
 Technology peripherals
AI
ChatGPT Special Topic: The Capabilities and Future of Large Language Models
Technology peripherals
AI
ChatGPT Special Topic: The Capabilities and Future of Large Language Models
ChatGPT Special Topic: The Capabilities and Future of Large Language Models

1. Commercialization of Generative Models
Nowadays, the generative AI track is hot. According to PitchBook statistics, the generative AI track will receive a total of approximately US$1.4 billion in financing in 2022, almost reaching the total of the past five years. Star companies such as OpenAI and Stability AI, and other start-ups such as Jasper, Regie.AI, Replika, etc. have all received capital favor.
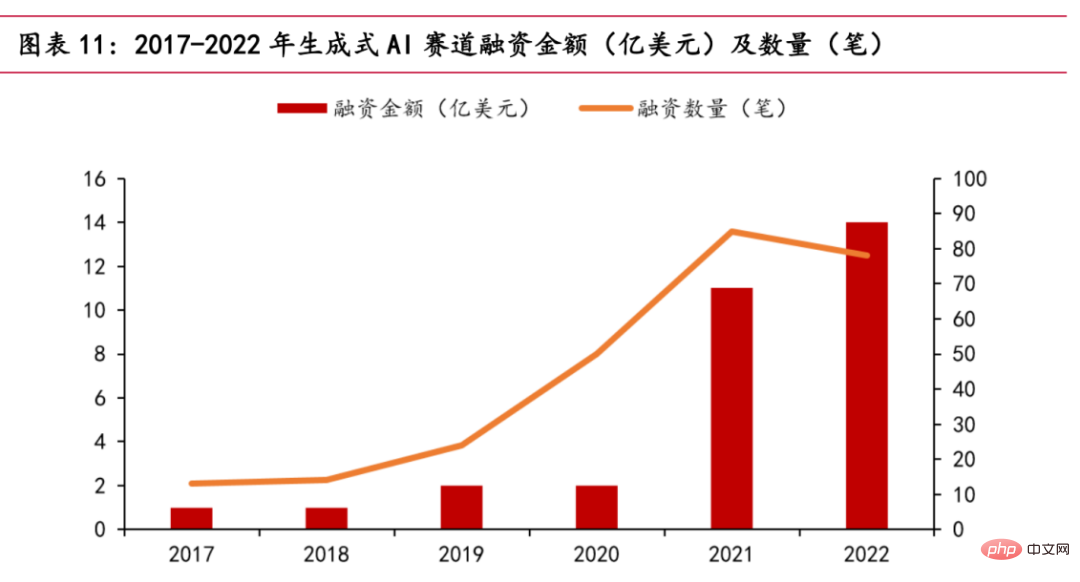
Chart of the relationship between financing amount and time
In October 2022, Stability AI received approximately US$100 million in financing and released the open source model Stable Diffusion, which can be based on The text description input by the user generates pictures, detonating the field of AI painting. On November 30, 2022, after ChatGPT announced its public beta, five days after it went online, the number of global users exceeded one million. In less than 40 days since its launch, daily active users have exceeded 10 million. In the early morning of March 15, 2023, OpenAI released the most powerful GPT series model - GPT-4, which provides a large-scale multi-modal model that can accept image and text input and produce text output, which has a disruptive impact in the industry. . On March 17, 2023, Microsoft held the Microsoft 365 Copilot conference, officially installed OpenAI's GPT-4 model into the Office suite, and launched the new AI function Copilot. It can not only make PPT and write copy, but also perform analysis and generate videos. In addition, various major domestic manufacturers have also announced the launch of products similar to ChatGPT. On February 8, Alibaba experts broke the news that Damo Academy is developing a ChatGPT-like conversational robot and has opened it to employees within the company for testing. It is possible to deeply combine AI large model technology with DingTalk productivity tools. On February 8, He Xiaodong, Vice President of JD.com, said frankly: JD.com has rich scenarios and high-quality data in the field of ChatGPT. On February 9, relevant sources at Tencent said: Tencent currently has plans for products similar to ChatGPT and AI-generated content, and special research is also progressing in an orderly manner. NetEase said that its education business will integrate AI-generated content, including but not limited to AI speaking teachers, essay scoring and evaluation, etc. On March 16, Baidu officially released the large language model and generative AI product "Wen Xin Yi Yan". Two days after the release, 12 companies have completed the first batch of contract cooperation and applied for Baidu Intelligent Cloud Wen Xin Yi Yan API calling service. The number of companies tested reached 90,000.
At present, large models have gradually penetrated into our lives. In the future, all walks of life are likely to undergo earth-shaking changes. Taking ChatGPT as an example, it includes the following aspects:
- ChatGPT Media: It can realize intelligent news writing and improve the effectiveness of news;
- ChatGPT Film and Television: Customize film and television content according to public interests, Obtaining higher ratings, box office and word-of-mouth reduces the cost of content creation for film and television production teams and improves creative efficiency.
- ChatGPT Marketing: Act as a virtual customer service to assist product marketing. For example, 24-hour product introduction and online services reduce marketing costs; can quickly understand customer needs and keep up with technological trends; provide stable and reliable consulting services with strong controllability and security.
- ChatGPT Entertainment: Real-time chat objects, enhancing companionship and fun.
- ChatGPT Education: Provides new educational tools to quickly check and fill in gaps through self-service questions.
- ChatGPT Finance: Realize financial information, automated production of financial products, and create virtual financial advisors.
- ChatGPT Medical: Quickly understand the patient’s condition and give timely feedback, providing immediate emotional support.
It should be noted that although the main discussion here is the implementation of large language models, in fact, other large models in multiple modalities (audio, video, pictures) also have broad application scenarios.
2. Introduction to generative models
1. The mainstream large language model: LaMDA
is released by Google. The LaMDA model is based on the transformer framework, has 137 billion model parameters, and has the ability to model long-distance dependencies in text. The model is trained through conversations. It mainly includes two processes: pre-training and fine-tuning: In the pre-training stage, they used up to 1.56T of public conversation data sets and web page text, using the language model (LM) as the objective function of training, that is, the goal is to predict the next character (token). In the fine-tuning phase, they designed multiple tasks, such as scoring attributes of responses (sensitivity, safety, etc.), to give the language model its human preferences. The figure below shows one type of fine-tuning task.

LaMDA model pre-training phase

One of the tasks in the LaMDA model fine-tuning phase
LaMDA model Focuses on dialogue generation tasks but often makes factual errors. Google released Bard (an experimental conversational AI service) this year, which is powered by the LaMDA model. However, during Bard's press conference, Bard made factual errors, which caused Google's stock price to plummet on Wednesday, falling more than 8% intraday, as low as about $98 on the refresh day, and its market value evaporated by $110 billion, which is disappointing.
2. Mainstream large language model: InstructGPT
The InstructGPT model is based on the GPT architecture and mainly consists of supervised fine-tuning (Supervise Fune-Tuning, SFT) and human feedback reinforcement learning (Reinforce Learning Human Fune- tuning, RLHF). ChatGPT, a conversational product powered by InstructGPT, focuses on generating language text and can also generate code and perform simple mathematical operations. The specific technical details have been discussed in detail in the previous two issues. Readers can go there to read them and will not repeat them here.
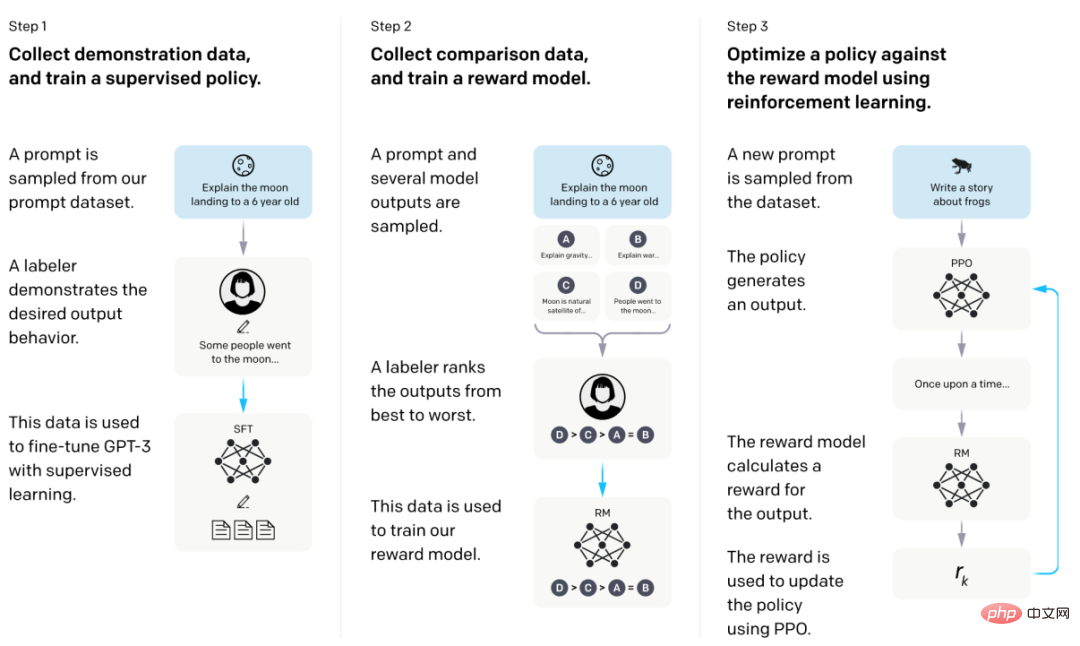
InstructGPT model training flow chart
3. Mainstream large language model: Cluade
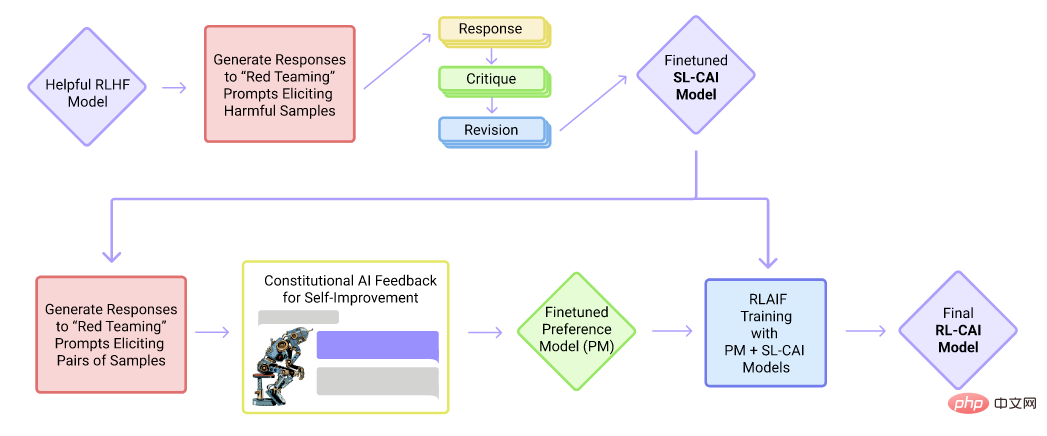
Cluade model training flow chart
Cluade is a conversational product of Anthropic Company. Cluade, like ChatGPT, is based on the GPT framework and is a one-way language model. However, unlike ChatGPT, it is mainly trained by reinforcement learning with supervised fine-tuning and AI feedback. In the supervised fine-tuning stage, it first formulates a series of rules (Constitution), such as not generating harmful information, not generating racial bias, etc., and then obtains supervised data based on these rules. Then, let AI judge the quality of the responses and automatically train the data set for reinforcement learning.
Compared with ChatGPT, Claude can reject inappropriate requests more clearly, and the connections between sentences are more natural. Claude is willing to speak up when faced with a problem that is beyond his capabilities. Currently, Cluade is still in the internal testing stage. However, according to the internal test results of Scale Sepllbook team members, compared to ChatGPT, Claude is stronger in 8 of the 12 tasks tested.
3. Capabilities of large language models
We have statistics on large language models at home and abroad, as well as model capabilities, open source situations, etc.
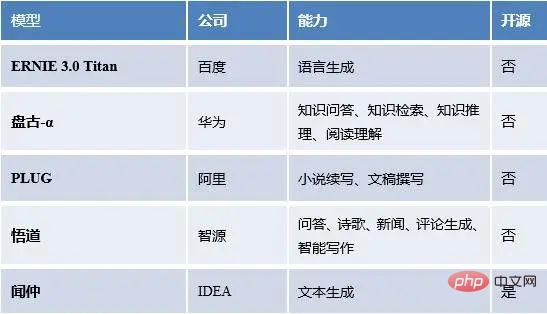
Domestic popular large language models
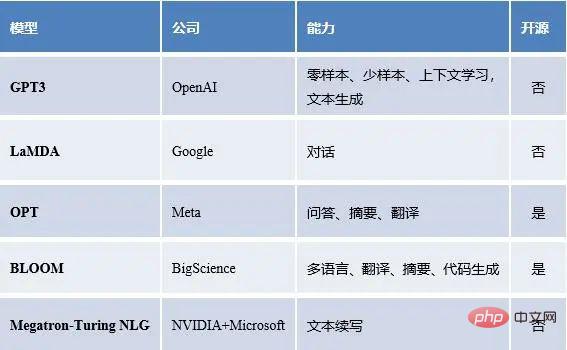
Foreign popular large language models
You can see It turns out that large language models have a variety of capabilities, including but not limited to few-shot learning, zero-shot transfer, and so on. So a very natural question arises, how do these abilities come about? Where does the power of large language models come from? Next, we try to answer the above doubts.
The figure below shows some mature large language models and evolution processes. To sum up, most models will go through three stages: pre-training, instruction fine-tuning and alignment. Representative models include Deepmind’s Sparrow and OpenAI’s ChatGPT.
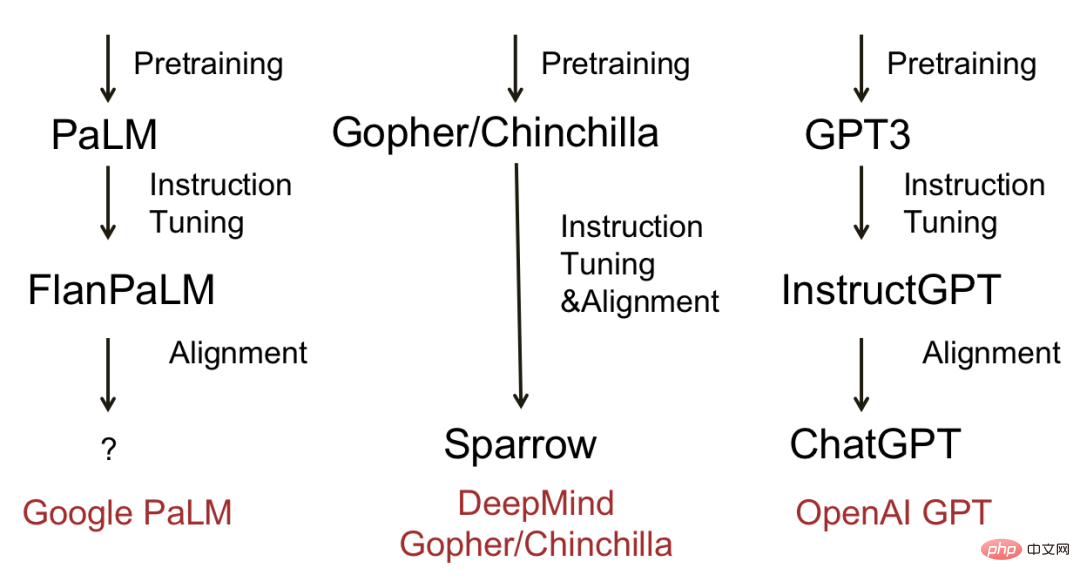
Evolutionary diagram of popular large language models
So, behind each step, what kind of capabilities can the model achieve? Dr. Fu Yao from the University of Edinburgh summarized what he believed to be the corresponding relationship between steps and abilities, giving us some inspiration.
1. Pre-training phase. The goal of this phase is to obtain a powerful basic model. Correspondingly, the capabilities demonstrated by the model at this stage include: language generation, context learning capabilities, world knowledge, reasoning capabilities, etc. Representative models at this stage include GPT-3, PaLM, etc.
2. Instruction fine-tuning stage. The goal of this phase is to unlock some emergent abilities. The emergent ability here specifically refers to the ability that small models do not have but only large models have. The model that has undergone instruction fine-tuning has capabilities that the basic model does not have. For example, by constructing new instructions, the model can solve new tasks; another example is the ability of the thinking chain, that is, by showing the model the reasoning process, the model can also imitate the correct reasoning, etc. Representative models include InstructGPT, Flan, etc.
Alignment stage. The goal of this stage is to make the model possess human values, such as to generate informative replies and not to produce discriminatory remarks, etc. It can be thought that the alignment stage gives the models “personality”. The representative model of this type is ChatGPT.
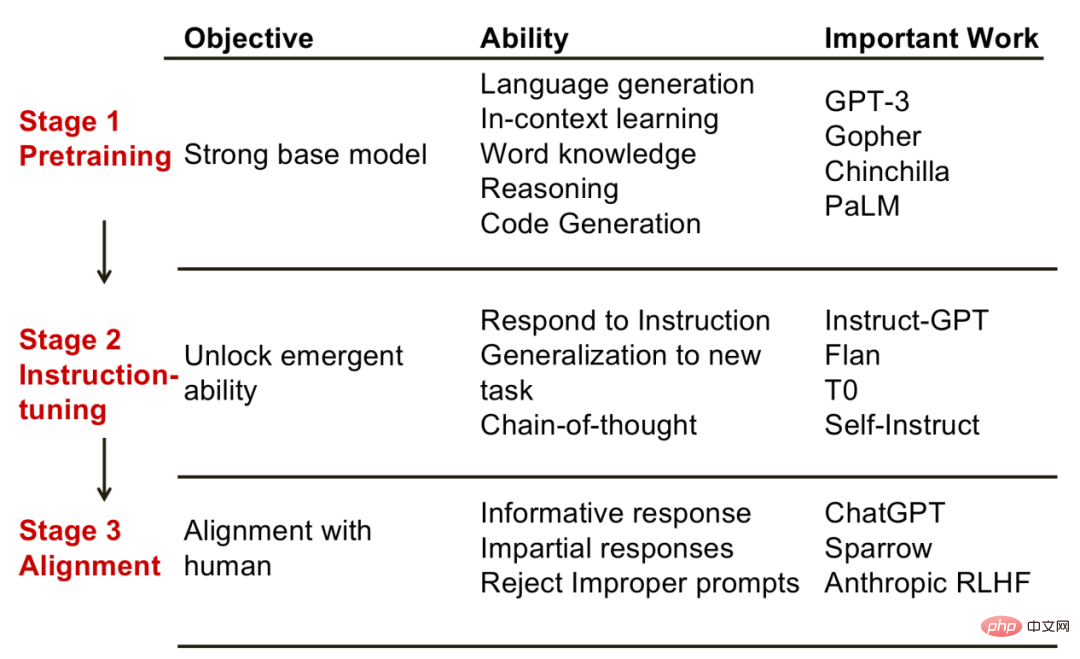
Three stages of large language model. The picture comes from "Fu Yao: On the Source of the Ability of Large Language Models"
Generally speaking, the above three stages complement each other and are indispensable. Only when a sufficiently powerful basic model is obtained in the pre-training stage can it be possible to stimulate (or enhance) other capabilities of the language model through instruction fine-tuning. The alignment stage gives the model a certain "character" to better comply with some requirements of human society.
4. Generative model identification
While large language model technology brings convenience, it also contains risks and challenges. At a technical level, the authenticity of the content generated by GPT cannot be guaranteed, such as harmful remarks, etc. At the usage level, users may abuse AI-generated texts in fields such as education and scientific research. Currently, many companies and institutions have begun to impose restrictions on the use of ChatGPT. Microsoft and Amazon have banned company employees from sharing sensitive data to ChatGPT for fear of leaking confidential information; the University of Hong Kong has banned the use of ChatGPT or other artificial intelligence tools in all classes, assignments and assessments at the University of Hong Kong. We mainly introduce related work in industry.
GPTZero: GPTZero is the earliest text generation and identification tool. It is an online website (https://gptzero.me/) published by Edward Tian (a CS undergraduate student from Princeton, USA). Its principle relies on text perplexity (PPL) as an indicator to determine who wrote the given content. Among them, perplexity is used to evaluate the quality of the language model, which is essentially to calculate the probability of a sentence appearing.
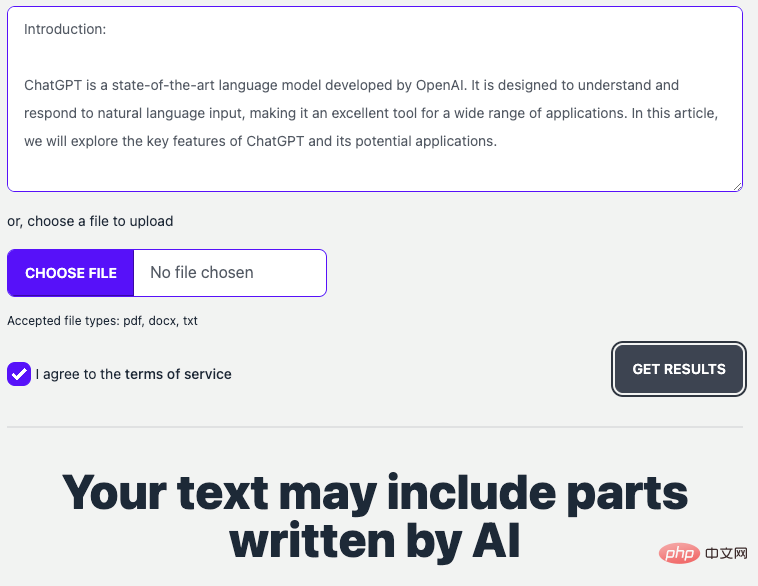
GPTZero website interface
(Here we use ChatGPT to generate a news report and let GPTZero determine whether it is generated text.)
GPT2 Output Detector: This tool is published by OpenAI. It leverages the "GPT2-Generated Content" and Reddit datasets, fine-tuned on RoBerta, to learn a detection classifier. That is, "fight magic with magic." The official website also reminds that the prediction results are more credible only when the text exceeds 50 characters (token).

GPT2 Output Detector website interface
AI Text Classifier: This tool is published by OpenAI. The principle is to collect human writing texts and AI writing texts on the same topic. Divide each text into prompt and reply pairs, and let the probability of GPT producing an answer after fine-tuning (for example, letting GPT produce Yes/No) as the result threshold. The tool's classification is very detailed, and the results include 5 categories: very unlikely to be generated by AI (threshold 0.98).
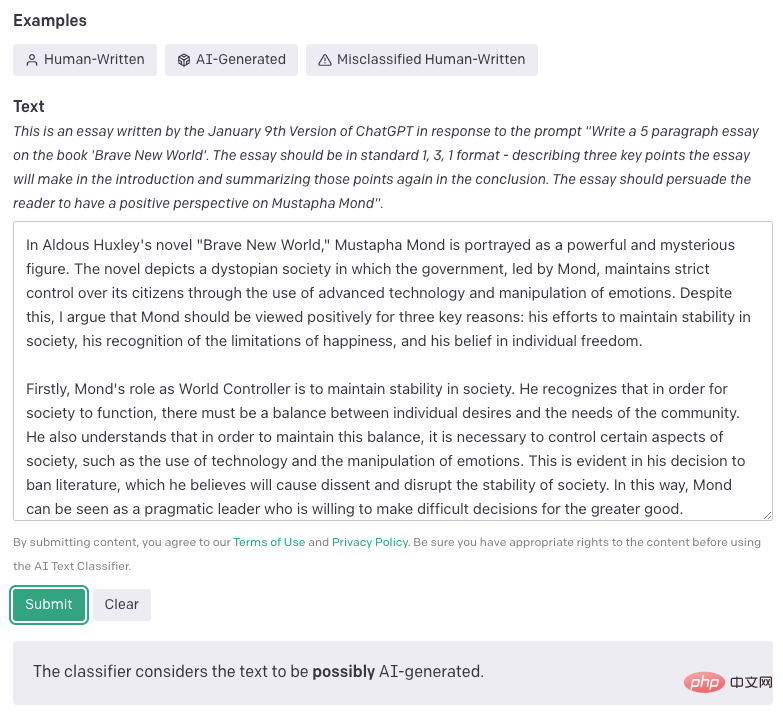
AI Text Classifier website interface
5. Summary & Outlook
Large language models have emergent capabilities that small models do not have, such as excellent Zero-sample learning, domain transfer, and thinking chain capabilities. The power of large models actually comes from pre-training, instruction fine-tuning and alignment. These three processes are closely related and have made today's super powerful large language models possible.
The large language model (GPT series) currently does not have the capabilities of confidence update, formal reasoning, Internet retrieval, etc. Some experts believe that if knowledge can be offloaded outside the model, the number of parameters will be greatly reduced, and the large language model will be greatly reduced. Models can really go a step further.
Only under reasonable supervision and governance, artificial intelligence technology can better serve people. There is a long way to go to develop large-scale models in China!
References
[1] https://stablediffusionweb.com
[2] https://openai.com/product/gpt-4
[3] LaMDA: Language Models for Dialog Applications, Arxiv 2022.10
[4] Constitutional AI: Harmlessness from AI Feedback, Arxiv 2022.12
[5] https://scale.com /blog/chatgpt-vs-claude#Calculation
[6] Guolian Securities: "ChatGPT has arrived, and commercialization is accelerating"
[7] Guotai Junan Securities: "ChatGPT Research Framework 2023》
[8] Fu Yao: Pre-training, instruction fine-tuning, alignment, specialization: On the source of large language model capabilities https://www.bilibili.com/video/BV1Qs4y1h7pn/?spm_id_from=333.880 .my_history.page.click&vd_source=da8bf0b993cab65c4de0f26405823475
[9] Analysis of a 10,000-word long article! Reproduce and use GPT-3/ChatGPT, what you should know https://mp.weixin.qq.com/s/ILpbRRNP10Ef1z3lb2CqmA
The above is the detailed content of ChatGPT Special Topic: The Capabilities and Future of Large Language Models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
