

As we mentioned in the previous article, by implementing the Runnable interface through coding, you will obtain a boundary "task" that runs in a specified thread (or thread pool).
Re-observing the interface, it is not difficult to find that it does not have a method return value:
public interface Runnable {
void run();
}Before JDK1.5, if you want to use the execution results of the task, you need to carefully operate the thread to access critical section resources. . Using Callback for decoupling is a very good choice.
Note that lambda is used in order to reduce the length, but lambda is not supported before jdk1.5
Separate the calculation tasks into Other threads execute, and then return to the main thread to consume the results
We throw time-consuming tasks such as calculation and IO to other threads, allowing the main thread to focus on its own business, assuming that it is accepting user input and processing feedback, but Let's omit this part
We can design a code similar to the following:
Although it still has many unreasonable things that deserve optimization, it is enough for demonstration
class Demo {
static final Object queueLock = new Object();
static List<Runnable> mainQueue = new ArrayList<>();
static boolean running = true;
static final Runnable FINISH = () -> running = false;
public static void main(String[] args) {
synchronized (queueLock) {
mainQueue.add(Demo::onStart);
}
while (running) {
Runnable runnable = null;
synchronized (queueLock) {
if (!mainQueue.isEmpty())
runnable = mainQueue.remove(0);
}
if (runnable != null) {
runnable.run();
}
Thread.yield();
}
}
public static void onStart() {
//...
}
public static void finish() {
synchronized (queueLock) {
mainQueue.clear();
mainQueue.add(FINISH);
}
}
}Simulate a computing thread and task callback:
interface Callback {
void onResultCalculated(int result);
}
class CalcThread extends Thread {
private final Callback callback;
private final int a;
private final int b;
public CalcThread(Callback callback, int a, int b) {
this.callback = callback;
this.a = a;
this.b = b;
}
@Override
public void run() {
super.run();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
final int result = a + b;
System.out.println("threadId" + Thread.currentThread().getId() + ",calc result:" + result + ";" + System.currentTimeMillis());
synchronized (queueLock) {
mainQueue.add(() -> callback.onResultCalculated(result));
}
}
}Fill in the onStart business:
class Demo {
public static void onStart() {
System.out.println("threadId" + Thread.currentThread().getId() + ",onStart," + System.currentTimeMillis());
new CalcThread(result -> {
System.out.println("threadId" + Thread.currentThread().getId() + ",onResultCalculated:" + result + ";" + System.currentTimeMillis());
finish();
}, 200, 300).start();
}
}As mentioned above, if the business If you only focus on the execution of the task and don't care too much about the thread itself, you can use Runnable:
class Demo {
static class CalcRunnable implements Runnable {
private final Callback callback;
private final int a;
private final int b;
public CalcRunnable(Callback callback, int a, int b) {
this.callback = callback;
this.a = a;
this.b = b;
}
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
final int result = a + b;
System.out.println("threadId" + Thread.currentThread().getId() + ",calc result:" + result + ";" + System.currentTimeMillis());
synchronized (queueLock) {
mainQueue.add(() -> callback.onResultCalculated(result));
}
}
}
public static void onStart() {
System.out.println("threadId" + Thread.currentThread().getId() + ",onStart," + System.currentTimeMillis());
new Thread(new CalcRunnable(result -> {
System.out.println("threadId" + Thread.currentThread().getId() + ",onResultCalculated:" + result + ";" + System.currentTimeMillis());
finish();
}, 200, 300)).start();
}
}It is not difficult to imagine: We very much need
to let specific threads, specific Types of threads can conveniently receive tasks. Looking back at the thread pool in this series of articles, the thread pool came into being
It has a more lightweight mechanism than Synchronize
Have a more convenient data structure
At this point, we can realize: Before JDK1.5, due to the insufficient functions of JDK, Java programs used threadsrougher.
finally has new features in JDK1.5: Future and the thread pool mentioned in the previous article, time flies , nearly 20 years have passed.
/**
* 略
* @since 1.5
* @author Doug Lea
* @param <V> The result type returned by this Future's {@code get} method
*/
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}Although the API comments have been removed, you can still understand the meaning of each API without going into details.
Obviously, in order to increase the return value, there is no need to replace Runnable with such a complex interface. After a brief thought, we can summarize the return value:
Return the results of the business in Runnable, such as calculation, reading resources, etc.
Simply return a result after the Runnable is executed
From a business layer perspective, only the following interface is needed, which increases the return value and makes it more user-friendly. Exception:
Author's note: Put aside the underlying implementation and only look at the coding needs of the business side
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}Obviously, JDK needs to provide backward compatibility:
Runnable cannot be discarded, nor should it be discarded
Users cannot be required to completely reconstruct the code
, so the adapter is also provided. Allowing users to perform simple partial refactoring to use new features
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}And Future is just as its name suggests. It represents a result and status in the "future" and was born to handle asynchronously more conveniently.
and has built-in FutureTask, which will be expanded in the FutureTask detailed explanation chapter.
Based on JDK1.8, let’s take a look at the streamlined class diagram structure:
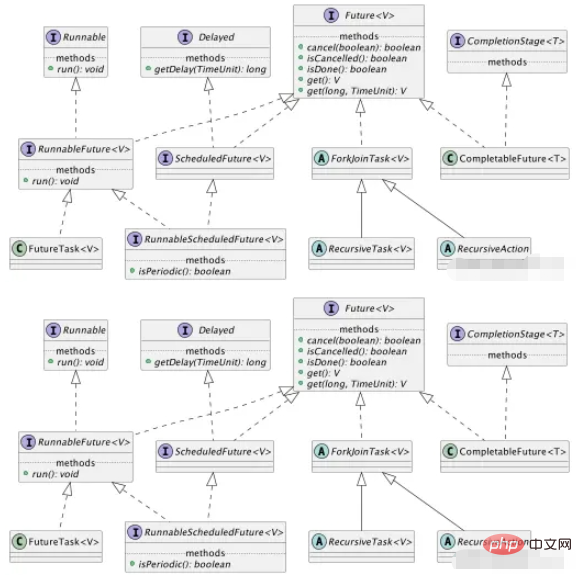
public class FutureTask {
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
}public class FutureTask {
//新建
private static final int NEW = 0;
//处理中
private static final int COMPLETING = 1;
//正常
private static final int NORMAL = 2;
//异常
private static final int EXCEPTIONAL = 3;
//已取消
private static final int CANCELLED = 4;
//中断中
private static final int INTERRUPTING = 5;
//已中断
private static final int INTERRUPTED = 6;
}Core Method
public class FutureTask {
public boolean isCancelled() {
return state >= CANCELLED;
}
public boolean isDone() {
return state != NEW;
}
}Cancel:
and CAS modifies the state successfully, otherwise it returns cancellation failure
interrupts the executing thread and CAS changes the state to INTERRUPTED
Delete and notify all waiting threads
Call done()
Set callable to null
public class FutureTask {
public boolean cancel(boolean mayInterruptIfRunning) {
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) {
return false;
}
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
finishCompletion();
}
return true;
}
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null; ) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (; ; ) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
}获取结果: 先判断状态,如果未进入到 COMPLETING(即为NEW状态),则阻塞等待状态改变,返回结果或抛出异常
public class FutureTask {
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
public V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
if (unit == null)
throw new NullPointerException();
int s = state;
if (s <= COMPLETING &&
(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
throw new TimeoutException();
return report(s);
}
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V) x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable) x);
}
}而使用则非常简单,也非常的朴素。
我们以文中的的例子进行改造:
沿用原Runnable逻辑
移除回调,增加 CalcResult
将 CalcResult 对象作为既定返回结果,Runnable中设置其属性
class Demo {
static class CalcResult {
public int result;
}
public static void onStart() {
System.out.println("threadId" + Thread.currentThread().getId() + ",onStart," + System.currentTimeMillis());
final CalcResult calcResult = new CalcResult();
Future<CalcResult> resultFuture = Executors.newSingleThreadExecutor().submit(() -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
final int result = 200 + 300;
System.out.println("threadId" + Thread.currentThread().getId() + ",calc result:" + result + ";" + System.currentTimeMillis());
calcResult.result = result;
}, calcResult);
System.out.println("threadId" + Thread.currentThread().getId() + "反正干点什么," + System.currentTimeMillis());
if (resultFuture.isDone()) {
try {
final int ret = resultFuture.get().result;
System.out.println("threadId" + Thread.currentThread().getId() + ",get result:" + ret + ";" + System.currentTimeMillis());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
finish();
}
}如果直接使用新特性Callback,则如下:
直接返回结果,当然也可以直接返回Integer,不再包裹一层
class Demo {
public static void onStart() {
System.out.println("threadId" + Thread.currentThread().getId() + ",onStart," + System.currentTimeMillis());
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<CalcResult> resultFuture = executor.submit(() -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
final int result = 200 + 300;
System.out.println("threadId" + Thread.currentThread().getId() + ",calc result:" + result + ";" + System.currentTimeMillis());
final CalcResult calcResult = new CalcResult();
calcResult.result = result;
return calcResult;
});
System.out.println("threadId" + Thread.currentThread().getId() + "反正干点什么," + System.currentTimeMillis());
if (resultFuture.isDone()) {
try {
final int ret = resultFuture.get().result;
System.out.println("threadId" + Thread.currentThread().getId() + ",get result:" + ret + ";" + System.currentTimeMillis());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executor.shutdown();
finish();
}
}相信读者诸君会有这样的疑惑:
为何使用Future比原先的回调看起来粗糙?
首先要明确一点:文中前段的回调Demo,虽然达成了既定目标,但效率并不高!!在当时计算很昂贵的背景下,并不会如此莽撞地使用!
而在JDK1.5开始,提供了大量内容支持多线程开发。考虑到篇幅,会在系列文章中逐步展开。
另外,FutureTask中的CAS与Happens-Before本篇中亦不做展开。
接下来,再做一些引申,简单看一看多线程业务模式。
常用的多线程设计模式包括:
Future模式
Master-Worker模式
Guarded Suspension模式
不变模式
生产者-消费
文中对于Future的使用方式遵循了Future模式。
业务方在使用时,已经明确了任务被分离到其他线程执行时有等待期,在此期间,可以干点别的事情,不必浪费系统资源。
在程序系统中设计两类线程,并相互协作:
Master线程(单个)
Worker线程
Master线程负责接受任务、分配任务、接收(必要时进一步组合)结果并返回;
Worker线程负责处理子任务,当子任务处理完成后,向Master线程返回结果;
作者按:此时可再次回想一下文章开头的Demo
使用缓存队列,使得 服务线程/服务进程 在未就绪、忙碌时能够延迟处理请求。
使用等待-通知机制,将消费 服务的返回结果 的方式规范化
在并行开发过程中,为确保数据的一致性和正确性,有必要对对象进行同步,而同步操作会对程序系统的性能产生相当的损耗。
因此,使用状态不可改变的对象,依靠其不变性来确保 并行操作 在 没有同步机制 的情况下,保持一致性和正确性。
对象创建后,其内部状态和数据不再发生改变
对象被共享、被多个线程访问
设计两类线程:若干个生产者线程和若干个消费者线程。
生产者线程负责提交用户请求,消费者线程负责处理用户请求。生产者和消费者之间通过共享内存缓冲区进行通信。
内存缓冲区的意义:
解决是数据在多线程间的共享问题
缓解生产者和消费者之间的性能差
这几种模式从不同角度出发解决特定问题,但亦有一定的相似之处,不再展开。
The above is the detailed content of How to use Java multi-threaded Future to obtain asynchronous tasks. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



