

Synchronized is a reentrant exclusive lock, similar to the ReentrantLock lock function. It can be used almost anywhere synchronized is used. ReentrantLock instead. The biggest similarity between the two is: reentrant exclusive lock. The main differences between the two are as follows:
ReentrantLock has richer functions, such as providing Condition, Locking API that can be interrupted, complex scenarios that can satisfy lock queues, etc.;
ReentrantLock can be divided into fair locks and unfair locks, while synchronized are both unfair locks;
The usage postures of the two are also different. ReentrantLock needs to be stated that there is an API for locking and releasing locks, while synchronized will automatically lock and release the lock on the code block, and synchronized is more convenient to use. convenient.
synchronized and ReentrantLock have similar functions, so we will take synchronized as an example.
In a distributed system, we like to lock some dead configuration resources into the JVM memory when the project is started, so that the request can get these When the configuration resources are shared, they can be retrieved directly from the memory without having to retrieve them from the database every time, which reduces time overhead.
Generally, such shared resources include: dead business process configuration and dead business rule configuration.
The steps for shared resource initialization are generally: project startup -> trigger initialization action -> single thread to retrieve data from the database -> assemble into the data structure we need -> put in JVM memory .
When the project is started, in order to prevent shared resources from being loaded multiple times, we often add exclusive locks so that after one thread completes loading the shared resources, another thread can continue to load. At this time, the exclusive lock We can choose synchronized or ReentrantLock for the lock. We took synchronized as an example and wrote the mock code, as follows:
// 共享资源
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// 有无初始化完成的标志位
private static boolean loaded = false;
/**
* 初始化共享资源
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// 再次 check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// 从数据库中捞取数据,组装成 SHARED_MAP 的数据格式
loaded = true;
log.info("SynchronizedDemo init end");
}
}I don’t know if you have found the @PostConstruct annotation from the above code. The function of the @PostConstruct annotation is When the Spring container is initialized, the method marked with this annotation is executed. In other words, the init method shown in the above figure is triggered when the Spring container is started.
You can download the demo code, find the DemoApplication startup file, right-click run on the DemoApplication file to start the entire Spring Boot project, and put a breakpoint on the init method to debug.
We use synchronized in the code to ensure that only one thread can perform the operation of initializing shared resources at the same time, and we add a shared resource loading completion flag (loaded) to determine whether the loading is completed. If the loading is completed, other loading threads will return directly.
If you replace synchronized with ReentrantLock, the implementation is the same, except that you need to explicitly use the API of ReentrantLock to lock and release the lock. One thing to note when using ReentrantLock is that we need to add Lock, release the lock in the finally method block. This ensures that even if an exception occurs after adding the lock in try, the lock can be released correctly in finally.
Some students may ask, can't we use ConcurrentHashMap directly? Why do we need to lock it? It is true that ConcurrentHashMap is thread-safe, but it can only ensure thread safety during Map internal data operations. It cannot guarantee that in multi-threaded situations, the entire action of querying the database and assembling data is only executed once. What we add synchronized locks the entire operation, ensuring that the entire operation is only executed once.
1: Xiao Ming bought a product on Taobao and felt it was not good, so he returned the product (the product has not been shipped yet) , only refund), we call it a single product refund. When a single product refund is run in the background system, the overall time consumption is 30 milliseconds.
2: During Double 11, Xiao Ming bought 40 items on Taobao and generated the same order (actually multiple orders may be generated, for the convenience of description, we will call them one). The next day Xiao Ming discovered Among them, 30 items were purchased impulsively, and 30 items need to be returned together.
At this time, the backend only has the function of refunding single products, and there is no function of refunding batch products (returning 30 products at one time is called batch). In order to quickly implement this function , Student A did it according to this plan: a for loop called the single product refund interface 30 times. During the QA environment test, it was found that if 30 products were to be refunded, it would take: 30 * 30 = 900 milliseconds. Coupled with other logic, it takes almost 1 second to refund 30 products, which actually takes a long time. At that time, classmate A raised this question and hoped that everyone could help to optimize the time consumption of the entire scenario.
同学 B 当时就提出,你可以使用线程池进行执行呀,把任务都提交到线程池里面去,假如机器的 CPU 是 4 核的,最多同时能有 4 个单商品退款可以同时执行,同学 A 觉得很有道理,于是准备修改方案,为了便于理解,我们把两个方案都画出来,对比一下:
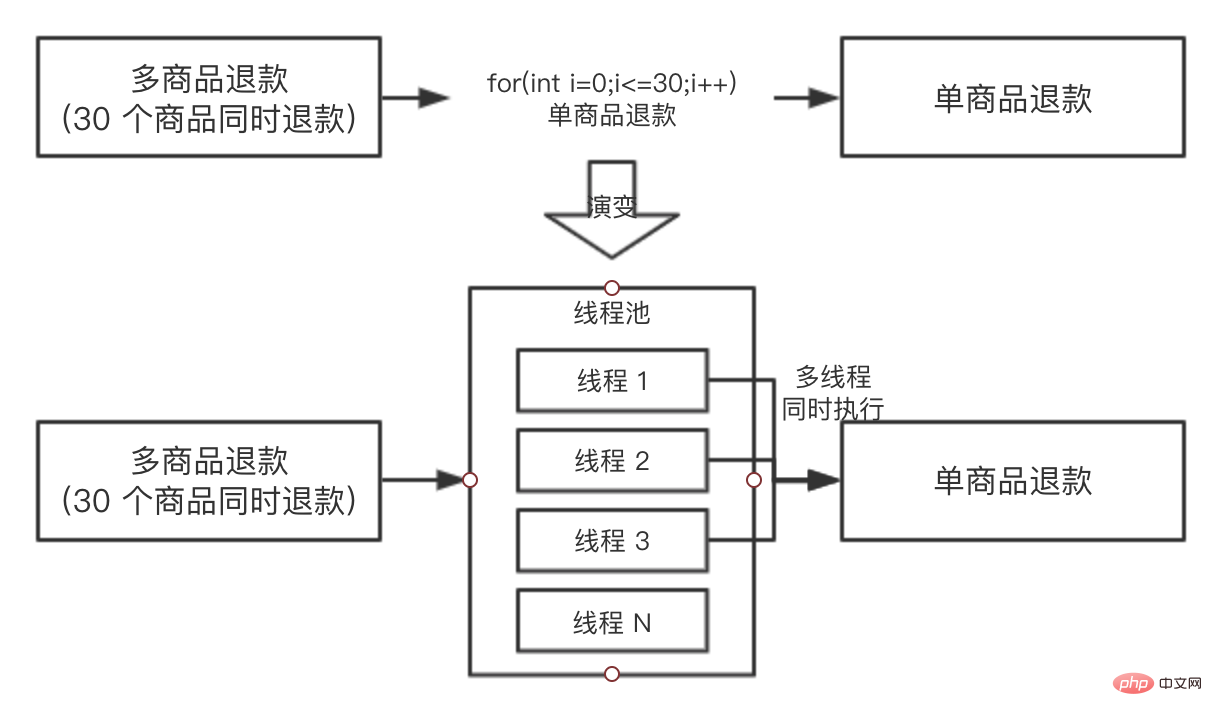
同学 A 于是就按照演变的方案去写代码了,过了一天,抛出了一个问题:向线程池提交了 30 个任务后,主线程如何等待 30 个任务都执行完成呢?因为主线程需要收集 30 个子任务的执行情况,并汇总返回给前端。
大家可以先不往下看,自己先思考一下,我们前几章说的那种锁可以帮助解决这个问题?
CountDownLatch 可以的,CountDownLatch 具有这种功能,让主线程去等待子任务全部执行完成之后才继续执行。
此时还有一个关键,我们需要知道子线程执行的结果,所以我们用 Runnable 作为线程任务就不行了,因为 Runnable 是没有返回值的,我们需要选择 Callable 作为任务。
我们写了一个 demo,首先我们来看一下单个商品退款的代码:
// 单商品退款,耗时 30 毫秒,退款成功返回 true,失败返回 false
@Slf4j
public class RefundDemo {
/**
* 根据商品 ID 进行退款
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// 线程沉睡 30 毫秒,模拟单个商品退款过程
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}接着我们看下 30 个商品的批量退款,代码如下:
@Slf4j
public class BatchRefundDemo {
// 定义线程池
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state 初始化为 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// 准备 30 个商品
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// 准备开始批量退款
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// 使用 Callable,因为我们需要等到返回值
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// 每个子线程都会执行 countDown,使 state -1 ,但只有最后一个才能真的唤醒主线程
countDownLatch.countDown();
return result;
}
});
// 收集批量退款的结果
futures.add(future);
}
log.info("30 个商品已经在退款中");
// 使主线程阻塞,一直等待 30 个商品都退款完成,才能继续执行
countDownLatch.await();
log.info("30 个商品已经退款完成");
// 拿到所有结果进行分析
List<Boolean> result = futures.stream().map(fu-> {
try {
// get 的超时时间设置的是 1 毫秒,是为了说明此时所有的子线程都已经执行完成了
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// 打印结果统计
long success = result.stream().filter(r->r.equals(true)).count();
log.info("执行结果成功{},失败{}",success,result.size()-success);
}
}上述代码只是大概的底层思路,真实的项目会在此思路之上加上请求分组,超时打断等等优化措施。
我们来看一下执行的结果:
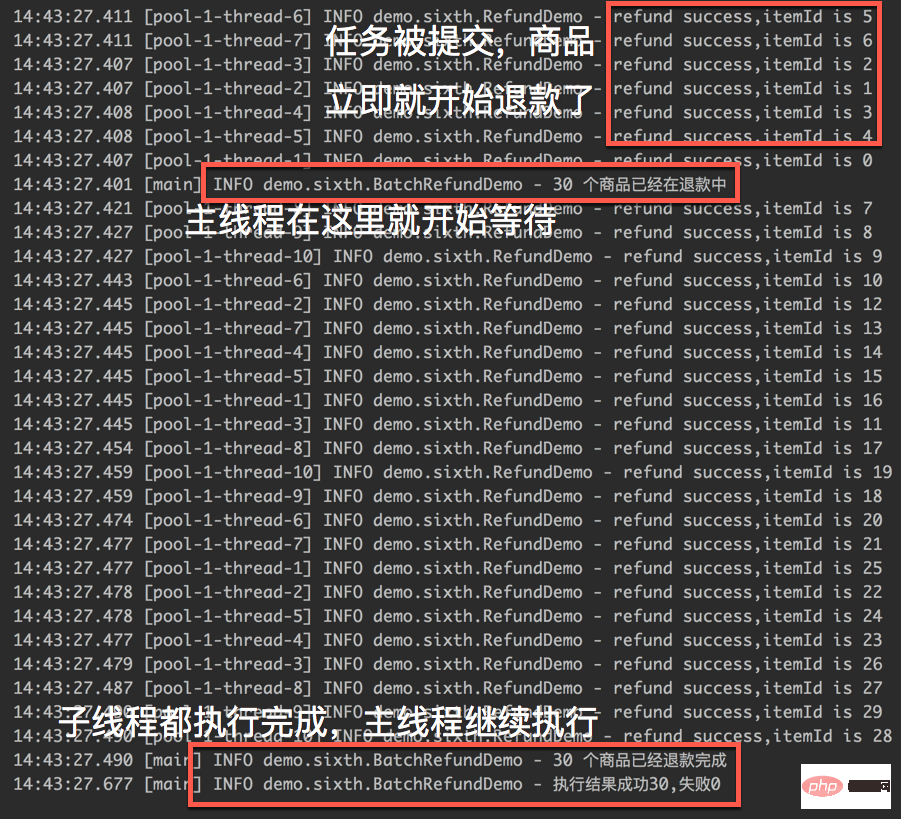
从执行的截图中,我们可以明显的看到 CountDownLatch 已经发挥出了作用,主线程会一直等到 30 个商品的退款结果之后才会继续执行。
接着我们做了一个不严谨的实验(把以上代码执行很多次,求耗时平均值),通过以上代码,30 个商品退款完成之后,整体耗时大概在 200 毫秒左右。
而通过 for 循环单商品进行退款,大概耗时在 1 秒左右,前后性能相差 5 倍左右,for 循环退款的代码如下:
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for 循环单个退款耗时{}",System.currentTimeMillis()-begin1);性能的巨大提升是线程池 + 锁两者结合的功劳。
The above is the detailed content of Analysis of Java lock usage scenarios at work. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



