
 Technology peripherals
AI
Apple develops 'AI architect' GAUDI: generates ultra-realistic 3D scenes based on text!
Technology peripherals
AI
Apple develops 'AI architect' GAUDI: generates ultra-realistic 3D scenes based on text!
Apple develops 'AI architect' GAUDI: generates ultra-realistic 3D scenes based on text!

Nowadays, new text-generated image models are released every once in a while, and each of them has very powerful effects. They always amaze everyone. This field has already reached the sky. However, AI systems such as OpenAI's DALL-E 2 or Google's Imagen can only generate two-dimensional images. If text can also be turned into a three-dimensional scene, the visual experience will be doubled. Now, the AI team from Apple has launched the latest neural architecture for 3D scene generation - GAUDI.

It can capture complex and realistic 3D scene distribution, immersive rendering from a moving camera, and also based on text prompts. Create 3D scenes! The model is named after Antoni Gaudi, a famous Spanish architect.

##Paper address: https://arxiv.org/pdf/2207.13751.pdf
1 3D rendering based on NeRFs
Neural rendering combines computer graphics with artificial intelligence and has produced many methods of generating 3D models from 2D images. system. For example, the recently developed 3D MoMa by Nvidia can create a 3D model from less than 100 photos in an hour. Google also relies on Neural Radiation Fields (NeRFs) to combine 2D satellite and Street View images into 3D scenes in Google Maps to achieve immersive views. Google’s HumanNeRF can also render 3D human bodies from videos.
Currently, NeRFs are mainly used as a neural storage medium for 3D models and 3D scenes, which can be rendered from different camera perspectives. NeRFs are also already starting to be used in virtual reality experiences.
So, can NeRFs, with its powerful ability to realistically render images from different camera angles, be used in generative AI? Of course, there are research teams that have tried to generate 3D scenes. For example, Google launched the AI system Dream Fields for the first time last year. It combines NeRF's ability to generate 3D views with OpenAI's CLIP's ability to evaluate image content, and finally achieves the ability to Generate NeRF matching text description.

##Caption: Google Dream Fields
However, Google’s Dream Fields can only generate 3D views of a single object, and there are many difficulties in extending it to completely unconstrained 3D scenes. The biggest difficulty is that there are great restrictions on the position of the camera. For a single object, every possible and reasonable camera position can be mapped to a dome, but in a 3D scene, the position of the camera will be affected by objects and walls, etc. Obstacle limitations. If these factors are not considered during scene generation, it will be difficult to generate a 3D scene.2
3D rendering expert GAUDI
For the above-mentioned problem of limited camera position, Apple's GAUDI model has come up with three specialized networks To make it easy: GAUDI has acamera pose decoder, which separates the camera pose from the 3D geometry and appearance of the scene, can predict the possible position of the camera, and ensure that the output is a valid position of the 3D scene architecture .
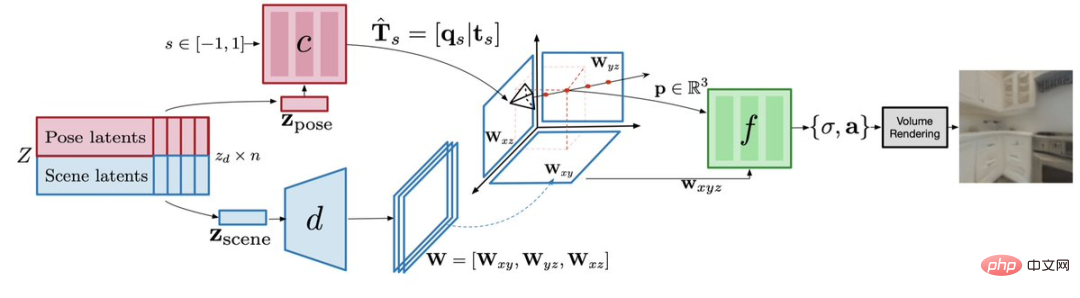
Note: Decoder model architecture Scene decoder for scenariosYou can predict the representation of a three-dimensional plane, which is a 3D canvas.
Then,Radiation Field Decoder will use the volume rendering equation on this canvas to draw subsequent images.
GAUDI’s 3D generation consists of two stages:One is the optimization of latent and network parameters: learning latent representations that encode the 3D radiation fields and corresponding camera poses of thousands of trajectories. Unlike for a single object, the effective camera pose varies with the scene, so it is necessary to encode the valid camera pose for each scene. The second is to use the diffusion model to learn a generative model on the latent representation, so that it can model well in both conditional and unconditional reasoning tasks. The former generates 3D scenes based on text or image prompts, while the latter generates 3D scenes based on camera trajectories. With 3D indoor scenes, GAUDI can generate new camera movements. As in some of the examples below, the text description contains information about the scene and the navigation path. Here the research team adopted a pre-trained RoBERTa-based text encoder and used its intermediate representation to adjust the diffusion model. The generated effect is as follows: Text prompt: Enter the kitchen Text prompt: Go upstairs Text prompt: Go through the corridor In addition, using pre-trained ResNet-18 as the image encoder, GAUDI is able to sample the radiation field of a given image observed from random viewpoints, thereby extracting from the image cues Create 3D scenes. Image prompt: Generate 3D scene: Image Tips: Generate 3D scene: Researcher Experiments on four different datasets, including the indoor scanning dataset ARKitScences, show that GAUDI can reconstruct learned views and match the quality of existing methods. Even in the huge task of producing 3D scenes with hundreds of thousands of images for thousands of indoor scenes, GAUDI did not suffer from mode collapse or orientation problems. The emergence of GAUDI will not only have an impact on many computer vision tasks, but its 3D scene generation capabilities will also be beneficial to model-based reinforcement learning and planning, SLAM and 3D content. Production and other research fields. At present, the quality of the video generated by GAUDI is not high, and many artifacts can be seen. However, this system may be a good start and foundation for Apple's ongoing AI system for rendering 3D objects and scenes. It is said that GAUDI will also be applied to Apple's XR headsets for generating digital positions. You can look forward to it~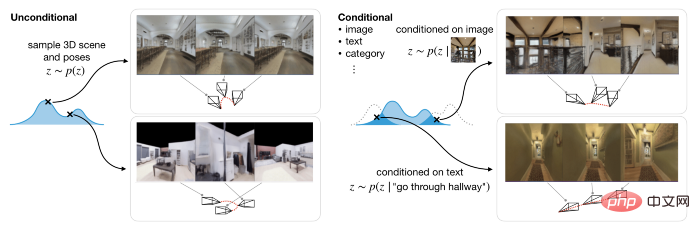







The above is the detailed content of Apple develops 'AI architect' GAUDI: generates ultra-realistic 3D scenes based on text!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
