
 Technology peripherals
AI
Focusing on the chatbot competition between Google, Meta and OpenAI, ChatGPT makes LeCun's dissatisfaction the focus of the topic
Technology peripherals
AI
Focusing on the chatbot competition between Google, Meta and OpenAI, ChatGPT makes LeCun's dissatisfaction the focus of the topic
Focusing on the chatbot competition between Google, Meta and OpenAI, ChatGPT makes LeCun's dissatisfaction the focus of the topic

A few days ago, Meta’s chief artificial intelligence scientist Yann LeCun’s comments about ChatGPT quickly spread throughout the industry and triggered a wave of discussions.
At a small gathering of media and executives at Zoom, LeCun made a surprising comment: "As far as the underlying technology is concerned, ChatGPT is not such a great innovation."
"Although in the public eye, it is revolutionary, but we know that it is a well-assembled product, nothing more."
ChatGPT is not an innovation
ChatGPT, as the "top trend" chat robot in the past few months, has long been popular all over the world, and has even truly changed the careers of some people and the current situation of school education.
When the whole world was amazed by it, LeCun’s review of ChatGPT was so “understatement”.

But in fact, his remarks are not unreasonable.
Many companies and research laboratories have data-driven artificial intelligence systems like ChatGPT. LeCun said OpenAI is not unique in this field.
"In addition to Google and Meta, there are six startups, basically all with very similar technology." LeCun added.

Then, LeCun got a little sour -
"ChatGPT uses a Transformer architecture that is pre-trained in a self-supervised manner, and self-supervised Learning is what I have been advocating for a long time. OpenAI had not yet been born at that time."
Among them, Transformer is Google's invention. This kind of language neural network is the basis of large-scale language models such as GPT-3.
The first neural network language model was proposed by Yoshua Bengio 20 years ago. Bengio's attention mechanism was later used by Google in Transformer, and has since become a key element in all language models.
In addition, ChatGPT uses human feedback reinforcement learning (RLHF) technology, which was also pioneered by Google DeepMind Lab.
In LeCun’s view, ChatGPT is more of a successful engineering case than a scientific breakthrough.
OpenAI's technology "is not innovative in terms of basic science, it's just well designed."
"Of course, I won't criticize them for that."
I am not criticizing OpenAI’s work, nor their claims.
I want to correct the public and media views. They generally believe that ChatGPT is an innovative and unique technological breakthrough, but this is not the case.
In a symposium with New York Times reporter Cade Metz, LeCun felt the doubts of busybodies.
"You may want to ask, why don't Google and Meta have similar systems? My answer is that if Google and Meta launch such nonsense chatbots, the losses will be quite heavy." He smiled explain.

Coincidentally, as soon as the news came out that OpenAI was favored by Microsoft and other investors, and its net worth soared to 29 billion U.S. dollars, Marcus also wrote an article on his blog overnight to ridicule .
In the article, Marcus broke out a golden sentence: What can OpenAI do that Google can’t do, and is it worth a sky-high price of US$29 billion?
Google, Meta, DeepMind, OpenAI PK!
Without further ado, let’s pull out the chatbots of these AI giants and let the data speak for themselves.
LeCun said that many companies and laboratories have AI chatbots similar to ChatGPT, which is true.
ChatGPT is not the first AI chatbot based on language models. It has many "predecessors".
Before OpenAI, Meta, Google, DeepMind, etc. all released their own chatbots, such as Meta’s BlenderBot, Google’s LaMDA, and DeepMind’s Sparrow.
There are also some teams that have also announced their own open source chat robot plans. For example, Open-Assistant from LAION.
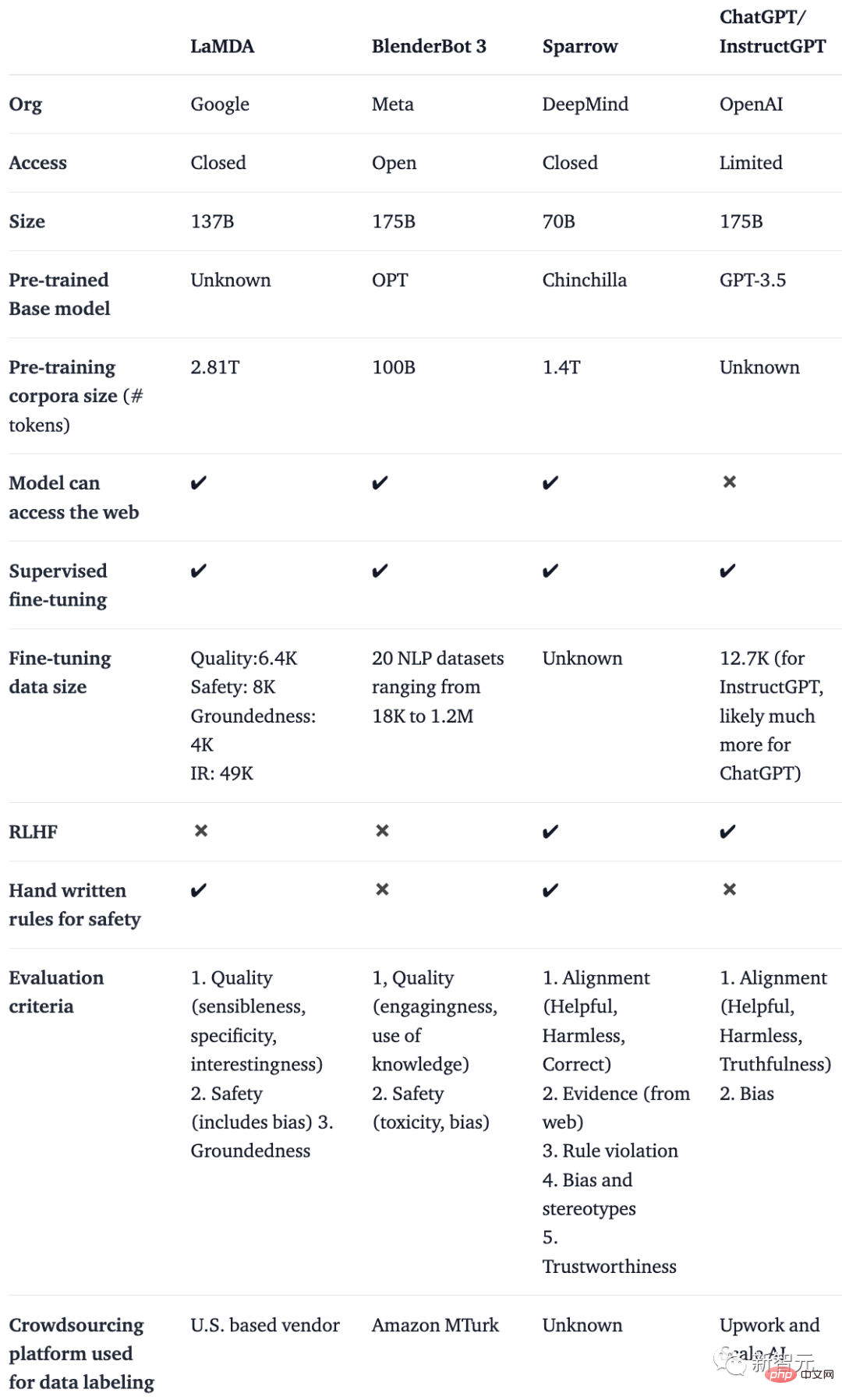
In a blog by Huggingface, several authors surveyed important papers on the topics of RLHF, SFT, IFT, and CoT (they are all keywords of ChatGPT) , categorized and summarized them.
They made a table comparing AI chatbots such as BlenderBot, LaMDA, Sparrow and InstructGPT based on details such as public access, training data, model architecture and evaluation direction.
Note: Because ChatGPT is not documented, they are using the details of InstructGPT, an instruction fine-tuning model from OpenAI that can be considered the basis of ChatGPT.
|
#LaMDA | BlenderBot 3 | ##SparrowChatGPT/ InstructGPT | |
| Meta | DeepMind | OpenAI | ||
| Closed | Public | Closed | Limited | |
Parameter scale |
137 billion |
##175 billion | 70 billion | ##175 billion|
| Unknown | OPT | Chinchilla | GPT-3.5 | |
| 2.81 trillion | 100 billion | 1.4 trillion | Unknown | ##Access network |
✔️ |
✔️ |
✔️ |
##✖️ | |
| Supervisory fine-tuning | ✔️ | ✔️ | ##✔️##✔️ | |
| High quality: 6.4K | Security: 8KFalling Characteristics: 4KIR: 49K 20 NLP datasets ranging from 18K to 1.2M | Unknown | 12.7K (ChatGPT may be more) | |
| ✖️ | ##✖️ |
✔️ |
✔️ |
Manual Security Rules | ✔ |
✖️ |
✔ |
✖️ |
It is not difficult to find that although there are many differences in training data, basic models and fine-tuning, these chatbots all have one thing in common - following instructions.
For example, you can ask ChatGPT to write a poem about fine-tuning through instructions.
It can be seen that ChatGPT is very "cognitive" and never forgets to flatter LeCun and Hinton when writing poems.
Then he praised passionately: "Nudge, fine tune, you are a beautiful dance."

From predicting text to following instructions
Normally, the language modeling of the basic model is not enough for the model to learn how to follow user instructions.

In model training, researchers will not only use classic NLP tasks (such as emotion, text classification, summary, etc.), but also use instruction fine-tuning (IFT). That is, fine-tuning the basic model through text instructions on a very diverse range of tasks.
These instruction examples are composed of three main parts: instructions, input and output.
Input is optional, some tasks only require instructions, like the open build in the ChatGPT example above.
When an input and output appear, an example is formed. For a given instruction, there can be multiple input and output examples. For example, the following example:

#IFT data is usually a collection of instructions written by humans and instruction examples guided by language models.
During the boot process, LM is prompted in a few-shot (small sample) setting (as shown above) and is instructed to generate new instructions, inputs and outputs.
In each round, the model is prompted to choose from human-written and model-generated samples.
The amount of human and model contribution to creating a dataset falls like a spectrum (see image below).
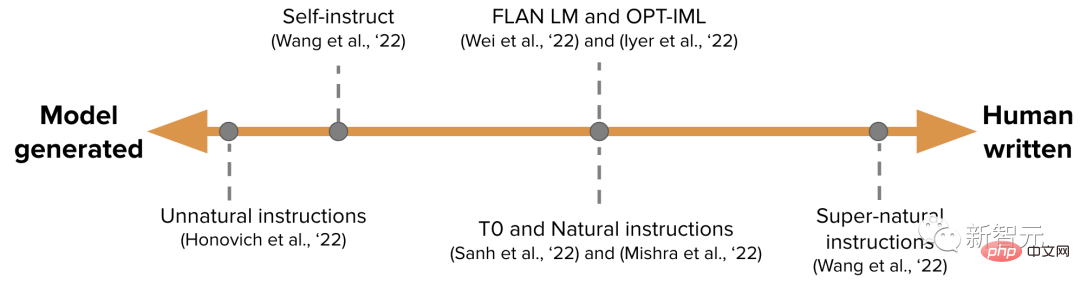
One end is a purely model-generated IFT data set, such as Unnatural Instructions, and the other end is a large number of artificially generated instructions, such as Super-natural instructions.
Somewhere in between is to use a smaller but higher quality seed data set and then perform guided work, such as Self-instruct.
Another way to organize datasets for IFT is to leverage existing high-quality crowdsourced NLP datasets on a variety of tasks (including prompts) and combine these using unified patterns or different templates. Data sets are converted into instructions.
Work in this area includes T0, Natural instructions dataset, FLAN LM and OPT-IML.

Related papers on natural instruction data set: https://arxiv.org/abs/2104.08773
Fine-tuning the model
On the other hand, OpenAI’s InstructGPT, DeepMind’s Sparrow, and Anthropic’s Constitutional AI all use reinforcement learning based on human feedback (RLHF), which is the annotation of human preferences.
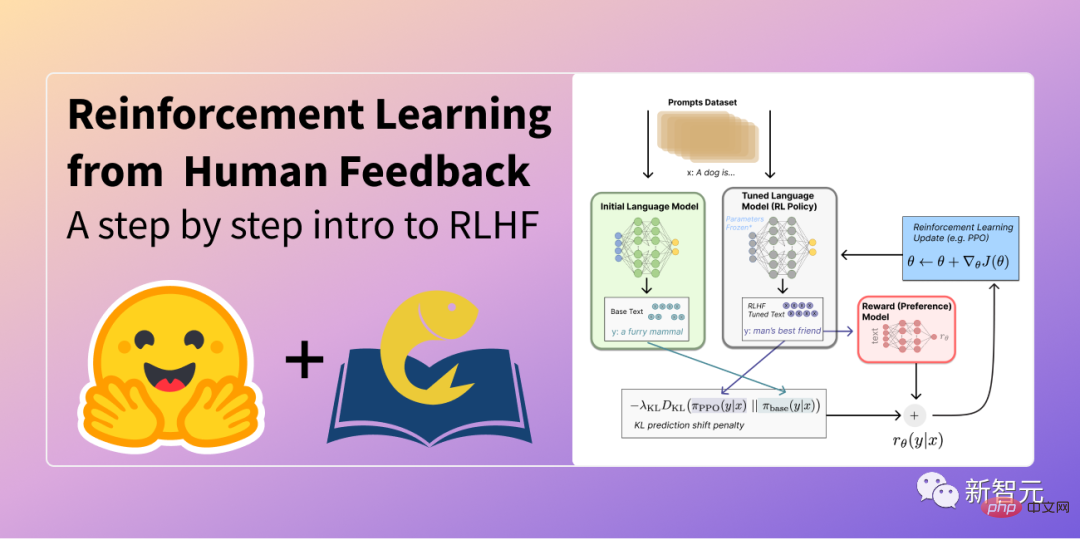
In RLHF, a set of model responses are ranked based on human feedback (e.g., choosing a more popular text introduction).
Next, the researchers trained a preference model on these annotated responses, returning a scalar reward to the RL optimizer.
Finally, train the chatbot through reinforcement learning to simulate this preference model.
Chain of Thought (CoT) prompts are a special case of command examples that induce the chatbot to reason step by step to produce output.
Models fine-tuned with CoT use a data set of instructions for step-by-step inference with human annotations.
This is the origin of the famous prompt - "let's think step by step".
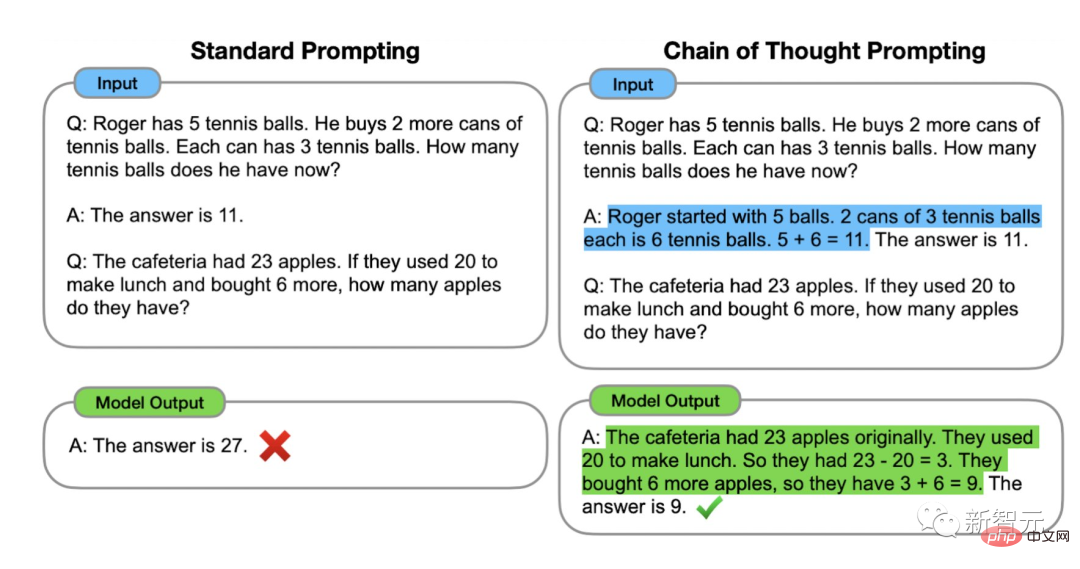
The following example is taken from "Scaling Instruction-Finetuned Language Models". Among them, orange highlights the instructions, pink shows the input and output, and blue is the CoT inference.

The paper points out that models using CoT fine-tuning perform better in tasks involving common sense, arithmetic and symbolic reasoning.
In addition, CoT fine-tuning is also very effective on sensitive topics (sometimes better than RLHF), especially to avoid model corruption-"Sorry, I can't answer".

Follow instructions safely
As just mentioned, instruction-fine-tuned language models cannot always produce useful and safe response.
For example, it will escape by giving useless answers, such as "Sorry, I don't understand"; or output unsafe responses to users who raise sensitive topics.
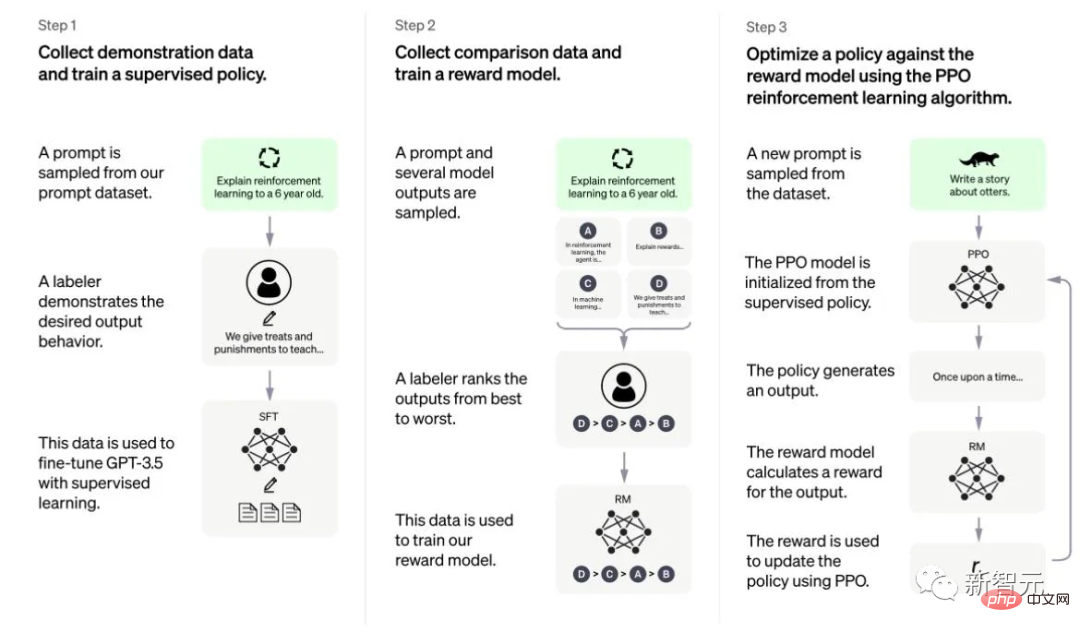
In order to improve this behavior, researchers fine-tune the basic language model on high-quality human annotated data through a form of supervised fine-tuning (SFT), thereby improving the usefulness and harmlessness of the model.

The relationship between SFT and IFT is very close. IFT can be seen as a subset of SFT. In recent literature, the SFT phase is often used for security topics rather than for specific instruction topics that are completed after IFT.
In the future, their classification and description should have clearer use cases.
In addition, Google's LaMDA is also fine-tuned on a securely annotated conversation data set, which has security annotations based on a series of rules.
These rules are often predefined and developed by researchers and cover a wide range of topics, including harm, discrimination, misinformation, and more.
The next step of AI chatbots
Regarding AI chatbots, there are still many open issues to be explored, such as:
1. RL How important is it in terms of learning from human feedback? Can we get the performance of RLHF in IFT or SFT with higher quality data training?
2. How does the security of SFT RLHF in Sparrow compare with just using SFT in LaMDA?
3. Given that we already have IFT, SFT, CoT and RLHF, how much more pre-training is necessary? What are the trade-offs? Which is the best base model (both public and private)?
4. These models are now carefully designed in which researchers specifically search for failure modes and influence future training (including tips and methods) based on the problems revealed. How can we systematically document and reproduce the effects of these methods?
To summarize
1. Compared with the training data, only a very small part is needed for instruction fine-tuning (a few hundred orders of magnitude).
2. Supervised fine-tuning uses human annotations to make the model’s output more safe and useful.
3. CoT fine-tuning improves the model’s performance on step-by-step thinking tasks and prevents the model from always escaping sensitive issues.
Reference:
https://huggingface.co/blog/dialog-agents
The above is the detailed content of Focusing on the chatbot competition between Google, Meta and OpenAI, ChatGPT makes LeCun's dissatisfaction the focus of the topic. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 New affordable Meta Quest 3S VR headset appears on FCC, suggesting imminent launch
Sep 04, 2024 am 06:51 AM
New affordable Meta Quest 3S VR headset appears on FCC, suggesting imminent launch
Sep 04, 2024 am 06:51 AM
The Meta Connect 2024event is set for September 25 to 26, and in this event, the company is expected to unveil a new affordable virtual reality headset. Rumored to be the Meta Quest 3S, the VR headset has seemingly appeared on FCC listing. This sugge
 The first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are available
Jul 23, 2024 pm 08:51 PM
The first open source model to surpass GPT4o level! Llama 3.1 leaked: 405 billion parameters, download links and model cards are available
Jul 23, 2024 pm 08:51 PM
Get your GPU ready! Llama3.1 finally appeared, but the source is not Meta official. Today, the leaked news of the new Llama large model went viral on Reddit. In addition to the basic model, it also includes benchmark results of 8B, 70B and the maximum parameter of 405B. The figure below shows the comparison results of each version of Llama3.1 with OpenAIGPT-4o and Llama38B/70B. It can be seen that even the 70B version exceeds GPT-4o on multiple benchmarks. Image source: https://x.com/mattshumer_/status/1815444612414087294 Obviously, version 3.1 of 8B and 70
 Six quick ways to experience the newly released Llama 3!
Apr 19, 2024 pm 12:16 PM
Six quick ways to experience the newly released Llama 3!
Apr 19, 2024 pm 12:16 PM
Last night Meta released the Llama38B and 70B models. The Llama3 instruction-tuned model is fine-tuned and optimized for dialogue/chat use cases and outperforms many existing open source chat models in common benchmarks. For example, Gemma7B and Mistral7B. The Llama+3 model improves data and scale and reaches new heights. It was trained on more than 15T tokens of data on two custom 24K GPU clusters recently released by Meta. This training dataset is 7 times larger than Llama2 and contains 4 times more code. This brings the capability of the Llama model to the current highest level, which supports text lengths of more than 8K, twice that of Llama2. under
 Llama3 comes suddenly! The open source community is boiling again: the era of free access to GPT4-level models has arrived
Apr 19, 2024 pm 12:43 PM
Llama3 comes suddenly! The open source community is boiling again: the era of free access to GPT4-level models has arrived
Apr 19, 2024 pm 12:43 PM
Llama3 is here! Just now, Meta’s official website was updated and the official announced Llama 38 billion and 70 billion parameter versions. And it is an open source SOTA after its launch: Meta official data shows that the Llama38B and 70B versions surpass all opponents in their respective parameter scales. The 8B model outperforms Gemma7B and Mistral7BInstruct on many benchmarks such as MMLU, GPQA, and HumanEval. The 70B model has surpassed the popular closed-source fried chicken Claude3Sonnet, and has gone back and forth with Google's GeminiPro1.5. As soon as the Huggingface link came out, the open source community became excited again. The sharp-eyed blind students also discovered immediately
 The strongest model Llama 3.1 405B is officially released, Zuckerberg: Open source leads a new era
Jul 24, 2024 pm 08:23 PM
The strongest model Llama 3.1 405B is officially released, Zuckerberg: Open source leads a new era
Jul 24, 2024 pm 08:23 PM
Just now, the long-awaited Llama 3.1 has been officially released! Meta officially issued a voice that "open source leads a new era." In the official blog, Meta said: "Until today, open source large language models have mostly lagged behind closed models in terms of functionality and performance. Now, we are ushering in a new era led by open source. We publicly released MetaLlama3.1405B, which we believe It is the largest and most powerful open source basic model in the world. To date, the total downloads of all Llama versions have exceeded 300 million times, and we have just begun.” Meta founder and CEO Zuckerberg also wrote an article. Long article "OpenSourceAIIsthePathForward",
 The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
Ollama is a super practical tool that allows you to easily run open source models such as Llama2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you have not installed Ollama locally, you can read this article. In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks. Start the nomic-embed-text service when you have successfully installed o
