
 Technology peripherals
AI
Can Stable Diffusion surpass algorithms such as JPEG and improve image compression while maintaining clarity?
Technology peripherals
AI
Can Stable Diffusion surpass algorithms such as JPEG and improve image compression while maintaining clarity?
Can Stable Diffusion surpass algorithms such as JPEG and improve image compression while maintaining clarity?

Text-basedImage generation models are very popular. Not only diffusion models are popular, but also the open source Stable Diffusion model.

Recently, a Swiss software engineer, Matthias Bühlmann, accidentally discovered that Stable Diffusion can not only be used to generate images; Compress bitmap images, even higher compression rate than JPEG and WebP.
For example, a photo of a llama, the original image is 768KB, it can be compressed to 5.66KB using JPEG, and Stable Diffusion can further compress it to 4.98KB , and can retain more high-resolution details and fewer compression artifacts, which is visibly better than other compression algorithms to the naked eye.

However, this compression method also has flaws, that is, is not suitable for compressing face and text images, in some cases Next, some original images will even be generated with no content.

Although retraining an autoencoder can also achieve a compression effect similar to Stable Diffusion, but using Stable Diffusion One of the main advantages is that someone has invested millions of funds to help you train one, so why do you spend money to train a compression model again?
How Stable Diffusion compresses images
Diffusion models are challenging the dominance of generative models, and the corresponding open source Stable Diffusion model is also setting off an artistic revolution in the machine learning community.

Stable Diffusion is obtained by connecting three trained neural networks in series, that is, a variational autoencoder (VAE) , U-Net model and a text encoder.
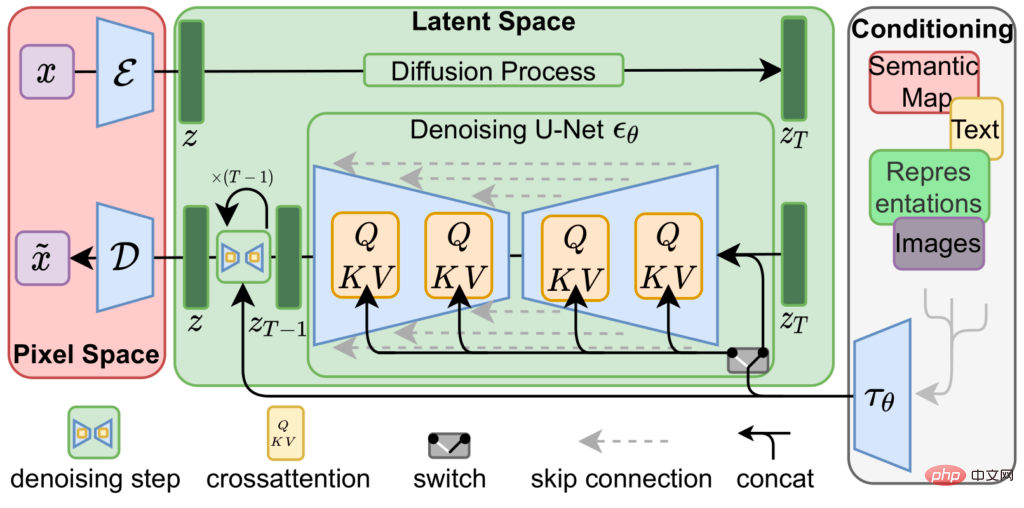
The variational autoencoder encodes and decodes the image in the image space to obtain the representation vector of the image in the latent space , represented by a vector with lower resolution (64x64) with higher precision (4x32bit) The source image (3x8 or 4x8bit of 512x512) .
VAE's training process of encoding images into latent space mainly relies on self-supervised learning, that is, the input and output are both source images. Therefore, as the model is further trained, different versions of the model will The latent space representation may look different.
After remapping and interpreting the latent space representation into a 4-channel color image using Stable Diffusion v1.4, it looks like the middle image in the figure below, in the source image Key features are still visible.

It should be noted that VAE round-trip encoding once is not lossless.
For example, after decoding, theANNA name on the blue tape is not as clear as the source image, and the readability is significantly reduced.
The variational autoencoder in Stable Diffusion v1.4 is not very good at representing small text and face images, I don’t know if it will be improved in v1.5. The main compression algorithm of Stable Diffusion is to use this latent space representation of images to generate new images from short text descriptions. Start from the random noise represented by the latent space, use a fully trained U-Net to iteratively remove the noise from the latent space image, and output the model with a simpler representation that it believes is in this noise The prediction of "seeing" is a bit like when we look at clouds, restore the shapes or faces in our minds from irregular graphics. When using Stable Diffusion to generate images, this iterative denoising step is guided by a third component, the text encoder, which provides U-Net with information about it Information on what one should try to see in the noise. However, for compression tasks, does not require a text encoder, so the experimental process only created an empty string encoding Used to tell U-Net to perform unguided denoising during the image reconstruction process. In order to use Stable Diffusion as an image compression codec, the algorithm needs to effectively compress the latent representation produced by VAE. It can be found in experiments that downsampling the latent representation or directly using existing lossy image compression methods will greatly reduce the quality of the reconstructed image. But the author found that VAE decoding seems to be very effective in quantization of latent representations. Scaling, clamping, and remapping of potentials from floating point to 8-bit unsigned integers produces only small visible reconstruction errors. #By quantizing the 8-bit latent representation, the data size represented by the image is now 64*64*4*8bit=16kB, which is much smaller than uncompressed The source image is 512*512*3*8bit=768kB If the number of bits of the latent representation is less than 8 bits, it will not produce better results. If palettizingand dithering are further performed on the image, the quantization effect will be improved again. Created a palette representation using 256*4*8 bit vectors and a latent representation of Floyd-Steinberg dithering, further compressing the data size to 64*64*8 256*4 *8bit=5kB The dithering of the latent space palette introduces noise, thus distorting the decoding results. However, since Stable Diffusion is based on the removal of latent noise, U-Net can be used to remove the noise caused by jitter. After 4 iterations, the reconstruction result is visually very close to the unquantized version. Although the amount of data is greatly reduced (the source image is 155 times larger than the compressed image), the effect is very good, but it also introduces Some artifacts (such as the heart pattern in the original image that is not present). Interestingly, this compression scheme introduces artifacts that have a greater impact on image content than image quality, and images compressed in this way may contain these types of compression artifacts. The author also used zlib to perform lossless compression on the palette and index. In the test samples, most of the compression results were less than 5kb, but this compression method still has more room for optimization. In order to evaluate this compression codec, the author did not use any standard test images found on the Internet, because the images on the Internet are likely to be trained by Stable Diffusion Concentrations have occurred, and compressing such images may result in an unfair contrast advantage. To make the comparison as fair as possible, the author used the highest quality encoder settings from the Python image library, as well as adding lossless data compression of the compressed JPG data using the mozjpeg library. It’s worth noting that while Stable Diffusion’s results subjectively look much better than JPG and WebP compressed images, they are not significantly better in terms of standard measurements like PSNR or SSIM. , but no worse. It's just that the types of artifacts introduced are less obvious because they affect image content more than they affect image quality. This compression method is also a bit dangerous, although the quality of the reconstructed features is high, the content may be affected by compression artifacts, even if it looks very sharp. For example, in a test image, although Stable Diffusion as a codec does a much better job of maintaining the quality of the image, even camera grain are preserved (something that most traditional compression algorithms struggle to achieve), but their content is still affected by compression artifacts, and fine features like building shapes may change. While it is certainly impossible to identify more true values in a JPG compressed image than in a Stable Diffusion compressed image, the Stable Diffusion compression results The high visual quality can be deceptive, as compression artifacts in JPG and WebP are easier to spot. If you also want to reproduce the experiment, the author has open sourced the code on . Finally, the author stated that the experiment designed in the article is still quite simple, but the effect is still surprising, . 



The above is the detailed content of Can Stable Diffusion surpass algorithms such as JPEG and improve image compression while maintaining clarity?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
Mobile photography has fundamentally changed the way we capture and share life’s moments. The advent of smartphones, especially the iPhone, played a key role in this shift. Known for its advanced camera technology and user-friendly editing features, iPhone has become the first choice for amateur and experienced photographers alike. The launch of iOS 17 marks an important milestone in this journey. Apple's latest update brings an enhanced set of photo editing features, giving users a more powerful toolkit to turn their everyday snapshots into visually engaging and artistically rich images. This technological development not only simplifies the photography process but also opens up new avenues for creative expression, allowing users to effortlessly inject a professional touch into their photos
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
 Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Written above & The author’s personal understanding is that in the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving. Head
