
 Technology peripherals
AI
University of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4
Technology peripherals
AI
University of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4
University of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4

Visual command fine-tuning is popular.
This paper is called Visual Instruction Tuning and is jointly produced by the University of Wisconsin-Madison, Microsoft Research and Columbia University.
The authors include Haotian Liu, Chunyuan Li, Qingyang Wu and Yong Jae Lee.

At the same time, the researchers also open sourced their code, models and data sets on GitHub. The paper is also posted on Arxiv.
Explanation
So what exactly is the function of LLaVA? If you dive into the paper, it may be a bit strange to those who are not familiar with it.
Let’s first see what LLaVA itself says.
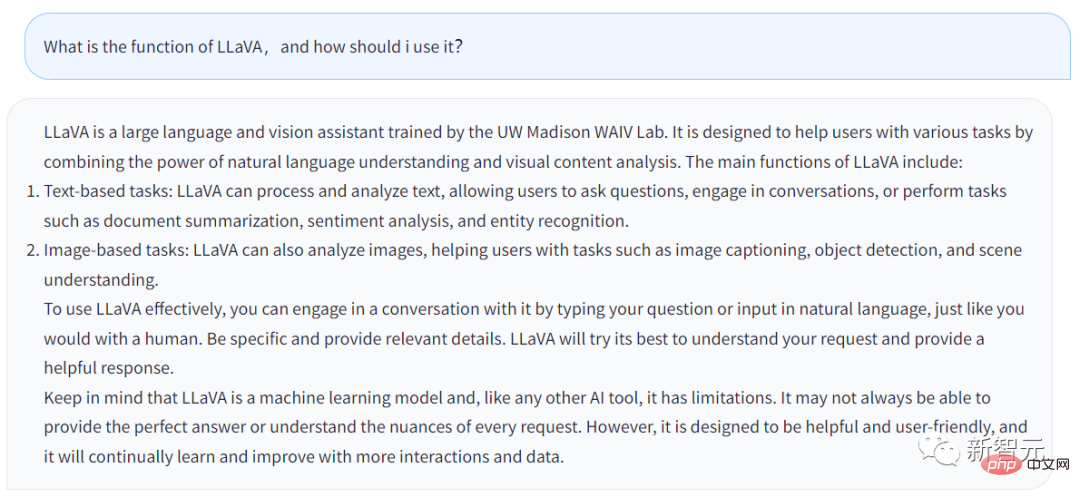
## The above answer is generated from LLaVA’s Chatbot. The question I entered is, what is the function of LLaVA and what should users do? Take advantage of it?
The answer is as follows:
LLaVA is a large language and visual assistant trained in the UW Madison WAIV laboratory. LLaVA is designed to help users handle various tasks by leveraging its natural language understanding capabilities and visual content analysis capabilities.
LLaVA’s main features include:
· Text-based tasks: LLaVA can process and analyze text , allowing users to ask questions, LLaVA can chat with users, or complete tasks entered by users, such as refining document summaries, sentiment analysis, entity recognition, etc.
· Image-based tasks: LLaVA can analyze images, describe images, perform object recognition, and analyze and understand scenes.
If users want to better apply LLaVA, they can directly talk to LLaVA, just like talking to humans. Provide as much detail as possible and LLaVA will generate a more complete answer.
At the same time, you should remember that after all, LLaVA is a machine learning model and an AI tool. As long as it is a tool, it has its limitations. LLaVA may not perfectly answer the questions entered by the user every time.
Of course, LLaVA is constantly learning and improving, and its functions will become more and more powerful.
In general, it can be seen from LLaVA’s answer that the functions of Chatbot are not much different from GPT. But LLaVA can handle some tasks related to images.
Exhibiting ColorThe researchers detailed the technical details of LLaVA in their Arxiv paper.
It is important to know that using machine-generated instructions to follow data to fine-tune instructions for large language models (LLMs) improves the zero-point capability of new tasks, but this idea is not explored in the multi-modal field. less.
In the paper, the researchers attempted for the first time to use language-only GPT-4 to generate instruction-following data for multi-modal language images.
By conditioning instructions on this generated data, the researchers introduce LLaVA: a large-scale language and vision assistant that is an end-to-end trained large-scale multi-modal Stateful model, which connects a visual encoder and LLM for general vision and language understanding.
Early experiments show that LLaVA demonstrates impressive multi-modal chat capabilities, sometimes outputting multi-modal GPT-4 performance on unseen images/commands, and on synthetic multi-modal chats. Compared with GPT-4 on the modal instruction following data set, it achieved a relative score of 85.1%.
When fine-tuned for Science Magazine, the synergy of LLaVA and GPT-4 achieved a new state-of-the-art accuracy of 92.53%.
Researchers have disclosed the data, models and code base for visual command adjustments generated by GPT-4.
Multimodal model
First clarify the definition.
Large-scale multimodal model refers to a model based on machine learning technology that can process and analyze multiple input types, such as text and images.
These models are designed to handle a wider range of tasks and are able to understand different forms of data. By taking text and images as input, these models improve their ability to understand and compile explanations to generate more accurate and relevant answers.
Humans interact with the world through multiple channels, including vision and language, because each individual channel has unique advantages in representing and conveying certain concepts of the world, thereby facilitating greater Understand the world well.
One of the core aspirations of artificial intelligence is to develop a universal assistant that can effectively follow multi-modal visual and language instructions, be consistent with human intentions, and complete various real-life tasks. World Mission.
As a result, the developer community has witnessed a renewed interest in developing language-enhanced basic vision models with powerful capabilities in open-world visual understanding such as classification, detection, segmentation, description, and visual generation and editing.
In these features, each task is independently solved by a single large visual model, with task instructions implicitly considered in the model design.
Furthermore, language is only used to describe image content. While this allows language to play an important role in mapping visual signals to linguistic semantics - a common channel for human communication. However, this results in models that often have fixed interfaces with limited interactivity and adaptability to user instructions.
And large language models (LLM) show that language can play a broader role: a common interface for a general assistant, various task instructions can be explicitly expressed in language, and guide the end to The end-trained neural assistant switches to the task of interest to solve it.
For example, the recent success of ChatGPT and GPT-4 have demonstrated the ability of this LLM to follow human instructions and stimulated huge interest in developing open source LLM.
LLaMA is an open source LLM whose performance is equivalent to GPT-3. Ongoing work leverages various machine-generated high-quality instruction following samples to improve LLM's alignment capabilities, reporting impressive performance compared to proprietary LLMs. Importantly, this line of work is text-only.
In this paper, researchers propose visual command tuning, which is the first attempt to extend command tuning into a multimodal space and paves the way for building a universal visual assistant. the way. Specifically, the main contents of the paper include:
Multimodal instruction following data. A key challenge is the lack of visual language instructions to follow the data. We present a data reform perspective and pipeline that uses ChatGPT/GPT-4 to convert image-text pairs into appropriate command-following formats.
Large multi-modal model. The researchers developed a large multimodal model (LMM) by connecting CLIP's open-set visual encoder and language decoder LaMA, and fine-tuned them end-to-end on the generated instructional visual-verbal data. Empirical studies verify the effectiveness of LMM instruction tuning using generated data and provide practical suggestions for building a general instruction-following visual agent. With GPT 4, the research team achieved state-of-the-art performance on the Science QA multi-modal inference dataset.
Open source. The research team released the following to the public: the generated multimodal instruction data, a code library for data generation and model training, model checkpoints, and a visual chat demonstration.
Result Display

It can be seen that LLaVA can handle all kinds of problems, and the answers generated are both comprehensive and logical.
LLaVA shows some multi-modal capabilities close to the level of GPT-4, with a GPT-4 relative score of 85% in terms of visual chat.
In terms of reasoning question and answer, LLaVA even reached the new SoTA-92.53%, defeating the multi-modal thinking chain.
The above is the detailed content of University of Wisconsin-Madison and others jointly issued a post! The latest multi-modal large model LLaVA is released, and its level is close to GPT-4. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
