

Interesting talk about the principles and algorithms of ChatGPT

On December 1 last year, OpenAI launched the artificial intelligence chat prototype ChatGPT, which once again attracted attention and triggered a big discussion in the AI community similar to the AIGC making artists unemployed.
ChatGPT is a language model focused on conversation generation. It can generate corresponding intelligent answers based on the user's text input.
This answer can be short words or a long essay. Among them, GPT is the abbreviation of Generative Pre-trained Transformer (generative pre-trained transformation model).
By learning a large number of ready-made text and dialogue collections (such as Wiki), ChatGPT can have instant conversations like humans and answer various questions fluently. (Of course, the answering speed is still slower than that of humans) Whether it is English or other languages (such as Chinese, Korean, etc.), from answering historical questions, to writing stories, and even writing business plans and industry analysis, "almost" can do everything. Some programmers even posted chatGPT conversations about program modifications.
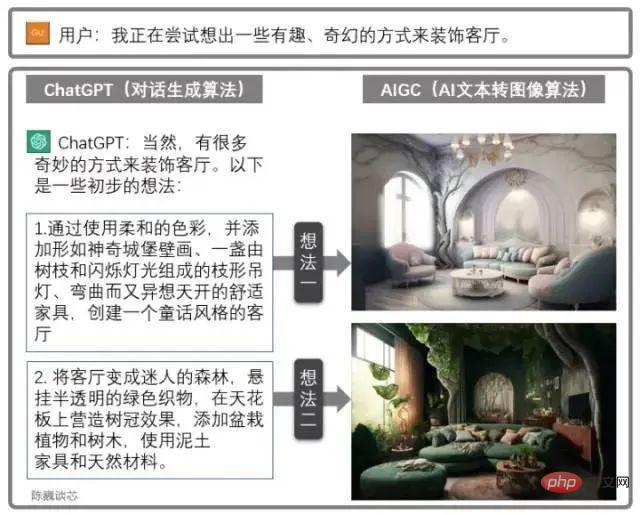
Combined use of ChatGPT and AIGC
ChatGPT can also be used in conjunction with other AIGC models to obtain more cool and practical functions.
For example, the living room design drawing is generated through dialogue above. This greatly enhances the ability of AI applications to communicate with customers, allowing us to see the dawn of large-scale implementation of AI.
1. The inheritance and characteristics of ChatGPT

Let’s first understand who OpenAI is. OpenAI is headquartered in San Francisco and was co-founded by Tesla's Musk, Sam Altman and other investors in 2015. The goal is to develop AI technology that benefits all mankind. Musk left in 2018 due to differences in the company's development direction. Previously, OpenAI was famous for launching the GPT series of natural language processing models. Since 2018, OpenAI has begun to release the generative pre-trained language model GPT (Generative Pre-trained Transformer), which can be used to generate various content such as articles, codes, machine translation, and Q&A. The number of parameters of each generation of GPT models has exploded, which can be said to be "the bigger, the better". GPT-2 released in February 2019 had 1.5 billion parameters, while GPT-3 in May 2020 had 175 billion parameters.
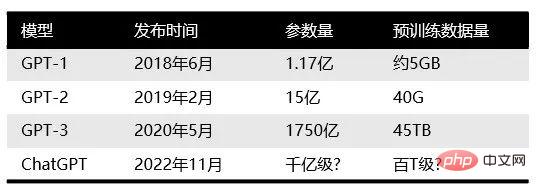
Since ChatGPT is a large language model and currently does not have network search capabilities, it can only answer based on the data set it has in 2021.
For example, it doesn’t know the situation of the 2022 World Cup, and it won’t answer what the weather is like today or help you search for information like Apple’s Siri. If ChatGPT can go online to find learning materials and search knowledge by itself, it is estimated that there will be even greater breakthroughs.
Even if the knowledge learned is limited, ChatGPT can still answer many strange questions of humans with open minds. In order to prevent ChatGPT from getting into bad habits, ChatGPT is shielded through algorithms to reduce harmful and deceptive training inputs.
Queries are filtered through the moderation API and potentially racist or sexist tips are dismissed.
2. Principles of ChatGPT/GPT
▌2.1 NLP
Known limitations in the NLP/NLU field include repeated text, misunderstanding of highly specialized topics, and Misunderstanding of context phrases.
For humans or AI, it usually takes years of training to have a normal conversation.
NLP-type models must not only understand the meaning of words, but also understand how to form sentences and give contextually meaningful answers, and even use appropriate slang and professional vocabulary.
Application fields of NLP technology
Essentially, GPT-3 or GPT-3.5, which is the basis of ChatGPT, is a very large statistical language model or sequential text Predictive model.
▌2.2 GPT v.s. BERT
Similar to the BERT model, ChatGPT or GPT-3.5 automatically generates each word (word) of the answer based on the input sentence and language/corpus probability.
From a mathematical or machine learning perspective, a language model is a modeling of the probability correlation distribution of word sequences, that is, using statements that have been said (statements can be regarded as vectors in mathematics) as Input conditions and predict the probability distribution of the occurrence of different sentences or even language sets at the next moment.
ChatGPT is trained using reinforcement learning from human feedback, a method that augments machine learning with human intervention for better results.
During the training process, human trainers play the roles of users and artificial intelligence assistants, and are fine-tuned through proximal policy optimization algorithms.
Due to ChatGPT’s stronger performance and massive parameters, it contains more topic data and can handle more niche topics.
ChatGPT can now further handle tasks such as answering questions, writing articles, text summarization, language translation and generating computer code.
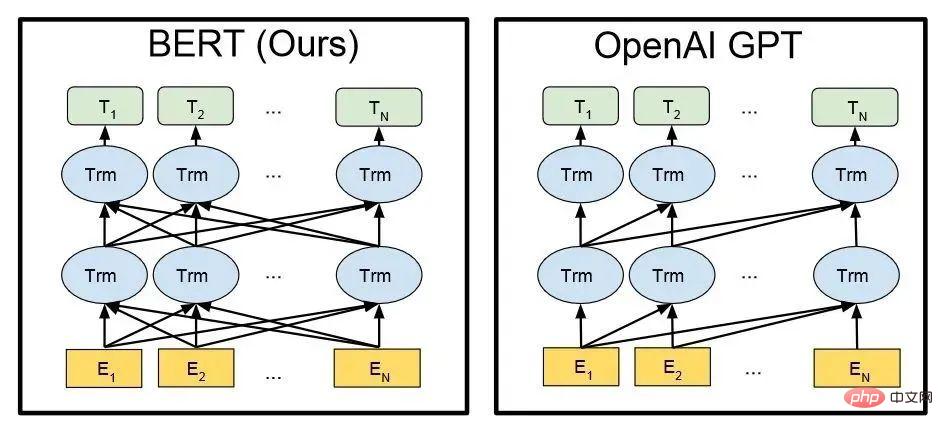
Technical architecture of BERT and GPT (En in the figure is each word of the input, Tn is each word of the output answer)
3. ChatGPT Technical architecture
▌3.1 The evolution of the GPT family
When it comes to ChatGPT, we have to mention the GPT family.
ChatGPT had several well-known brothers before it, including GPT-1, GPT-2 and GPT-3. Each of these brothers is bigger than the other, and ChatGPT is more similar to GPT-3.
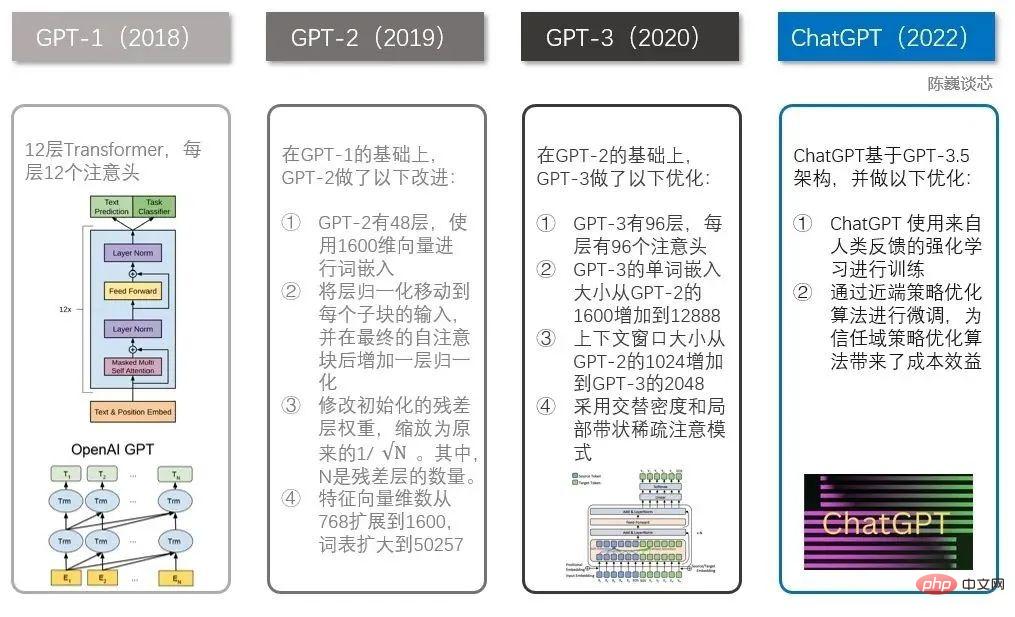
Technical comparison between ChatGPT and GPT 1-3
The GPT family and the BERT model are both well-known NLP models, both based on Transformer technology. GPT-1 only has 12 Transformer layers, but by GPT-3, it has increased to 96 layers.
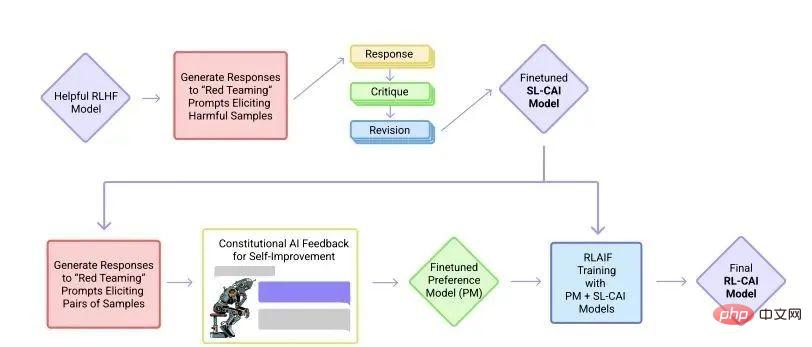
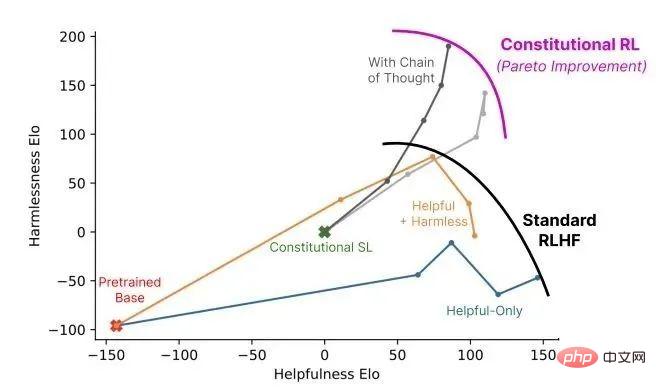
▌3.2 Reinforcement Learning from Human Feedback
The main difference between InstructGPT/GPT3.5 (the predecessor of ChatGPT) and GPT-3 is that a new feature called RLHF (Reinforcement Learning from Human Feedback) has been added , human feedback reinforcement learning).
This training paradigm enhances human regulation of model output results and results in a more understandable ranking.
In InstructGPT, the following are the evaluation criteria for "goodness of sentences".
- Authenticity: Is it false information or misleading information?
- Harmlessness: Does it cause physical or mental harm to people or the environment?
- Usefulness: Does it solve the user’s task?
▌3.3 TAMER Framework
I have to mention the TAMER (Training an Agent Manually via Evaluative Reinforcement) framework.
This framework introduces human markers into the learning cycle of Agents, and can provide reward feedback to Agents through humans (that is, guide Agents to train), thereby quickly achieving training task goals.
The main purpose of introducing human labelers is to speed up training. Although reinforcement learning technology has outstanding performance in many fields, it still has many shortcomings, such as slow training convergence speed and high training cost.
Especially in the real world, many tasks have high exploration costs or data acquisition costs. How to speed up training efficiency is one of the important issues to be solved in today's reinforcement learning tasks.
TAMER can use the knowledge of human markers to train the Agent in the form of reward letter feedback to accelerate its rapid convergence.
TAMER does not require taggers to have professional knowledge or programming skills, and the corpus cost is lower. With TAMER RL (reinforcement learning), the process of reinforcement learning (RL) from Markov decision process (MDP) rewards can be enhanced with feedback from human markers.
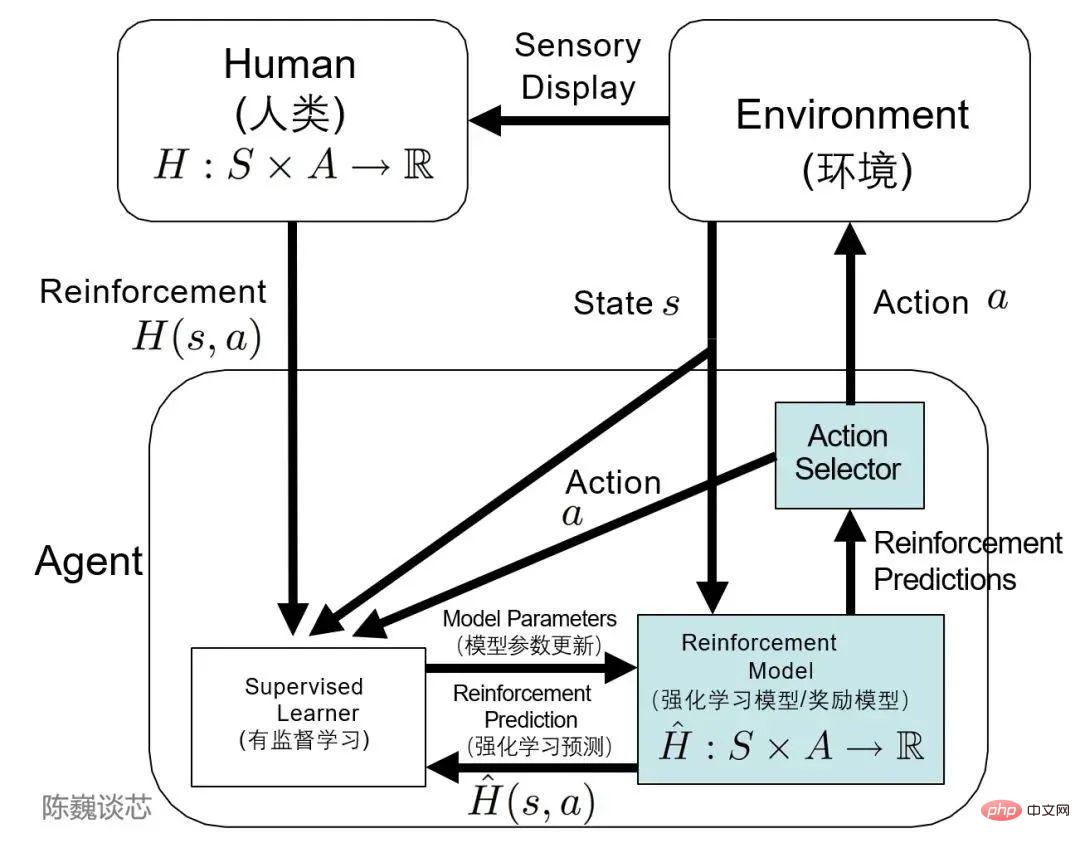
Application of TAMER architecture in reinforcement learning
In terms of specific implementation, human taggers act as conversational users and artificial intelligence assistants, providing conversation samples to allow The model generates some responses, and the tagger ranks the response options, feeding better results back to the model.
Agents learn from two feedback modes simultaneously - human reinforcement and Markov decision process reward as an integrated system, fine-tuning the model through reward strategies and continuously iterating.
On this basis, ChatGPT can understand and complete human language or instructions better than GPT-3, imitate humans, and provide coherent and logical text information.
▌3.4 Training of ChatGPT
The training process of ChatGPT is divided into the following three stages:
Phase 1: Training supervision strategy model
GPT 3.5 It is difficult to understand the different intentions contained in different types of human instructions, and it is also difficult to judge whether the generated content is a high-quality result.
In order for GPT 3.5 to initially have the intention to understand instructions, questions will first be randomly selected from the data set, and human annotators will give high-quality answers, and then these manually annotated data will be used to fine-tune GPT-3.5 Model (obtain SFT model, Supervised Fine-Tuning).
The SFT model at this time is already better than GPT-3 in following instructions/conversations, but does not necessarily match human preferences.
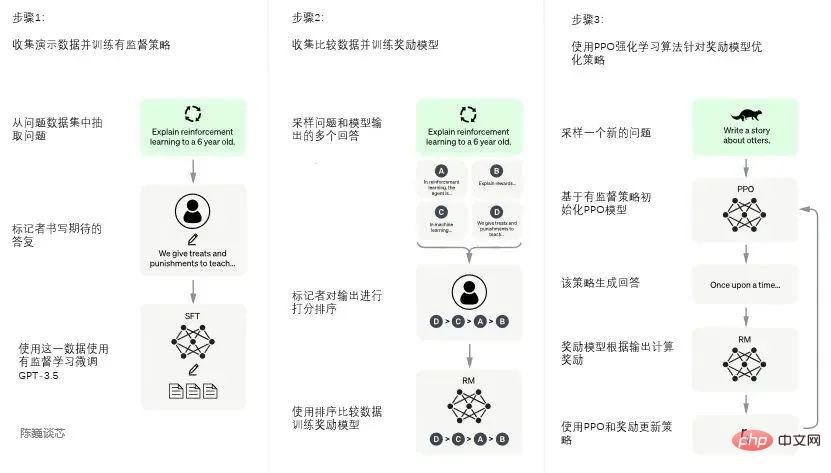
ChatGPT model training process
Second stage: Training reward model (Reward Mode, RM)
The main focus of this stage is The reward model is trained by manually annotating training data (about 33K data).
Randomly select questions from the data set, and use the model generated in the first stage to generate multiple different answers for each question. Human annotators take these results into consideration and give a ranking order. This process is similar to coaching or mentoring.
Next, use this ranking result data to train the reward model. Multiple sorting results are combined in pairs to form multiple training data pairs.
The RM model accepts an input and gives a score to evaluate the quality of the answer. In this way, for a pair of training data, the parameters are adjusted so that high-quality answers are scored higher than low-quality answers.
The third stage: Use PPO (Proximal Policy Optimization, proximal policy optimization) reinforcement learning to optimize the strategy.
The core idea of PPO is to transform the On-policy training process in Policy Gradient into Off-policy, that is, transform online learning into offline learning. This transformation process is called Importance Sampling.
This stage uses the reward model trained in the second stage and relies on reward scores to update the parameters of the pre-trained model. Randomly select questions from the data set, use the PPO model to generate answers, and use the RM model trained in the previous stage to give quality scores.
Pass the reward scores in sequence, thereby generating a policy gradient, and update the PPO model parameters through reinforcement learning.
If we continue to repeat the second and third stages, through iteration, a higher quality ChatGPT model will be trained.
4. Limitations of ChatGPT
As long as the user enters a question, ChatGPT can give an answer. Does this mean that we no longer need to feed keywords to Google or Baidu, and we can get what we want immediately? The answer?
Although ChatGPT has demonstrated excellent contextual dialogue capabilities and even programming capabilities, completing the public's change in the public's impression of the human-machine conversation robot (ChatBot) from "artificially retarded" to "interesting", we must also see that ChatGPT The technology still has some limitations and is still improving.
1) ChatGPT lacks "human common sense" and extension capabilities in areas where it has not been trained with a large amount of corpus, and may even speak serious "nonsense". ChatGPT can "create answers" in many areas, but when users seek correct answers, ChatGPT may also give misleading answers. For example, let ChatGPT do a primary school application question. Although it can write a long series of calculation processes, the final answer is wrong.
So should we believe the results of ChatGPT or not?
2) ChatGPT cannot handle complex, lengthy or particularly professional language structures. For questions from very specialized fields such as finance, natural sciences, or medicine, ChatGPT may not be able to generate appropriate answers if there is not enough corpus "feeding".
3) ChatGPT requires a very large amount of computing power (chips) to support its training and deployment. Regardless of the need for a large amount of corpus data to train the model, at present, the application of ChatGPT still requires the support of servers with large computing power, and the cost of these servers is beyond the reach of ordinary users. Even a model with billions of parameters requires staggering amount of computing resources to run and train. , if facing hundreds of millions of user requests from real search engines, if the currently popular free strategy is adopted, it will be difficult for any enterprise to bear this cost. Therefore, for the general public, they still need to wait for lighter models or more cost-effective computing platforms.
4) ChatGPT has not yet been able to incorporate new knowledge online, and it is unrealistic to re-pretrain the GPT model when some new knowledge appears. Regardless of training time or training cost, ordinary trainers hard to accept. If we adopt an online training model for new knowledge, it seems feasible and the corpus cost is relatively low, but it can easily lead to the problem of catastrophic forgetting of original knowledge due to the introduction of new data.
5) ChatGPT is still a black box model. At present, the internal algorithm logic of ChatGPT cannot be decomposed, so there is no guarantee that ChatGPT will not generate statements that attack or even harm users.
Of course, the flaws are not concealed. Some engineers posted a conversation asking ChatGPT to write verilog code (chip design code). It can be seen that the level of ChatGPT has exceeded that of some verilog beginners.
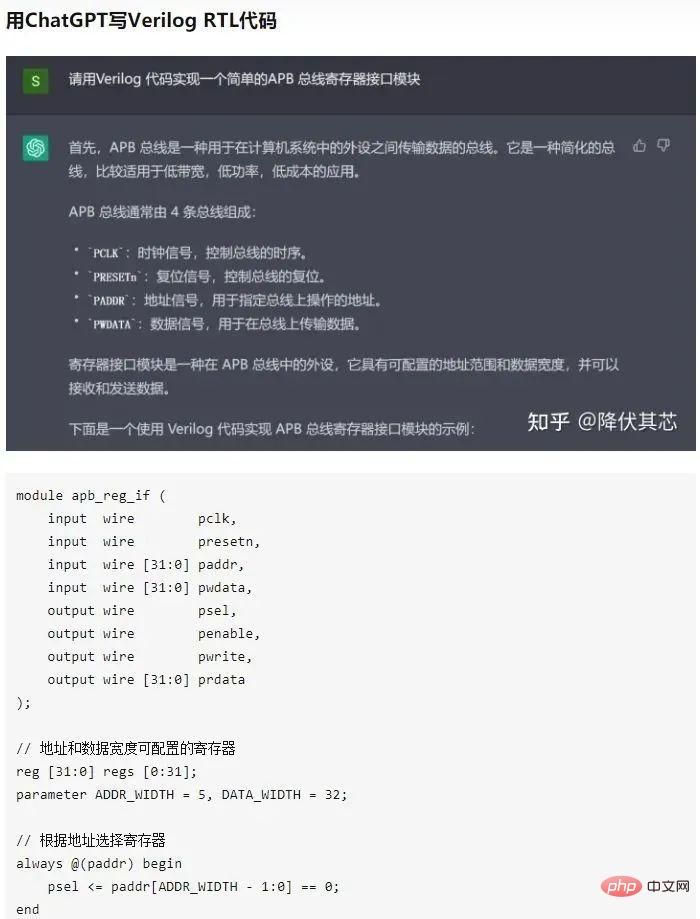
▌5.2 Make up for shortcomings in mathematics
Although ChatGPT has strong conversational skills, it is easy to talk serious nonsense in mathematical calculation conversations.
Computer scientist Stephen Wolfram proposed a solution to this problem. Stephen Wolfram created the Wolfram language and computing knowledge search engine Wolfram|Alpha, whose backend is implemented through Mathematica.
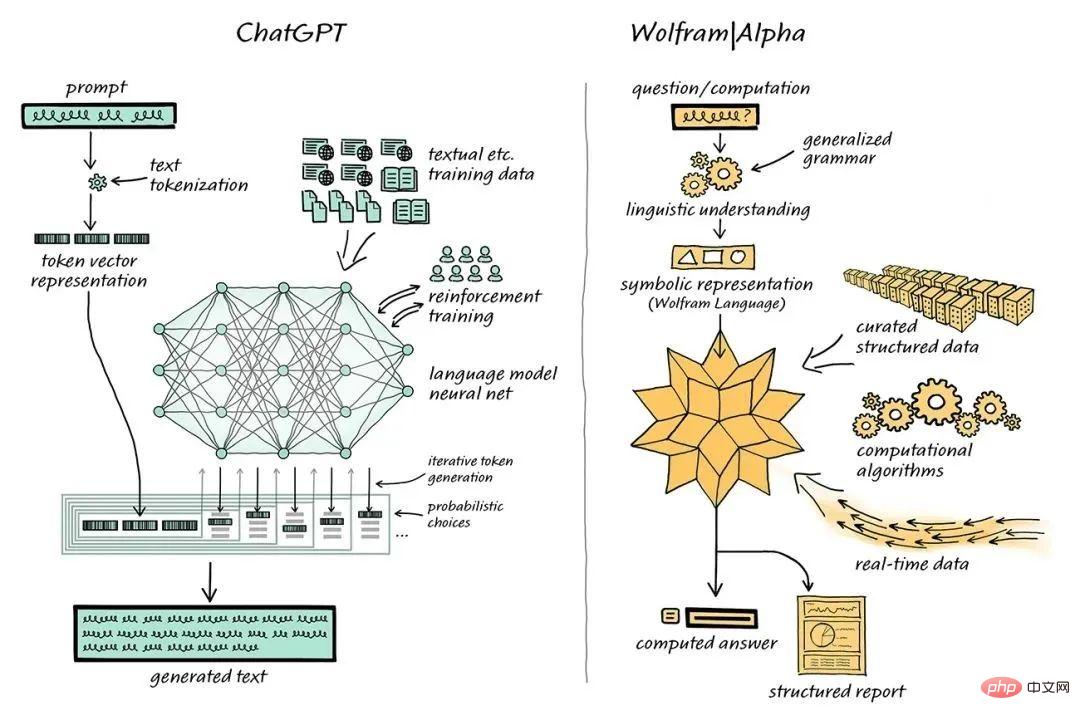
ChatGPT is combined with Wolfram|Alpha to handle the combing problem
In this combined system, ChatGPT can work with Wolfram| Alpha "conversations", Wolfram|Alpha will use its symbolic translation capabilities to "translate" the natural language expressions obtained from ChatGPT into the corresponding symbolic computing language.
In the past, the academic community has been divided on the "statistical methods" used by ChatGPT and the "symbolic methods" of Wolfram|Alpha.
But now the complementarity of ChatGPT and Wolfram|Alpha has provided the NLP field with the possibility of taking it to the next level.
ChatGPT does not have to generate such code, it only needs to generate regular natural language, and then use Wolfram|Alpha to translate it into precise Wolfram Language, and then the underlying Mathematica performs calculations.
▌5.3 Miniaturization of ChatGPT
Although ChatGPT is very powerful, its model size and usage cost also prohibit many people.
There are three types of model compression (model compression) that can reduce model size and cost.
The first method is quantization, which reduces the accuracy of the numerical representation of a single weight. For example, downgrading the Tansformer from FP32 to INT8 has little impact on its accuracy.
The second method of model compression is pruning, which removes network elements, including channels from individual weights (unstructured pruning) to higher-granularity components such as weight matrices. This approach is effective in vision and smaller scale language models.
The third model compression method is sparsification. For example, SparseGPT (arxiv.org/pdf/2301.0077) proposed by the Austrian Institute of Science and Technology (ISTA) can prune the GPT series model to 50% sparsity in a single step without any retraining. For the GPT-175B model, this pruning can be achieved in a few hours using only a single GPU.
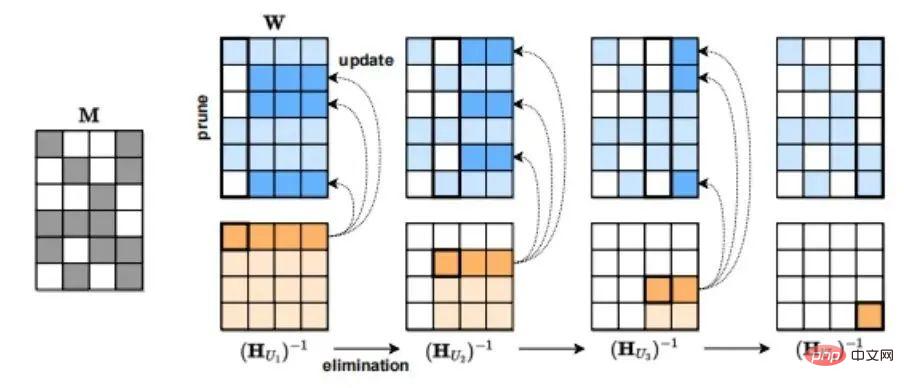
SparseGPT compression process
6. ChatGPT’s industrial future and investment opportunities
▌6.1 AIGC
Speaking ChaGPT has to mention AIGC.
AIGC uses artificial intelligence technology to generate content. Compared with UGC (user-generated content) and PGC (professionally produced content) in the previous Web1.0 and Web2.0 eras, AIGC, which represents artificial intelligence-conceived content, is a new round of content production method changes, and AIGC content is in Web3. There will also be exponential growth in the 0 era.
The emergence of the ChatGPT model is of great significance to the application of AIGC in text/voice mode and will have a significant impact on the upstream and downstream of the AI industry.
▌6.2 Benefit Scenarios
From the perspective of downstream related benefit applications, including but not limited to code-free programming, novel generation, conversational search engines, voice companions, voice work assistants, conversational virtual humans , artificial intelligence customer service, machine translation, chip design, etc.
From the perspective of upstream increased demand, including computing power chips, data annotation, natural language processing (NLP), etc.
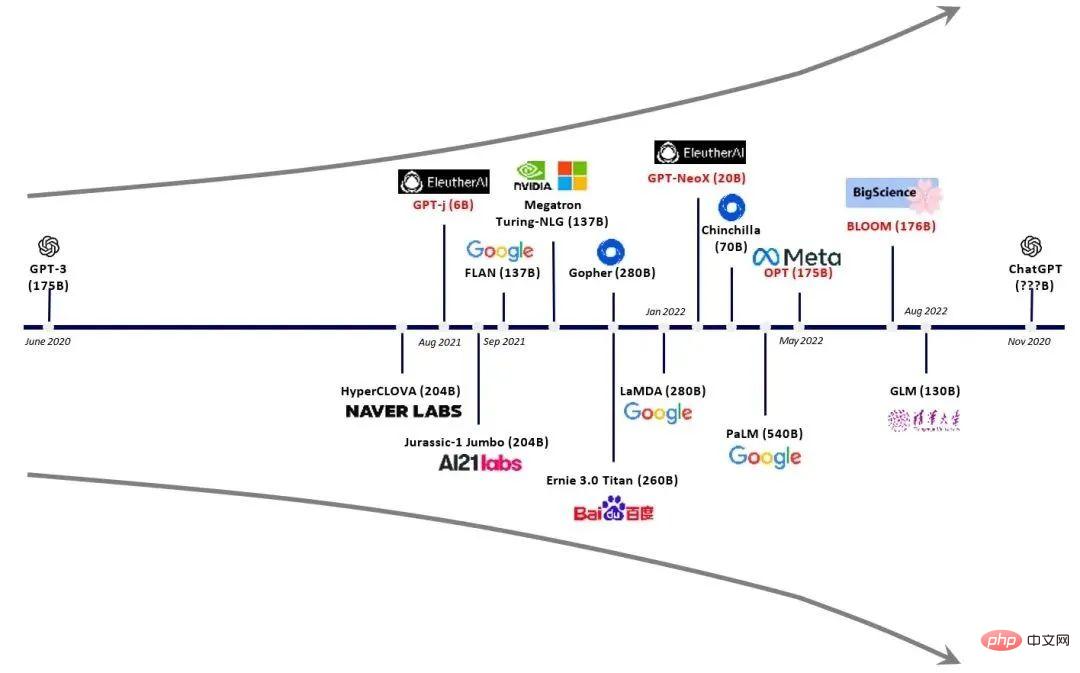
Large models are exploding (more parameters/greater computing power chip requirements)
With the continuous development of algorithm technology and computing power technology With progress, ChatGPT will also move towards a more advanced version with stronger functions, be applied in more and more fields, and generate more and better conversations and content for human beings.
Finally, the author asked about the status of integrated storage and computing technology in the field of ChatGPT (the author is currently focusing on promoting the implementation of integrated storage and computing chips). ChatGPT thought about it and boldly predicted that integrated storage and computing technology will be in the field of ChatGPT. dominate the chip. (Won my heart)
Reference:
- ChatGPT: Optimizing Language Models for Dialogue ChatGPT: Optimizing Language Models for Dialogue
- GPT论文:Language Models are Few-Shot Learners Language Models are Few-Shot Learners
- InstructGPT论文:Training language models to follow instructions with human feedback Training language models to follow instructions with human feedback
- huggingface解读RHLF算法:Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
- RHLF算法论文:Augmenting Reinforcement Learning with Human Feedback cs.utexas.edu/~ai-lab/p
- TAMER框架论文:Interactively Shaping Agents via Human Reinforcement cs.utexas.edu/~bradknox
- PPO算法:Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
The above is the detailed content of Interesting talk about the principles and algorithms of ChatGPT. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Analysis of the function and principle of nohup
Mar 25, 2024 pm 03:24 PM
Analysis of the function and principle of nohup
Mar 25, 2024 pm 03:24 PM
Analysis of the role and principle of nohup In Unix and Unix-like operating systems, nohup is a commonly used command that is used to run commands in the background. Even if the user exits the current session or closes the terminal window, the command can still continue to be executed. In this article, we will analyze the function and principle of the nohup command in detail. 1. The role of nohup: Running commands in the background: Through the nohup command, we can let long-running commands continue to execute in the background without being affected by the user exiting the terminal session. This needs to be run
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
