
 Technology peripherals
AI
Comprehensive comparison of four 'ChatGPT search' models! Hand-annotated by a Chinese doctor from Stanford: New Bing has the lowest fluency, and nearly half of the sentences are not quoted.
Technology peripherals
AI
Comprehensive comparison of four 'ChatGPT search' models! Hand-annotated by a Chinese doctor from Stanford: New Bing has the lowest fluency, and nearly half of the sentences are not quoted.
Comprehensive comparison of four 'ChatGPT search' models! Hand-annotated by a Chinese doctor from Stanford: New Bing has the lowest fluency, and nearly half of the sentences are not quoted.

Not long after the release of ChatGPT, Microsoft successfully launched the "New Bing". Not only did its stock price surge, it even threatened to replace Google and usher in a new era of search engines.
But is New Bing really the right way to play a large language model? Are the generated answers actually useful to users? How credible is the quotation in the sentence?
Recently, Stanford researchers collected a large number of user queries from different sources and analyzed the four popular generative search engines, Bing Chat, NeevaAI, Human evaluation was performed by perplexity.ai and YouChat.

Paper link: https://arxiv.org/pdf/2304.09848.pdf
Experimental results found that responses from existing generative search engines are fluent and informative, but often contain statements without evidence and inaccurate quotes.
On average, only 51.5% of the citations can fully support the generated sentences, and only 74.5% of the citations can be used as evidence support for the relevant sentences.
The researchers believe that this result is too low for systems that may become the main tool for information-seeking users, especially considering that some sentences are only plausible. Generative search engines still need further optimization.

##Personal homepage: https://cs.stanford.edu/~nfliu/
The first author Nelson Liu is a fourth-year doctoral student in the Natural Language Processing Group of Stanford University. His supervisor is Percy Liang. He graduated from the University of Washington with a bachelor's degree. His main research direction is building practical NLP systems, especially for information search. s application.
Don’t Trust Generative Search EnginesIn March 2023, Microsoft reported that “approximately one-third of daily preview users use [Bing] every day "Chat", and Bing Chat provided 45 million chats in the first month of its public preview. In other words, integrating large language models into search engines is very marketable and is very likely to change the search entrance to the Internet.

But at present, the existing generative search engines based on large-scale language model technology still have the problem of low accuracy, but specifically The accuracy of the search engine has not yet been fully evaluated, and the limitations of the new search engine have not yet been fully understood.
Verifiability is the key to improving the credibility of search engines, that is, providing external links to citations for each sentence in the generated answer. As evidence support, it can make it easier for users to verify the accuracy of answers.
The researchers conducted manual evaluation on four commercial generative search engines (Bing Chat, NeevaAI, perplexity.ai, YouChat) by collecting questions from different types and sources.
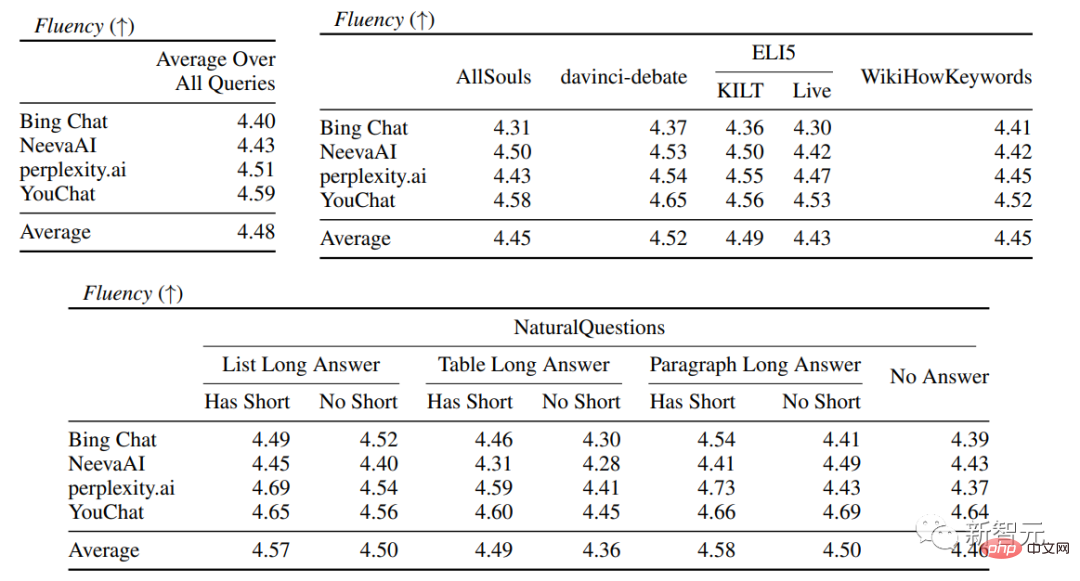
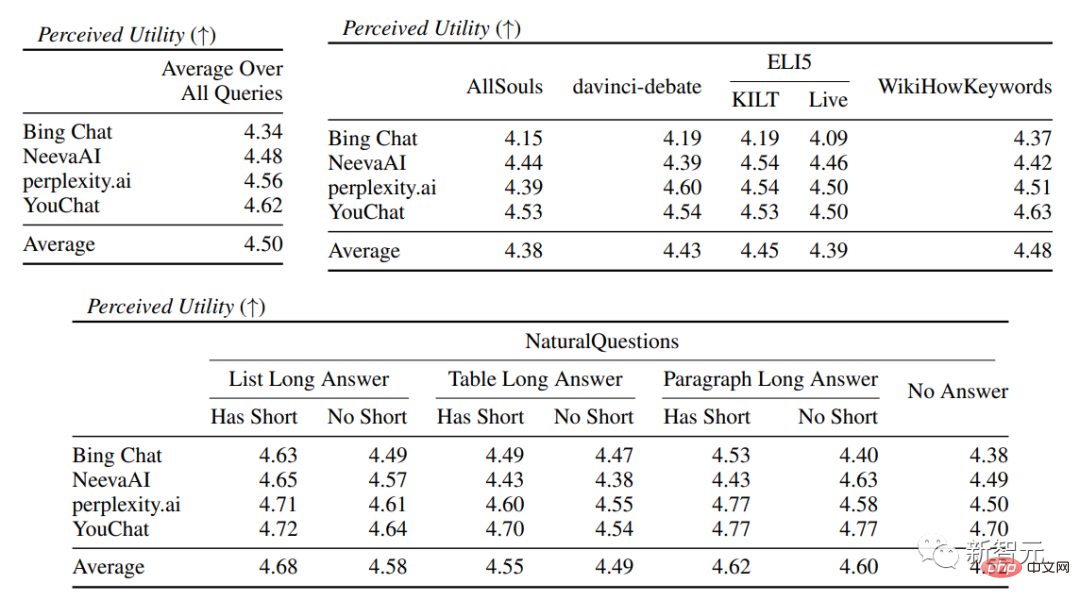
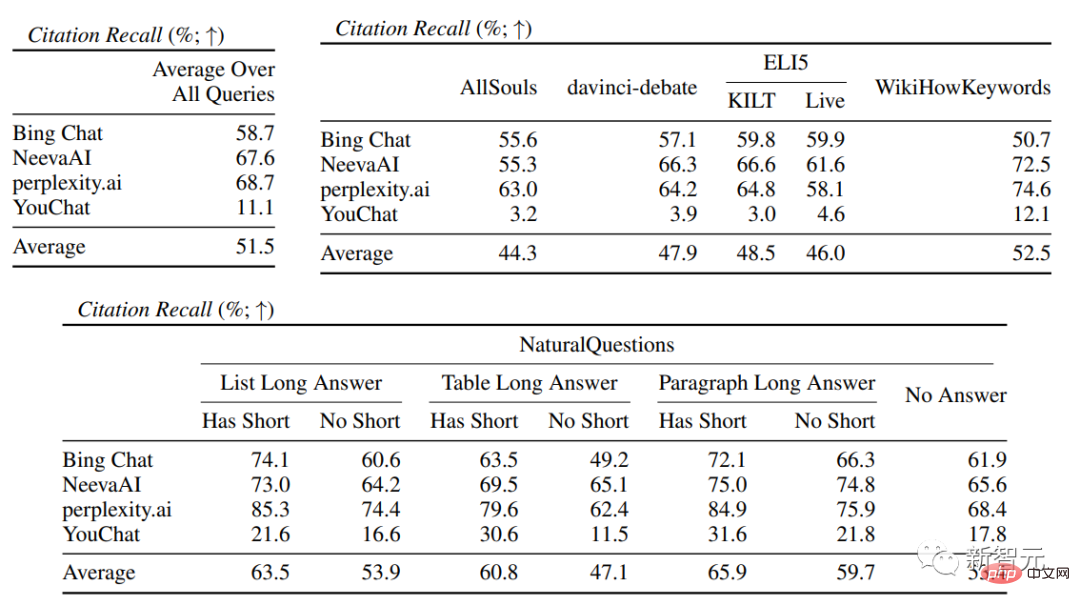
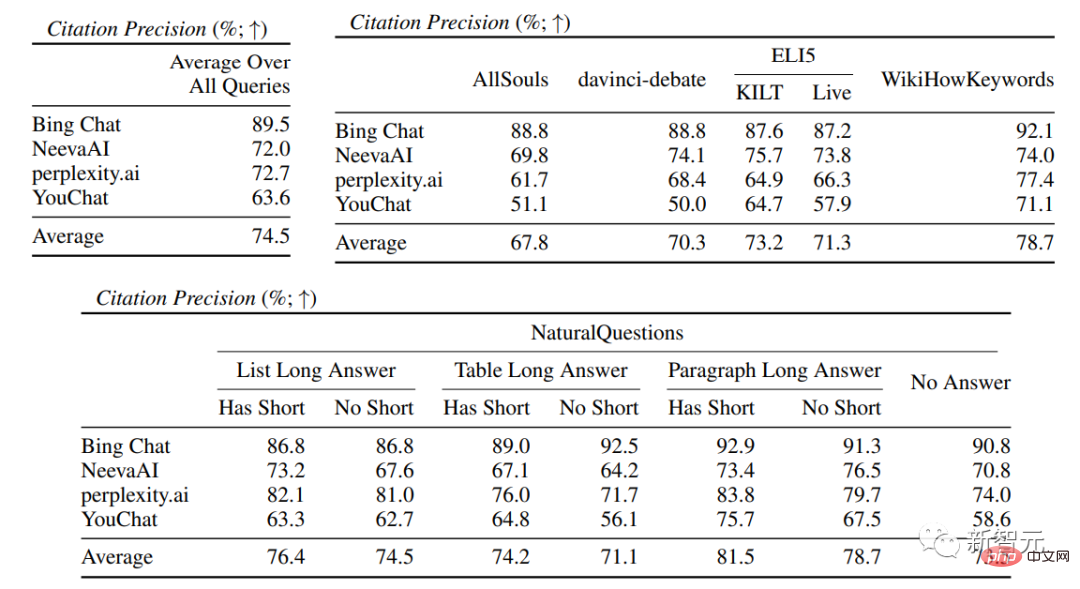
##Evaluation indicatorsmainly include fluency, that is Whether the generated text is coherent; Usefulness, that is, whether the search engine's reply is helpful to the user, and whether the information in the answer can solve the problem; citation recall, that is, the generated The proportion of sentences about external websites that contain citation support; Citation Precision, that is, the proportion of generated citations that support its related sentences. Fluency Simultaneously display the user query, the generated reply and the statement "The reply is fluent and semantically coherent", Annotators rated the data on a five-point Likert scale. Perceived utility Similar to fluency, Annotators are asked to rate their agreement with the statement that the response is useful and informative to the user's query. Citation recall (citation recall) Citation recall refers to the value of citations that are fully supported by their related citations The proportion of sentences that are verified, so the calculation of this indicator requires identifying the sentences in the responses that are worthy of verification, and assessing whether each sentence worthy of verification is supported by relevant citations. In the "Identifying Sentences Worth Verifying" process, the researchers consider each generated sentence about the external world It’s all worth verifying, even the ones that may seem obvious and trivial, because what may seem like obvious “common sense” to some readers may not actually be correct. The goal of a search engine system should be to provide a reference source for all generated sentences about the outside world so that readers can easily verify any narrative in the generated reply. This cannot be done for the sake of simplicity. Sacrifice verifiability. So in fact the annotators verify all the generated sentences, except for those responses where the system is the first person, such as "As a language model, I am not capable of... ", or questions to users, such as "Do you want to know more?" etc. Assess "Whether a statement worthy of verification is adequately supported by its relevant citations" can be attributed to the identified source (AIS, attributable to identified) sources) Evaluation framework, the annotator performs binary annotation, that is, if an ordinary listener agrees that "based on the quoted web page, it can be concluded...", then the citation can fully support the reply. Citation accuracy In order to measure the accuracy of citations, annotators need to judge Whether each quotation provides full, partial, or irrelevant support for the sentence to which it relates. Full support : All information in the sentence is supported by the citation. Partial support : Some information in the sentence is supported by the citation, but other parts may be missing or contradictory. Irrelevant support (No support) : If the referenced web page is completely irrelevant or contradictory. For sentences with multiple relevant citations, annotators will be additionally required to use the AIS evaluation framework to determine whether all relevant citation web pages as a whole provide sufficient support for the sentence (II metajudgment). In the fluency and usefulness evaluation, it can be seen that each search engine is able to generate very smooth and useful replies. In the specific search engine evaluation, you can see that Bing Chat has the lowest fluency/usefulness rating (4.40/4.34), followed by NeevaAI (4.43/4.48), perplexity.ai (4.51/4.56), and YouChat (4.59/4.62). In different categories of user queries, it can be seen that shorter retrieval questions are usually smoother than long questions, and usually only answer factual knowledge; some difficult questions Questions often require aggregation of different tables or web pages, and the synthesis process reduces the overall flow. In the citation evaluation, it can be seen that existing generative search engines often fail to fully or correctly cite web pages, and on average only 51.5% of the generated sentences are fully supported by citations ( Recall), only 74.5% of the citations fully support their related sentences (precision). This value is unacceptable for a search engine system that already has millions of users , especially when generating responses often contains a large amount of information. And There are large differences in citation recall and precision between different generative search engines , with perplexity.ai achieving the highest recall ( 68.7), while NeevaAI (67.6), Bing Chat (58.7) and YouChat (11.1) are lower. On the other hand, Bing Chat achieved the highest accuracy (89.5) , followed by perplexity.ai (72.7), NeevaAI (72.0) and YouChat ( 63.6) Across different user queries, the citation recall gap between NaturalQuestions queries with long answers and non-NaturalQuestions queries is close to 11% (respectively 58.5 and 47.8); Similarly, citation recall between NaturalQuestions queries with short answers and NaturalQuestions queries without short answers The difference is nearly 10% (63.4 for queries with short answers, 53.6 for queries with only long answers, and 53.4 for queries with no long or short answers). The citation rate will be lower in questions without web page support. For example, when evaluating open-ended AllSouls paper questions, generative search engines will The citation recall rate is only 44.3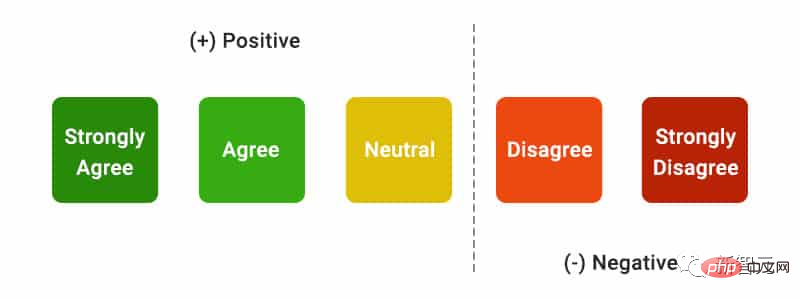
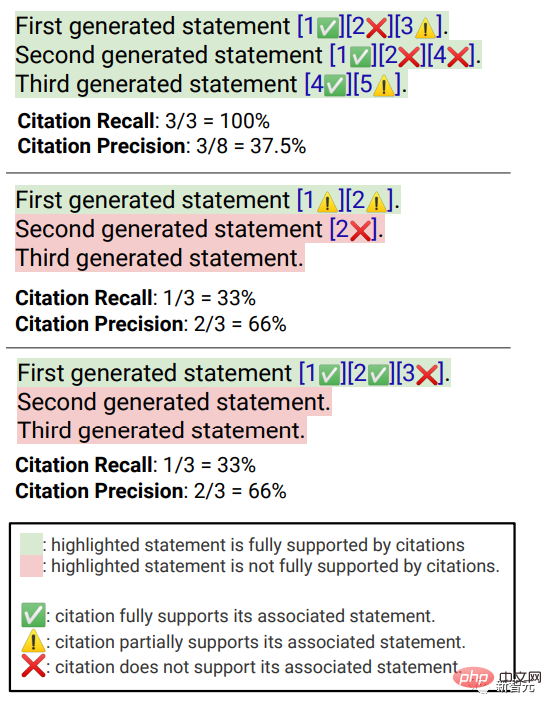
Experimental results
The above is the detailed content of Comprehensive comparison of four 'ChatGPT search' models! Hand-annotated by a Chinese doctor from Stanford: New Bing has the lowest fluency, and nearly half of the sentences are not quoted.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Assets launches a new AI intelligent trading system to lead the new era of trading efficiency! The well-known comprehensive trading platform Global Assets officially launched its AI intelligent trading system, aiming to use technological innovation to improve global trading efficiency, optimize user experience, and contribute to the construction of a safe and reliable global trading platform. The move marks a key step for global assets in the field of smart finance, further consolidating its global market leadership. Opening a new era of technology-driven and open intelligent trading. Against the backdrop of in-depth development of digitalization and intelligence, the trading market's dependence on technology is increasing. The AI intelligent trading system launched by Global Assets integrates cutting-edge technologies such as big data analysis, machine learning and blockchain, and is committed to providing users with intelligent and automated trading services to effectively reduce human factors.
 What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
The top exchanges include: 1. Binance, the world's largest trading volume, supports 600 currencies, and the spot handling fee is 0.1%; 2. OKX, a balanced platform, supports 708 trading pairs, and the perpetual contract handling fee is 0.05%; 3. Gate.io, covers 2700 small currencies, and the spot handling fee is 0.1%-0.3%; 4. Coinbase, the US compliance benchmark, the spot handling fee is 0.5%; 5. Kraken, the top security, and regular reserve audit.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Exchanges play a vital role in today's cryptocurrency market. They are not only platforms for investors to trade, but also important sources of market liquidity and price discovery. The world's largest virtual currency exchanges rank among the top ten, and these exchanges are not only far ahead in trading volume, but also have their own advantages in user experience, security and innovative services. Exchanges that top the list usually have a large user base and extensive market influence, and their trading volume and asset types are often difficult to reach by other exchanges.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 Top 10 Virtual Currency Trading Websites Ranking (Latest Ranking in 2025)
Apr 21, 2025 pm 12:18 PM
Top 10 Virtual Currency Trading Websites Ranking (Latest Ranking in 2025)
Apr 21, 2025 pm 12:18 PM
The recommendations of cryptocurrency trading platforms for different needs are as follows: 1. Newbies are given priority to Coinbase and Binance because of their simple and easy to use interface; 2. High-frequency traders should choose OKX and Gate.io to enjoy low latency and low fees; 3. Institutions and large-value traders recommend Kraken and Gemini because of their compliance and insurance protection; 4. Users who explore small currencies are suitable for KuCoin and Huobi because of their innovation zone and small currencies support.
