

How to disable speech recognition in Windows 11

Microsoft’s latest operating system, Windows 11, also offers speech recognition options similar to those in Windows 10.
It’s worth noting that you can use speech recognition offline or use it over an internet connection. Speech recognition allows you to use your voice to control certain applications and also dictate text into Word documents.
Microsoft's speech recognition service doesn't give you a full set of features. Interested users can check out our tutorial on some of the best speech recognition apps that you can download on your PC to enjoy advanced features.
Note that you need to train this feature to improve its accuracy, and many people will not find its performance satisfactory. So for this reason you might want to disable it.
Follow this tutorial to learn how to disable speech recognition in Windows 11.
What are the most common voice commands?
Regardless of the reason, before you disable speech recognition on your Windows 11 PC, you should know that this accessibility feature is designed to enhance your user experience.
If you are looking for ways to use the voice typing tool on your PC, then you can check out our dedicated tutorial on how to use the voice typing tool in Windows 11.
After you have granted access to your microphone, you can browse some common voice commands listed below and use them to facilitate hands-free use of your PC.
- Open Search: Says press Windows S
- Select an item: Says click Computer, click the file name (instead of File Name says the exact name of the file)
- Scroll: Says scroll up, scroll down, scroll left, scroll right
- Display list of applicable commands: What can I say?
- Insert new line: Say new line
- Place the cursor before a specific word: Say Go to word (Say the specific word instead of the word )
- Do not insert a space before the next word: Say No space
- Capitalize the first letter of the word: Say Caps word (instead of the word Say specific words)
For a complete list of commands, you can check out the official Microsoft support page.
How to turn off speech recognition on Windows 11?
1. Disable offline speech recognition
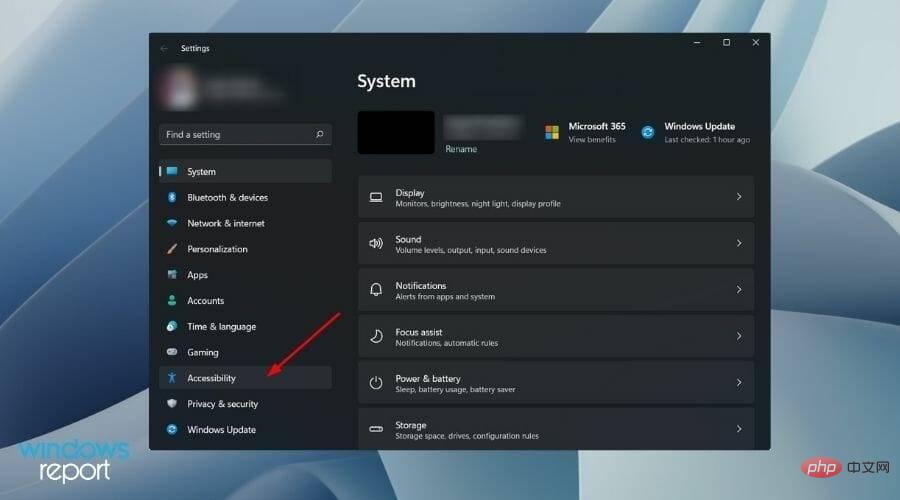
- Right-click the Startmenu button and select Settings.
- Select Accessibility from the left pane.

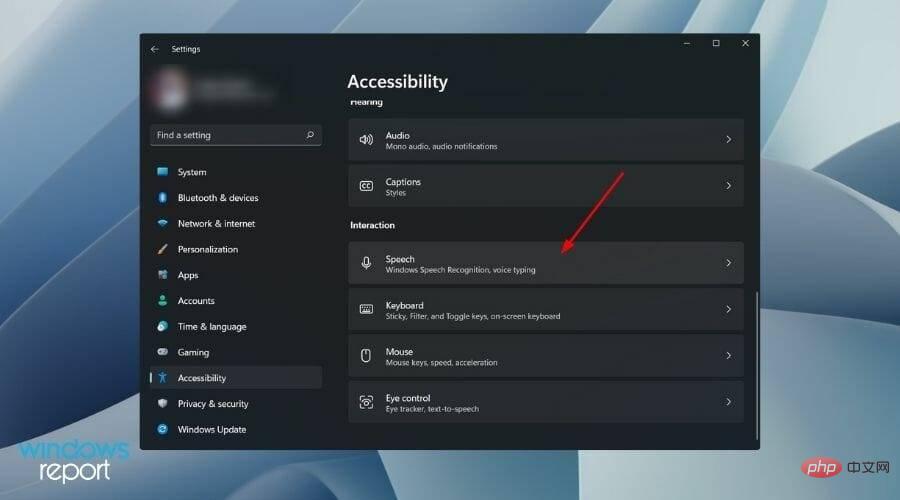
- Now, scroll down from the right side and under the Interaction section, click on Voice.
- Just turn off the switch next to the Windows Speech Recognition option.
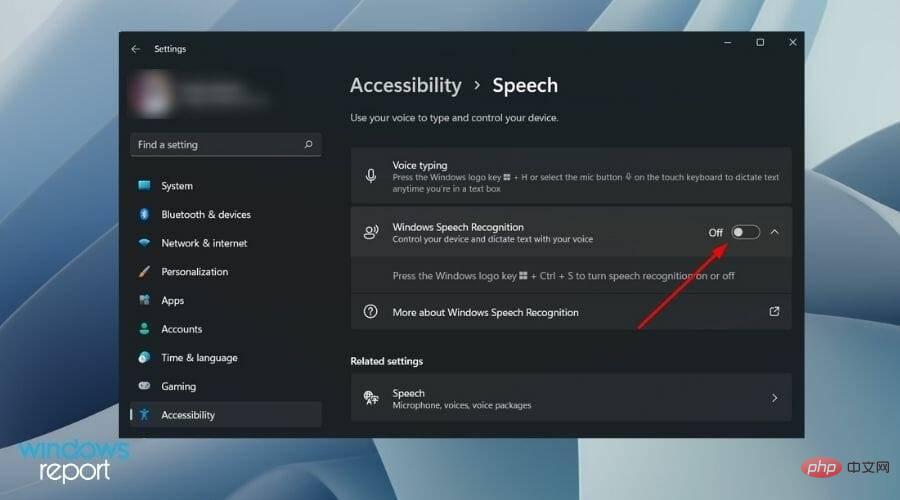
In addition to the above steps, you can also press the buttons simultaneously to turn the Windows Speech Recognition service on or off. Windows Ctrl S
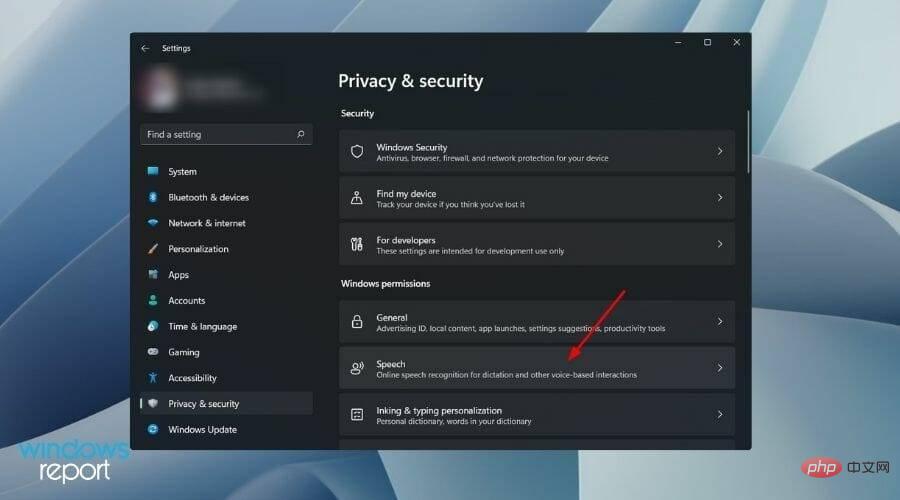
2. Disable online voice Identify
- Right-click the Startmenu button and select Settings.
- You need to selectPrivacy and Security from the left pane.
- Under the Windows Permissions section, click Speech.
- Close Online speech recognition option switch.
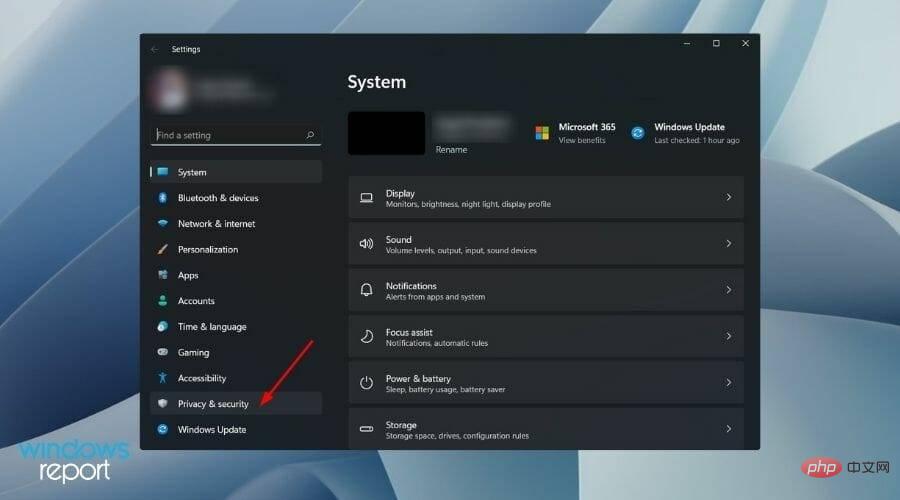
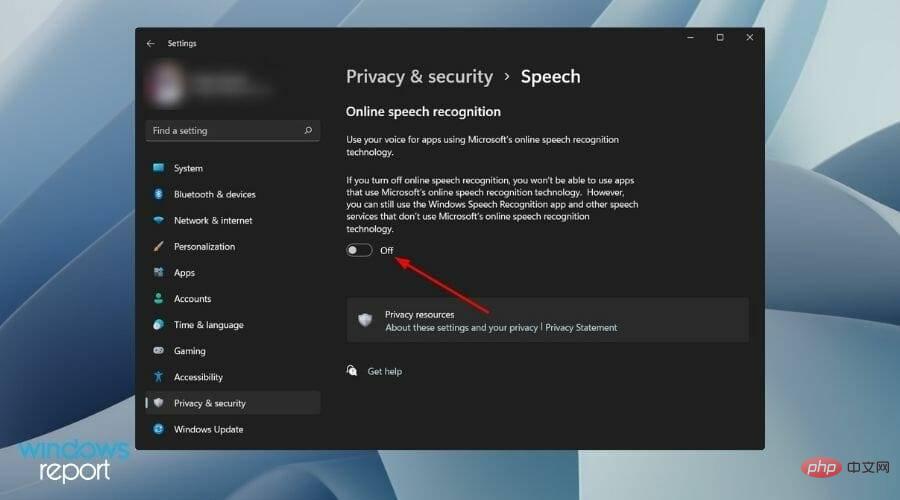
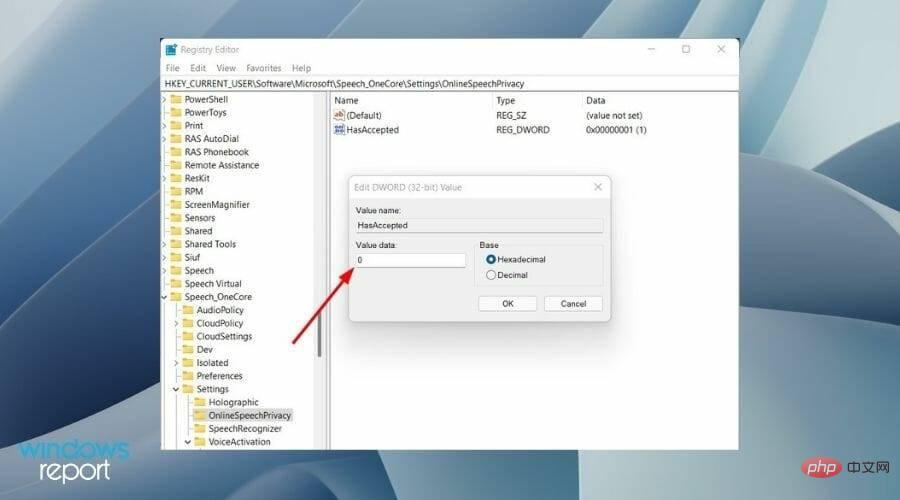
Additionally, you can go a step further and permanently disable the online speech recognition service using a registry setting.
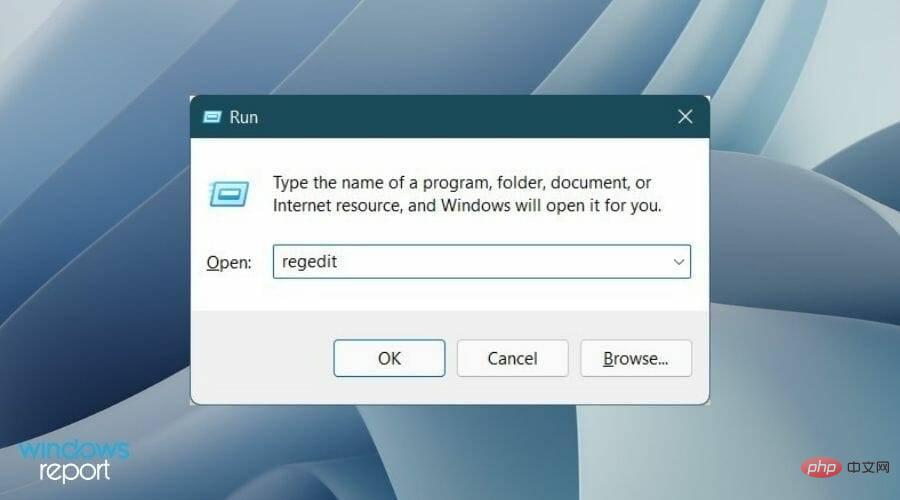
Please note that tweaking Registry Editor, while not dangerous, may stop some critical services on your PC if done incorrectly.- Press the button at the same time to open the "Run" dialog box. Windows R
- Type regedit and press Enter.
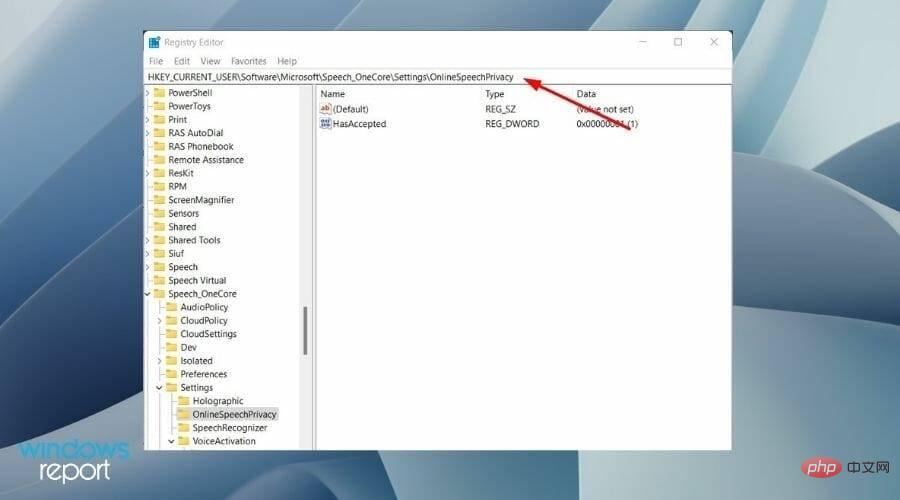
- In the address bar of Registry Editor, paste the following path and press Enter.
HKEY_CURRENT_USER\Software\Microsoft\Speech_OneCore\Settings\OnlineSpeechPrivacy
- On the right, double-click HasAccepted and change the value to 0 .
- Press OK and close the Registry Editor.
- Restart your PC and the online speech recognition service will now be permanently disabled.
Why should you disable Windows Speech Recognition?
Thankfully, Windows 11 does not enable Windows Speech Recognition by default. To use this service, you need to enable it manually.
But this also means that users will not be able to use this feature out of the box. In addition, to use the voice recognition function, you need to set it up if you are using it for the first time.
The above is the detailed content of How to disable speech recognition in Windows 11. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to disable speech recognition in Windows 11
May 01, 2023 am 09:13 AM
How to disable speech recognition in Windows 11
May 01, 2023 am 09:13 AM
<p>Microsoft’s latest operating system, Windows 11, also provides speech recognition options similar to those in Windows 10. </p><p>It is worth noting that you can use speech recognition offline or use it through an Internet connection. Speech recognition allows you to use your voice to control certain applications and also dictate text into Word documents. </p><p>Microsoft's speech recognition service does not provide you with a complete set of features. Interested users can check out some of our best speech recognition apps
 How do I use text-to-speech and speech recognition technology on Windows 11?
Apr 24, 2023 pm 03:28 PM
How do I use text-to-speech and speech recognition technology on Windows 11?
Apr 24, 2023 pm 03:28 PM
Like Windows 10, Windows 11 computers have text-to-speech functionality. Also known as TTS, text-to-speech allows you to write in your own voice. When you speak into the microphone, the computer uses a combination of text recognition and speech synthesis to write text on the screen. This is a great tool if you have trouble reading or writing because you can perform stream of consciousness while speaking. You can overcome writer's block with this handy tool. TTS can also help you if you want to generate a voiceover script for a video, check the pronunciation of certain words, or hear text aloud through Microsoft Narrator. Additionally, the software is good at adding proper punctuation, so you can learn good grammar as well. voice
 How to automatically recognize speech and generate subtitles in movie clipping. Introduction to the method of automatically generating subtitles
Mar 14, 2024 pm 08:10 PM
How to automatically recognize speech and generate subtitles in movie clipping. Introduction to the method of automatically generating subtitles
Mar 14, 2024 pm 08:10 PM
How do we implement the function of generating voice subtitles on this platform? When we are making some videos, in order to have more texture, or when narrating some stories, we need to add our subtitles, so that everyone can better understand the information of some of the videos above. It also plays a role in expression, but many users are not very familiar with automatic speech recognition and subtitle generation. No matter where it is, we can easily let you make better choices in various aspects. , if you also like it, you must not miss it. We need to slowly understand some functional skills, etc., hurry up and take a look with the editor, don't miss it.
 How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to use WebSocket and JavaScript to implement an online speech recognition system Introduction: With the continuous development of technology, speech recognition technology has become an important part of the field of artificial intelligence. The online speech recognition system based on WebSocket and JavaScript has the characteristics of low latency, real-time and cross-platform, and has become a widely used solution. This article will introduce how to use WebSocket and JavaScript to implement an online speech recognition system.
 Detailed method to turn off speech recognition in WIN10 system
Mar 27, 2024 pm 02:36 PM
Detailed method to turn off speech recognition in WIN10 system
Mar 27, 2024 pm 02:36 PM
1. Enter the control panel, find the [Speech Recognition] option, and turn it on. 2. When the speech recognition page pops up, select [Advanced Voice Options]. 3. Finally, uncheck [Run speech recognition at startup] in the User Settings column in the Voice Properties window.
 Audio quality issues in vocal speech recognition
Oct 08, 2023 am 08:28 AM
Audio quality issues in vocal speech recognition
Oct 08, 2023 am 08:28 AM
Audio quality issues in voice speech recognition require specific code examples. In recent years, with the rapid development of artificial intelligence technology, voice speech recognition (Automatic Speech Recognition, referred to as ASR) has been widely used and researched. However, in practical applications, we often face audio quality problems, which directly affects the accuracy and performance of the ASR algorithm. This article will focus on audio quality issues in voice speech recognition and give specific code examples. audio quality for voice speech
 Speaker variation problem in voice gender recognition
Oct 08, 2023 pm 02:22 PM
Speaker variation problem in voice gender recognition
Oct 08, 2023 pm 02:22 PM
Speaker variation problem in voice gender recognition requires specific code examples. With the rapid development of speech technology, voice gender recognition has become an increasingly important field. It is widely used in many application scenarios, such as telephone customer service, voice assistants, etc. However, in voice gender recognition, we often encounter a challenge, that is, speaker variability. Speaker variation refers to differences in the phonetic characteristics of the voices of different individuals. Because individual voice characteristics are affected by many factors, such as gender, age, voice, etc.
 Speech recognition using OpenAI's Whisper model
Apr 12, 2023 pm 05:28 PM
Speech recognition using OpenAI's Whisper model
Apr 12, 2023 pm 05:28 PM
Speech recognition is a field in artificial intelligence that allows computers to understand human speech and convert it into text. The technology is used in devices such as Alexa and various chatbot applications. The most common thing we do is voice transcription, which can be converted into transcripts or subtitles. Recent developments in state-of-the-art models such as wav2vec2, Conformer, and Hubert have significantly advanced the field of speech recognition. These models employ techniques that learn from raw audio without manually labeling the data, allowing them to efficiently use large datasets of unlabeled speech. They have also been extended to use up to 1,000,000 hours of training data, far more than used in academic supervision datasets