

What is k-nearest neighbor algorithm?

K Nearest Neighbor algorithm is also called KNN algorithm. This algorithm is a relatively classic algorithm in machine learning. Generally speaking, KNN algorithm is a relatively easy to understand algorithm.
If a sample is the largest among the k most similar (that is, the nearest neighbor in the feature space) samples in the feature space If most of them belong to a certain category, the sample also belongs to this category.
Source: KNN algorithm was first proposed by Cover and Hart as a classification algorithm
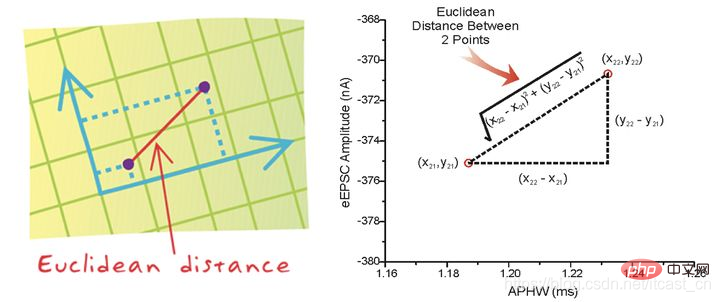
The distance between two samples can be calculated by the following formula, also called Euclidean distance. The distance formula will be discussed later
Application scenarios For: house price prediction, sales amount prediction, loan amount prediction
What is linear regression?
Linear regression is the use of regression equations (functions) to predict one or more independent variables An analytical way to model the relationship between (eigenvalues) and dependent variables (target values).
Features: The situation with only one independent variable is called univariate regression, and the situation with more than one independent variable is called multiple regression.

Linear regression is represented by a matrix, for example:
So how do you understand it? ? Let’s look at a few examples:
Final grade: 0.7×examination grade 0.3×daily grade
House price = 0.02×central area Distance 0.04×city nitric oxide concentration (-0.12×average housing price) 0.254×urban crime rate
In the above two examples, we see that the relationship between the characteristic value and the target value is established There is a relationship, which can be understood as a linear model.
Logistic Regression is a classification model in machine learning. Logistic regression is a classification algorithm. Although the name has regression in it. Due to the simplicity and efficiency of the algorithm, it is widely used in practice.
Application scenarios: Ad click rate, whether it is spam, whether it is sick, financial fraud, fake account.
You can find a feature here, that is, both categories belong to judgment, and logistic regression is a powerful tool for solving two-classification problems.
To master logistic regression, you must master two points:
What are the input values in logistic regression?
How to judge the output of logistic regression?
Input:

##Activation function: sigmoid function

Judgment criteria
The regression results are input into the sigmoid function, and the output result is: [ A probability value in the interval 0, 1], the default is 0.5 as the threshold.

The final classification of logistic regression is to judge whether it belongs to a certain category through the probability value of belonging to a certain category, and this category is marked as 1 (positive example) by default, and the other category will be marked as 0 (negative example) ). (Convenient for loss calculation)
Output result explanation (important): Suppose there are two categories A and B, and assume that our probability value is the probability value belonging to the category A(1) . Now there is a sample input to the logistic regression output result 0.55, then this probability value exceeds 0.5, which means that the result of our training or prediction is the A(1) category. Then on the contrary, if the result is 0.3, then the training or prediction result will be the B(0) category.
The threshold of logistic regression can be changed. For example, in the above example, if you set the threshold to 0.6, then the output result is 0.55, which belongs to category B.
The origin of the decision tree idea is very simple. The conditional branch structure in programming is the if-else structure. The earliest Decision tree is a classification learning method that uses this kind of structure to segment data
Decision tree: It is a tree structure in which each internal node represents a judgment on an attribute. Each branch represents the output of a judgment result, and finally each leaf node represents a classification result. It is essentially a tree composed of multiple judgment nodes.
How do you understand this sentence? Through a conversation example

The above case is a girl who puts age at the top through qualitative subjective consciousness, then if This process needs to be quantified, how to deal with it?
At this time, you need to use the knowledge in information theory: information entropy and information gain.

##Ensemble learning solves a single prediction problem by building several models. It works by generating multiple classifiers/models, each learning and making predictions independently. These predictions are ultimately combined into a combined prediction that is better than any single classification prediction.
Clustering algorithm
Business push based on location information, news clustering, filtering and sorting.
Image segmentation, dimensionality reduction, identification; outlier detection; abnormal credit card consumption; discovery of gene fragments with the same function.
Clustering algorithm:
In the clustering algorithm, samples are divided into different categories based on the similarity between samples. Different similarity calculation methods will result in different clustering results. Commonly used similarity calculation methods include the Euclidean distance method.
The above is the detailed content of What are the necessary algorithms for entry-level machine learning?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



