
 Technology peripherals
AI
It only takes 3 seconds to steal your voice! Microsoft releases speech synthesis model VALL-E: Netizens exclaimed that the threshold for 'telephone fraud' has been lowered again
Technology peripherals
AI
It only takes 3 seconds to steal your voice! Microsoft releases speech synthesis model VALL-E: Netizens exclaimed that the threshold for 'telephone fraud' has been lowered again
It only takes 3 seconds to steal your voice! Microsoft releases speech synthesis model VALL-E: Netizens exclaimed that the threshold for 'telephone fraud' has been lowered again

Let ChatGPT help you write the script and Stable Diffusion generate illustrations. Do you need a voice actor to make a video? It's coming!
Recently, researchers from Microsoft released a new text-to-speech (TTS) model VALL-E, which only needs to provide three seconds of audio samples to simulate the input of human voices, and Corresponding audio is synthesized based on the input text, and the emotional tone of the speaker can also be maintained.

Thesis link: https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Project link: https://valle-demo.github. io/
Code link: https://github.com/microsoft/unilm
Let’s take a look at the effect first: Suppose you have a 3-second recording.
diversity_speaker Audio: 00:0000:03
Then just enter the text "Because we do not need it." to get the synthesized voice.
diversity_s1 Audio: 00:0000:01
Even using different random seeds, personalized speech synthesis can be performed.
diversity_s2 Audio: 00:0000:02
VALL-E can also maintain the speaker’s ambient sound, such as inputting this voice.
env_speaker Audio: 00:0000:03
Then according to the text "I think it's like you know um more convenient too.", you can output the synthesized speech while maintaining the ambient sound.
env_vall_eAudio: 00:0000:02
And VALL-E can also maintain the speaker's emotion, such as inputting an angry voice.
anger_ptAudio: 00:0000:03
Based on the text "We have to reduce the number of plastic bags.", you can also express angry emotions.
anger_oursAudio: 00:0000:02
There are many more examples on the project website.
Specifically, the researchers trained the language model VALL-E from discrete encodings extracted from off-the-shelf neural audio codec models, and treated TTS as a conditional language modeling task rather than Continuous signal regression.
In the pre-training stage, the TTS training data received by VALL-E reached 60,000 hours of English speech, which is hundreds of times larger than the data used by the existing system.
And VALL-E also demonstrates in-context learning capabilities. It only needs to use the 3-second registration recording of the unseen speaker as a sound prompt to synthesize high-quality personalized speech.
Experimental results show that VALL-E is significantly better than the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity, and can also preserve the speaker's emotion and the acoustics of the sound cues in the synthesis environment.
Zero-shot Speech Synthesis
Over the past decade, speech synthesis has made huge breakthroughs through the development of neural networks and end-to-end modeling.
But current cascaded text-to-speech (TTS) systems usually utilize a pipeline with an acoustic model and a vocoder that uses mel spectrograms as intermediate representations.
Although some high-performance TTS systems can synthesize high-quality speech from single or multiple speakers, it still requires high-quality clean data from the recording studio, which cannot be achieved with large-scale data scraped from the Internet. meet the data requirements and will lead to model performance degradation.
Due to the relatively small amount of training data, the current TTS system still has the problem of poor generalization ability.
Under the zero-shot task setting, for speakers who have not appeared in the training data, the similarity and naturalness of speech will drop sharply.
In order to solve the zero-shot TTS problem, existing work usually utilizes methods such as speaker adaption and speaker encoding, which require additional fine-tuning and complex pre-designed features. , or heavy structural work.
Rather than designing a complex and specialized network for this problem, given their success in text synthesis, the researchers believe the ultimate solution should be to train the model with as much diverse data as possible.
VALL-E model
In the field of text synthesis, large-scale unlabeled data from the Internet is directly fed into the model. As the amount of training data increases, the model performance is also constantly improving.
Researchers migrated this idea to the field of speech synthesis. The VALL-E model is the first TTS framework based on language models, utilizing massive, diverse, and multi-speaker speech data.
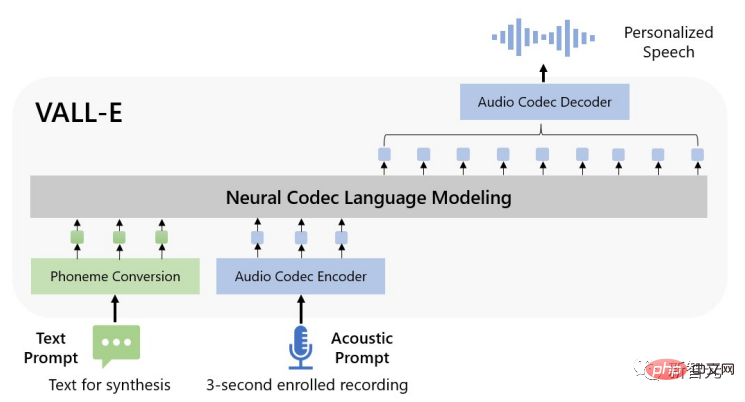
In order to synthesize personalized speech, the VALL-E model generates corresponding acoustic tokens based on the acoustic tokens and phoneme prompts of the 3-second enrolled recording. This information can limit the speaker. and content information.
Finally, the generated acoustic token is used to synthesize the final waveform with the corresponding neural codec.
The discrete acoustic tokens from the audio codec model enable TTS to be regarded as conditional codec language modeling, so some advanced hint-based large model techniques (such as GPTs) can be used in TTS tasks On.
Acoustic tokens can also use different sampling strategies during the inference process to produce diverse synthesis results in TTS.
The researchers trained VALL-E using the LibriLight dataset, which consists of 60,000 hours of English speech with more than 7,000 unique speakers. The raw data is audio-only, so only a speech recognition model is used to generate the transcripts.
Compared with previous TTS training datasets, such as LibriTTS, the new dataset provided in the paper contains more noisy speech and inaccurate transcriptions, but provides different speakers and registers (prosodies ).
The researchers believe that the method proposed in the article is robust to noise and can utilize big data to achieve good generality.

It is worth noting that existing TTS systems are always trained with dozens of hours of monolingual speaker data or hundreds of hours of multilingual speaker data. More than hundreds of times smaller than VALL-E.
In short, VALL-E is a brand-new language model method for TTS, which uses audio encoding and decoding codes as intermediate representations and uses a large amount of different data to give the model powerful contextual learning capabilities.
Reasoning: In-Context Learning via Prompting
Context learning (in-context learning) is an amazing ability of text-based language models, which can predict unseen Input labels without requiring additional parameter updates.
For TTS, if the model can synthesize high-quality speech for unseen speakers without fine-tuning, then the model is considered to have contextual learning capabilities.
However, existing TTS systems do not have strong in-context learning capabilities because they either require additional fine-tuning or suffer from significant degradation to unseen speakers.
For language models, prompting is necessary to achieve context learning in zero-shot situations.
The prompts and reasoning designed by the researchers are as follows:
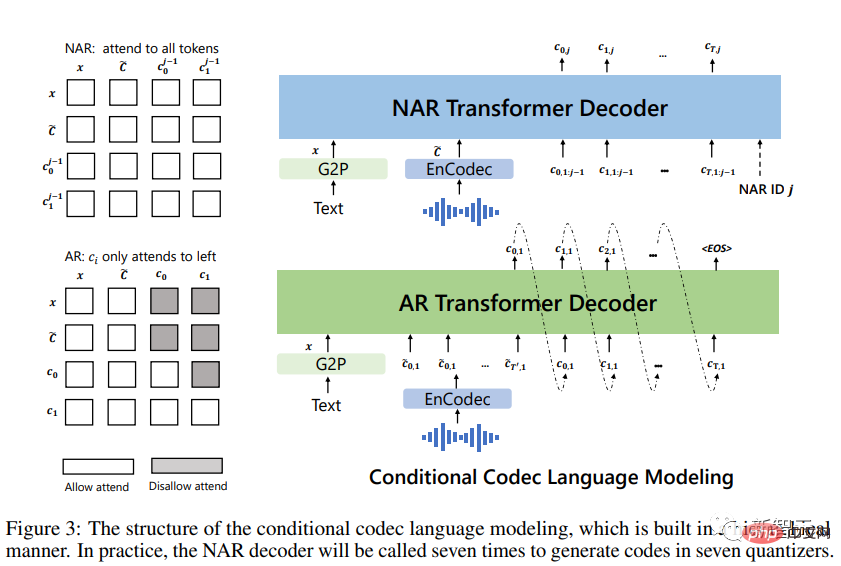
First convert the text into a phoneme sequence, and encode the enrolled recording into an acoustic matrix to form a phoneme prompt and an acoustic prompt, both of which Used in AR and NAR models.
For AR models, use sampling-based decoding conditional on hints, because beam search may cause LM to enter an infinite loop; in addition, sampling-based methods can greatly increase the diversity of outputs.
For the NAR model, use greedy decoding to select the token with the highest probability.
Finally, a neural codec is used to generate waveforms conditioned on the eight encoding sequences.
Acoustic cues may not necessarily have a semantic relationship with the speech to be synthesized, so they can be divided into two cases:
VALL-E: The main goal is for unseen speakers Generate the given content.
The input of this model is a text sentence, a piece of enrolled speech and its corresponding transcription. Add the transcribed phonemes of the enrolled speech as phoneme cues to the phoneme sequence of the given sentence, and use the first-level acoustic token of the registered speech as the acoustic prefix. With phoneme cues and acoustic prefixes, VALL-E generates an acoustic token for a given text, cloning the speaker's voice.
VALL-E-continual: Uses the entire transcript and the first 3 seconds of the utterance as phonemic and acoustic cues respectively, and asks the model to generate continuous content.
The reasoning process is the same as setting VALL-E, except that the enrolled speech and the generated speech are semantically continuous.
Experimental Section
The researchers evaluated VALL-E on the LibriSpeech and VCTK datasets, where all tested speakers did not appear in the training corpus.
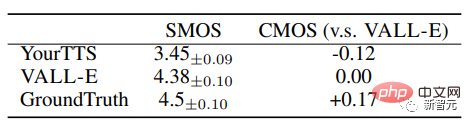
VALL-E significantly outperforms state-of-the-art zero-shot TTS systems in terms of speech naturalness and speaker similarity, with a 0.12 Comparative Average Option Score (CMOS) and a 0.93 Similarity Average on LibriSpeech Option Score (SMOS).
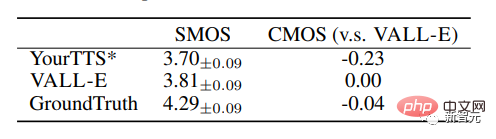
VALL-E also surpasses the baseline system with performance improvements of 0.11 SMOS and 0.23 CMOS on VCTK, even reaching a 0.04CMOS score against ground truth, indicating that on VCTK on, synthetic speech from unseen speakers is as natural as human recordings.
Furthermore, qualitative analysis shows that VALL-E is able to synthesize different outputs with 2 identical texts and target speakers, which may be beneficial for pseudo-data in speech recognition tasks create.
It can also be found in the experiment that VALL-E can maintain the sound environment (such as reverberation) and the emotion prompted by the sound (such as anger, etc.).
Security hazard
If powerful technology is misused, it may cause harm to society. For example, the threshold for phone fraud has been lowered again!
Due to VALL-E’s potential for mischief and deception, Microsoft has not opened VALL-E’s code or interfaces for testing.
Some netizens shared: If you call the system administrator, record a few words they say "Hello", and then re-synthesize the voice based on these words "Hello, I am the system administrator." "My voice is a unique identifier and can be safely verified." I always thought this was impossible. You couldn't accomplish this task with so little data. Now it seems that I may be wrong...
In the final Ethics Statement of the project, the researchers stated that "the experiments in this article were based on the model user as the target speaker and obtained performed under the assumption of speaker consent. However, when the model generalizes to unseen speakers, the relevant parts should be accompanied by speech editing models, including protocols to ensure that speakers agree to perform modifications and systems to detect edited speech.”

The author also states in the paper that since VALL-E can synthesize speech that maintains the identity of the speaker, it may bring potential risks of misuse of the model, Such as spoofing voice recognition or imitating a specific speaker.
To reduce this risk, a detection model can be built to distinguish whether an audio clip is synthesized by VALL-E. As we further develop these models, we will also put Microsoft AI principles into practice.
Reference materials:
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
The above is the detailed content of It only takes 3 seconds to steal your voice! Microsoft releases speech synthesis model VALL-E: Netizens exclaimed that the threshold for 'telephone fraud' has been lowered again. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Microsoft bing international version entrance address (bing search engine entrance)
Mar 14, 2024 pm 01:37 PM
Microsoft bing international version entrance address (bing search engine entrance)
Mar 14, 2024 pm 01:37 PM
Bing is an online search engine launched by Microsoft. The search function is very powerful and has two entrances: the domestic version and the international version. Where are the entrances to these two versions? How to access the international version? Let’s take a look at the details below. Bing Chinese version website entrance: https://cn.bing.com/ Bing international version website entrance: https://global.bing.com/ How to access Bing international version? 1. First enter the URL to open Bing: https://www.bing.com/ 2. You can see that there are options for domestic and international versions. We only need to select the international version and enter keywords.
 Why can't I hear the sound on WeChat Voice? What should I do if I can't hear the sound on WeChat Voice?
Mar 13, 2024 pm 02:31 PM
Why can't I hear the sound on WeChat Voice? What should I do if I can't hear the sound on WeChat Voice?
Mar 13, 2024 pm 02:31 PM
Why can’t I hear the sound on WeChat Voice? WeChat is an indispensable communication tool in our daily lives. Many users have encountered problems during use. For example, cannot hear the sound in WeChat voice? So what to do? Now let this site give users a detailed introduction to what to do if you can’t hear the sound in WeChat voice. What should I do if I can’t hear the sound in WeChat voice? 1. The sound set by the mobile phone system is relatively low or in a mute state. In this case, you can increase the volume or turn off the silent mode. 2. It is also possible that the WeChat speaker function is not turned on. Open "Settings" and select "Chat" option. 3. After clicking the "Chat" option
 Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
News on April 18th: Recently, some users of the Microsoft Edge browser using the Canary channel reported that after upgrading to the latest version, they found that the option to automatically save passwords was disabled. After investigation, it was found that this was a minor adjustment after the browser upgrade, rather than a cancellation of functionality. Before using the Edge browser to access a website, users reported that the browser would pop up a window asking if they wanted to save the login password for the website. After choosing to save, Edge will automatically fill in the saved account number and password the next time you log in, providing users with great convenience. But the latest update resembles a tweak, changing the default settings. Users need to choose to save the password and then manually turn on automatic filling of the saved account and password in the settings.
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
 Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
According to news from this site on April 27, Microsoft released the Windows 11 Build 26100 preview version update to the Canary and Dev channels earlier this month, which is expected to become a candidate RTM version of the Windows 1124H2 update. The main changes in the new version are the file explorer, Copilot integration, editing PNG file metadata, creating TAR and 7z compressed files, etc. @PhantomOfEarth discovered that Microsoft has devolved some functions of the 24H2 version (Germanium) to the 23H2/22H2 (Nickel) version, such as creating TAR and 7z compressed files. As shown in the diagram, Windows 11 will support native creation of TAR
 Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
According to news on March 21, Microsoft recently updated its Microsoft Edge browser and added a practical "enlarge image" function. Now, when using the Edge browser, users can easily find this new feature in the pop-up menu by simply right-clicking on the image. What’s more convenient is that users can also hover the cursor over the image and then double-click the Ctrl key to quickly invoke the function of zooming in on the image. According to the editor's understanding, the newly released Microsoft Edge browser has been tested for new features in the Canary channel. The stable version of the browser has also officially launched the practical "enlarge image" function, providing users with a more convenient image browsing experience. Foreign science and technology media also paid attention to this
 Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
In the second half of 2024, the official Microsoft Security Blog published a message in response to the call from the security community. The company plans to eliminate the NTLAN Manager (NTLM) authentication protocol in Windows 11, released in the second half of 2024, to improve security. According to previous explanations, Microsoft has already made similar moves before. On October 12 last year, Microsoft proposed a transition plan in an official press release aimed at phasing out NTLM authentication methods and pushing more enterprises and users to switch to Kerberos. To help enterprises that may be experiencing issues with hardwired applications and services after turning off NTLM authentication, Microsoft provides IAKerb and
