
 Technology peripherals
AI
DeepMind said: AI models need to lose weight, and autoregression becomes the main trend
Technology peripherals
AI
DeepMind said: AI models need to lose weight, and autoregression becomes the main trend
DeepMind said: AI models need to lose weight, and autoregression becomes the main trend

Autoregressive attention programs with Transformer as the core have always been difficult to overcome the difficulty of scale. To this end, DeepMind/Google recently established a new project to propose a good way to help such programs effectively slim down.
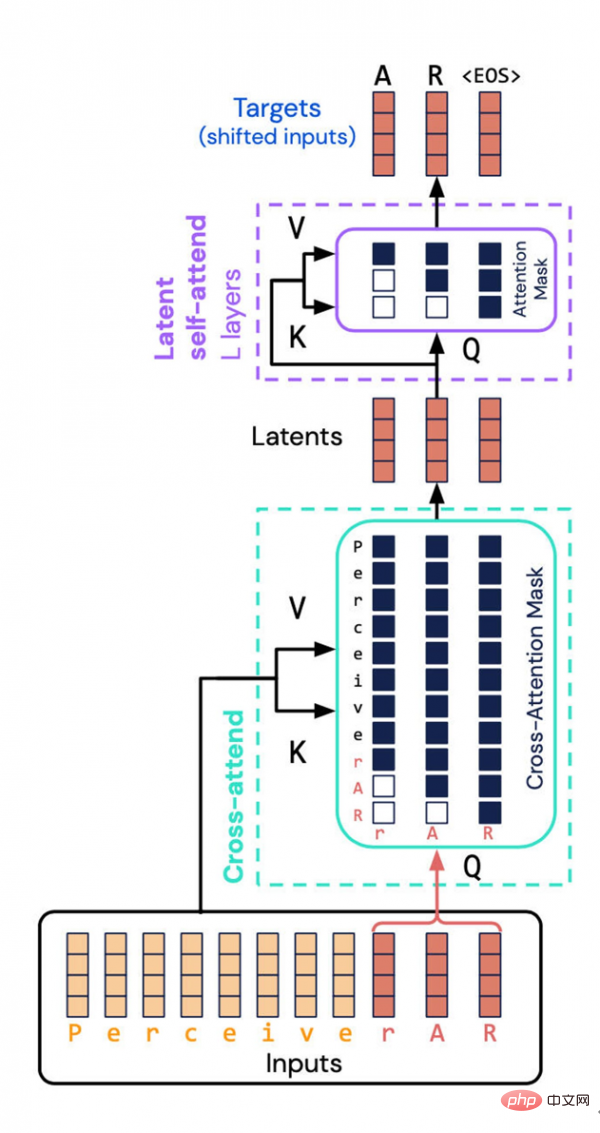
The Perceiver AR architecture created by DeepMind and Google Brain avoids a resource-intensive task - calculating the combined properties of input and output into the latent space. Instead, they introduced “causal masking” into the latent space, thereby achieving the autoregressive order of a typical Transformer.
One of the most impressive development trends in the field of artificial intelligence/deep learning is that the size of models is getting larger and larger. Experts in the field say that since scale is often directly linked to performance, this wave of volume expansion is likely to continue.
However, the scale of the project is getting larger and larger, and the resources consumed are naturally increasing, which has caused deep learning to raise new issues at the social and ethical level. This dilemma has attracted the attention of mainstream scientific journals such as Nature.
Because of this, we may have to return to the old word "efficiency" - AI programs. Is there any room for further efficiency improvement?
Scientists from DeepMind and Google Brain departments have recently modified the neural network Perceiver they launched last year, hoping to improve its efficiency in using computing resources.
The new program is named Perceiver AR. The AR here originates from "autoregressive", which is also another development direction of more and more deep learning programs today. Autoregression is a technique that allows the machine to use the output as a new input to the program. It is a recursive operation, thereby forming an attention map in which multiple elements are related to each other.
The popular neural network Transformer launched by Google in 2017 also has this autoregressive characteristic. In fact, the later GPT-3 and the first version of Perceiver continued the autoregressive technical route.
Before Perceiver AR, Perceiver IO, launched in March this year, was the second version of Perceiver. Going back further, it was the first version of Perceiver released this time last year.
The initial innovation of Perceiver is to use Transformer and make adjustments so that it can flexibly absorb various inputs, including text, sound and images, thereby breaking away from dependence on specific types of input. This allows researchers to develop neural networks using multiple input types.
As a member of the trend of the times, Perceiver, like other model projects, has begun to use the autoregressive attention mechanism to mix different input modes and different task domains. Such use cases also include Google’s Pathways, DeepMind’s Gato, and Meta’s data2vec.
In March of this year, Andrew Jaegle, the creator of the first version of Perceiver, and his team of colleagues released the "IO" version. The new version enhances the output types supported by Perceiver, enabling a large number of outputs containing a variety of structures, including text language, optical flow fields, audio-visual sequences and even unordered sets of symbols, etc. Perceiver IO can even generate operating instructions in the game "StarCraft 2".
In this latest paper, Perceiver AR has been able to implement general autoregressive modeling for long contexts. However, during the research, Jaegle and his team also encountered new challenges: how to scale the model when dealing with various multi-modal input and output tasks.
The problem is that the autoregressive quality of the Transformer, and any program that similarly builds input-to-output attention maps, requires massive distribution sizes of up to hundreds of thousands of elements.
This is the fatal weakness of the attention mechanism. More precisely, everything needs to be attended to in order to build up the probability distribution of the attention map.
As Jaegle and his team mentioned in the paper, as the number of things that need to be compared with each other increases in the input, the model's consumption of computing resources will become increasingly exaggerated:
This kind of There is a conflict between long context structures and the computational nature of the Transformer. Transformers repeatedly perform self-attention operations on the input, which causes computational requirements to grow both quadratically with input length and linearly with model depth. The more input data there is, the more input tags corresponding to the observed data content, the patterns in the input data become more subtle and complex, and deeper layers must be used to model the generated patterns. Due to limited computing power, Transformer users are forced to either truncate the model input (preventing the observation of more distant patterns) or limit the depth of the model (thus depriving it of the expressive ability to model complex patterns).
In fact, the first version of Perceiver also tried to improve the efficiency of Transformers: not directly performing attention, but performing attention on the potential representation of the input. In this way, the computing power requirements of processing large input arrays can be "(decoupled) from the computing power requirements corresponding to large deep networks."
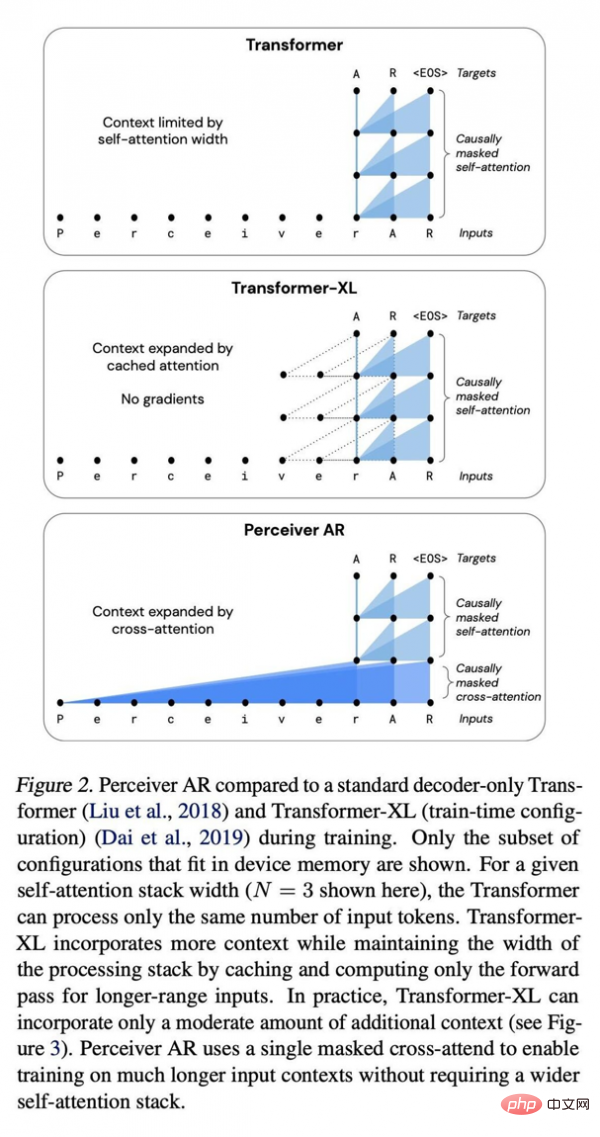
Comparison between Perceiver AR, standard Transformer deep network, and enhanced Transformer XL.
In the latent part, the input representation is compressed and thus becomes a more efficient attention engine. This way, "with deep networks, most of the computation actually happens on the self-attention stack," rather than having to operate on countless inputs.
But the challenge still exists, because the underlying representation does not have the concept of order, so Perceiver cannot generate output like Transformer. The order is crucial in autoregression, and each output should be the product of the input before it, not the product after it.
But since each latent model pays attention to all inputs regardless of their location, "for autoregressive generation that requires that each model output must depend only on its previous input," the researchers write, Perceiver will not be directly applicable."
As for Perceiver AR, the research team went one step further and inserted the sequence into Perceiver to enable automatic regression.
The key here is to perform so-called "causal masking" on the input and latent representation. On the input side, causal masking performs "cross-attention," while on the underlying representation side it forces the program to pay attention only to what comes before a given symbol. This method restores the directivity of the Transformer and can still significantly reduce the total calculation amount.
The result is that Perceiver AR can achieve modeling results comparable to Transformer based on more inputs, but the performance is greatly improved.
They write, “Perceiver AR can perfectly identify and learn long context patterns that are at least 100k tokens apart in the synthetic copying task.” In comparison, Transformer has a hard limit of 2048 tokens. The more there are, the longer the context will be and the more complex the program output will be.
Compared with the Transformer and Transformer-XL architectures that widely use pure decoders, Perceiver AR is more efficient and can flexibly change the actual computing resources used during testing according to the target budget.
The paper writes that under the same attention conditions, the wall clock time to calculate Perceiver AR is significantly shorter, and it can absorb more context (i.e. more input symbols) under the same computing power budget:
The context length of Transformer is limited to 2048 tokens, which is equivalent to only supporting 6 layers - because larger models and longer contexts require a huge amount of memory. Using the same 6-layer configuration, we can extend the total context length of Transformer-XL memory to 8192 tokens. Perceiver AR can extend the context length to 65k markers, and with further optimization, it is expected to even exceed 100k.
All of this makes computing more flexible: “We can better control the amount of calculations a given model generates during testing, allowing us to achieve a stable balance between speed and performance. ."
Jaegle and colleagues also wrote that this approach works for any input type and is not limited to word symbols. For example pixels in images can be supported:
The same process works for any input that can be sorted, as long as causal masking techniques are applied. For example, the RGB channels of an image can be sorted in raster scan order by decoding the R, G, and B color channels of each pixel in the sequence, in order or out of order.
The authors found great potential in Perceiver and wrote in the paper, "Perceiver AR is an ideal candidate for long-context general-purpose autoregressive models."
But if you want to pursue For higher computational efficiency, another additional instability factor needs to be addressed. The authors point out that the research community has also recently attempted to reduce the computational requirements of autoregressive attention through "sparsity" (that is, the process of limiting the importance assigned to some input elements).
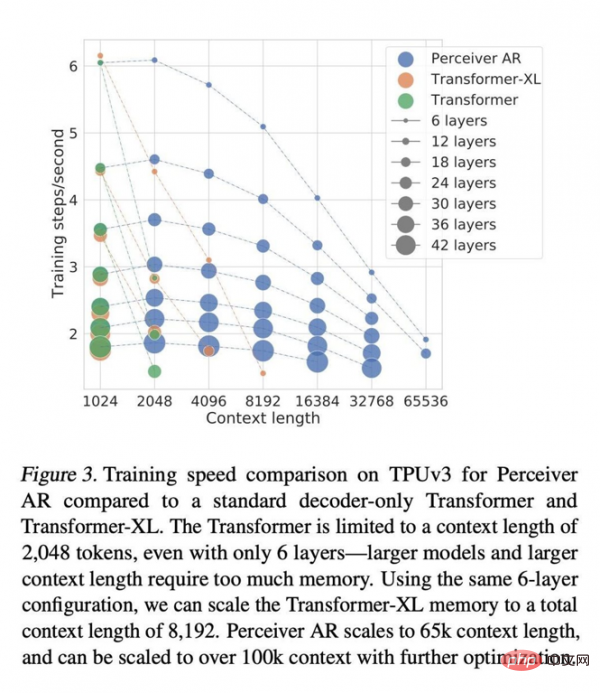
In the same wall clock time, Perceiver AR is able to run more from the input with the same number of layers. symbols, or significantly shorten the computation time with the same number of input symbol runs. The authors believe that this excellent flexibility may lead to a general efficiency improvement method for large networks.
But sparsity also has its own shortcomings, the main one being that it is too rigid. The paper writes, "The disadvantage of using sparsity methods is that this sparsity must be created by manual adjustment or heuristic methods. These heuristics are often only applicable to specific fields and are often difficult to adjust." OpenAI and NVIDIA in 2019 The Sparse Transformer released in 2017 is a sparse project.
They explained, “In contrast, our work does not require manual creation of sparse patterns on the attention layer, but allows the network to autonomously learn which long-context inputs require more attention and need to be passed through. The network propagates."
The paper also adds, "The initial cross-attention operation reduces the number of positions in the sequence and can be viewed as a form of sparse learning."
With this The sparsity itself learned in this way may become another powerful tool in the deep learning model toolkit in the next few years.
The above is the detailed content of DeepMind said: AI models need to lose weight, and autoregression becomes the main trend. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
When installing and configuring GitLab on a CentOS system, the choice of database is crucial. GitLab is compatible with multiple databases, but PostgreSQL and MySQL (or MariaDB) are most commonly used. This article analyzes database selection factors and provides detailed installation and configuration steps. Database Selection Guide When choosing a database, you need to consider the following factors: PostgreSQL: GitLab's default database is powerful, has high scalability, supports complex queries and transaction processing, and is suitable for large application scenarios. MySQL/MariaDB: a popular relational database widely used in Web applications, with stable and reliable performance. MongoDB:NoSQL database, specializes in
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
