
 Backend Development
Python Tutorial
How to implement automatic inspection of python apscheduler cron scheduled task trigger interface
Backend Development
Python Tutorial
How to implement automatic inspection of python apscheduler cron scheduled task trigger interface
How to implement automatic inspection of python apscheduler cron scheduled task trigger interface

Python cron scheduled task trigger interface automatic inspection
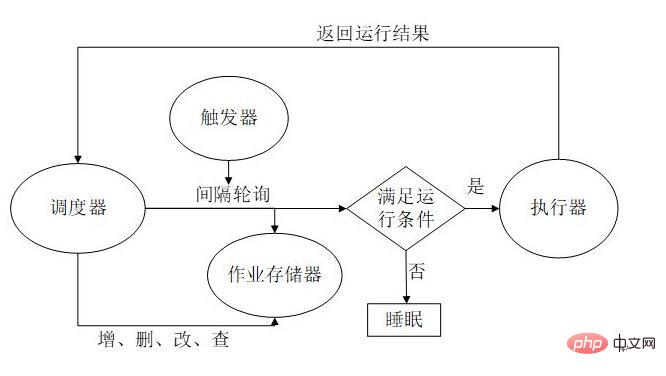
There are several types of scheduled task triggering methods. In daily work, R&D students use more It’s the cron method
I checked that the APScheduler framework supports multiple scheduled task methods
First install the apscheduler module
$ pip install apscheduler
The code is as follows: (Various comments are made in the method The definition and range of time parameters)
from apscheduler.schedulers.blocking import BlockingScheduler
class Timing:
def __init__(self, start_date, end_date, hour=None):
self.start_date = start_date
self.end_date = end_date
self.hour = hour
def cron(self, job, *value_list):
"""cron格式 在特定时间周期性地触发"""
# year (int 或 str) – 年,4位数字
# month (int 或 str) – 月 (范围1-12)
# day (int 或 str) – 日 (范围1-31)
# week (int 或 str) – 周 (范围1-53)
# day_of_week (int 或 str) – 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun)
# hour (int 或 str) – 时 (范围0-23)
# minute (int 或 str) – 分 (范围0-59)
# second (int 或 str) – 秒 (范围0-59)
# start_date (datetime 或 str) – 最早开始日期(包含)
# end_date (datetime 或 str) – 分 最晚结束时间(包含)
# timezone (datetime.tzinfo 或str) – 指定时区
scheduler = BlockingScheduler()
scheduler.add_job(job, 'cron', start_date=self.start_date, end_date=self.end_date, hour=self.hour,
args=[*value_list])
scheduler.start()
def interval(self, job, *value_list):
"""interval格式 周期触发任务"""
# weeks (int) - 间隔几周
# days (int) - 间隔几天
# hours (int) - 间隔几小时
# minutes (int) - 间隔几分钟
# seconds (int) - 间隔多少秒
# start_date (datetime 或 str) - 开始日期
# end_date (datetime 或 str) - 结束日期
# timezone (datetime.tzinfo 或str) - 时区
scheduler = BlockingScheduler()
# 在 2019-08-29 22:15:00至2019-08-29 22:17:00期间,每隔1分30秒 运行一次 job 方法
scheduler.add_job(job, 'interval', minutes=1, seconds=30, start_date=self.start_date,
end_date=self.end_date, args=[*value_list])
scheduler.start()
@staticmethod
def date(job, *value_list):
"""date格式 特定时间点触发"""
# run_date (datetime 或 str) - 作业的运行日期或时间
# timezone (datetime.tzinfo 或 str) - 指定时区
scheduler = BlockingScheduler()
# 在 2019-8-30 01:00:01 运行一次 job 方法
scheduler.add_job(job, 'date', run_date='2019-8-30 01:00:00', args=[*value_list])
scheduler.start()The encapsulation method is not very universal. The code will be optimized later, but at least it can be used now, hahahahahahahahahahahahaha
Thinked about the idea, The inspection triggers the task, and then triggers DingTalk, so the scheduled task should be in the top layer
The code encapsulated by DingTalk shared before and continue to improve the bottom part
if __name__ == '__main__':
file_list = ["test_shiyan.py", "MeetSpringFestival.py"]
# run_py(file_list)
case_list = ["test_case_01", "test_case_02"]
# run_case(test_sample, case_list)
dingDing_list = [2, case_list, test_sample]
# run_dingDing(*dingDing_list)
Timing('2022-02-15 00:00:00', '2022-02-16 00:00:00', '0-23').cron(run_dingDing, *dingDing_list)The function of run_dingDing() We put it in the encapsulated Timing().cron(run_dingDing, *dingDing_list), then we pass the parameters in run_dingDing() in the form of tuples
is what we wrote above and you can see it here
def cron(self, job, *value_list):
"""cron格式 在特定时间周期性地触发"""
scheduler.add_job(job, 'cron', start_date=self.start_date, end_date=self.end_date, hour=self.hour,
args=[*value_list])I put the filling in the time range in the Timing() initialization, which makes it more comfortable.
The timing can be triggered after running Timing().cron(), but it must be Just turn on the computer. When you start researching the platform later, it will be nice to store it in the server~
apscheduler reported an error: Run time of job …… next run at: ……)” was missed by
apscheduler An error similar to the following occurs during the running process:
Run time of job "9668_hack (trigger: interval[1:00:00], next run at: 2018- 10-29 22:00:00 CST)" was missed by 0:01:47.387821Run time of job "9668_index (trigger: interval[0:30:00], next run at: 2018-10-29 21:30: 00 CST)" was missed by 0:01:47.392574Run time of job "9669_deep (trigger: interval[1:00:00], next run at: 2018-10-29 22:00:00 CST)" was missed by 0:01:47.397622Run time of job "9669_hack (trigger: interval[1:00:00], next run at: 2018-10-29 22:00:00 CST)" was missed by 0:01:47.402938Run time of job "9669_index (trigger: interval[0:30:00], next run at: 2018-10-29 21:30:00 CST)" was missed by 0:01:47.407996
Baidu basically couldn't point out this problem. Google found the key configuration, but the error still occurred, so I continued to look for information to find out what the hell was causing this problem.
misfire_grace_time parameter
There is a parameter mentioned in it: misfire_grace_time, but what is this parameter used for? I found an explanation elsewhere, which involves to several other parameters, but give a comprehensive summary based on my own understanding
coalesce: When for some reason a job has accumulated several times There is no actual operation (for example, the system is restored after hanging for 5 minutes, and there is a task that is run every minute. Logically speaking, it was originally "planned" to run 5 times in these 5 minutes, but it was not actually executed). If coalesce is True, the next time this job is submitted to the executor, it will only be executed once, which is the last time. If it is False, it will be executed 5 times (not necessarily, because there are other conditions, see the explanation of misfire_grace_time later)max_instance: This means that there can be at most several instances of the same job running at the same time. For example, a job that takes 10 minutes is designated to run once every minute. , if our max_instance value is 5, then in the 6th to 10th minutes, the new running instance will not be executed because there are already 5 instances runningmisfire_grace_time: Imagine a scenario similar to the coalesce above. If a job was originally executed at 14:00, but was not scheduled for some reason, and now it is 14:01, when the 14:00 running instance is submitted , will check if the difference between the time it is scheduled to run and the current time (here is 1 minute) is greater than the 30 seconds limit we set, then this running instance will not be executed.
Example:
For a task once every 15 minutes, set misfire_grace_time to 100 seconds, and prompt at 0:06:
Run time of job "9392_index (trigger: interval[0:15:00], next run at: 2018-10-27 00:15:00 CST)" was missed by 0:06:03.931026
Explanation:
#The task that was supposed to be executed at 0:00 was not scheduled for some reason and was prompted to run next time ( 0:15) is 6 minutes different from the current time (threshold 100 seconds), so it will not run at 0:15
So this parameter can be commonly understood as the timeout tolerance of the task Configure and give the executor a timeout. If what should be run has not been completed within this time range, your TND should stop running.
So I modified the configuration as follows:
class Config(object):
SCHEDULER_JOBSTORES = {
'default': RedisJobStore(db=3,host='0.0.0.0', port=6378,password='******'),
}
SCHEDULER_EXECUTORS = {
'default': {'type': 'processpool', 'max_workers': 50} #用进程池提升任务处理效率
}
SCHEDULER_JOB_DEFAULTS = {
'coalesce': True, #积攒的任务只跑一次
'max_instances': 1000, #支持1000个实例并发
'misfire_grace_time':600 #600秒的任务超时容错
}
SCHEDULER_API_ENABLED = True我本以为这样应该就没什么问题了,配置看似完美,但是现实是残忍的,盯着apscheduler日志看了一会,熟悉的“was missed by”又出现了,这时候就需要怀疑这个配置到底有没有生效了,然后发现果然没有生效,从/scheduler/jobs中可以看到任务:
{
"id": "9586_site_status",
"name": "9586_site_status",
"func": "monitor_scheduler:monitor_site_status",
"args": [
9586,
"http://sl.jxcn.cn/",
1000,
100,
200,
"",
0,
2
],
"kwargs": {},
"trigger": "interval",
"start_date": "2018-09-14T00:00:00+08:00",
"end_date": "2018-12-31T00:00:00+08:00",
"minutes": 15,
"misfire_grace_time": 10,
"max_instances": 3000,
"next_run_time": "2018-10-24T18:00:00+08:00"
}可以看到任务中默认就有misfire_grace_time配置,没有改为600,折腾一会发现修改配置,重启与修改任务都不会生效,只能修改配置后删除任务重新添加(才能把这个默认配置用上),或者修改任务的时候把这个值改掉
scheduler.modify_job(func=func, id=id, args=args, trigger=trigger, minutes=minutes,start_date=start_date,end_date=end_date,misfire_grace_time=600)
然后就可以了?图样图森破,missed 依然存在。
其实从后来的报错可以发现这个容错时间是用上的,因为从执行时间加上600秒后才出现的报错。
找到任务超时的根本原因
那么还是回到这个超时根本问题上,即使容错时间足够长,没有这个报错了,但是一个任务执行时间过长仍然是个根本问题,所以终极思路还在于如何优化executor的执行时间上。
当然这里根据不同的任务处理方式是不一样的,在于各自的代码了,比如更改链接方式、代码是否有冗余请求,是否可以改为异步执行,等等。
而我自己的任务解决方式为:由接口请求改为python模块直接传参,redis链接改为内网,极大提升执行效率,所以也就控制了执行超时问题。
The above is the detailed content of How to implement automatic inspection of python apscheduler cron scheduled task trigger interface. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
This article will explain how to improve website performance by analyzing Apache logs under the Debian system. 1. Log Analysis Basics Apache log records the detailed information of all HTTP requests, including IP address, timestamp, request URL, HTTP method and response code. In Debian systems, these logs are usually located in the /var/log/apache2/access.log and /var/log/apache2/error.log directories. Understanding the log structure is the first step in effective analysis. 2. Log analysis tool You can use a variety of tools to analyze Apache logs: Command line tools: grep, awk, sed and other command line tools.
 Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python each have their own advantages, and choose according to project requirements. 1.PHP is suitable for web development, especially for rapid development and maintenance of websites. 2. Python is suitable for data science, machine learning and artificial intelligence, with concise syntax and suitable for beginners.
 The role of Debian Sniffer in DDoS attack detection
Apr 12, 2025 pm 10:42 PM
The role of Debian Sniffer in DDoS attack detection
Apr 12, 2025 pm 10:42 PM
This article discusses the DDoS attack detection method. Although no direct application case of "DebianSniffer" was found, the following methods can be used for DDoS attack detection: Effective DDoS attack detection technology: Detection based on traffic analysis: identifying DDoS attacks by monitoring abnormal patterns of network traffic, such as sudden traffic growth, surge in connections on specific ports, etc. This can be achieved using a variety of tools, including but not limited to professional network monitoring systems and custom scripts. For example, Python scripts combined with pyshark and colorama libraries can monitor network traffic in real time and issue alerts. Detection based on statistical analysis: By analyzing statistical characteristics of network traffic, such as data
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
This article will guide you on how to update your NginxSSL certificate on your Debian system. Step 1: Install Certbot First, make sure your system has certbot and python3-certbot-nginx packages installed. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
To maximize the efficiency of learning Python in a limited time, you can use Python's datetime, time, and schedule modules. 1. The datetime module is used to record and plan learning time. 2. The time module helps to set study and rest time. 3. The schedule module automatically arranges weekly learning tasks.
 How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Configuring an HTTPS server on a Debian system involves several steps, including installing the necessary software, generating an SSL certificate, and configuring a web server (such as Apache or Nginx) to use an SSL certificate. Here is a basic guide, assuming you are using an ApacheWeb server. 1. Install the necessary software First, make sure your system is up to date and install Apache and OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
