
 Technology peripherals
AI
Soft Diffusion: Google's new framework correctly schedules, learns and samples from a universal diffusion process
Technology peripherals
AI
Soft Diffusion: Google's new framework correctly schedules, learns and samples from a universal diffusion process
Soft Diffusion: Google's new framework correctly schedules, learns and samples from a universal diffusion process

We know that score-based models and denoising diffusion probability models (DDPM) are two powerful types of generative models that generate samples by inverting the diffusion process. These two types of models have been unified into a single framework in the paper "Score-based generative modeling through stochastic differential equations" by Yang Song and other researchers, and are widely known as diffusion models.
At present, the diffusion model has achieved great success in a series of applications including image, audio, video generation and solving inverse problems. In the paper "Elucidating the design space of diffusionbased generative models", researchers such as Tero Karras analyzed the design space of the diffusion model and identified three stages, namely i) selecting the scheduling of the noise level, ii) selecting the network parameters. ization (each parameterization generates a different loss function), iii) design the sampling algorithm.
Recently, in an arXiv paper "Soft Diffusion: Score Matching for General Corruptions" jointly conducted by Google Research and UT-Austin, several researchers believe that the diffusion model still has a Important step: corruption. Generally speaking, corruption is a process of adding noise of different amplitudes, and for DDMP also requires rescaling. Although there have been attempts to use different distributions for diffusion, a general framework is still lacking. Therefore, the researchers proposed a diffusion model design framework for a more general damage process.
Specifically, they proposed a new training objective called Soft Score Matching and a novel sampling method, Momentum Sampler. Theoretical results show that for damage processes that satisfy regularity conditions, Soft Score MatchIng is able to learn their scores (i.e., likelihood gradients) that diffusion must transform any image into any image with non-zero likelihood.
In the experimental part, the researchers trained the model on CelebA and CIFAR-10. The model trained on CelebA achieved the SOTA FID score of the linear diffusion model - 1.85. At the same time, the model trained by the researchers is significantly faster than the model trained using the original Gaussian denoising diffusion.

##Paper address: https://arxiv.org/pdf/2209.05442.pdf
Method OverviewGenerally speaking, diffusion models generate images by inverting a damage process that gradually increases noise. The researchers show how to learn to invert diffusion involving linear deterministic degradation and stochastic additive noise.

#Specifically, the researchers demonstrated a framework for using a more general damage model to train a diffusion model, which consists of three parts, each for new training objectives. Soft Score Matching, novel sampling method Momentum Sampler, and scheduling of damage mechanisms.
Let’s first look at the training target Soft Score Matching. The name is inspired by soft filtering, which is a photography term that refers to a filter that removes fine details. It learns the fraction of a conventional linear damage process in a provable way, also incorporates a filtering process into the network, and trains the model to predict images after damage that match diffusion observations.
This training objective can prove that the score is learned as long as diffusion assigns non-zero probability to any clean, corrupted image pair. Additionally, this condition is always satisfied when additive noise is present in the damage.
Specifically, the researchers explored the damage process in the following form.

In the process, the researchers discovered that noise has both empirical (i.e., better results) and theoretical (i.e., for learning fractions) benefits. Very important. This also becomes a key difference from Cold Diffusion, a concurrent work that reverses deterministic corruption.
The second is the sampling method Momentum Sampling. The researchers demonstrated that the choice of sampler has a significant impact on the quality of the generated samples. They proposed Momentum Sampler for inverting a universal linear damage process. The sampler uses convex combinations of damage with different diffusion levels and is inspired by momentum methods in optimization.
This sampling method is inspired by the continuous formulation of the diffusion model proposed in the paper by Yang Song et al. above. The algorithm for Momentum Sampler is shown below.

The following figure visually shows the impact of different sampling methods on the quality of the generated samples. The image sampled with Naive Sampler on the left seems repetitive and lacks detail, while the Momentum Sampler on the right significantly improves the sampling quality and FID score.

The last thing is scheduling. Even if the type of degradation is predefined (like blurring), deciding how much to damage at each diffusion step is not trivial. The researchers propose a principled tool to guide the design of damage processes. To find the schedule, they minimize the Wasserstein distance between distributions along the path. Intuitively, researchers want a smooth transition from a completely corrupted distribution to a clean distribution.
Experimental Results
The researchers evaluated the proposed method on CelebA-64 and CIFAR-10, both of which are standard baselines for image generation. The main purpose of the experiment is to understand the role of damage type.
The researchers first tried to use blur and low-amplitude noise for damage. The results show that their proposed model achieves SOTA results on CelebA, i.e., an FID score of 1.85, outperforming all other methods that only add noise and possibly rescale the image. In addition, the FID score obtained on CIFAR-10 is 4.64, which is competitive even though it does not reach SOTA.

In addition, on the CIFAR-10 and CelebA data sets, the researcher's method also performed better on another indicator, sampling time. Another added benefit is significant computational advantages. Deblurring (almost no noise) appears to be a more efficient manipulation compared to image generation denoising methods.
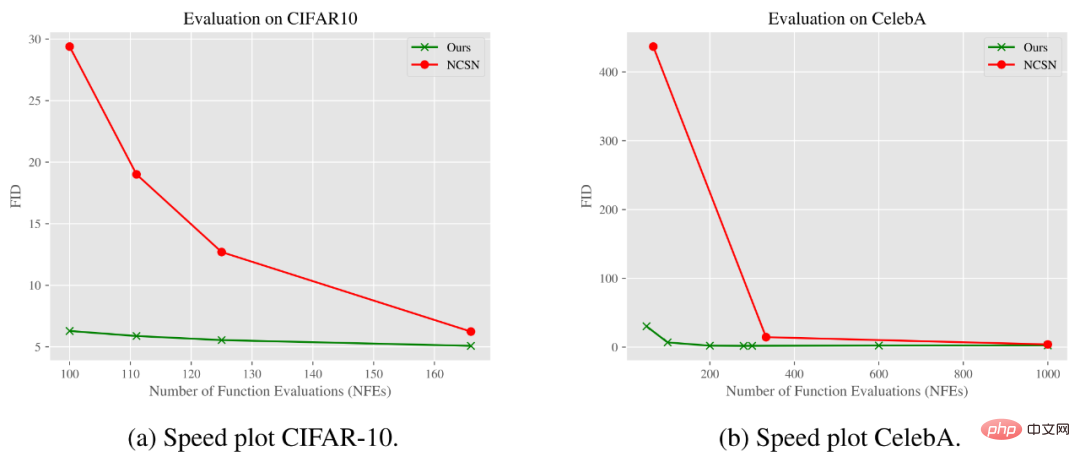
The graph below shows how the FID score changes with the Number of Function Evaluations (NFE). As can be seen from the results, our model can achieve the same or better quality than the standard Gaussian denoising diffusion model using significantly fewer steps on the CIFAR-10 and CelebA datasets.
The above is the detailed content of Soft Diffusion: Google's new framework correctly schedules, learns and samples from a universal diffusion process. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
