
 Technology peripherals
AI
Summarizing the past three years, MIT releases a review paper on AI accelerators
Technology peripherals
AI
Summarizing the past three years, MIT releases a review paper on AI accelerators
Summarizing the past three years, MIT releases a review paper on AI accelerators

In the past year, both startups and established companies have been slow to announce, launch and deploy artificial intelligence (AI) and machine learning (ML) accelerators. But it’s not unreasonable, and for many companies that publish accelerator reports, they spend three to four years researching, analyzing, designing, validating, and weighing the design of the accelerator and building the technology stack to program the accelerator. For those companies that have released upgraded versions of their accelerators, development cycles are still at least two to three years, although they report that they are shorter. The focus of these accelerators is still on accelerating deep neural network (DNN) models. The application scenarios range from extremely low-power embedded speech recognition and image classification to data center large model training. Competition in typical market and application areas continues, which is An important part of the shift from modern traditional computing to machine learning solutions for industrial and technology companies.
The AI ecosystem brings together components of edge computing, traditional high-performance computing (HPC), and high-performance data analytics (HPDA) that must work together to be effective Empower decision-makers, frontline staff and analysts. Figure 1 shows an architectural overview of this end-to-end AI solution and its components.
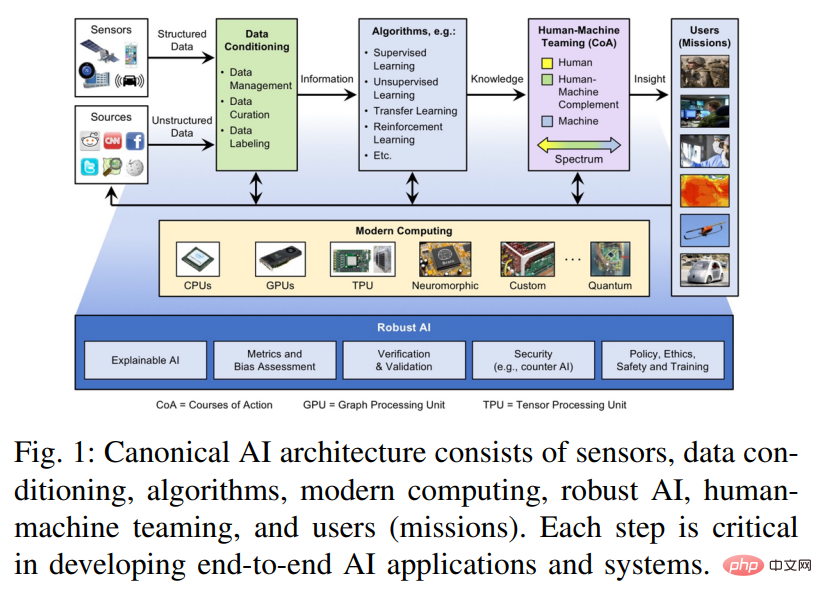
The original data first needs to be data curated. In this step, the data is fused, aggregated, structured, accumulated and converted into information. The information generated by the data wrangling step serves as input to supervised or unsupervised algorithms such as neural networks that extract patterns, fill in missing data or find similarities between data sets, and make predictions, thereby converting the input information into actionable Knowledge. This actionable knowledge will be transferred to humans and used in the decision-making process during the human-machine collaboration phase. The human-machine collaboration stage provides users with useful and important insights, transforming knowledge into actionable intelligence or insight.
Underpinning this system is a modern computing system. The trend of Moore's Law has ended, but at the same time many related laws and trends have been proposed, such as Denard's Law (power density), clock frequency, core count, instructions per clock cycle and instructions per Joule (Koomey's Law). From the system-on-a-chip (SoC) trend that first appeared in automotive applications, robotics, and smartphones, innovation continues to advance through the development and integration of accelerators of commonly used cores, methods, or functions. These accelerators offer different balances between performance and functional flexibility, including an explosion of innovation in deep learning processors and accelerators. By reading a large number of related papers, this article explores the relative advantages of these technologies, as they are particularly important when applying artificial intelligence to embedded systems and data centers that have extreme requirements on size, weight, and power.
This article is an update of IEEE-HPEC papers from the past three years. As in past years, this article continues to focus on accelerators and processors for deep neural networks (DNN) and convolutional neural networks (CNN), which are extremely computationally intensive. This article focuses on the development of accelerators and processors in inference, because many AI/ML edge applications rely heavily on inference. This article addresses all numeric precision types supported by accelerators, but for most accelerators their best inference performance is int8 or fp16/bf16 (IEEE 16-bit floating point or Google's 16-bit brain float).

##Paper link: https://arxiv.org/pdf/2210.04055.pdf
Currently, there have been many papers discussing AI accelerators. For example, the first paper in this series of surveys discusses the peak performance of FPGAs for certain AI models. Previous surveys have covered FPGAs in depth and are therefore no longer included in this survey. This ongoing survey effort and article aims to collect a comprehensive list of AI accelerators, including their computational capabilities, energy efficiency, and computational efficiency using accelerators in embedded and data center applications. At the same time, the article mainly compares neural network accelerators for government and industrial sensor and data processing applications. Some accelerators and processors included in previous years' papers have been excluded from this year's survey because they may have been replaced by new accelerators from the same company, are no longer maintained, or are no longer relevant to the topic .
Processor Survey
Many of the latest advances in artificial intelligence are due in part to improvements in hardware performance, which enable machine learning algorithms that require huge amounts of computing power, especially networks such as DNNs. The survey for this article gathered a variety of information from publicly available materials, including various research papers, technical journals, company-published benchmarks, etc. While there are other ways to obtain information on companies and startups (including those in silent periods), this article omits this information at the time of this survey and the data will be included in the survey when it becomes public. Key metrics from this public data are shown in the chart below, which reflects the latest processor peak performance versus power consumption capabilities (as of July 2022).
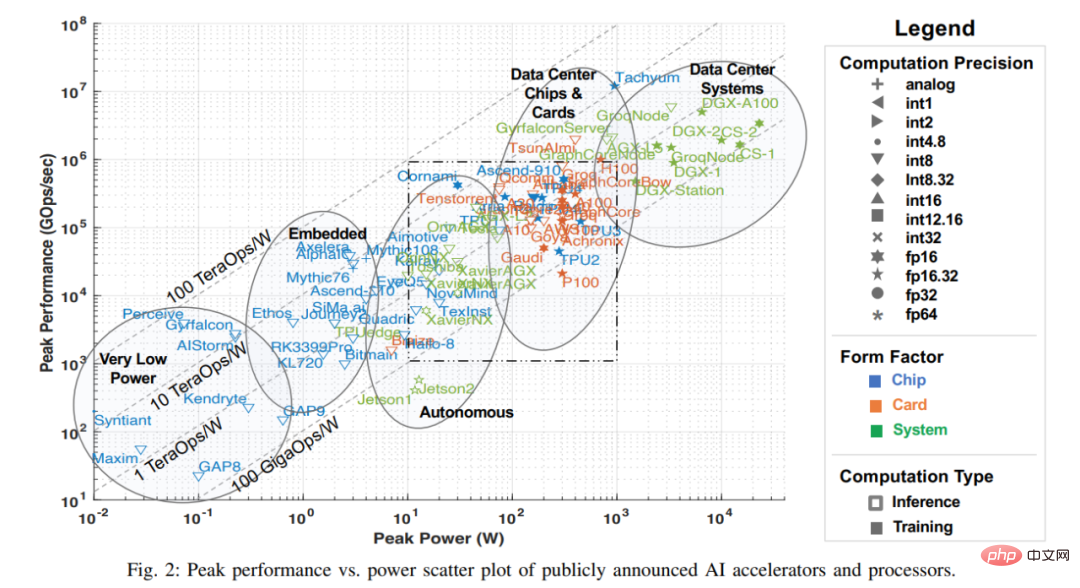
Note: The dotted box in Figure 2 corresponds to Figure 3 below. Figure 3 is an enlarged version of the dotted box. .
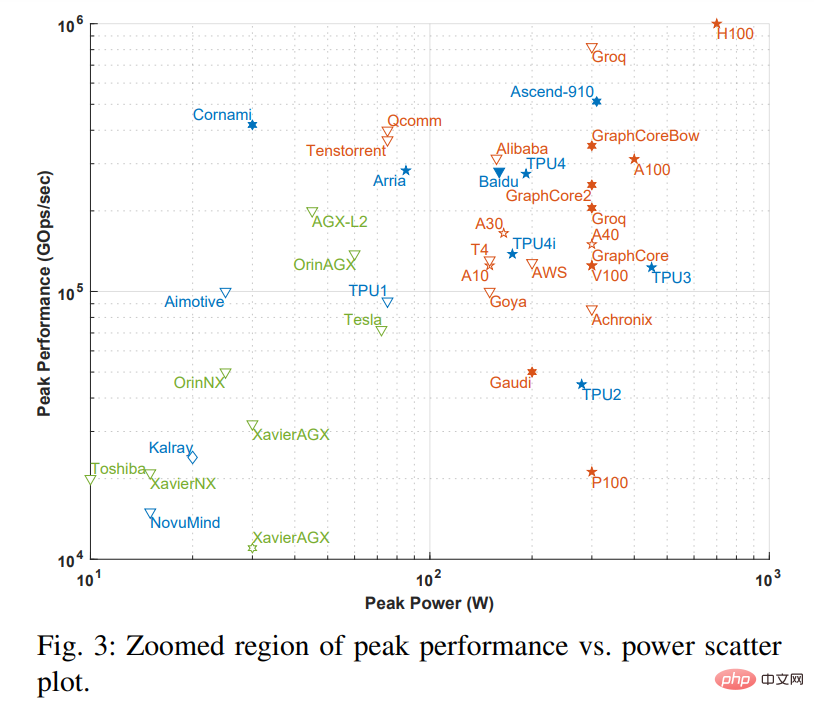
The x-axis in the figure represents the peak power, and the y-axis represents the peak gigabit operations per second (GOps/s), both are Logarithmic scale. The calculation accuracy of the processing power is represented by different geometries, ranging from int1 to int32 and from fp16 to fp64. There are two types of precision displayed. The left side represents the precision of multiplication operations, and the right side represents the precision of accumulation/addition operations (such as fp16.32 represents fp16 multiplication and fp32 accumulation/addition). Use colors and shapes to differentiate between different types of systems and peak power. Blue represents a single chip; orange represents a card; green represents an overall system (single-node desktop and server systems). This investigation is limited to single motherboard, single memory systems. The open geometries in the figure represent the top performance of accelerators that perform only inference, while the solid geometries represent the performance of accelerators that perform both training and inference.
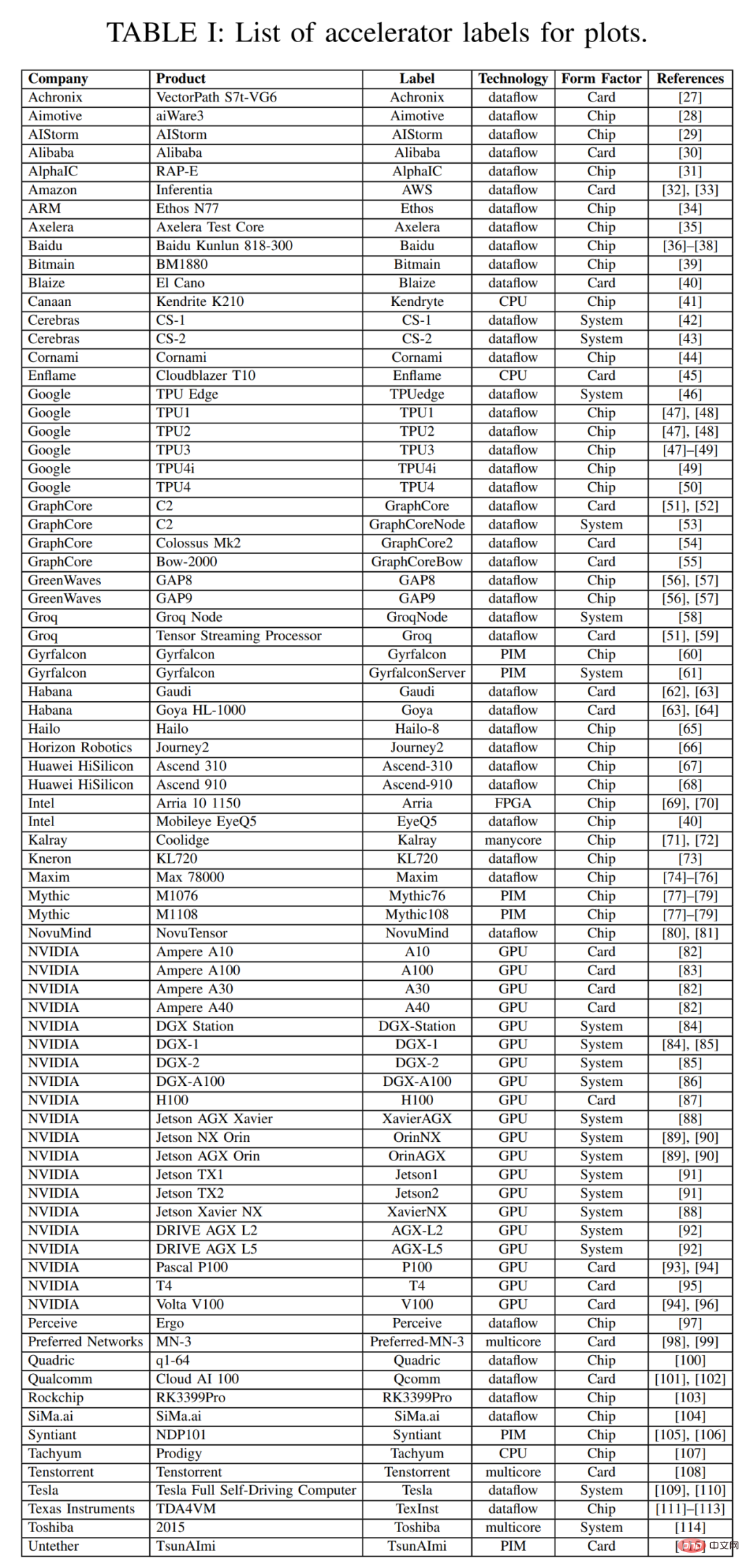
In this survey, this article begins with a scatter plot of survey data over the past three years. This article summarizes some important metadata for the accelerator, card, and overall system in Table 1 below, including labels for each point in Figure 2, with many points drawn from last year's survey. Most columns and entries in Table 1 are accurate and clear. But two technology items probably aren't: Dataflow and PIM. Dataflow-type processors are processors customized for neural network inference and training. Because neural network training and inference computations are built fully deterministically, they are suitable for dataflow processing, where computations, memory accesses, and inter-ALU communications are explicitly/statically programmed or placed and routed to the compute hardware. Processor in Memory (PIM) accelerators integrate processing elements with memory technology. Among these PIM accelerators are those based on analog computing technology that enhances flash memory circuits with in-place analog multiply-add functions. You can refer to the Mythic and Gyrfalcon accelerator materials for more details on this innovative technology.
#This article reasonably categorizes accelerators according to their expected applications. Figure 1 uses ellipses to identify five types of accelerators, corresponding to performance and power consumption. : Voice processing with very low power consumption and very small sensors; embedded cameras, small drones and robots; driver assistance systems, autonomous driving and autonomous robots; chips and cards for data centers; data center systems.
The performance, functions and other indicators of most accelerators have not changed. You can refer to papers in the past two years for relevant information. The following are accelerators that have not been included in past articles.
Dutch embedded systems startup Acelera claims that they produce embedded test chips with digital and analog design capabilities, and this test chip is to test the scope of digital design capabilities. They hope to add analog (and possibly flash) design elements in future work.
Maxim Integrated has released a system-on-chip (SoC) called the MAX78000 for ultra-low-power applications. It includes ARM CPU cores, RISC-V CPU cores, and AI accelerators. The ARM core is used for rapid prototyping and code reuse, while the RISC-V core is optimized for lowest power consumption. The AI accelerator has 64 parallel processors supporting 1-bit, 2-bit, 4-bit and 8-bit integer operations. The SoC operates at a maximum power of 30mW, making it suitable for low-latency, battery-powered applications.
Tachyum recently released an all-in-one processor called Prodigy. Each core of Prodigy integrates the functions of CPU and GPU. It is designed for HPC and machine learning applications. The chip has 128 high-performance unified cores. , operating frequency is 5.7GHz.
NVIDIA released its next-generation GPU called Hopper (H100) in March 2022. Hopper integrates more Symmetric Multiprocessors (SIMD and Tensor cores), 50% more memory bandwidth, and SXM mezzanine card instances with 700W power. (PCIe card power is 450W)
NVIDIA has released a series of system platforms over the past few years for deployment of Ampere architecture GPUs in automotive, robotics and other embedded applications. For automotive applications, the DRIVE AGX platform adds two new systems: DRIVE AGX L2 enables Level 2 autonomous driving in the 45W power range, and DRIVE AGX L5 enables Level 5 autonomous driving in the 800W power range. Jetson AGX Orin and Jetson NX Orin also use Ampere architecture GPUs for robotics, factory automation, and more, and they have a maximum peak power of 60W and 25W.
Graphcore releases its second-generation accelerator chip, the CG200, which is deployed on a PCIe card and has a peak power of approximately 300W. Last year, Graphcore also launched the Bow accelerator, the first wafer-to-wafer processor designed in partnership with TSMC. The accelerator itself is the same as the CG200 mentioned above, but it's paired with a second die that greatly improves power and clock distribution across the entire CG200 chip. This represents a 40% performance improvement and a 16% performance-per-watt improvement.
In June 2021, Google announced details of its fourth-generation pure inference TPU4i accelerator. Nearly a year later, Google has shared details of its 4th generation training accelerator, TPUv4. While the official announcement has few details, they did share peak power and related performance figures. Like previous TPU versions, TPU4 is available through Google Compute Cloud and used for internal operations.
The following is an introduction to accelerators that do not appear in Figure 2. Each version releases some benchmark results, but some lack peak performance and some do not publish peak performance. Power, as follows.
SambaNova released some benchmark results of reconfigurable AI accelerator technology last year. This year it also released a number of related technologies and published application papers in cooperation with Argonne National Laboratory. However, SambaNova did not provide any details and could only estimate the peak performance or power consumption of its solution from publicly available sources.
In May this year, Intel Habana Labs announced the launch of the second generation Goya inference accelerator and Gaudi training accelerator, named Greco and Gaudi2 respectively. Both perform several times better than previous versions. The Greco is a 75w single wide PCIe card, while the Gaudi2 is also a 650w double wide PCIe card (probably on a PCIe 5.0 slot). Habana published some benchmark comparisons of Gaudi2 against the Nvidia A100 GPU, but did not disclose peak performance figures for either accelerator.
Esperanto has produced some demo chips for Samsung and other partners to evaluate. The chip is a 1000-core RISC-V processor with an AI tensor accelerator per core. Esperanto has released some performance figures, but they don't disclose peak power or peak performance.
At Tesla AI Day, Tesla introduced their custom Dojo accelerator and some details of the system. Their chips have a peak 22.6 TF FP32 performance, but peak power consumption for each chip has not been announced, perhaps those details will be revealed at a later date.
Last year Centaur Technology launched an x86 CPU with an integrated AI accelerator, which has a 4096-byte wide SIMD unit and has very competitive performance. But Centaur's parent company, VIA Technologies, appears to have ended development of CNS processors after selling its U.S.-based processor engineering team to Intel.
Some Observations and Trends
There are several observations worth mentioning in Figure 2, as follows.
Int8 remains the default numeric precision for embedded, autonomous, and datacenter inference applications. This accuracy is sufficient for most AI/ML applications that use rational numbers. Also some accelerators use fp16 or bf16. Model training uses integer representation.
No additional features other than accelerators for machine learning have been found in the extremely low-power chips. In the ultra-low-power chip and embedded categories, it is common to release system-on-chip (SoC) solutions, often including low-power CPU cores, audio and video analog-to-digital converters (ADCs), cryptographic engines, network interfaces, etc. . These additional features of the SoC don't change the peak performance metrics, but they do have a direct impact on the peak power reported by the chip, so that's important when comparing them.
The embedded part has not changed much, which means that the computing performance and peak power are sufficient to meet the application needs in this field.
Over the past few years, several companies, including Texas Instruments, have launched AI accelerators. And NVIDIA has also released some better-performing systems for automotive and robotics applications, as mentioned earlier. In the data center, the PCIe v5 specification is highly anticipated in order to break through the 300W power limit of PCIe v4.
Finally, not only are high-end training systems releasing impressive performance numbers, but these companies are also releasing highly scalable interconnect technology to connect thousands of cards together. This is especially important for dataflow accelerators like Cerebras, GraphCore, Groq, Tesla Dojo, and SambaNova, which are programmed via explicit/static programming or place-and-route onto the compute hardware. This way it enables these accelerators to fit very large models like transformers.
Please refer to the original text for more details.
The above is the detailed content of Summarizing the past three years, MIT releases a review paper on AI accelerators. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
