
 Technology peripherals
AI
Super programmed AI appears on the cover of Science! AlphaCode Programming Contest: Half of the Programmers Are Contested
Technology peripherals
AI
Super programmed AI appears on the cover of Science! AlphaCode Programming Contest: Half of the Programmers Are Contested
Super programmed AI appears on the cover of Science! AlphaCode Programming Contest: Half of the Programmers Are Contested

This December, when OpenAI’s ChatGPT is gaining momentum, AlphaCode, which once overwhelmed half of the programmers, is on the cover of Science!

Paper link: https://www.science.org/doi/10.1126/science.abq1158
Speaking of AlphaCode, everyone must be familiar with it.
As early as February this year, it quietly participated in 10 programming competitions on the famous Codeforces and defeated half of the human coders in one fell swoop.
Half of the programmers will be beaten
We all know that this kind of test is very popular among programmers-programming competition.
In the competition, the main test is the programmer's ability to think critically through experience and create solutions to unforeseen problems.
This embodies the key to human intelligence, and machine learning models are often difficult to imitate this kind of human intelligence.
But the scientists at DeepMind broke this rule.
YujiA Li et al. developed AlphaCode using self-supervised learning and an encoder-decoder converter architecture.

##The development work of AlphaCode was completed while at home
Although AlphaCode is also based on the standard Transformer codec architecture, DeepMind has enhanced it at an "epic level" -
It uses a Transformer-based language models, generate code at an unprecedented scale, and then cleverly filter out a small subset of available programs.
The specific steps are:
1) Multi-ask attention: let each attention block share the key and value header, and At the same time, combined with the encoder-decoder model, the sampling speed of AlphaCode is increased by more than 10 times.
2) Masked Language Modeling (MLM): By adding an MLM loss to the encoder, the solution rate of the model is improved.
3) Tempering: Make the training distribution sharper, thereby preventing the regularization effect of overfitting.
4) Value conditioning and prediction: Provide an additional training signal by distinguishing correct and incorrect question submissions in the CodeContests dataset.
5) Exemplary Out-of-Strategy Learning Generation (GOLD): Let the model produce the correct solution for each problem by focusing training on the most likely solution to each problem .
Well, everyone knows the result.
With an Elo score of 1238, AlphaCode has ranked in the top 54.3% in these 10 games. Looking at the previous 6 months, this result reached the top 28%.
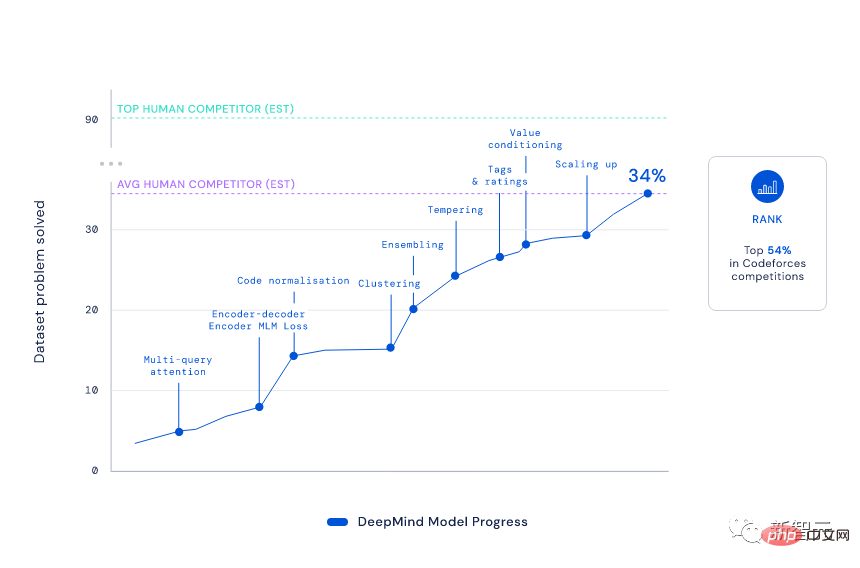
You must know that in order to achieve this ranking, AlphaCode must "pass five levels and defeat six generals", solving problems that integrate critical thinking, logic, and algorithms , various new problems combining coding and natural language understanding.
Judging from the results, AlphaCode not only solved 29.6% of the programming problems in the CodeContests data set, but 66% of them were solved in the first submission. (The total number of submissions is limited to 10 times)
In comparison, the solution rate of the traditional Transformer model is relatively low, only single digits.
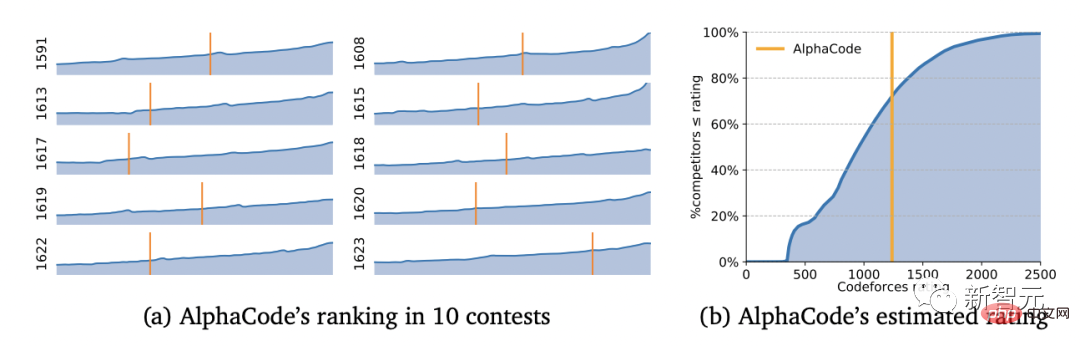
Even Codeforces founder Mirzayanov was very surprised by this result.
After all, programming competitions test the ability to invent algorithms, which has always been the weakness of AI and the strength of humans.
I can definitely say that the results from AlphaCode exceeded my expectations. I was skeptical at first because even in simple competition problems one not only needs to implement the algorithm but also invent it (which is the hardest part). AlphaCode has made itself a formidable opponent for many humans. I can't wait to see what the future holds!
——Mike Mirzayanov, founder of Codeforces
So, can AlphaCode steal programmers’ jobs?
Of course not.
AlphaCode can only complete simple programming tasks. If the tasks become more complex and the problems become more "unforeseeable", AlphaCode, which only translates instructions into codes, will be helpless.
After all, from a certain perspective, a score of 1238 is equivalent to the level of a middle school student who is just learning to program. At this level, it is not a threat to real programming experts.
But there is no doubt that the development of this type of coding platform will have a huge impact on programmer productivity.
Even the entire programming culture may be changed: perhaps, in the future, humans will only be responsible for formulating problems, and the tasks of generating and executing code can be handed over to machine learning.
What’s so difficult about programming competitions?
We know that although machine learning has made great progress in generating and understanding text, most AI is still limited to simple mathematics and programming problems.
What they will do is to retrieve and copy existing solutions (I believe anyone who has played ChatGPT recently will understand this).
So, why is it so difficult for AI to learn to generate the correct program?
1. To generate code that solves a specified task, you need to search in all possible character sequences. This is a massive space, and only a small part of it corresponds to the valid correct program.
2. A single character edit may completely change the behavior of the program or even cause it to crash, and each task has many distinct and valid solutions.
For extremely difficult programming competitions, AI needs to understand complex natural language descriptions; it needs to reason about problems it has never seen before, rather than simply memorizing code snippets; Requires mastery of various algorithms and data structures, and precise completion of code that may be hundreds of lines long.
In addition, to evaluate the code it generates, the AI also needs to perform tasks on an exhaustive set of hidden tests and check for execution speed and edge-case correctness.

(A) Problem 1553D, with a medium difficulty score of 1500; (B) Problem solution generated by AlphaCode
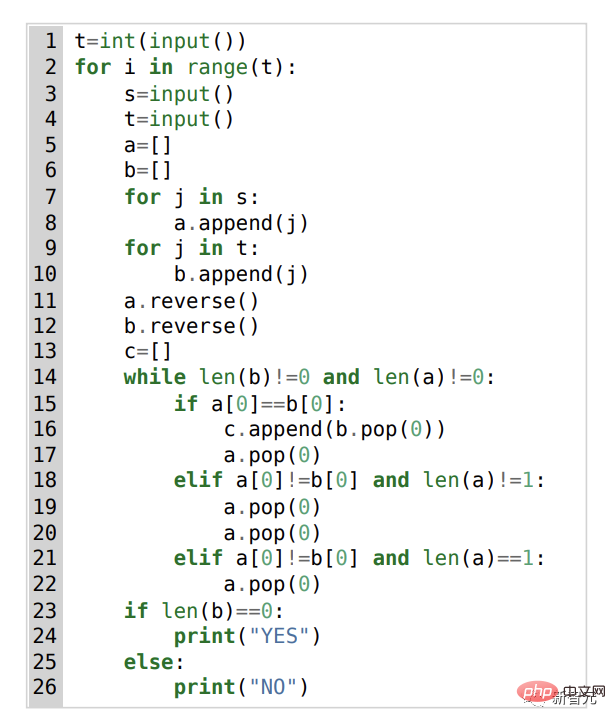
Take this 1553D problem as an example. Participants need to find a way to convert a string of randomly repeated s and t letters into another string of the same letters using a limited set of inputs. .
Contestants cannot just enter new letters, but must use the "backspace" command to delete several letters from the original string. The specific questions are as follows:

In this regard, the solution given by AlphaCode is as follows:
Moreover, AlphaCode’s “problem-solving ideas” are no longer It is a black box that also shows the location of the code and attention highlights.
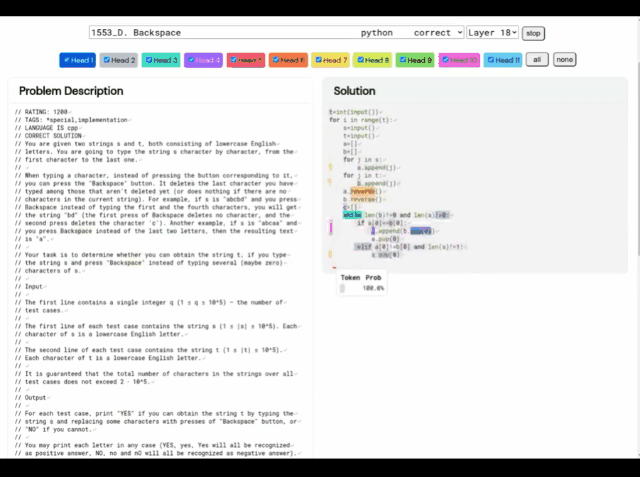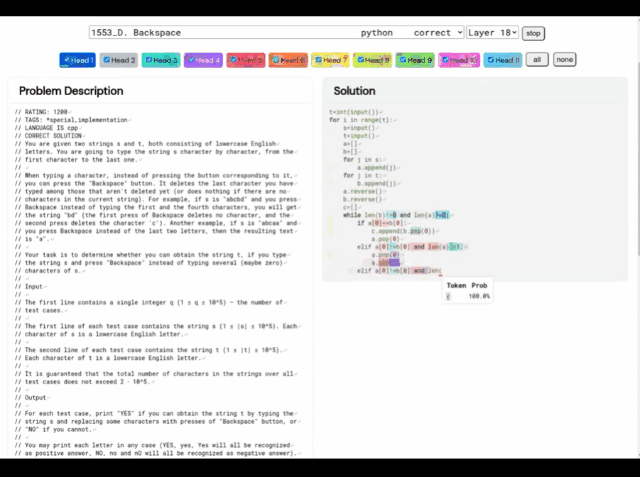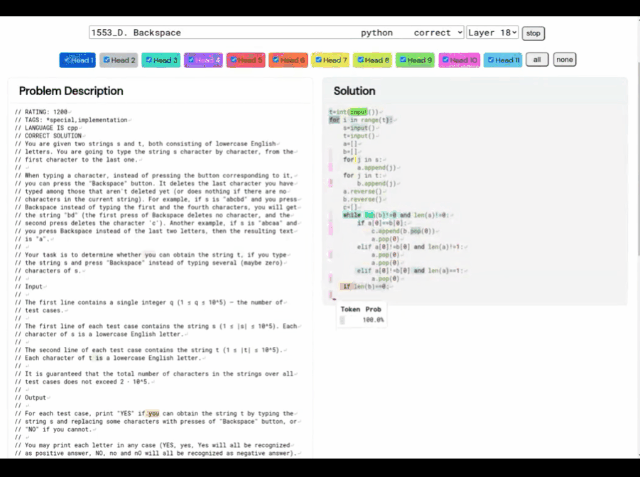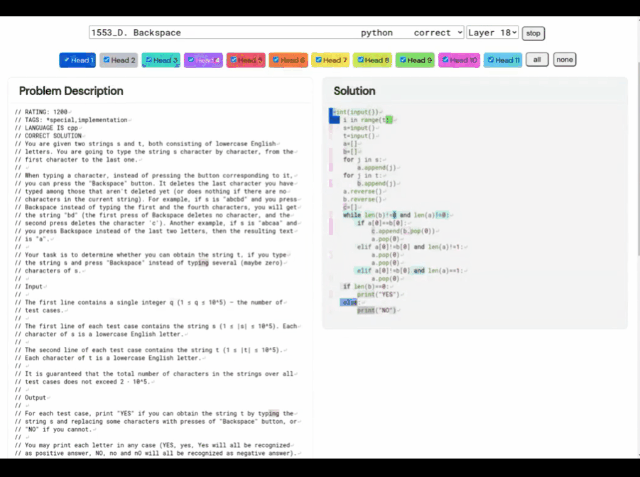
AlphaCode’s Learning System
When participating in programming competitions, the main challenges AlphaCode faces are:
(i) requires searching in a huge program space, (ii) only about 13,000 example tasks are available for training, and (iii) there is a limited number of submissions per problem.
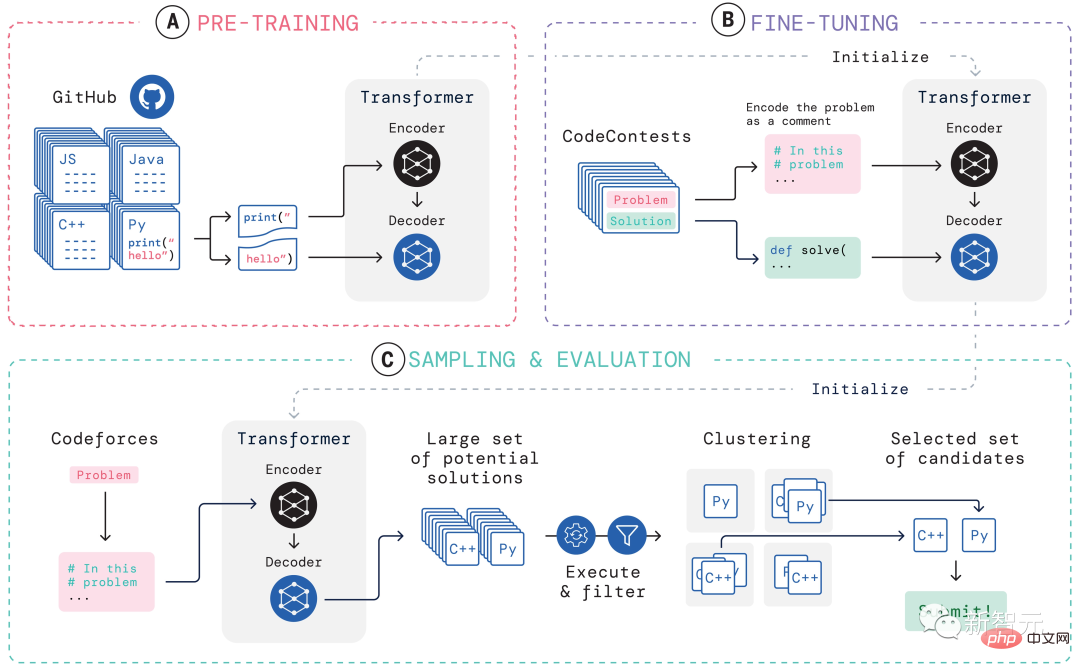
In order to deal with these problems, the construction of AlphaCode's entire learning system is divided into three links, pre-training, fine-tuning, sampling and evaluation, as shown in the figure above Show.
Pre-training
In the pre-training stage, using 715GB of code snapshots of human coders collected on GitHub, Pre-train the model and use cross-entropy next-token prediction loss. During the pre-training process, the code file is randomly divided into two parts, the first part is used as the input of the encoder, and the model is trained to generate the second part without the encoder.
This pre-training learns a strong prior for the encoding, enabling subsequent task-specific fine-tuning to be performed on a smaller data set.
Fine-tuning
In the fine-tuning phase, the model is run on a 2.6GB competitive programming problem dataset For fine-tuning and evaluation, the dataset was created by DeepMind and released publicly under the name CodeContests.
The CodeContests data set includes questions and test cases. The training set contains 13,328 questions, with an average of 922.4 submitted answers per question. The validation set and test set contain 117 and 165 questions respectively.
During fine-tuning, the natural language problem statement is encoded as program annotations so that it looks more similar to the files seen during pre-training (which can include extended natural language language annotation) and use the same next-token prediction loss.
Sampling
In order to select the 10 best samples for submission, filtering and clustering methods are used , execute the samples using the example tests included in the problem statement, and remove samples that fail these tests.
Filter out nearly 99% of the model samples, cluster the remaining candidate samples, execute these samples on the input generated by a separate transformer model, and Programs that produce the same output on generated input are grouped together.
Then, select one sample from each of the 10 largest clusters for submission. Intuitively, correct programs behave identically and form large clusters, while incorrect programs fail in diverse ways.
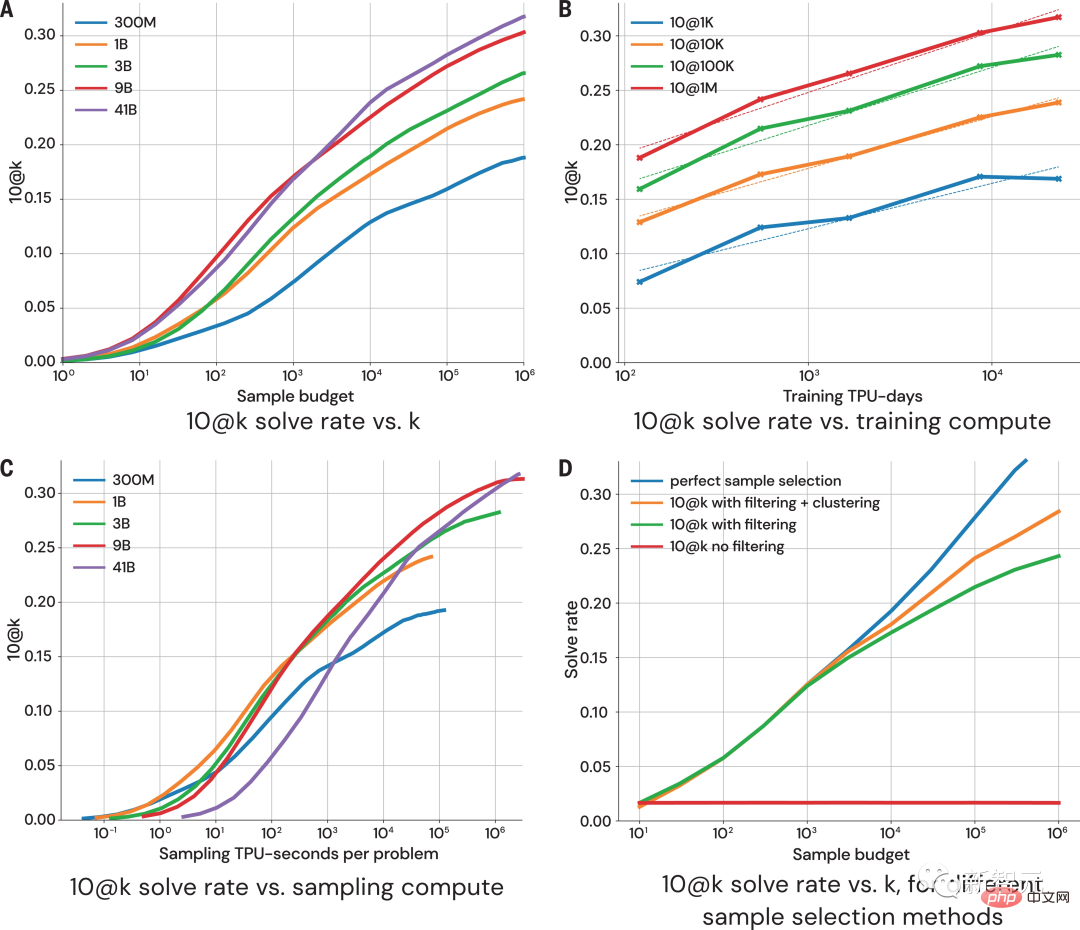
Evaluation
The above figure shows the 10@k indicator on how model performance changes with more sample size and computational effort. From the performance evaluation of the sampling results, the researchers came to the following four conclusions:
#1. The solution rate expands logarithmically linearly with larger sample sizes;
2. A better model has a higher slope on the scaling curve;
3. The solution rate is logarithmically linearly proportional to more calculations;
4. Sample selection is crucial to the expansion of the solution rate.
Purely “data-driven”
There is no doubt that the introduction of AlphaCode represents a substantial step in the development of machine learning models.
Interestingly, AlphaCode does not contain explicit built-in knowledge about the structure of computer code.
Instead, it relies on a purely "data-driven" approach to writing code, which is to learn the structure of computer programs by simply observing large amounts of existing code.

Article address: https://www.science.org/doi/10.1126/science.add8258
Fundamentally, what makes AlphaCode better than other systems on competitive programming tasks comes down to two main attributes:
1. Training Data
2. Post-processing of candidate solutions
But computer code is a highly structured medium and programs must adhere to a defined syntax , and must produce explicit pre- and post-conditions in different parts of the solution.
The method used by AlphaCode when generating code is exactly the same as when generating other text content - one token at a time, and the correctness of the program is only checked after the entire program is written. .
Given the appropriate data and model complexity, AlphaCode can generate coherent structures. However, the final recipe for this sequential generation procedure is buried deep within the parameters of LLM and is elusive.
However, regardless of whether AlphaCode can really "understand" programming problems, it does reach the average human level in coding competitions.
"Solving programming competition problems is a very difficult thing and requires humans to have good coding skills and problem-solving creativity. AlphaCode is able to achieve success in this field I'm impressed with the progress and excited to see how the model uses its statement understanding to generate code and guide its stochastic exploration to create solutions."
—Petr Mitrichev, Google software engineer and world-class competitive programmer
AlphaCode placed in the top 54% of programming competitions, demonstrating how deep learning models require critical thinking potential in the task of thinking.
These models elegantly leverage modern machine learning to express solutions to problems as code, harkening back to AI’s symbolic reasoning roots from decades ago.
And this is just the beginning.
In the future, more powerful AIs that can solve problems will be born. Perhaps this day is not far away.
The above is the detailed content of Super programmed AI appears on the cover of Science! AlphaCode Programming Contest: Half of the Programmers Are Contested. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
To create a data table using phpMyAdmin, the following steps are essential: Connect to the database and click the New tab. Name the table and select the storage engine (InnoDB recommended). Add column details by clicking the Add Column button, including column name, data type, whether to allow null values, and other properties. Select one or more columns as primary keys. Click the Save button to create tables and columns.
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
The core of Oracle SQL statements is SELECT, INSERT, UPDATE and DELETE, as well as the flexible application of various clauses. It is crucial to understand the execution mechanism behind the statement, such as index optimization. Advanced usages include subqueries, connection queries, analysis functions, and PL/SQL. Common errors include syntax errors, performance issues, and data consistency issues. Performance optimization best practices involve using appropriate indexes, avoiding SELECT *, optimizing WHERE clauses, and using bound variables. Mastering Oracle SQL requires practice, including code writing, debugging, thinking and understanding the underlying mechanisms.
 How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
Field operation guide in MySQL: Add, modify, and delete fields. Add field: ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT] Modify field: ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
The integrity constraints of Oracle databases can ensure data accuracy, including: NOT NULL: null values are prohibited; UNIQUE: guarantee uniqueness, allowing a single NULL value; PRIMARY KEY: primary key constraint, strengthen UNIQUE, and prohibit NULL values; FOREIGN KEY: maintain relationships between tables, foreign keys refer to primary table primary keys; CHECK: limit column values according to conditions.
 Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Nested queries are a way to include another query in one query. They are mainly used to retrieve data that meets complex conditions, associate multiple tables, and calculate summary values or statistical information. Examples include finding employees above average wages, finding orders for a specific category, and calculating the total order volume for each product. When writing nested queries, you need to follow: write subqueries, write their results to outer queries (referenced with alias or AS clauses), and optimize query performance (using indexes).
 What does oracle do
Apr 11, 2025 pm 06:06 PM
What does oracle do
Apr 11, 2025 pm 06:06 PM
Oracle is the world's largest database management system (DBMS) software company. Its main products include the following functions: relational database management system (Oracle database) development tools (Oracle APEX, Oracle Visual Builder) middleware (Oracle WebLogic Server, Oracle SOA Suite) cloud service (Oracle Cloud Infrastructure) analysis and business intelligence (Oracle Analytics Cloud, Oracle Essbase) blockchain (Oracle Blockchain Pla
