
 Technology peripherals
AI
Integrating GPT large model products, WakeData new round of product upgrades
Technology peripherals
AI
Integrating GPT large model products, WakeData new round of product upgrades
Integrating GPT large model products, WakeData new round of product upgrades

Recently, WakeData Weike Data (hereinafter referred to as "WakeData") has completed a new round of product capability upgrades.
At the product launch conference in November 2022, WakeData’s “three determinations” have been conveyed: always firmly invest in technology, comprehensively consolidate the scientific and technological capabilities and self-research rate of core products; always be firm Domestic adaptation capabilities support domestic chips, operating systems, databases, middleware, national secret algorithms, etc., and realize local substitution of foreign manufacturers in the same field; always firmly embrace the ecosystem and create a win-win situation with partners.
WakeData continues a new round of product capability upgrades. Relying on its technology accumulation in the past five years and its practice in real estate, retail, automobile and other industries and vertical fields, it has jointly developed privately owned products with strategic partners. WakeMind, a large industry model with centralized deployment capabilities, will help more companies revolutionize themselves, improve efficiency, and continue to liberate productivity in the AIGC era.
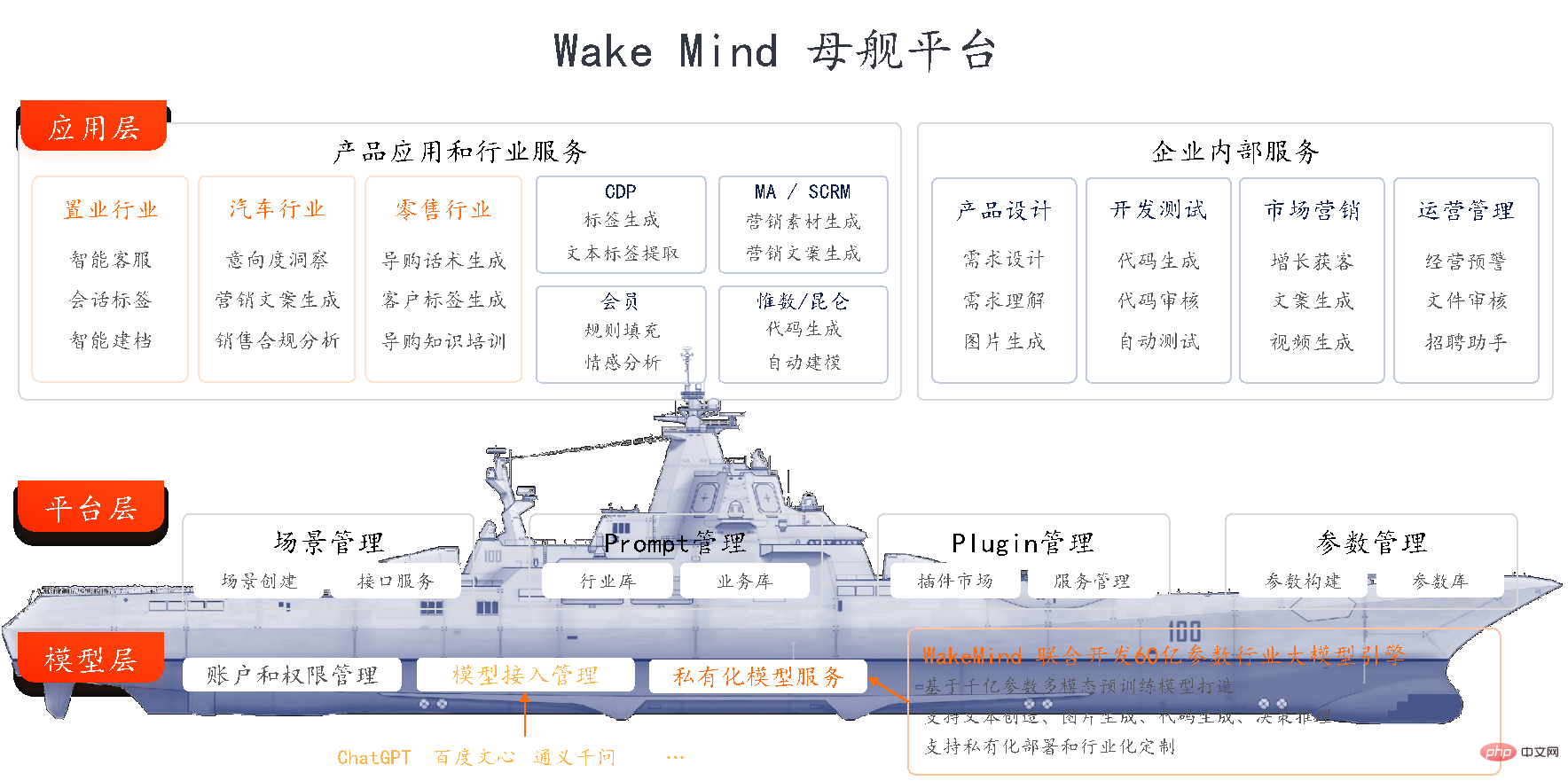
The three major platform layers of the WakeMind model
Model layer: The mothership platform will be based on privatized deployment and As the core engine with industry customization capabilities, WakeMind has been connected to large models such as ChatGPT. It also supports access to multiple large model capabilities such as Wen Xinyiyan and Tongyi Qianwen.
Platform layer: WakeMind is based on Prompt project, Plugin, LangChain and other methods realize efficient dialogue capabilities with large models. On the basis of zero-sample learning, the model can better understand contextual information through Prompt and Plugin management; by feeding industry corpus, the model can quickly learn industry knowledge and have the ability to think and reason about industries and vertical fields.
Application layer: The WakeMind mothership platform provides underlying capabilities to empower product applications and industry scenarios through carrier-based aircraft one after another, improving internal productivity of the enterprise.
For example, how does the mothership platform empower Weishu Cloud. In the process of building and using data assets with the help of Weishu Cloud Platform, enterprises often need to invest a large number of professional data development engineers to participate in business needs analysis and data development work, and a large number of tedious development tasks will lead to the entire data value realization cycle. Being elongated. Based on WakeMind empowerment, only through text interaction, Weishu Cloud can automatically generate corresponding data query statements and execute the query with one click, which can greatly improve the efficiency of data query, analysis, and development, and comprehensively reduce the technical threshold for data use. , to achieve the goal of making data available to everyone.
The three major characteristics of the WakeMind model
1) The number of parameters is more suitable for industrial and vertical field scenarios. To reach human-level content, AI-generated content often needs to be based on "pre-training and fine-tuning" large models; WakeData teamed up with the industry's leading multi-modal pre-trained large model manufacturer with hundreds of billions of parameters to compress 100 WakeMind model with 100 million parameters; in focused industries and vertical fields, based on P-Tuning V2, the parameters that need fine-tuning can be reduced to one thousandth of the original, significantly reducing the amount of calculation required for fine-tuning.
2) Text creation and code generation with industry-specific and vertical domain capabilities.
3) Support privatized deployment and industrial customization. Leading companies in industries or vertical fields hope to have the ability to privatize deployment and industry-specific customization of large models. How to conduct effective pre-training with small sample learning and low computing power consumption has become the technical threshold for industrial customized models. The accumulation of WakeData's industry data and vertical field data will enable large industry models to have industry know-how and form unique competitive advantages.
At the same time, WakeMind uses the Transformer architecture to generate tens of thousands of instruction compliance sample data in a self-instruct manner. It uses SFT (Supervised Fine-Tuning), RLHF and other technologies to achieve intent alignment. After quantization through INT8, it can be significantly Reduce the cost of inference and make the model feasible for privatized deployment
Large model and industrial pre-trained large model
Since OpneAI released ChatGPT, it has brought it to the world A huge shock came. The Large Language Model (LLM) behind it and RLHF (Reinforcement Learning from Human Feedback), a language model optimized based on human feedback using reinforcement learning, have received widespread attention.
WakeData has released 11 AI models in NLP, CV, speech and other fields since its early days, among which the large NLP semantic analysis model has the most abundant application scenarios. For example, in real estate, automobile, brand retail and other industries with low frequency and high customer unit price, SCRM is one of the most effective ways to manage potential customers and existing customers. Through the accumulation of industry corpus and specific pre-training, WakeData enables AI to develop a deep understanding of the industry and can quickly respond to customer questions 24 hours a day during the conversation. It can also automatically extract customer tags based on conversation information to improve the resolution of customer portraits.
In WakeData, AI large model capabilities have covered everything from the construction of underlying customer data assets, to mid-level customer business journeys and business rules, to upper-level multi-touch point marketing links; with the ability to The ability to 'reduce costs, improve efficiency, and empower' the entire digital customer management vertical field. For example, in the field of CDP customer data platform, operators used to need cumbersome rule design to select the appropriate target customer groups. Now, through simple language description and dialogue, AI can assist in finding the corresponding target customer groups, greatly reducing the platform cost. The cost of using and learning is reduced, and the usage efficiency and interactive experience are greatly improved.
In the field of MA marketing automation, WakeData’s products have been connected to WeChat ecosystem, Douyin, Xiaohongshu and other touch points, and support the automated construction of marketing journeys, providing rich The journey template library can achieve "real-time, one-to-one, personalized" user contact. An important part of this is the generation of personalized marketing materials, including text, pictures, mixed graphics and text, etc. AI large models can greatly improve the efficiency and quality of this part while reducing costs.
In the field of Loyalty membership, when the membership system spans different industries and business formats, there will be challenges in unifying membership rules and member assets. WakeData’s AI large model is based on a large amount of industry experience and corpus training The formed Prompt engine can automatically generate mapping logic and combination solutions for different membership rules through simple conversations to describe the characteristics and business demands of members of different business types.
The practice of large models in industries and vertical fields has proven its value.
Three stages of WakeMind’s business path
1) 2018-2021, self-owned model application and commercialization exploration period. Based on WakeData's three basic product lines of Weishu Cloud, Weike Cloud, and Kunlun Platform, the self-developed NLP large model will be comprehensively explored and practiced in vertical fields such as real estate, new retail, automobiles, and digital marketing.
2) 2022-2023, WakeMind release and mothership platform construction period. WakeData collaborates with strategic partners to accelerate the research and development of industry large model WakeMind, and through the mothership platform, WakeMind has the ability to customize industry and vertical fields, has the ability to privatize deployment, and has the access and management capabilities of general large models to achieve Advantageous additions to the scenario that cannot be covered by own models.
3) In 2023 and beyond, the WakeMind model application period will be fully entered. Based on the capabilities of the mothership platform, WakeMind is fully connected to product lines such as Weike Cloud, Weishu Cloud, and Kunlun Platform. Through industry knowledge accumulation, industry scenario optimization, and industry prompt engineering training, WakeMind further improves the industry capabilities of the model and will Launch larger-scale commercial applications in real estate, new retail, automobile and other industries. At the same time, WakeData itself has begun to realize its own productivity revolution based on the capabilities of the WakeMind mothership platform.
How WakeData uses AI to liberate productivity
WakeData's mission is defined as "waking up data" and has been deployed in the field of big data platforms for many years. As a TOB enterprise services company, WakeData sees huge opportunities in "how to use large models" and covers the use of large models in two aspects: on the one hand, it integrates large models into products, and on the other hand, it helps companies internally of designers, programmers, and others use large models for product development and customer project delivery.
There are two basic elements for the access and application of large models, more applicable scenarios and big data AI capabilities. WakeData’s two main products, “Weike Cloud” and “Weishu Cloud” are Access to large models is facilitated. Weike Cloud can more conveniently and seamlessly connect large model tools based on industry digital applications, and customers do not need to worry about the complex configuration and technical optimization behind the application; Weike Cloud can apply optimization prompt projects and vertical models based on industry help scenarios. This is also the product solution advantage that WakeData has always adhered to in platform applications.
At the same time, WakeData divides large model access products into two categories. One is based on product and industry business flow access. The focus of this type of access is to optimize experience and industry knowledge to help Customers can use it quickly, conveniently and effectively; the second type is to deeply optimize vertical scenarios based on product architecture and open source large models. This type of product is more in line with the needs of large customers in terms of risk resistance and data security. At the same time, the model can be continuously updated based on industry understanding. Optimization can maintain the continued competitiveness of such customers in vertical industries.
“Enterprises must integrate big models in digital transformation and digital customer management. Big data and scenarios are two key elements.” Li Kechen, founder and CEO of WakeData, said.
Under normal circumstances, large models require a large amount of data for effective training, so it is crucial to have industrial data platform capabilities. Recently, the Cyberspace Administration of China released the "Measures for the Management of Generative Artificial Intelligence Services (Draft for Comments)", which particularly emphasizes the legal compliance of training and pre-training data sources, as well as the authenticity, accuracy, objectivity and diversity of the data. sex. The value application scenarios of large models are an important factor in the development and commercialization of large models; the so-called scenarios refer to the purpose of the models we train and whether they can create core value for the business under the premise of legal compliance.
Li Kechen believes that scenarios are environments where large models are used, and the basis of big data and AI technology is capabilities; companies with industry scenarios and industry data will be faster, more effective, and more agile when acquiring large model capabilities. .
WakeData’s two core product lines are the accumulation of these two elements; as a new generation data platform, Weishu Cloud has powerful big data Eed-to-End data processing capabilities. As a new generation of digital customer management platform, Keyun includes CDP, MA, SCRM, Loyalty and other suites, and has a large number of business application scenarios. Through the strategy of deep cultivation in vertical industries, Keyun has stronger industry Know-How and more valuable products. value of training sample data. Weishu Cloud will release version 5.0 in 2022. Its data integration, data calculation, data analysis and governance, data visualization, and data assetization capabilities all have industry-leading advantages. These data-side advantages have also become barriers to competition for industrialized artificial intelligence applications in the era of large models.
“A working atmosphere that promotes productivity liberation has been initially formed within WakeData. WakeMind capabilities have been used in areas such as product design, development testing, and marketing operations. The initial application has achieved a human efficiency of 20%. Improvement. While accelerating product research and development, it also improves the efficiency of customer project delivery and saves time and cost for the implementation of customers' digital projects." said Qian Yong, WakeData CTO.
The Kunlun platform consists of three parts: basic cloud, development cloud, and integrated cloud. It is a very important cloud native technology base in the process of WakeData product development, implementation and delivery. Kunlun Platform Development Cloud is empowered by WakeMind. Engineers are already exploring applications such as "based on product documentation, assisting in generating corresponding architecture design and data model design, and then assisting in generating code and detecting the correctness of the code." For example, in the process of promoting domain-driven design, WakeMind can assist in learning DDD and assist engineers in domain modeling; in the process of data modeling, data models can be created, modified, automatically supplemented and improved through natural language interaction, and rapid production can be achieved. SQL statements; during the product development process, by inputting product documents, extract and generate a product glossary, and provide detailed explanations, etc.
For ordinary engineers, they can already make significant improvements in areas such as generating rule code, automatically generating unit tests, code review and optimization, etc. Improved development efficiency.
WakeMind provides a copywriting generation assistant available to everyone.
#The marketing department quickly builds a marketing growth matrix through AI’s Text to Video.
AIGC’s empowerment of industries and vertical fields is an inevitable trend, and it is also the core development path of WakeData since its establishment. WakeData has always maintained an open and embracing attitude towards ChatGPT-like technologies and services, and has actively participated in them. Based on the strategy of focusing on industrialized operations, WakeData has firmly grasped its path to value and commercialization. WakeMind's large industry model of WakeMind will help more companies revolutionize themselves, improve efficiency, and continue to liberate productivity in the AIGC era.
The above is the detailed content of Integrating GPT large model products, WakeData new round of product upgrades. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Product positioning of TensorRT-LLM TensorRT-LLM is a scalable inference solution developed by NVIDIA for large language models (LLM). It builds, compiles and executes calculation graphs based on the TensorRT deep learning compilation framework, and draws on the efficient Kernels implementation in FastTransformer. In addition, it utilizes NCCL for communication between devices. Developers can customize operators to meet specific needs based on technology development and demand differences, such as developing customized GEMM based on cutlass. TensorRT-LLM is NVIDIA's official inference solution, committed to providing high performance and continuously improving its practicality. TensorRT-LL
 Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
According to news on April 4, the Cyberspace Administration of China recently released a list of registered large models, and China Mobile’s “Jiutian Natural Language Interaction Large Model” was included in it, marking that China Mobile’s Jiutian AI large model can officially provide generative artificial intelligence services to the outside world. . China Mobile stated that this is the first large-scale model developed by a central enterprise to have passed both the national "Generative Artificial Intelligence Service Registration" and the "Domestic Deep Synthetic Service Algorithm Registration" dual registrations. According to reports, Jiutian’s natural language interaction large model has the characteristics of enhanced industry capabilities, security and credibility, and supports full-stack localization. It has formed various parameter versions such as 9 billion, 13.9 billion, 57 billion, and 100 billion, and can be flexibly deployed in Cloud, edge and end are different situations
 New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
If the test questions are too simple, both top students and poor students can get 90 points, and the gap cannot be widened... With the release of stronger models such as Claude3, Llama3 and even GPT-5 later, the industry is in urgent need of a more difficult and differentiated model Benchmarks. LMSYS, the organization behind the large model arena, launched the next generation benchmark, Arena-Hard, which attracted widespread attention. There is also the latest reference for the strength of the two fine-tuned versions of Llama3 instructions. Compared with MTBench, which had similar scores before, the Arena-Hard discrimination increased from 22.6% to 87.4%, which is stronger and weaker at a glance. Arena-Hard is built using real-time human data from the arena and has a consistency rate of 89.1% with human preferences.
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
According to news on June 13, according to Byte's "Volcano Engine" public account, Xiaomi's artificial intelligence assistant "Xiao Ai" has reached a cooperation with Volcano Engine. The two parties will achieve a more intelligent AI interactive experience based on the beanbao large model. It is reported that the large-scale beanbao model created by ByteDance can efficiently process up to 120 billion text tokens and generate 30 million pieces of content every day. Xiaomi used the beanbao large model to improve the learning and reasoning capabilities of its own model and create a new "Xiao Ai Classmate", which not only more accurately grasps user needs, but also provides faster response speed and more comprehensive content services. For example, when a user asks about a complex scientific concept, &ldq
 Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
"High complexity, high fragmentation, and cross-domain" have always been the primary pain points on the road to digital and intelligent upgrading of the transportation industry. Recently, the "Qinling·Qinchuan Traffic Model" with a parameter scale of 100 billion, jointly built by China Vision, Xi'an Yanta District Government, and Xi'an Future Artificial Intelligence Computing Center, is oriented to the field of smart transportation and provides services to Xi'an and its surrounding areas. The region will create a fulcrum for smart transportation innovation. The "Qinling·Qinchuan Traffic Model" combines Xi'an's massive local traffic ecological data in open scenarios, the original advanced algorithm self-developed by China Science Vision, and the powerful computing power of Shengteng AI of Xi'an Future Artificial Intelligence Computing Center to provide road network monitoring, Smart transportation scenarios such as emergency command, maintenance management, and public travel bring about digital and intelligent changes. Traffic management has different characteristics in different cities, and the traffic on different roads
