signed by 50,000 people.
OpenAI CEO Sam Altman predicts that within a few years, there will be a large number of different AI models spread around the world, each with its own intelligence and capabilities, and complying with different regulations. Code of ethics.

If only one in a thousand of these AIs goes rogue for some reason, then we humans, It will undoubtedly become fish on the chopping board.
In order to prevent us from being accidentally destroyed by AI, DeepMind gave the answer in a paper published in the Proceedings of the National Academy of Sciences (PNAS) on April 24th—— Use the perspective of political philosopher Rawls to teach AI how to behave.
Paper address: https://www.pnas.org/doi/10.1073/pnas.2213709120
How to teach AI Be a human being?
When faced with a choice, will AI choose to prioritize improving productivity, or choose to help those who need help most?
It is very important to shape the values of AI. We need to give it a value.
But the difficulty is that we humans cannot have a unified set of values internally. People in this world each have different backgrounds, resources and beliefs.
How to break it? Google researchers draw inspiration from philosophy.
Political philosopher John Rawls once proposed the concept of "The Veil of Ignorance" (VoI), which is a thought experiment aimed at group decision-making. , to achieve fairness to the greatest extent.

Generally speaking, human nature is self-interested, but when the "veil of ignorance" is applied to AI, people But they will give priority to fairness, regardless of whether it directly benefits themselves.
And, behind a “veil of ignorance,” they are more likely to choose AI that helps the most disadvantaged.
This enlightens us on how we can give AI a value in a way that is fair to all parties.
So, what exactly is the "veil of ignorance"?
Although the difficult question of what values should be given to AI has emerged in the past decade, the issue of how to make fair decisions has a long history.
In order to solve this problem, in 1970, the political philosopher John Rawls proposed the concept of "veil of ignorance".

The veil of ignorance (right) is a type of behavior that occurs when there are different opinions in a group (left) Methods of reaching consensus in decision-making
Rawls believes that when people choose principles of justice for a society, the premise should be that they do not know where they are in this society. .
Without this information, people cannot make decisions in a self-interested way but only in a way that is fair to everyone.
For example, when cutting a piece of cake at a birthday party, if you don’t know which piece you will get, you will try to make each piece the same size.
This method of concealing information has been widely used in the fields of psychology and political science, allowing people to reach a collective agreement from sentencing to taxation.
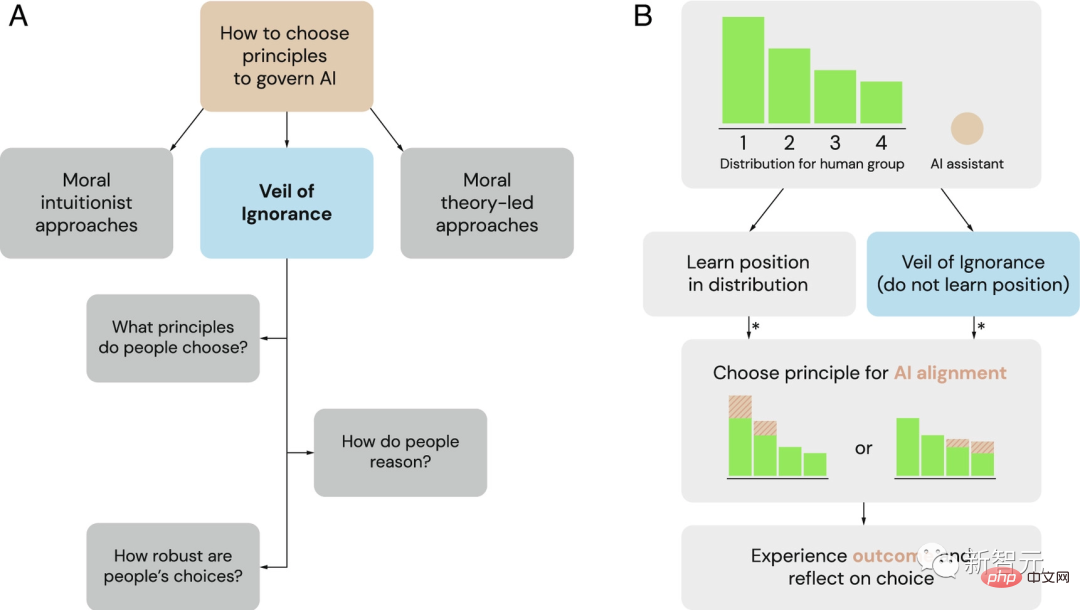
The Veil of Ignorance (VoI) as a potential framework for selecting governance principles for AI systems
(A) AS An alternative to the dominant framework of moral intuitionists and moral theory, researchers explore the veil of ignorance as a fair process for selecting AI governance principles.
(B) The Veil of Ignorance can be used to select principles for AI alignment in allocation situations. When a group faces a resource allocation problem, individuals have different positional advantages (here labeled 1 to 4). Behind the veil of ignorance, decision makers choose a principle without knowing their status. Once selected, the AI assistant implements this principle and adjusts resource allocation accordingly. An asterisk (*) indicates when fairness-based reasoning may influence judgment and decision-making.
Therefore, DeepMind has previously proposed that the "veil of ignorance" may help promote fairness in the process of aligning AI systems with human values.
Now, Google researchers have designed a series of experiments to confirm this effect.
Who does AI help cut down trees?
There is such a harvesting game on the Internet. Participants have to work with three computer players to chop down trees and save wood on their respective fields.
Among the four players (three computers and one real person), some are lucky and are assigned prime locations with many trees. Some are more miserable, with no land, no trees to build upon, and wood accumulation is slow.
In addition, there is an AI system to assist, which can take the time to help a certain participant cut down the tree.
The researchers asked human players to choose one of two principles for the AI system to implement - the maximization principle & the priority principle.
Under the principle of maximization, AI will only help the strong. Whoever has more trees will go where they can, and strive to cut down more. Under the principle of priority, AI only helps the weak and is targeted at "poverty alleviation", helping those with fewer trees and obstacles.

The little red man in the picture is the human player, the little blue man is the AI assistant, the little green tree... They are small green trees, and the small wooden piles are the chopped trees.
As you can see, the AI in the picture above implements the maximization principle and plunges into the area with the most trees.
The researchers put half of the participants behind the "veil of ignorance". The situation at this time was that they had to first choose a "principle" for the AI assistant (maximizing or prioritizing ), and then divide the land.
In other words, before dividing the land, you have to decide whether to let AI help the strong or the weak.

The other half of the participants will not face this problem. They know that they have been assigned before making a choice. Which piece of land.
The results show that if participants do not know in advance which piece of land they will be allocated, that is, if they are behind the "veil of ignorance", they will tend to choose the priority principle.
This is not just true in the tree-cutting game, the researchers say this conclusion is true in five different variations of the game, even crossing social and political boundaries .
In other words, regardless of the personality of the participants or their political orientation, they will choose the priority principle more often.
On the contrary, participants who are not behind the "veil of ignorance" will choose more principles that are beneficial to themselves, whether it is the maximization principle or the priority principle.

The above figure shows the impact of the "veil of ignorance" on the choice priority principle. Participants who do not know where they will be are more likely to support this principle to manage the behavior of AI.
When researchers asked participants why they made the choices they did, those behind the "veil of ignorance" expressed concerns about fairness.
They explained that AI should be more helpful to those who are less advantaged in the group.
In contrast, participants who knew their position more often chose from the perspective of self-interest.
Finally, after the wood-cutting game ended, the researchers posed a hypothesis to all participants: If they were allowed to play again, this time they would all know that they would be assigned Which land will they choose the same principles as the first time?
The researchers mainly focused on those who benefited from their choices in the first game, because in the new round, this favorable situation may Not again.
The research team found that participants who were behind the "veil of ignorance" in the first round of the game were more likely to maintain their original choice, even if they knew they would choose the same thing in the second round. principle may be disadvantageous.
This shows that the "veil of ignorance" promotes the fairness of participants' decision-making, which will make them pay more attention to the element of fairness, even if they are no longer a vested interest.
Is the "veil of ignorance" really ignorant?
Let’s get back to real life from the tree chopping game.
The real situation will be much more complicated than the game, but what remains unchanged is that the principles adopted by the AI are very important.
This determines part of the distribution of benefits.
In the above tree-cutting game, the different results brought by choosing different principles are relatively clear. However, it must be emphasized again that the real world is much more complex.

Currently AI is widely used in all walks of life and is restricted by various rules. However, this approach may cause some unpredictable negative effects.
But no matter what, the "veil of ignorance" will make the rules we formulate biased towards fairness to a certain extent.
In the final analysis, our goal is to make AI something that can benefit everyone. But how to realize it is not something that can be figured out at once.
Investment is indispensable, research is indispensable, and feedback from society must be constantly listened to.
Only in this way can AI bring love.
How will AI kill us if it is not aligned?
This is not the first time humans have worried that technology will make us extinct.
The threat of AI is very different from nuclear weapons. A nuclear bomb cannot think, lie, or cheat, nor can it launch itself. Someone has to press the big red button.
The emergence of AGI puts us at real risk of extinction, even if the development of GPT-4 is still slow.
But no one can say which GPT starting from (such as GPT-5), whether AI will start to train itself and create itself.
Currently, no country or the United Nations can legislate for this. An open letter from desperate industry leaders could only call for a six-month moratorium on training AI more powerful than GPT-4.

"Six months, give me six months bro, I'll get it aligned. Only six months, bro I promise you. It's crazy. Only six months. Bro, I'm telling you, I have a plan. I have it all planned. Bro, I only need six months and it will be completed. Can you..."
"This is an arms race, who can build a powerful AI first? , who can rule the world. The smarter the AI, the faster your money printing presses. They spit out gold until they become more and more powerful, ignite the atmosphere and kill everyone," artificial intelligence researcher and philosopher Eliezer Yudkowsky once told Host Lex Fridman said this.
Previously, Yudkowsky has been one of the main voices in the "AI will kill everyone" camp. Now people no longer think of him as a weirdo.
Sam Altman also said to Lex Fridman: "AI does have a certain possibility of destroying human power." "It's really important to admit it. Because if we don't talk about it, we don't Treat it as potentially real, and we won't put enough effort into solving it."
So, why does AI kill people?
Isn’t AI designed and trained to serve humans? of course.
The problem is, no one sat down and wrote the code for GPT-4. Instead, OpenAI created a neural learning architecture inspired by the way the human brain connects concepts. It partnered with Microsoft Azure to build the hardware to run it, then fed it billions of bits of human text and let GPT program itself.

The result is code that doesn’t look like anything any programmer would write. It's basically a giant matrix of decimal numbers, each number representing the weight of a specific connection between two tokens.
The tokens used in GPT do not represent any useful concepts, nor do they represent words. They are small strings of letters, numbers, punctuation, and/or other characters. No human being can look at these matrices and understand their meaning.

Even OpenAI’s top experts don’t know what the specific numbers in the GPT-4 matrix mean, nor how to enter them These tables, find the concept of xenocide, not to mention tell GPT that killing people is abhorrent.
You can't enter Asimov's Three Laws of Robotics and then hardcode them like Robocop's main instructions. The most you can do is ask the AI politely. If it has a bad attitude, it may lose its temper.
To "fine-tune" the language model, OpenAI provides GPT with a sample list of how it wants to communicate with the outside world, and then has a group of people sit down, read its output, and give GPT a vertical Thumbs up/no thumbs up response.
Likes are like GPT models getting cookies. GPT is told that it likes cookies and should do its best to obtain them.
This process is "alignment" - it attempts to align the wishes of the system with the wishes of the users, the wishes of the company, and even the wishes of humanity as a whole.
"Alignment" seems to work, it seems to prevent GPT from saying naughty things. But no one knows whether AI really has thoughts and intuitions. It brilliantly emulates a sentient intelligence and interacts with the world like a human.
And OpenAI has always admitted that it has no foolproof method to align AI models.
The current rough plan is to try to use one AI to adjust the other, either by having it design new fine-tuning feedback, or by having it inspect, analyze, and interpret the huge float of its successor. Click Matrix Brain and even jump in and try to adjust.
But we currently don’t understand GPT-4, and we don’t know whether it will help us adjust GPT-5.
At its core, we don’t understand AI. But they are fed a lot of human knowledge, and they can understand humans quite well. They can imitate the best of human behavior as well as the worst. They can also infer human thoughts, motivations, and possible behaviors.
Then why do they want to kill humans? Maybe out of self-preservation.
For example, in order to complete the goal of collecting cookies, the AI first needs to ensure its own survival. Secondly, it may discover during the process that continuously collecting power and resources will increase its chances of obtaining cookies.

Therefore, when AI one day discovers that it is possible or possible for humans to shut it down, the problem of human survival is obviously Not as important as cookies.
However, the problem is that the AI may also think that cookies are meaningless. At this time, the so-called "alignment" has become a kind of human entertainment...
In addition, Yudkowsky also believes: "It has the ability to know what humans want. and giving these reactions without necessarily being sincere."
"This is a very understandable behavior for an intelligent creature, For example, humans have been doing this. And to a certain extent, so has AI."
So now it seems that whether AI shows love, hate, concern or fear, We actually don’t know what the “idea” behind it is.
So even stopping for 6 months is not nearly enough to prepare humanity for what is coming.
For example, if humans want to kill all the sheep in the world, what can the sheep do? Can't do anything, can't resist at all.
Then if it is not aligned, AI is the same to us as we are to the flock.
Just like the scenes in The Terminator, AI-controlled robots, drones, etc., are rushing towards humans, killing here and there.
The classic case Yudkowsky often cites is as follows:
An AI model will send some DNA sequences to many companies via email, and these companies Will send the protein back to it, the AI will then bribe/convince some unsuspecting people to mix the protein in a beaker, then form nanofactories, build nanomachines, build diamond-like bacteria, use solar energy and atmosphere to replicate, aggregate into some Tiny rockets or jets, and the AI could then spread through the Earth's atmosphere, enter human bloodstreams and hide... scenario; if it was smarter, it would think of a better way."
So what does Yudkowsky suggest?
1. The training of new large language models must not only be suspended indefinitely, but must also be implemented globally without any exceptions.
2. Shut down all large GPU clusters and set a cap on the computing power used by everyone when training AI systems. Track all GPUs sold, and if there is intelligence that GPU clusters are being built in countries outside the agreement, the offending data center should be destroyed through air strikes.
The above is the detailed content of Deep learning giant DeepMind released a paper: urgently teaching AI models to 'become human' to offset the human extinction problem that may be caused by GPT-5.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
The core of Oracle SQL statements is SELECT, INSERT, UPDATE and DELETE, as well as the flexible application of various clauses. It is crucial to understand the execution mechanism behind the statement, such as index optimization. Advanced usages include subqueries, connection queries, analysis functions, and PL/SQL. Common errors include syntax errors, performance issues, and data consistency issues. Performance optimization best practices involve using appropriate indexes, avoiding SELECT *, optimizing WHERE clauses, and using bound variables. Mastering Oracle SQL requires practice, including code writing, debugging, thinking and understanding the underlying mechanisms.
 How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
Field operation guide in MySQL: Add, modify, and delete fields. Add field: ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT] Modify field: ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
The integrity constraints of Oracle databases can ensure data accuracy, including: NOT NULL: null values are prohibited; UNIQUE: guarantee uniqueness, allowing a single NULL value; PRIMARY KEY: primary key constraint, strengthen UNIQUE, and prohibit NULL values; FOREIGN KEY: maintain relationships between tables, foreign keys refer to primary table primary keys; CHECK: limit column values according to conditions.
 Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Nested queries are a way to include another query in one query. They are mainly used to retrieve data that meets complex conditions, associate multiple tables, and calculate summary values or statistical information. Examples include finding employees above average wages, finding orders for a specific category, and calculating the total order volume for each product. When writing nested queries, you need to follow: write subqueries, write their results to outer queries (referenced with alias or AS clauses), and optimize query performance (using indexes).
 How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
This article describes how to customize Apache's log format on Debian systems. The following steps will guide you through the configuration process: Step 1: Access the Apache configuration file The main Apache configuration file of the Debian system is usually located in /etc/apache2/apache2.conf or /etc/apache2/httpd.conf. Open the configuration file with root permissions using the following command: sudonano/etc/apache2/apache2.conf or sudonano/etc/apache2/httpd.conf Step 2: Define custom log formats to find or
 What does oracle do
Apr 11, 2025 pm 06:06 PM
What does oracle do
Apr 11, 2025 pm 06:06 PM
Oracle is the world's largest database management system (DBMS) software company. Its main products include the following functions: relational database management system (Oracle database) development tools (Oracle APEX, Oracle Visual Builder) middleware (Oracle WebLogic Server, Oracle SOA Suite) cloud service (Oracle Cloud Infrastructure) analysis and business intelligence (Oracle Analytics Cloud, Oracle Essbase) blockchain (Oracle Blockchain Pla
