

Privacy computing has now become a necessity. On the one hand, individual users’ demands for personal privacy and information security have become stronger. On the other hand, there are a large number of privacy and security-related laws and regulations issued, such as the European Union’s GDPR, the United States’ CCPA and domestic personal information protection laws. Regulations and policies have gradually changed from loose to strict, mainly reflected in rights and interests, implementation scope and execution. Strength, etc. Taking GDPR as an example, since it came into effect in 2018, more than 1,000 cases have emerged, with a total fine of more than 11 billion, and the highest single fine exceeds 5 billion (Amazon).

 ##
##
#In this context, data security has changed from optional to mandatory. This has led to a large number of enterprises, investments, start-ups and practitioners investing in the security and privacy technology ecosystem, and the academic circle has conducted many forward-looking explorations in response to the needs of the industry. These factors have contributed to the vigorous development of security and privacy technologies and ecosystems in recent years, among which technologies such as differential privacy, trusted execution environments, homomorphic encryption, secure multi-party computation, and federated learning have all made great progress. Gartner is also optimistic about the development of this field, believing that it will be a market worth tens of billions or even hundreds of billions in the future.

Back to the background of Big Data AI, from a macro perspective of the industry, Big Data The framework and technology have been commercialized and popularized on a large scale. We may be using big data technology all the time, but we don’t feel that programs and model training are running on a server cluster of thousands or even tens of thousands of nodes and large-scale data. In recent years, there have been two new trends in the development direction of this field: one is the improvement of ease of use, and the other is the refinement of application directions. The former has greatly lowered the threshold for using big data technology, while the latter continues to provide new solutions to emerging needs and problems, such as data lakes.
#From the perspective of the combination with the AI framework, big data and the AI ecosystem are now closely integrated. Because for AI models, the larger the amount of data and the higher the quality, the better the training effect of the model, so the two fields of big data and AI will naturally be combined.
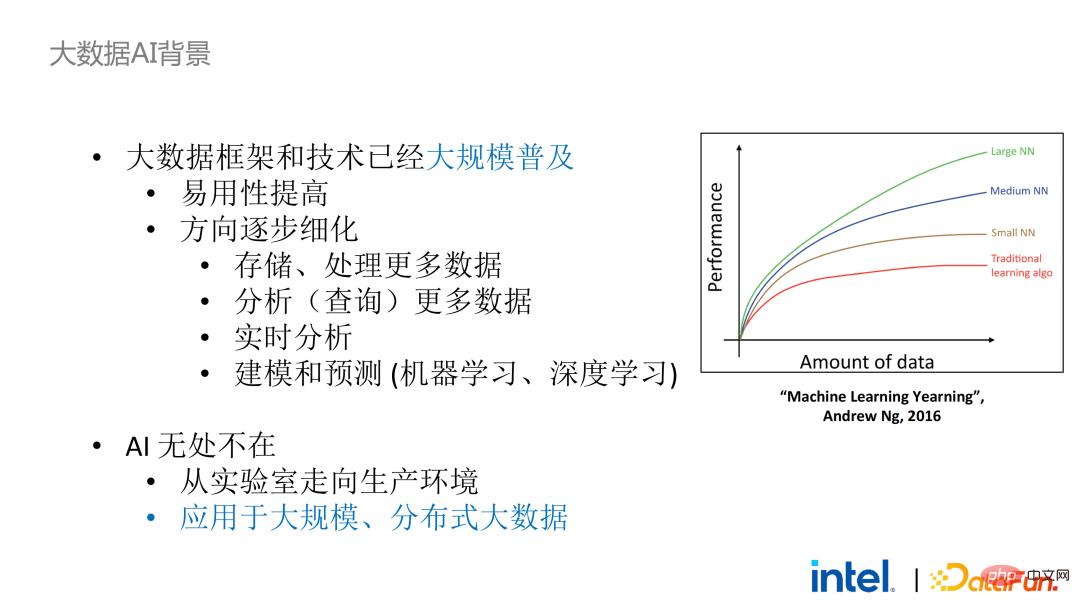
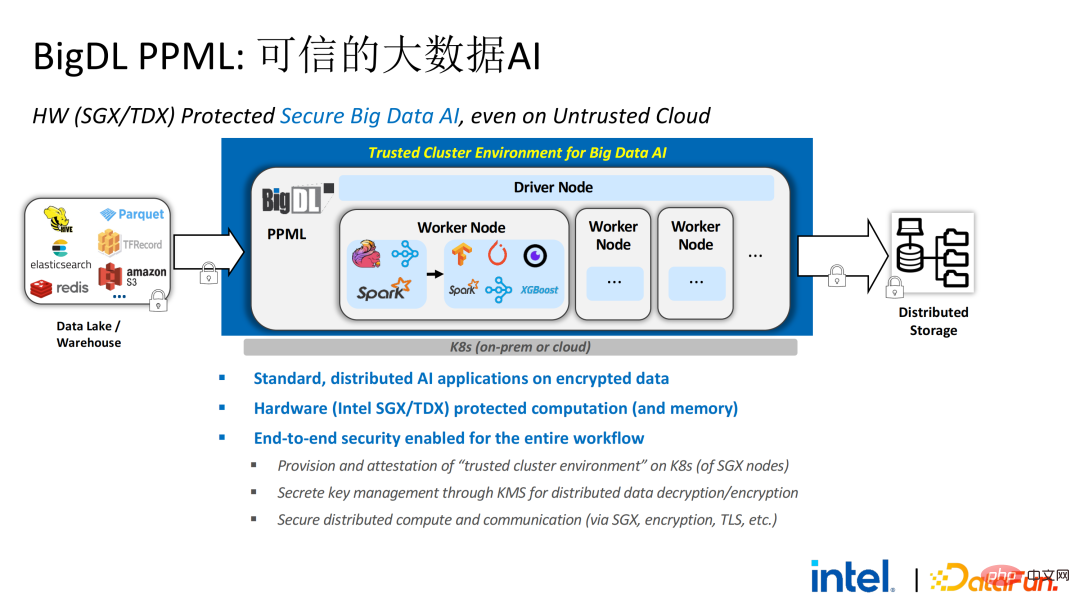
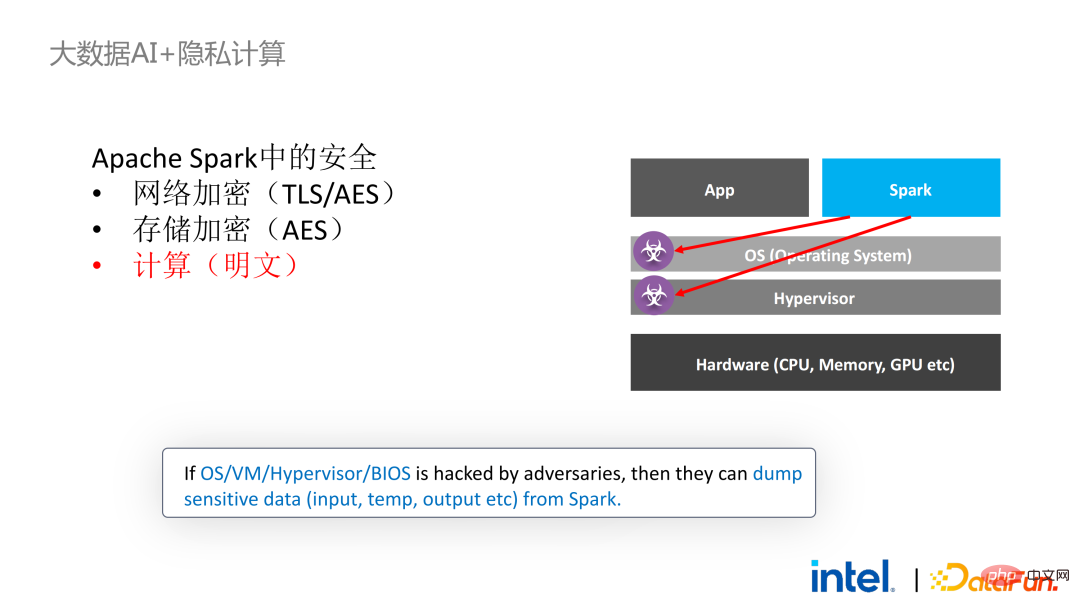
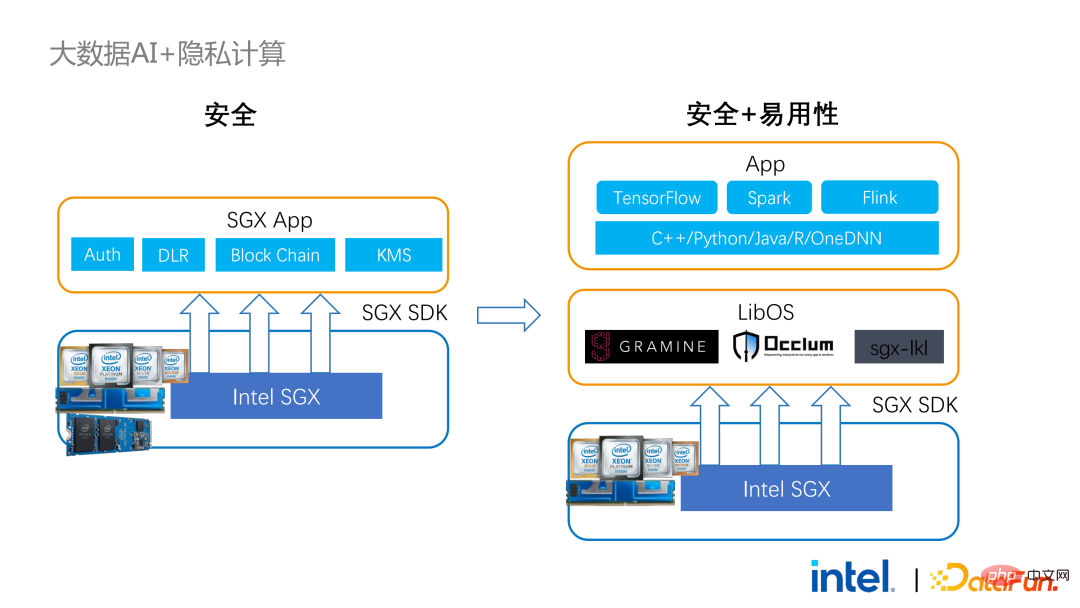
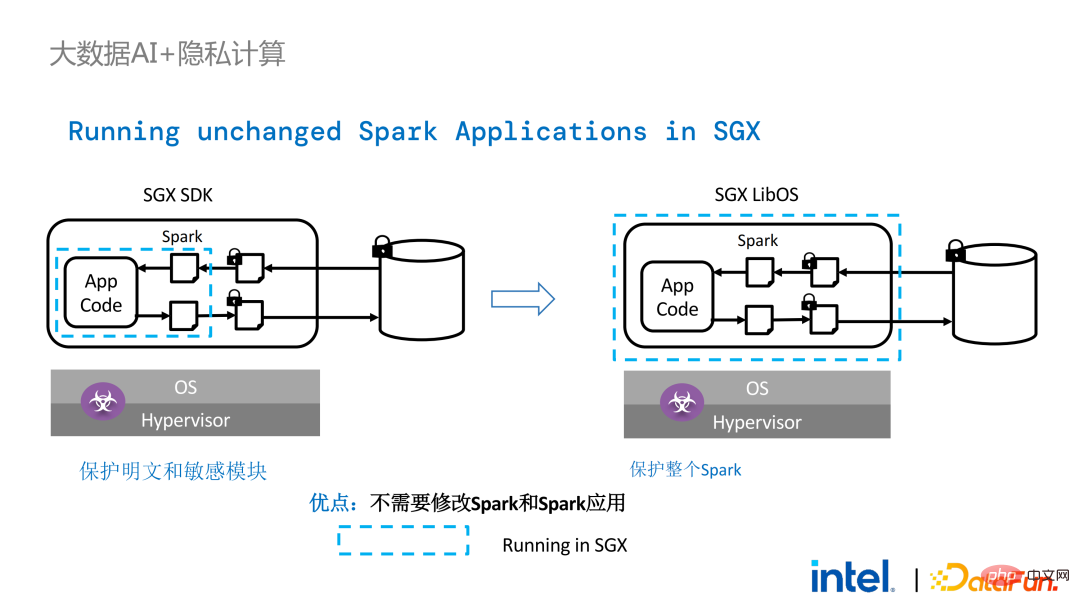
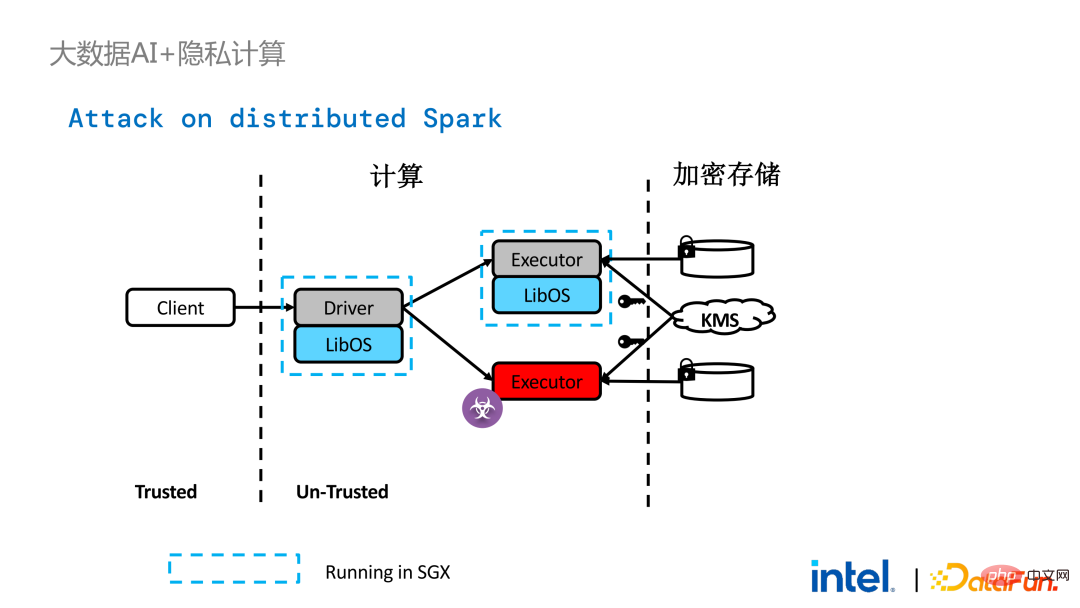
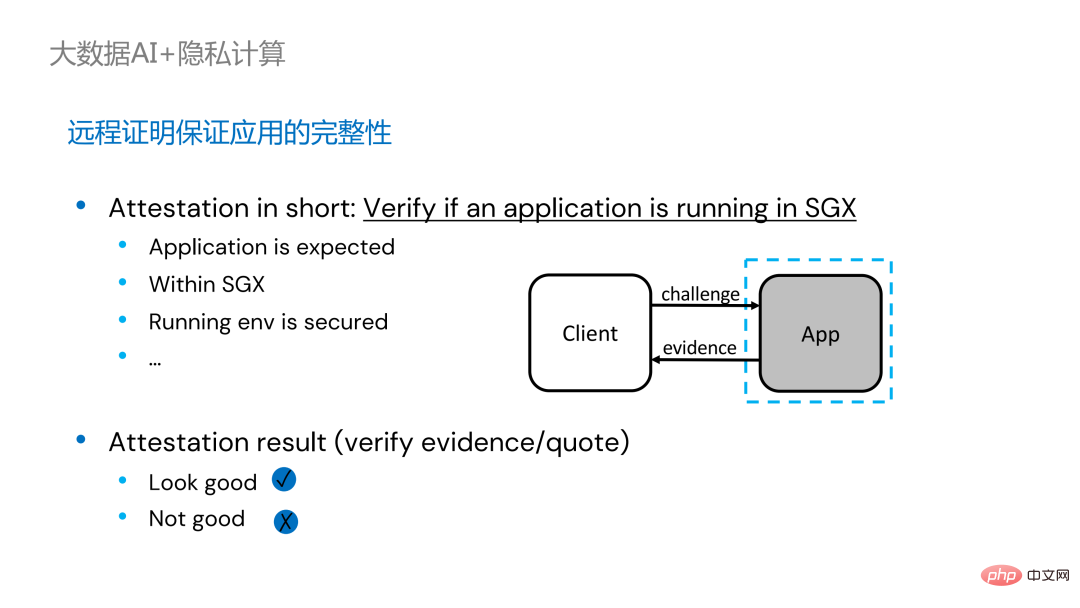
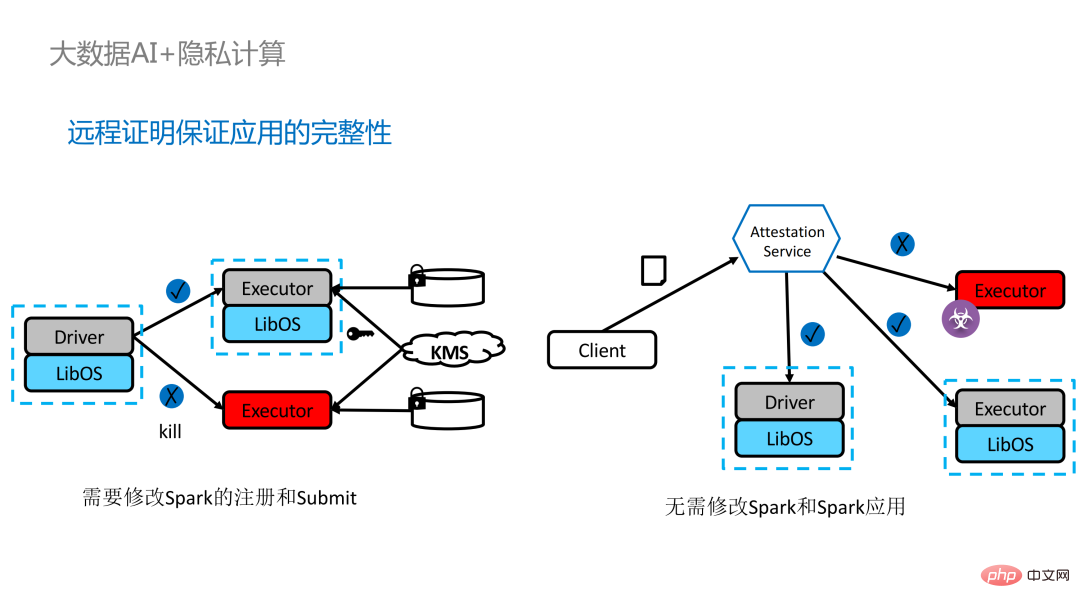
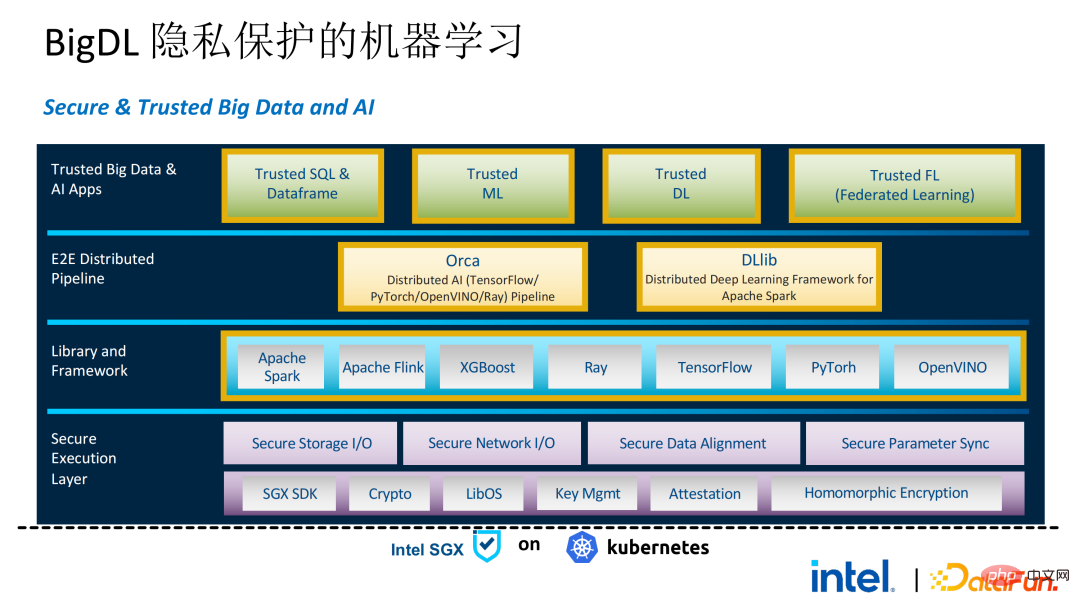
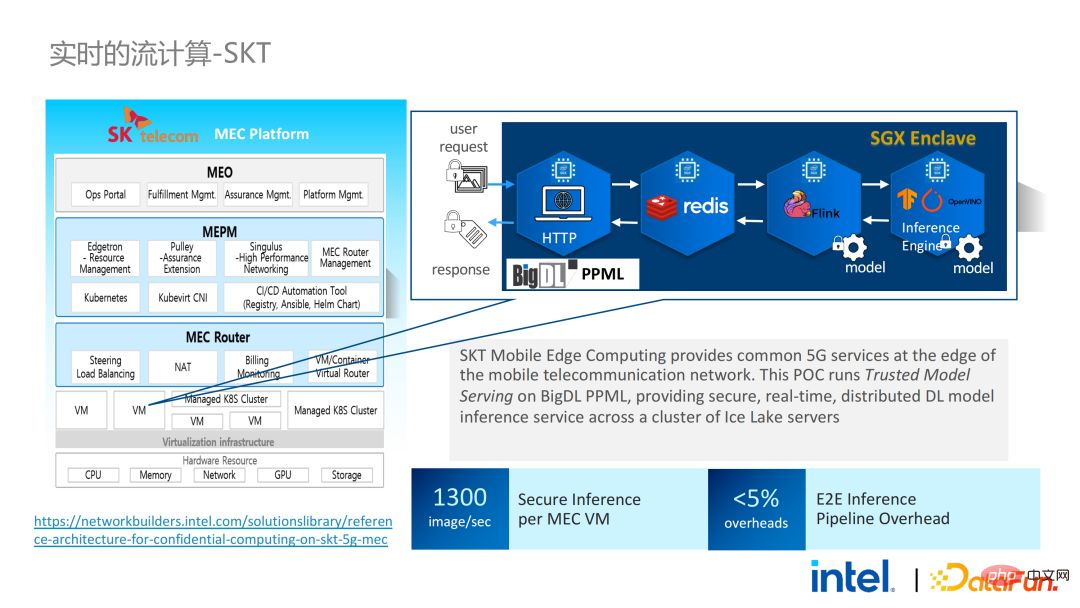
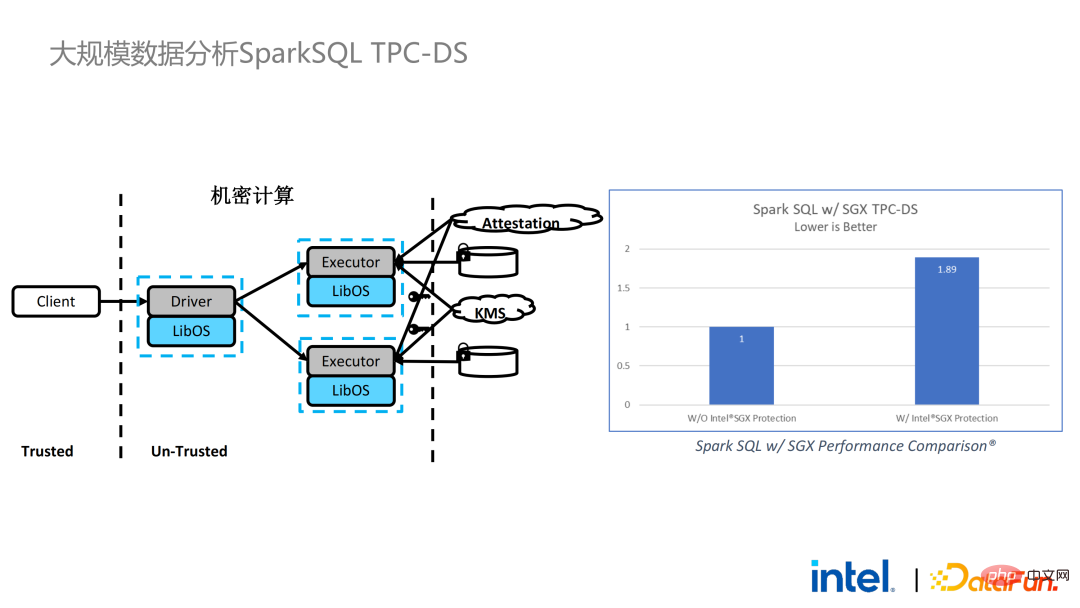
Two years ago, during the process of communicating with customers related to big data and AI applications in the industry, we Collected some user pain points. In addition to general performance issues, the first concern of most customers is compatibility issues. For example, some customers already have clusters with thousands or even tens of thousands of nodes. If they need to securely process some modules or links and apply privacy computing technology to achieve privacy protection functions, they may need to make changes to the existing applications. , or even introduce some completely new frameworks or infrastructures. These impacts are the primary issues that customers need to consider. Secondly, customers will consider the impact of data scale on security technology and hope that the introduced new frameworks and technologies can support the calculation of large-scale data and have high computing efficiency. Finally, customers will consider whether federated learning technology can solve the problem of data islands. Based on the customer needs obtained from the survey, we launched the BigDL PPML solution , The primary goal is to enable conventional, standard big data and AI solutions to run in a secure environment to ensure end-to-end security. For this purpose, the computing process needs to be protected by SGX (hardware-level TEE). At the same time, it is necessary to ensure that the storage and network are encrypted, and the entire link needs to be remotely attested (also called remote signature) to ensure the confidentiality and integrity of the calculation. ##Next weuse Apache Spark A commonly used big data framework is used as an example to elaborate on the necessity of this solution. Apache Spark is a commonly used distributed computing framework in the field of big data AI. It already has many security-related functions. For example, the network can be encrypted and authenticated, and communication and RPC are protected by TLS and AES; storage mainly involves Local shuffle storage is also protected by AES; however, there are major problems in calculation, because even the latest version of Spark can only perform plaintext calculations. If the computing environment or node is compromised, a large amount of sensitive data can be obtained. Hardware-level trustworthiness Information execution environment The left side shows the situation where the computing environment is not protected. Even if encrypted storage is used, as long as it is attacked during the plaintext calculation stage, there will be a risk of data leakage; the right side shows some attempts by the Spark community. , by extracting some key steps related to SparkSQL and rewriting this part of the logic with SGX SDK, we can both maximize performance and minimize the attack surface. However, the shortcomings of this method are also obvious, that is, the development cost is too high and the cost is too high. Rebuilding the core logic of SparkSQL requires a clear understanding of Spark; at the same time, the code cannot be reused in other projects. In order to solve the shortcomings mentioned above, we use the LibOS solution , in short, through the middle layer of LibOS, it reduces the difficulty of development and migration, and converts system API calls into a form that can be recognized by the SGX SDK, thereby achieving seamless migration of some conventional applications. Common LibOS solutions include Ant Group’s Occlum, Intel’s Gramine, and Imperial College’s sgx-lkl solution. The above LibOS all have their own features and advantages, and they solve the problems of SGX's ease of use and portability in different ways. ##With LibOS, there is no need to rewrite Spark Instead, it can put the entire Spark into SGX through LibOS without modifying Spark and existing applications. ##In Spark’s distributed computing, you can Each module in the distribution is protected by LibOS and SGX respectively. The storage side can be configured with key management and encrypted storage. The executor obtains the ciphertext data and decrypts and calculates it in SGX. The entire process is relatively insensitive to developers and has less impact on existing applications. #However, compared with stand-alone applications, security issues in distributed applications are also more complex. Attackers may compromise some operating nodes or collude with resource management nodes to replace the SGX environment with a malicious operating environment. In this way, keys and encrypted data can be illegally obtained, and ultimately private data can be leaked. remote attestation technology needs to be applied. To put it simply, applications running in SGX can provide certificates or certificates, and the certificates or certificates cannot be tampered with. The certificate can verify whether the application is running in SGX, whether the application has been tampered with, and whether the platform meets security standards. . On the left is a relatively complete but significantly modified solution. To perform remote attestation on the driver and executor sides, Spark needs to be modified to a certain extent. Another solution is to implement centralized remote certification through a third-party remote certification server, and use an unchangeable certificate to block modules controlled by attackers from obtaining data. The second option does not require modification of the application, but only requires modification of a small part of the startup script. , in which many steps can be automated and seamless migration can be achieved, greatly reducing migration costs. From a workflow perspective, this solution has another advantage, that is, data scientists cannot perceive underlying changes, and only cluster administrators need to participate in the deployment of SGX and preparation work, data scientists can carry out modeling and query work normally without being aware that the underlying environment has changed. This can well solve the compatibility and migration problems of existing applications, and will not hinder the daily work of data scientists and developers. The following is an overview of the entire PPML solution. In order to meet the different needs of customers, the functions supported by PPML have been continuously expanded in the past two years. For example, in the middle layer Library and Framework, commonly used computing frameworks such as Spark, Flink, and Ray are all supported; at the same time, PPML also supports machine learning, deep learning, and federated learning functions, and is equipped with support for encrypted storage and homomorphic encryption. , ensuring end-to-end full link security. The following is Some customers' application practice cases, the more famous one is last year's Tianchi Competition. In a sub-competition last year, the participants hoped that the training and model inference process could be completely protected by SGX. Through the Flink function provided by PPML and combined with Ant Group's LibOS project Occlum, the training and model inference could be made invisible at the application level. In the end, more than 4,000 teams participated in the entire competition, and hundreds of servers were used, proving that PPML can support large-scale commercial use, and overall, the operators did not perceive big changes. ##In September-October of the same year, Korea Telecom hoped to build an end-to-end secure , real-time model inference environment based on BigDL and Flink, they have more stringent performance requirements. After Tianchi’s experience, BigDL’s real-time model inference solution based on Flink and SGX has become more mature. The end-to-end performance loss is less than 5%, and the throughput has also met the basic needs of Korea Telecom. We also conducted Spark performance testing. In conclusion, even if the test data reaches hundreds of GB, there are no scalability and performance problems when the PPML solution runs Spark. Based on the customer's needs, we specifically selected TPC-DS, an IO-intensive application that is not friendly to SGX. TPC-DS is a commonly used SQL benchmark standard. It has relatively high IO and computing requirements. When the amount of data is large, large-scale disk, memory and network IO will occur. As a hardware-level TEE, data entering and exiting SGX needs to be decrypted and encrypted, so the cost of reading and writing data will be greater than that of non-SGX. After a complete TPC-DS test, the entire end-to-end loss was within 2 times, meeting customer expectations. Through the TPC-DS benchmark, we proved that even in this worst case, we can ensure that the end-to-end loss is reduced to an acceptable range (1.8). After realizing the seamless migration of big data applications, we also tried federated learning with some customers. Because SGX provides a secure environment, it can solve the most critical server and local data security issues in the federated learning process. There is a big difference between the federated learning solution provided by BigDL and the general solution, that is, the entire solution is essentially a federated learning solution for large-scale data. Among them, the workload and data size of each worker are relatively large, and each worker is equivalent to a small cluster. We have verified the feasibility and effectiveness of this solution with some customers. As mentioned above, in more than two years of communication and cooperation with customers, we have discovered We have reached several pain points related to privacy computing and big data AI. These pain points can be solved through security technologies such as SGX. Among them, LibOS can solve compatibility issues, SGX can solve security environment and performance issues; Spark or Flink support can solve big data and migration issues; federated learning can solve the data island problem. BigDL PPML is a one-stop privacy computing solution that integrates the above services. The ecology of SGX and TEE is currently developing rapidly. In the foreseeable future, TEE will be greatly improved in terms of ease of use, security and performance. For example, Intel's next-generation TDX can directly provide OS support, which can fundamentally solve application compatibility issues; open source The community is also improving support for confidential containers to ensure container security and greatly reduce the cost of application migration. From a security perspective, work such as microkernel will also appear to further strengthen the security of the TEE ecosystem. From a scalability perspective, Intel and the community are also promoting support for accelerators and IO devices, bringing them into the trusted domain to reduce the performance overhead of data flow. 
2. Big Data AI Privacy Computing

 ##
## ##SGX Technology
##SGX Technology
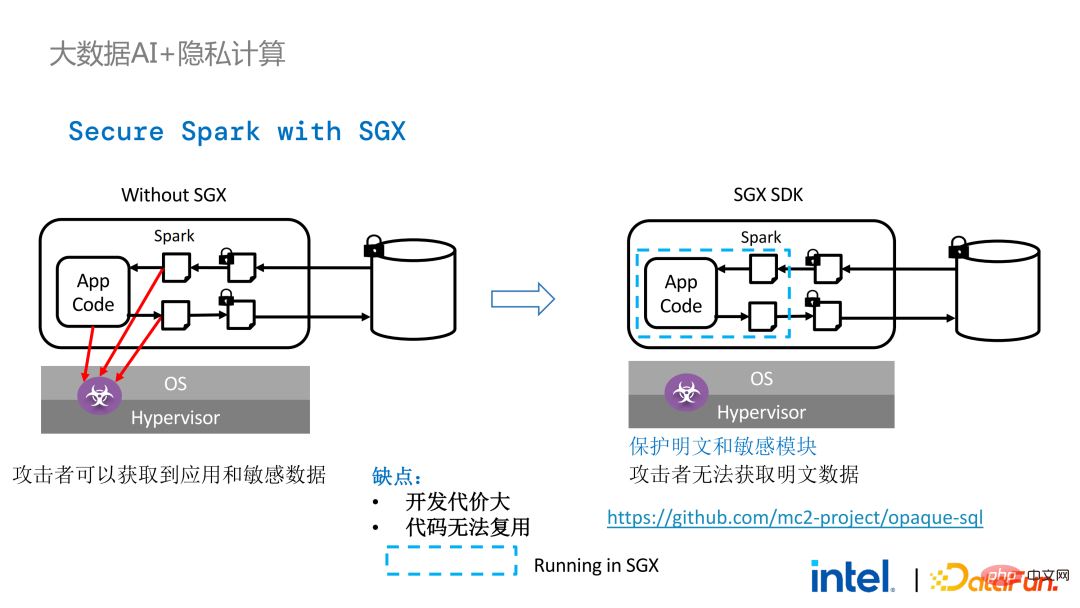
 ##Although LibOS allows Spark to run in SGX, it still costs a certain amount of time to adapt Spark to LibOS and SGX. Labor and time costs.
##Although LibOS allows Spark to run in SGX, it still costs a certain amount of time to adapt Spark to LibOS and SGX. Labor and time costs. 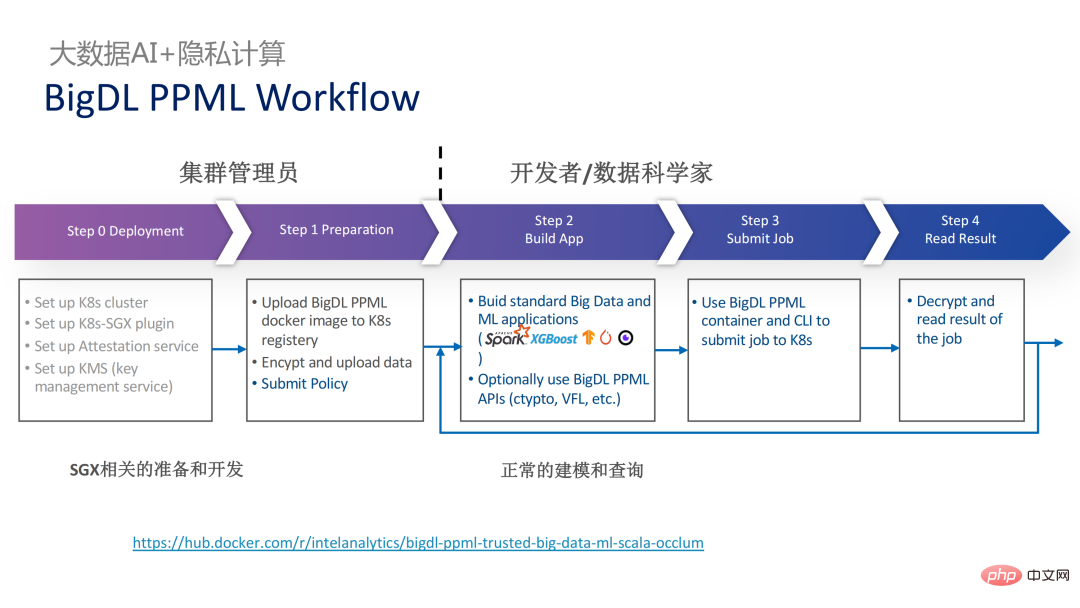
##03 Application Practice

04 Summary and Outlook


The above is the detailed content of Application practice of privacy computing in the field of big data AI. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



