

1. Import the jieba library and define the text
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2. Segment the text
words = jieba.cut(text)
This step will divide the text into several words and return a generator object words. You can use for to loop through all the words.
3. Count word frequency
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1This step traverses all words, counts the number of times each word appears, and saves it to a dictionaryword_count. When counting word frequencies, optimization can be performed by removing stop words. Here, words with a length less than 2 are simply filtered.
4. Result output
for word, count in word_count.items():
print(word, count)
In order to count the word frequency more accurately, we can count the word frequency in the word frequency statistics Add stop words to remove some common but meaningless words. The specific steps are as follows:
Define the stop word list
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
Segment the text and filter the stop words
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
Count word frequencies and output the results
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)After adding stop words, the output result is:

It can be seen that the disabled word kind of is not displayed.
Different from word frequency statistics that simply count words, jieba’s principle of keyword extraction is based on TF-IDF ( Term Frequency-Inverse Document Frequency) algorithm. The TF-IDF algorithm is a commonly used text feature extraction method that can measure the importance of a word in the text.
Specifically, the TF-IDF algorithm contains two parts:
Term Frequency: refers to the number of times a word appears in the text, usually using a Simple statistical value representation, such as word frequency, bigram word frequency, etc. Word frequency reflects the importance of a word in the text, but ignores the prevalence of the word in the entire corpus.
Inverse Document Frequency: refers to the reciprocal of the frequency of a word appearing in all documents, and is used to measure the prevalence of a word. The greater the inverse document frequency, the more common a word is and the lower the importance; the smaller the inverse document frequency is, the more unique the word is and the higher the importance.
The TF-IDF algorithm calculates the importance of each word in the text by comprehensively considering word frequency and inverse document frequency to extract keywords. In jieba, the specific implementation of keyword extraction includes the following steps:
Perform word segmentation on the text and obtain the word segmentation results.
Count the number of times each word appears in the text and calculate the word frequency.
Count the number of times each word appears in all documents and calculate the inverse document frequency.
Comprehensive consideration of word frequency and inverse document frequency, calculate the TF-IDF value of each word in the text.
Sort the TF-IDF values and select the words with the highest scores as keywords.
For example:
F (Term Frequency) refers to the frequency of a certain word appearing in a document. The calculation formula is as follows:
T F = (number of times a word appears in the document) / (total number of words in the document)
For example, in a document containing 100 words, a certain word appears 10 times , then the TF of the word is
10 / 100 = 0.1
IDF (Inverse Document Frequency) refers to the reciprocal of the number of documents in which a certain word appears in the document collection. The calculation formula is as follows:
I D F = log (total number of documents in the document collection/number of documents containing the word)
For example, in a document collection containing 1,000 documents, a certain word appears in 100 documents If so, the IDF of the word is log (1000 / 100) = 1.0
TFIDF is the result of multiplying TF and IDF. The calculation formula is as follows:
T F I D F = T F ∗ I D F
It should be noted that the TF-IDF algorithm only considers the occurrence of words in the text and ignores the correlation between words. Therefore, in some specific application scenarios, other text feature extraction methods need to be used, such as word vectors, topic models, etc.
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)In this example, we first imported the jieba.analyse module, and then defined a text to be extracted for keywordstext. Next, we use the jieba.analyse.extract_tags() function to extract keywords, where the topK parameter indicates the number of keywords to be extracted, and the withWeight parameter indicates whether Returns the weight value of the keyword. Finally, we iterate through the keyword list and output each keyword and its corresponding weight value.
The output result of this function is:
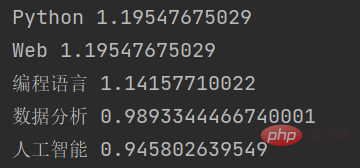
As you can see, jieba extracted several keywords in the input text based on the TF-IDF algorithm, and returned the weight value of each keyword.
The above is the detailed content of How to use Jieba for word frequency statistics and keyword extraction in Python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



