
 Technology peripherals
AI
Pictures + audios turn into videos in seconds! Xi'an Jiaotong University's open source SadTalker: supernatural head and lip movements, bilingual in Chinese and English, and can also sing
Technology peripherals
AI
Pictures + audios turn into videos in seconds! Xi'an Jiaotong University's open source SadTalker: supernatural head and lip movements, bilingual in Chinese and English, and can also sing
Pictures + audios turn into videos in seconds! Xi'an Jiaotong University's open source SadTalker: supernatural head and lip movements, bilingual in Chinese and English, and can also sing

With the popularity of the concept of digital people and the continuous development of generation technology, it is no longer a problem to make the characters in the photos move according to the audio input.
However, there are still many problems in "generating a talking avatar video through face images and a piece of voice audio", such as unnatural head movements and distorted facial expressions , the faces of the people in the videos and pictures are too different and other issues.
Recently, researchers from Xi'an Jiaotong University and others proposed the SadTalker model, which learns in a three-dimensional sports field to generate 3D motion coefficients of 3DMM (head) from audio. poses, expressions), and uses a new 3D facial renderer to generate head movements.

Paper link: https://arxiv.org/pdf/2211.12194.pdf
Project homepage: https://sadtalker.github.io/
Audio can be English, Chinese, songs , the characters in the video can also control the blinking frequency!
To learn realistic motion coefficients, the researchers explicitly model the connection between audio and different types of motion coefficients separately: through distilled coefficients and 3D-rendered faces , learn accurate facial expressions from audio; design PoseVAE through conditional VAE to synthesize different styles of head movements.
Finally, the generated three-dimensional motion coefficients are mapped to the unsupervised three-dimensional key point space of face rendering, and the final video is synthesized.
Finally, it was demonstrated in experiments that this method achieves state-of-the-art performance in terms of motion synchronization and video quality.
The current stable-diffusion-webui plug-in has also been released!
Photo Audio=Video
Many fields such as digital human creation and video conferencing require the technology of "using voice audio to animate still photos", but currently That's still a very challenging task.
Previous work has mainly focused on generating "lip movements" because the relationship between lip movements and speech is the strongest. Other work is also trying to generate other related movements (such as head movements). facial poses), but the quality of the resulting videos is still very unnatural and limited by preferred poses, blurring, identity modification, and facial distortion.
Another popular method is latent-based facial animation, which mainly focuses on specific categories of motion in conversational facial animation. It is also difficult to synthesize high-quality videos because Although the 3D facial model contains highly decoupled representations that can be used to independently learn the motion trajectories of different positions on the face, inaccurate expressions and unnatural motion sequences will still be generated.
Based on the above observations, researchers proposed SadTalker (Stylized Audio-Driven Talking-head), a stylized audio-driven video generation system through implicit three-dimensional coefficient modulation.
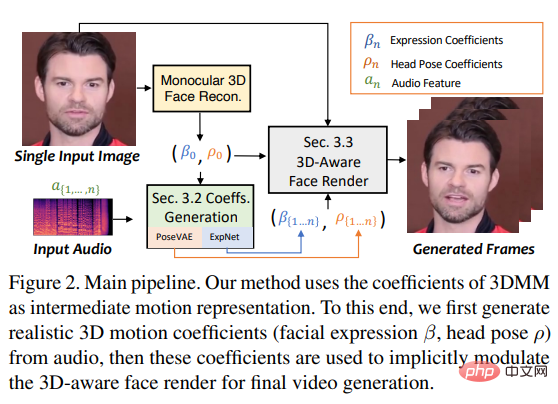
# To achieve this goal, the researchers treated the motion coefficients of 3DMM as intermediate representations and divided the task into The two main parts (expressions and poses) aim to generate more realistic motion coefficients (such as head poses, lip movements, and eye blinks) from audio, and learn each motion individually to reduce uncertainty.
Finally drives the source image through a 3D-aware face rendering inspired by face-vid2vid.
3D Face
Because real-life videos are shot in a three-dimensional environment, three-dimensional information is crucial to improve the authenticity of the generated video; however, previous work rarely considered three-dimensional space, because only one plane was used. It is difficult to obtain original three-dimensional sparse images, and high-quality facial renderers are difficult to design.
Inspired by recent single-image depth 3D reconstruction methods, the researchers used the space of predicted three-dimensional deformation models (3DMMs) as intermediate representations.
In 3DMM, the three-dimensional face shape S can be decoupled as:
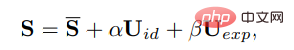
where S is the average shape of the three-dimensional human face, Uid and Uexp are the regularizations of the identity and expression of the LSFM morphable model. The coefficients α (80 dimensions) and β (64 dimensions) describe the identity and expression of the character respectively; in order to maintain the difference in posture, the coefficient r and t represent head rotation and translation respectively; in order to achieve identity-independent coefficient generation, only the parameters of the motion are modeled as {β, r, t}.
That is, the head pose ρ = [r, t] and expression coefficient β are learned separately from the driven audio, and then these motion coefficients are used to implicitly modulate facial rendering for Final video synthesis.
Motion sparse generation through audio
The three-dimensional motion coefficient contains head pose and expression, where the head pose is Global motion, while expressions are relatively local, so fully learning all coefficients will bring huge uncertainty to the network, because the relationship between head posture and audio is relatively weak, while the movement of lips is highly correlated with audio. .
So SadTalker uses the following PoseVAE and ExpNet to generate the movement of head posture and expression respectively.
ExpNet
It is very useful to learn a general model that can "generate accurate expression coefficients from audio" Difficult for two reasons:
1) Audio-to-expression is not a one-to-one mapping task for different characters;
2) There are some audio-related actions in the expression coefficient, which will affect the accuracy of prediction.
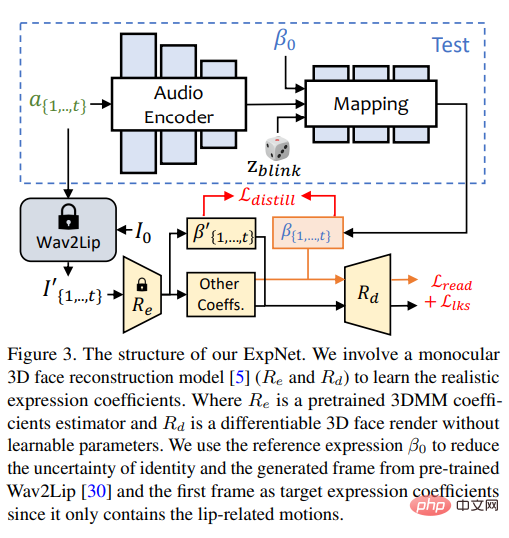
The design goal of ExpNet is to reduce these uncertainties; as for the character identity problem, the researchers moved the expression through the expression coefficient of the first frame associated with a specific person.
In order to reduce the motion weight of other facial components in natural conversations, only lip motion coefficients (lip motion only) are used as coefficient targets through the pre-trained network of Wav2Lip and deep 3D reconstruction.
As for other subtle facial movements (such as eye blinks), etc., they can be introduced in the additional landmark loss on the rendered image.
PoseVAE
Researchers designed a VAE-based model to learn real, identity-related images in conversation videos (identity-aware) stylized head movements.
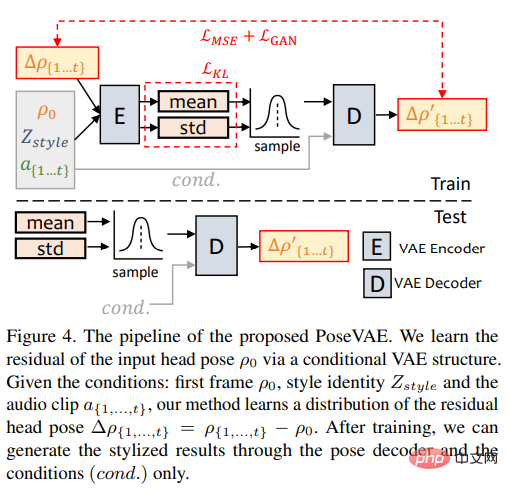
#In training, pose VAE is trained on fixed n frames using an encoder-decoder based structure. , where the encoder and decoder are both two-layer MLPs, and the input contains a continuous t-frame head pose, which is embedded into a Gaussian distribution; in the decoder, the network learns to generate t-frame poses from the sampling distribution.
It should be noted that PoseVAE does not directly generate poses, but learns the residual of the conditional pose of the first frame, which also allows this method to generate longer lengths under the conditions of the first frame in the test. , more stable and continuous head movement.
According to CVAE, corresponding audio features and style identifiers are also added to PoseVAE as conditions for rhythm awareness and identity style.
The model uses KL divergence to measure the distribution of generated motion; it uses mean square loss and adversarial loss to ensure the quality of generation.
3D-aware facial rendering
After generating realistic three-dimensional motion coefficients, the researchers passed a carefully designed 3D image animator to render the final video.
The recently proposed image animation method face-vid2vid can implicitly learn 3D information from a single image, but this method requires a real video as an action driving signal; and this paper The face rendering proposed in can be driven by 3DMM coefficients.
The researchers proposed mappingNet to learn the relationship between explicit 3DMM motion coefficients (head pose and expression) and implicit unsupervised 3D keypoints.
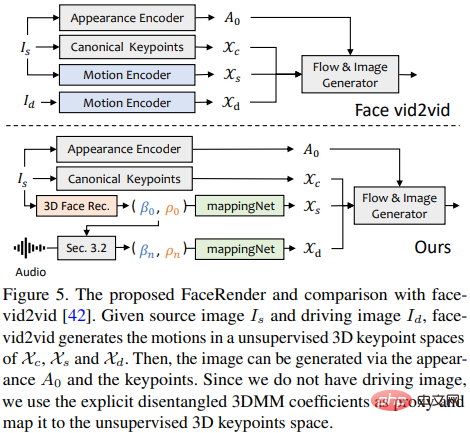
mappingNet is built through several one-dimensional convolutional layers, and uses the time coefficient of the time window for smoothing like PIRenderer; the difference is that the research The researchers found that the face-aligned motion coefficients in PIRenderer will greatly affect the naturalness of motion in audio-driven video generation, so mappingNet only uses coefficients for expressions and head poses.
The training phase consists of two steps: first follow the original paper and train face-vid2vid in a self-supervised manner; then freeze the appearance encoder, canonical keypoint estimator and image generator After all parameters, mappingNet is trained on the 3DMM coefficients of the ground truth video in a reconstructed manner for fine-tuning.
Uses L1 loss for supervised training in the domain of unsupervised keypoints, and gives the final generated video as per its original implementation.
Experimental results
In order to prove the superiority of this method, the researchers selected the Frechet Inception Distance (FID) and Cumulative Probability Blur Detection (CPBD) indicators to evaluate the image The quality, where FID mainly evaluates the authenticity of the generated frames, and CPBD evaluates the clarity of the generated frames.
To evaluate the degree of identity preservation, ArcFace is used to extract the identity embedding of the image, and then the cosine similarity (CSIM) of the identity embedding between the source image and the generated frame is calculated.
To evaluate lip synchronization and lip shape, researchers evaluated the perceptual differences of lip shapes from Wav2Lip, including distance score (LSE-D) and confidence score (LSE-C) .
In the evaluation of head motion, the diversity of generated head motions is calculated using the standard deviation of the head motion feature embeddings extracted by Hopenet from the generated frames; Beat Align is calculated Score to evaluate the consistency of audio and generated head movements.
In the comparison method, several of the most advanced talking avatar generation methods were selected, including MakeItTalk, Audio2Head and audio-to-expression generation methods (Wav2Lip, PC-AVS), using public Checkpoint weights are evaluated.
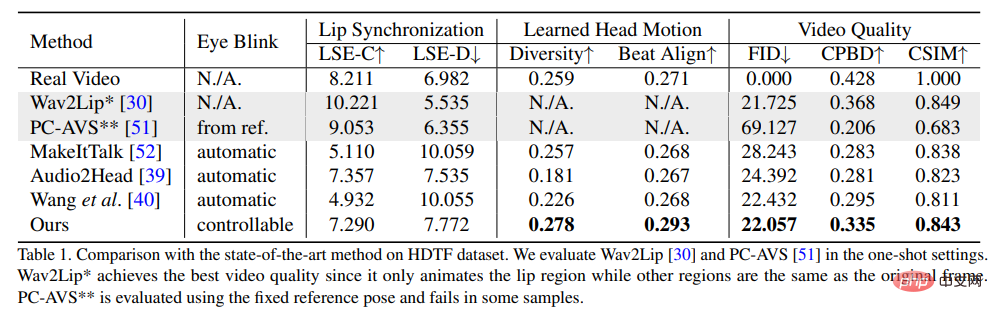
It can be seen from the experimental results that the method proposed in the article can show better overall video quality and header. diversity of head poses, while also showing comparable performance to other fully speaking head generation methods in terms of lip synchronization metrics.
The researchers believe that these lip sync metrics are too sensitive to audio, so that unnatural lip movements may get better scores, but the method proposed in the article achieved The similar scores to real videos also demonstrate the advantages of this method.

As can be seen in the visual results generated by the different methods, the visual quality of this method is very similar to the original target video, and different from the expected The posture is also very similar.
Compared with other methods, Wav2Lip generates blurry half-faces; PC-AVS and Audio2Head have difficulty retaining the identity of the source image; Audio2Head can only generate frontal speaking faces; MakeItTalk and Audio2Head generates distorted face videos due to 2D distortion.
The above is the detailed content of Pictures + audios turn into videos in seconds! Xi'an Jiaotong University's open source SadTalker: supernatural head and lip movements, bilingual in Chinese and English, and can also sing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 How to adjust audio balance in Win11? (Win11 adjusts the left and right channels of volume)
Feb 11, 2024 pm 05:57 PM
How to adjust audio balance in Win11? (Win11 adjusts the left and right channels of volume)
Feb 11, 2024 pm 05:57 PM
When listening to music or watching movies on a Win11 computer, if the speakers or headphones sound unbalanced, users can manually adjust the balance level according to their needs. So how do we adjust? In response to this problem, the editor has brought a detailed operation tutorial, hoping to help everyone. How to balance left and right audio channels in Windows 11? Method 1: Use the Settings app to tap the key and click Settings. Windows click System and select Sound. Choose more sound settings. Click on your speakers/headphones and select Properties. Navigate to the Levels tab and click Balance. Make sure "left" and
 Bose Soundbar Ultra launch experience: Home theater right out of the box?
Feb 06, 2024 pm 05:30 PM
Bose Soundbar Ultra launch experience: Home theater right out of the box?
Feb 06, 2024 pm 05:30 PM
For as long as I can remember, I have had a pair of large floor-standing speakers at home. I have always believed that a TV can only be called a TV if it is equipped with a complete sound system. But when I first started working, I couldn’t afford professional home audio. After inquiring and understanding the product positioning, I found that the sound bar category is very suitable for me. It meets my needs in terms of sound quality, size and price. Therefore, I decided to go with the soundbar. After careful selection, I selected this panoramic soundbar product launched by Bose in early 2024: Bose home entertainment speaker Ultra. (Photo source: Photographed by Lei Technology) Generally speaking, if we want to experience the "original" Dolby Atmos effect, we need to install a measured and calibrated surround sound + ceiling at home.
 How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? Where is the automatically saved image when posting?
Mar 22, 2024 am 08:06 AM
How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? Where is the automatically saved image when posting?
Mar 22, 2024 am 08:06 AM
With the continuous development of social media, Xiaohongshu has become a platform for more and more young people to share their lives and discover beautiful things. Many users are troubled by auto-save issues when posting images. So, how to solve this problem? 1. How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? 1. Clear the cache First, we can try to clear the cache data of Xiaohongshu. The steps are as follows: (1) Open Xiaohongshu and click the "My" button in the lower right corner; (2) On the personal center page, find "Settings" and click it; (3) Scroll down and find the "Clear Cache" option. Click OK. After clearing the cache, re-enter Xiaohongshu and try to post pictures to see if the automatic saving problem is solved. 2. Update the Xiaohongshu version to ensure that your Xiaohongshu
 How to post pictures in TikTok comments? Where is the entrance to the pictures in the comment area?
Mar 21, 2024 pm 09:12 PM
How to post pictures in TikTok comments? Where is the entrance to the pictures in the comment area?
Mar 21, 2024 pm 09:12 PM
With the popularity of Douyin short videos, user interactions in the comment area have become more colorful. Some users wish to share images in comments to better express their opinions or emotions. So, how to post pictures in TikTok comments? This article will answer this question in detail and provide you with some related tips and precautions. 1. How to post pictures in Douyin comments? 1. Open Douyin: First, you need to open Douyin APP and log in to your account. 2. Find the comment area: When browsing or posting a short video, find the place where you want to comment and click the "Comment" button. 3. Enter your comment content: Enter your comment content in the comment area. 4. Choose to send a picture: In the interface for entering comment content, you will see a "picture" button or a "+" button, click
 7 Ways to Reset Sound Settings on Windows 11
Nov 08, 2023 pm 05:17 PM
7 Ways to Reset Sound Settings on Windows 11
Nov 08, 2023 pm 05:17 PM
While Windows is capable of managing sound on your computer, you may still want to intervene and reset your sound settings in case you encounter audio issues or glitches. However, with the aesthetic changes Microsoft has made in Windows 11, zeroing in on these settings has become more difficult. So, let’s dive into how to find and manage these settings on Windows 11 or reset them in case any issues arise. How to Reset Sound Settings in Windows 11 in 7 Easy Ways Here are seven ways to reset sound settings in Windows 11, depending on the issue you are facing. let's start. Method 1: Reset app sound and volume settings Press the button on your keyboard to open the Settings app. Click now
 6 Ways to Make Pictures Sharper on iPhone
Mar 04, 2024 pm 06:25 PM
6 Ways to Make Pictures Sharper on iPhone
Mar 04, 2024 pm 06:25 PM
Apple's recent iPhones capture memories with crisp detail, saturation and brightness. But sometimes, you may encounter some issues that may cause the image to look less clear. While autofocus on iPhone cameras has come a long way, allowing you to take photos quickly, the camera can mistakenly focus on the wrong subject in certain situations, making the photo blurry in unwanted areas. If your photos on your iPhone look out of focus or lack sharpness overall, the following post should help you make them sharper. How to Make Pictures Clearer on iPhone [6 Methods] You can try using the native Photos app to clean up your photos. If you want more features and options
 How to make ppt pictures appear one by one
Mar 25, 2024 pm 04:00 PM
How to make ppt pictures appear one by one
Mar 25, 2024 pm 04:00 PM
In PowerPoint, it is a common technique to display pictures one by one, which can be achieved by setting animation effects. This guide details the steps to implement this technique, including basic setup, image insertion, adding animation, and adjusting animation order and timing. Additionally, advanced settings and adjustments are provided, such as using triggers, adjusting animation speed and order, and previewing animation effects. By following these steps and tips, users can easily set up pictures to appear one after another in PowerPoint, thereby enhancing the visual impact of the presentation and grabbing the attention of the audience.
 What should I do if the images on the webpage cannot be loaded? 6 solutions
Mar 15, 2024 am 10:30 AM
What should I do if the images on the webpage cannot be loaded? 6 solutions
Mar 15, 2024 am 10:30 AM
Some netizens found that when they opened the browser web page, the pictures on the web page could not be loaded for a long time. What happened? I checked that the network is normal, so where is the problem? The editor below will introduce to you six solutions to the problem that web page images cannot be loaded. Web page images cannot be loaded: 1. Internet speed problem The web page cannot display images. It may be because the computer's Internet speed is relatively slow and there are more softwares opened on the computer. And the images we access are relatively large, which may be due to loading timeout. As a result, the picture cannot be displayed. You can turn off the software that consumes more network speed. You can go to the task manager to check. 2. Too many visitors. If the webpage cannot display pictures, it may be because the webpages we visited were visited at the same time.
