

Brain hierarchical prediction makes large models more efficient!

With 100 billion neurons, each neuron has about 8,000 synapses, the complex structure of the brain inspires artificial intelligence research.
#Currently, the architecture of most deep learning models is an artificial neural network inspired by the neurons of the biological brain.
## Generative AI explodes, you can see the deep learning algorithm generating , the ability to summarize, translate and classify text is increasingly powerful.
#However, these language models still cannot match human language capabilities.
Predictive coding theory provides a preliminary explanation for this difference:
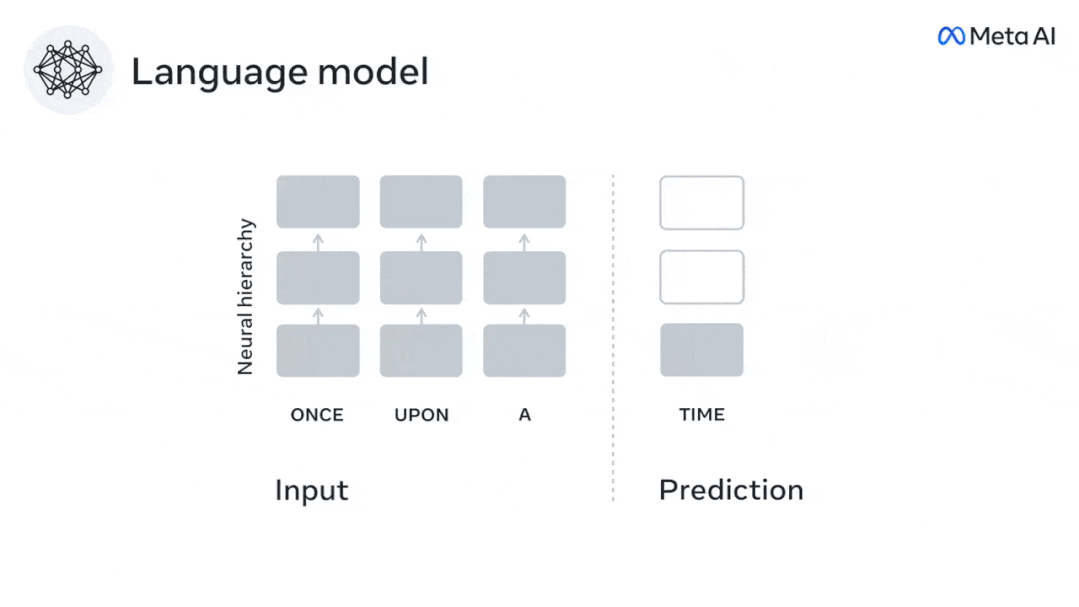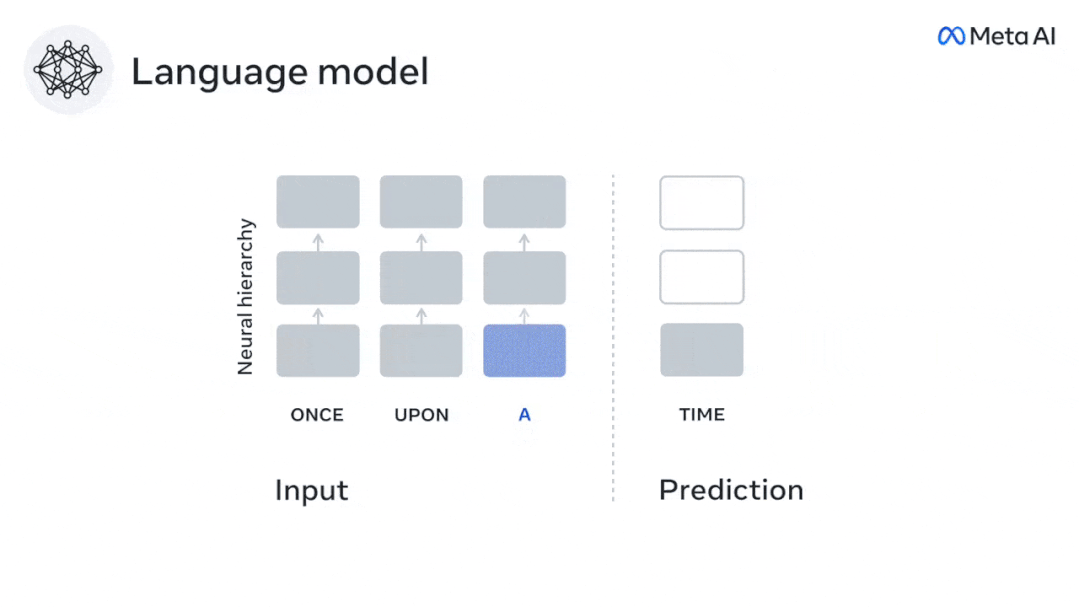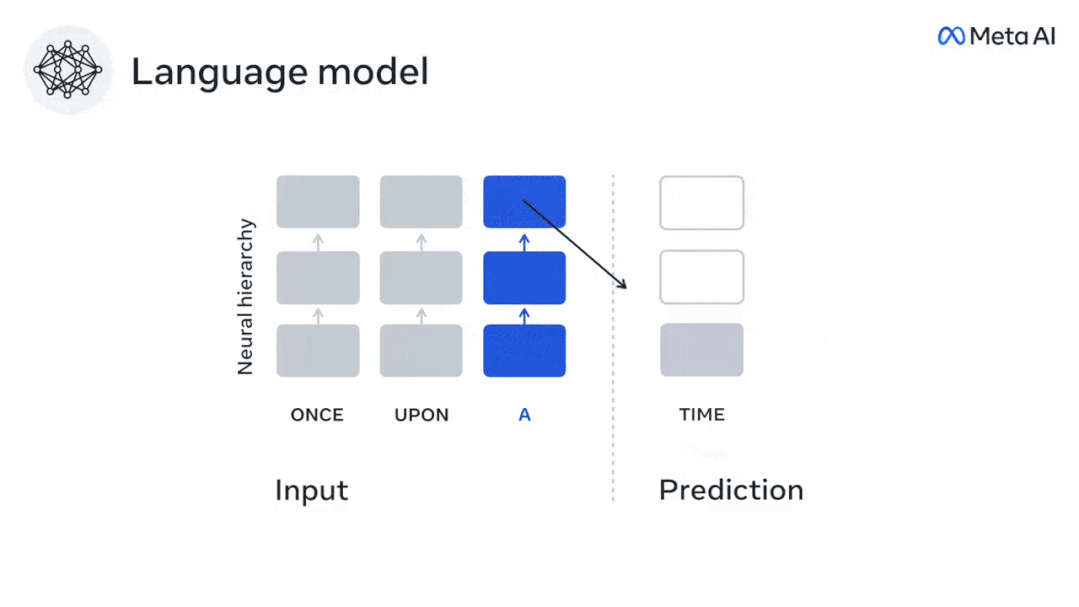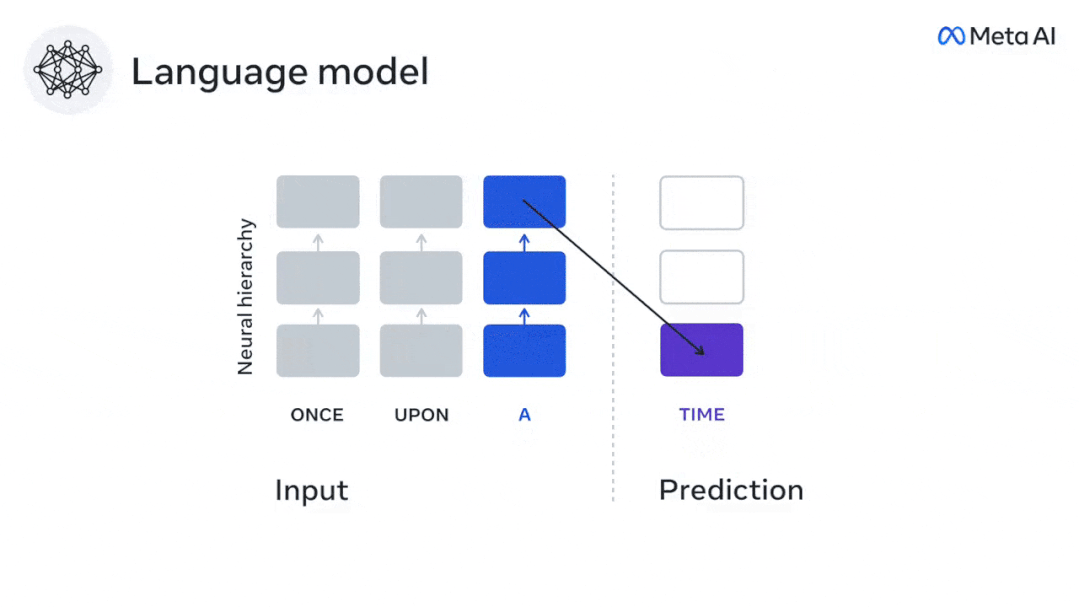
While language models can predict nearby words, the human brain constantly predicts layers of representation across multiple time scales.
To test this hypothesis, scientists at Meta AI analyzed the brain fMRI signals of 304 people who listened to the short story.
#It is concluded that hierarchical predictive coding plays a crucial role in language processing.
#Meanwhile, research illustrates how synergies between neuroscience and artificial intelligence can reveal the computational basis of human cognition.
#The latest research has been published in the Nature sub-journal Nature Human Behavior.

##Paper address: https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f
It is worth mentioning that GPT-2 was used during the experiment. Maybe this research can inspire OpenAI’s unopened models in the future.
Wouldn’t ChatGPT be even stronger by then? Brain Predictive Coding Hierarchy
In less than 3 years, deep learning has made significant progress in text generation and translation. Thanks to a well-trained algorithm: predict words based on nearby context.
#Notably, activation from these models has been shown to map linearly to brain responses to speech and text.
# Furthermore, this mapping depends primarily on the algorithm's ability to predict future words, thus suggesting that this goal is sufficient for them to converge to brain-like computations.
#However, a gap still exists between these algorithms and the brain: despite large amounts of training data, current language models fail at generating long stories, summarizing, and Challenges with coherent conversation and information retrieval.
#Because the algorithm cannot capture some syntactic structures and semantic properties, and the understanding of the language is also very superficial.
#For example, the algorithm tends to incorrectly assign verbs to subjects in nested phrases.
「the keys that the man holds ARE here」
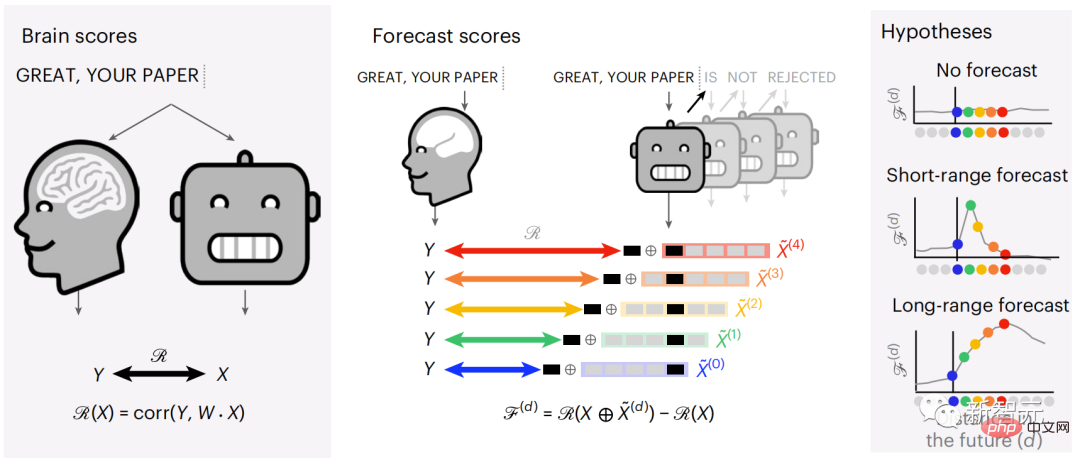
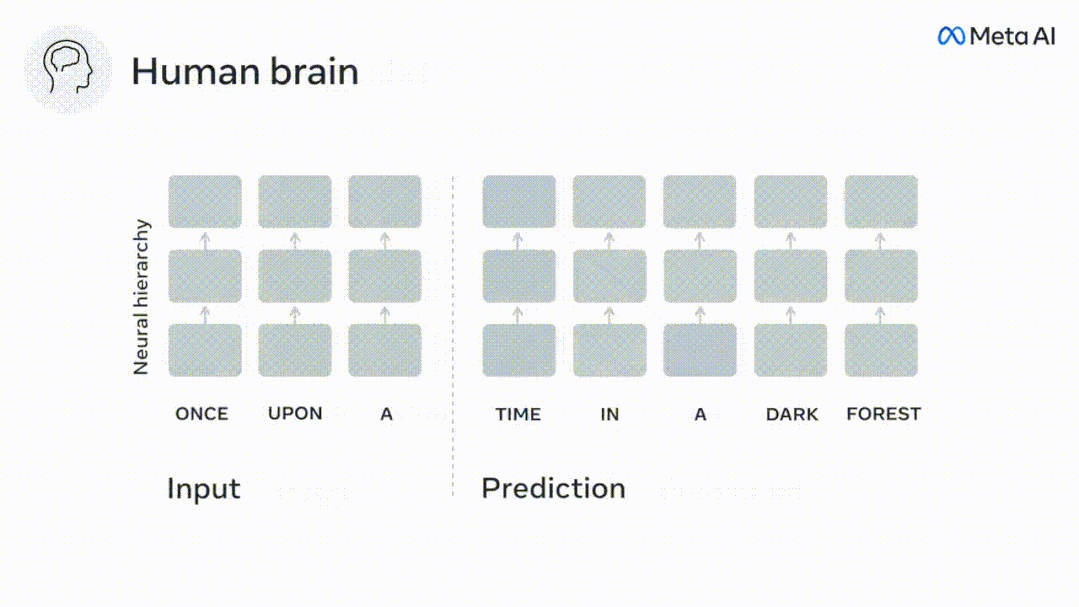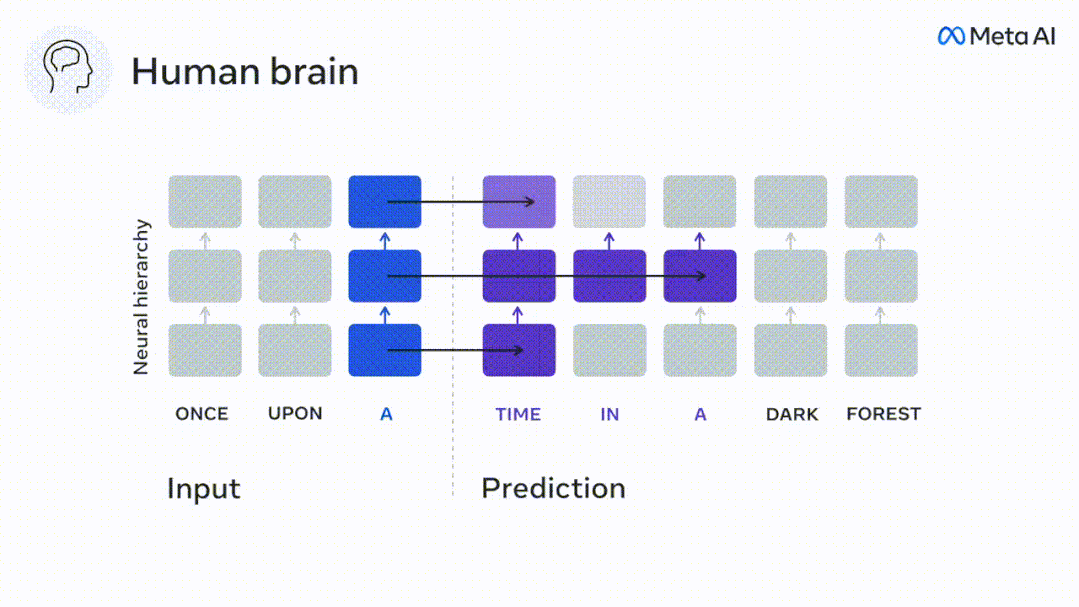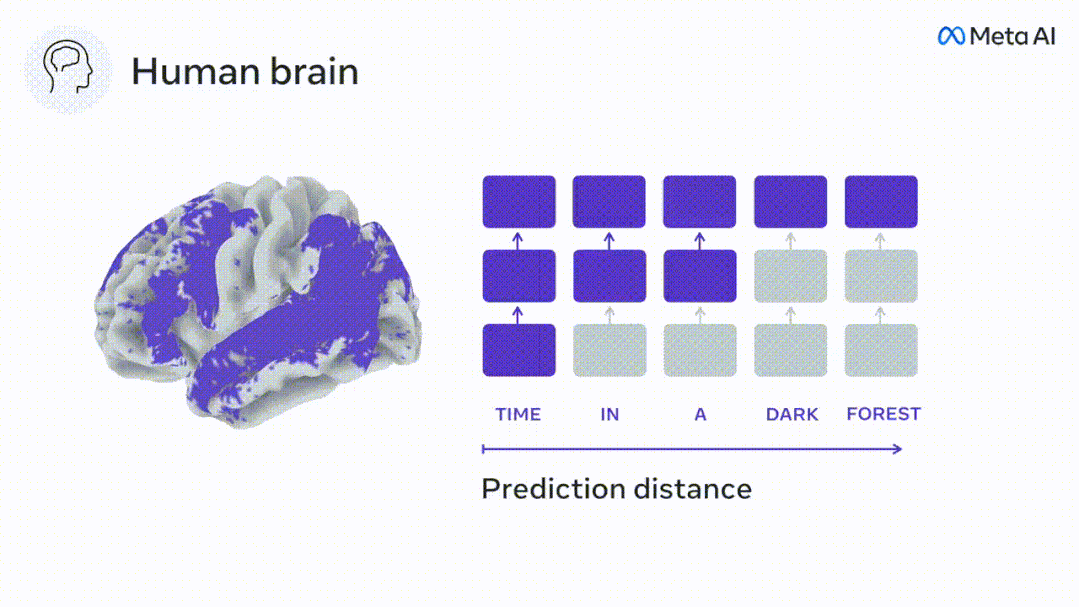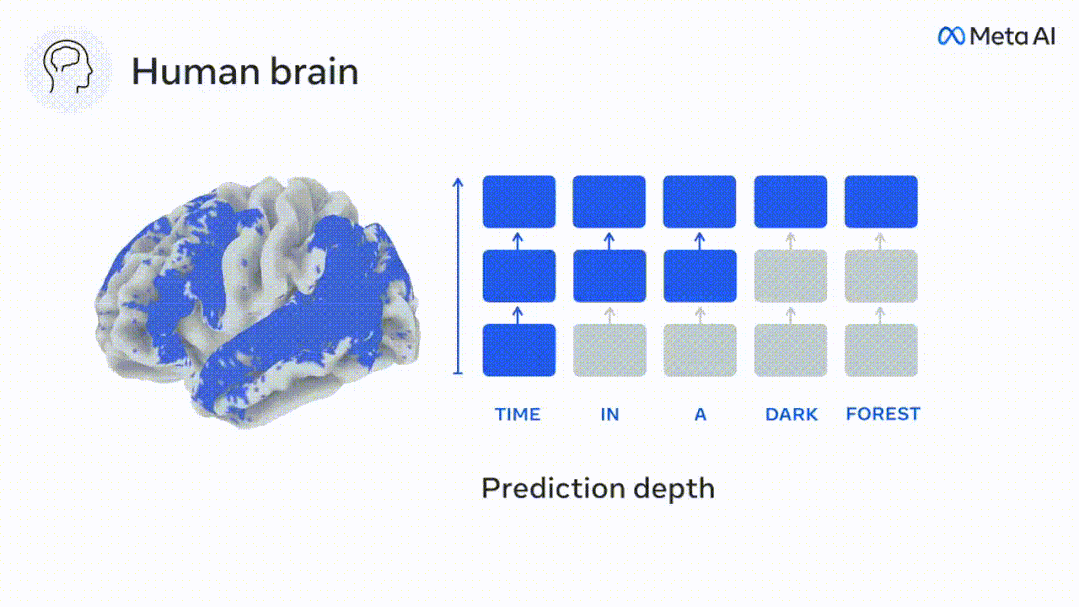
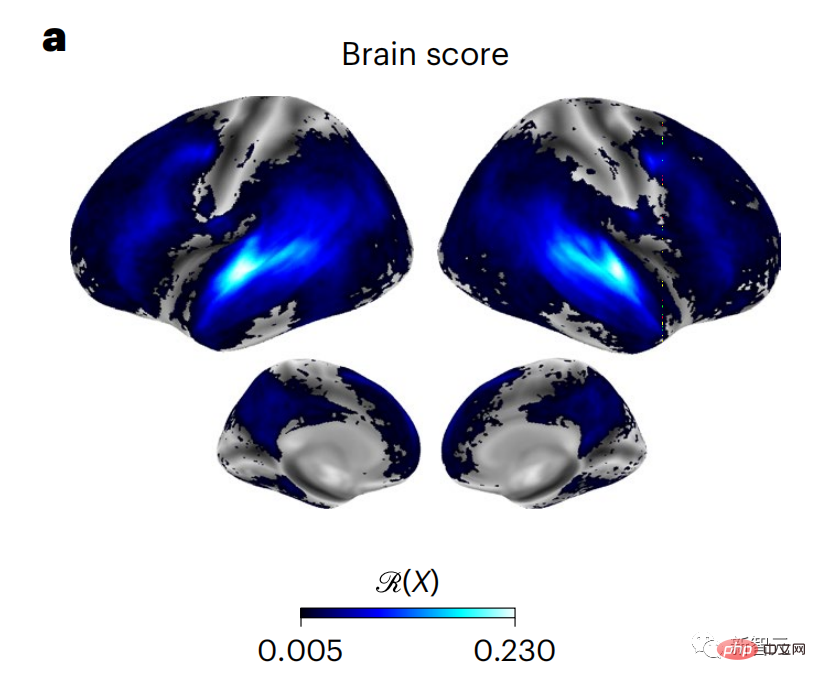
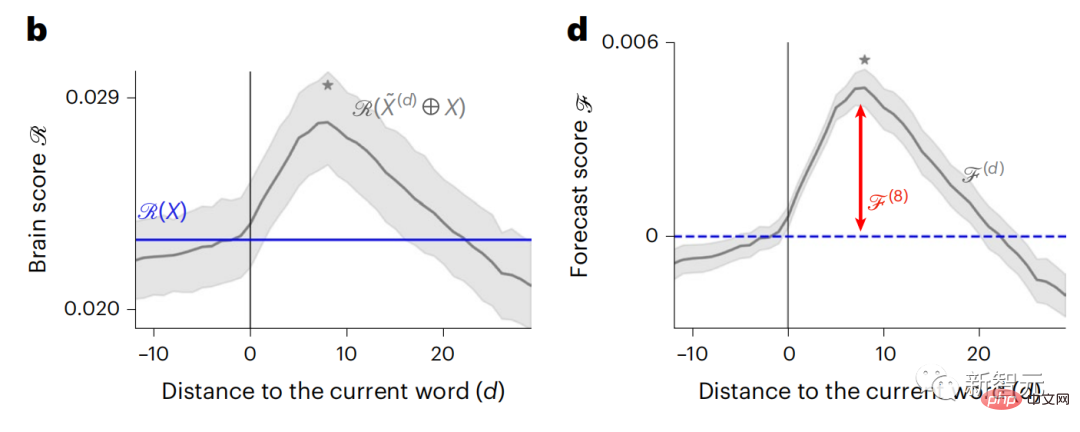
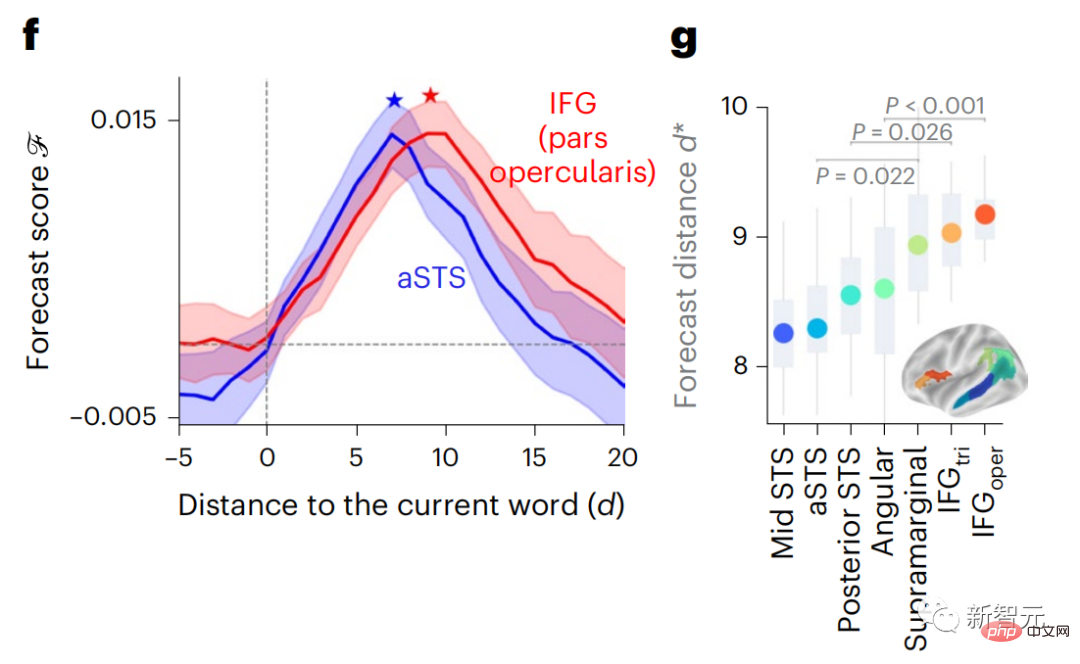
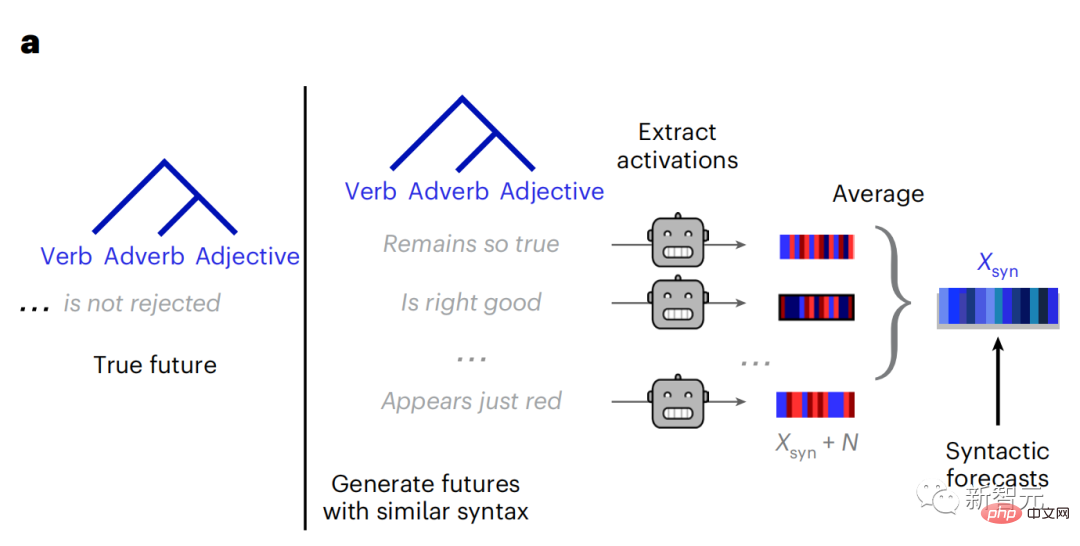
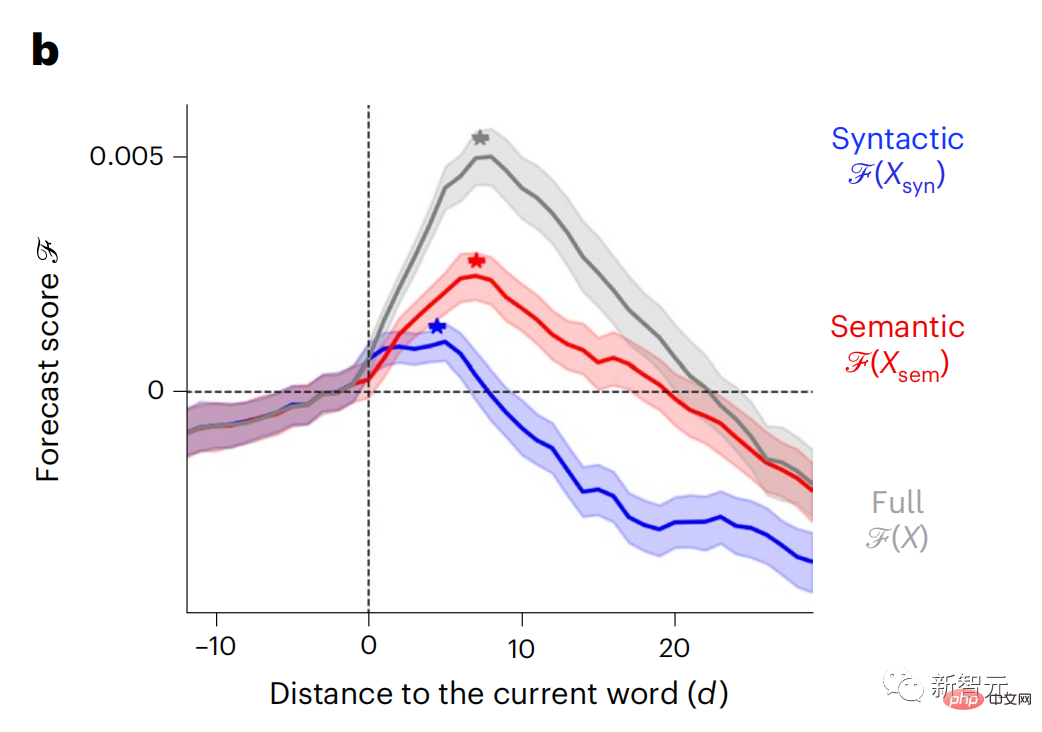
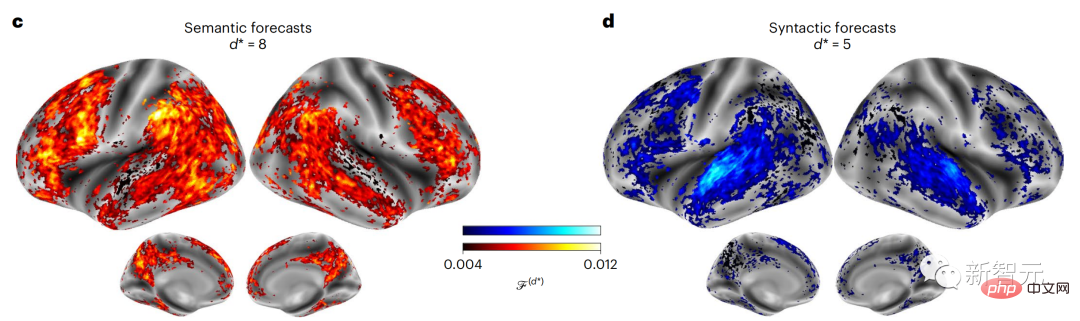
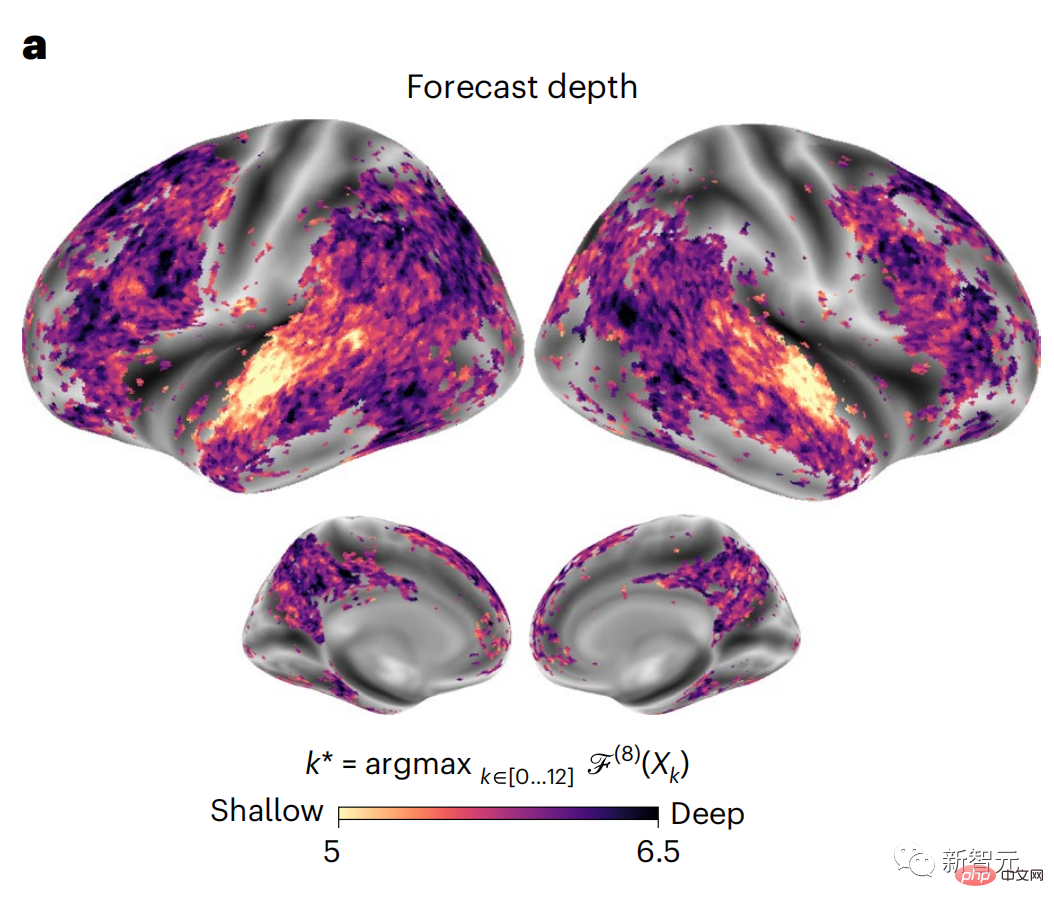
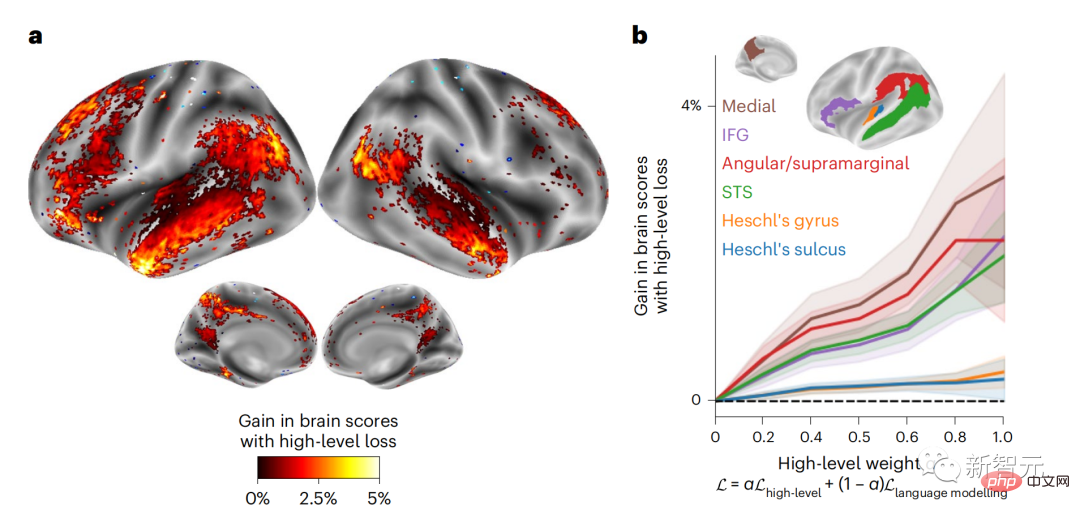
Similarly, when the text When generating predictions optimized only for the next word, deep language models can generate bland, incoherent sequences, or get stuck in loops that repeat endlessly. Currently, predictive coding theory provides a potential explanation for this flaw: Although deep language models are mainly used to Predicting the next word, but this framework shows that the human brain can predict at multiple time scales and cortical levels of representation. Previous research has demonstrated that speech prediction in the brain, that is, a word or phoneme, correlates well with functional magnetic resonance imaging ( fMRI), electroencephalography, magnetoencephalography and electrocorticography were correlated. #A model trained to predict the next word or phoneme can have its output reduced to a single number, the probability of the next symbol. # However, the nature and time scale of predictive representations are largely unknown. #In this study, the researchers extracted fMRI signals from 304 people and had each person listen to them for about 26 minutes short story (Y), and input the same content to activate the language algorithm (X). Then, the similarity between X and Y is quantified by the "brain score", that is, the Pearson correlation coefficient (R) after the best linear mapping W . #To test whether adding representations of predicted words improves this correlation, change the activation of the network (black rectangle X ) is connected to the prediction window (colored rectangle ~X), and then uses PCA to reduce the dimension of the prediction window to the dimension of X. Finally F quantifies the brain score gain obtained by enhancing the activation of this prediction window by the language algorithm. We repeat this analysis (d) with different distance windows. #It was found that this brain mapping could be improved by augmenting these algorithms with predictions that span multiple time scales, namely long-range predictions and hierarchical predictions. #Finally, the experimental results found that these predictions are hierarchically organized: the frontal cortex predicts higher levels, greater scope, and more predictions than the temporal cortex. Contextual representation. Deep language model maps to brain activity Researchers quantitatively studied the similarity between deep language models and the brain when the input content is the same. Using the Narratives dataset, the fMRI (functional magnetic resonance imaging) of 304 people who listened to short stories was analyzed. Perform independent linear ridge regression on the results for each voxel and each experimental individual to predict the fMRI signal resulting from activation of several deep language models . Using the held-out data, the corresponding "brain score" was calculated, that is, the correlation between the fMRI signal and the ridge regression prediction result obtained by inputting the specified language model stimulus sex. For clarity, first focus on the activations of the eighth layer of GPT-2, a 12-layer causal deep neural network powered by HuggingFace2 that is the most predictive Brain activity. Consistent with previous studies, GPT-2 activation accurately mapped to a distributed set of bilateral brain regions, with brain scores peaking in the auditory cortex and anterior and superior temporal regions. The Meta team then tested Does increasing stimulation of language models with long-range prediction capabilities lead to higher brain scores. #For each word, the researchers connected the model activation for the current word to a "prediction window" consisting of future words. The representation parameters of the prediction window include d, which represents the distance between the current word and the last future word in the window, and w, which represents the number of concatenated words. For each d, compare the brain scores with and without the predictive representation and calculate the “prediction score”. The results show that the prediction score is the highest when d=8, and the peak value appears in the brain area related to language processing. d=8 corresponds to 3.15 seconds of audio, which is the time of two consecutive fMRI scans. Prediction scores were distributed bilaterally in the brain, except in the inferior frontal and supramarginal gyri. Through supplementary analysis, the team also obtained the following results: (1) Each future word with a distance of 0 to 10 from the current word has a significant contribution to the prediction result. ; (2) Predictive representations are best captured with a window size of around 8 words; (3) Random predictive representations cannot improve brain scores; (4) Compared to real future words, GPT-2 generated words can achieve similar results results, but with lower scores. The predicted time frame changes along the layers of the brain Anatomy & Functional studies have shown that the cerebral cortex is hierarchical. Are the prediction time windows the same for different levels of cortex? #The researchers estimated the peak prediction score of each voxel and expressed its corresponding distance as d. The results showed that the d corresponding to the predicted peak in the prefrontal area was larger than that in the temporal lobe area on average (Figure 2e), and the d of the inferior temporal gyrus It is larger than the superior temporal sulcus. The variation of the best prediction distance along the temporal-parietal-frontal axis is basically symmetrical in both hemispheres of the brain . For each word and its preceding context, ten possible future words that match the syntax of a true future word. For each possible future word, the corresponding GPT-2 activation is extracted and averaged. This approach is able to decompose a given language model activation into syntactic and semantic components, thereby calculating their respective prediction scores. The results show that semantic prediction is long-range (d = 8), involving a distributed network, in front Peaks were reached in the lobe and parietal lobes, while syntactic prediction was shorter in scope (d = 5) and concentrated in superior temporal and left frontal regions. These results reveal multiple levels of prediction in the brain, in which the superior temporal cortex mainly predicts short-term, superficial and syntactic representations, while the inferior frontal and parietal regions mainly predict long-term, contextual, high-level and syntactic representations. Semantic representation. The predicted background becomes more complex along the brain hierarchy Still as before The method calculates the prediction score, but changes the use of GPT-2 layers to determine k for each voxel, the depth at which the prediction score is maximized. # Our results show that the optimal prediction depth varies along the expected cortical hierarchy, with the best model predicting deeper in associative cortex than in lower-level language areas . Differences between regions, although small on average, are very noticeable in different individuals. In general, long-term predictions in the frontal cortex have a more complex background than short-term predictions in lower-level brain areas. The level is higher. Adjust GPT-2 to a predictive encoding structure Adjust the current word and future words of GPT-2 The representations can be concatenated to obtain a better model of brain activity, especially in the frontal area. Can fine-tuning GPT-2 to predict representations at greater distances, with richer backgrounds, and higher levels of hierarchy improve brain mapping of these regions? In the adjustment, not only language modeling is used, but also high-level and long-distance targets are used. The high-level targets here are pre-trained GPT -Layer 8 of the 2 model. The results showed that fine-tuning GPT-2 with high-level and long-range modeling pairs best improved frontal lobe responses, while auditory area and lower-level of brain regions did not significantly benefit from such high-level targeting, further reflecting the role of frontal regions in predicting long-range, contextual, and high-level representations of language. Reference: https:/ /www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f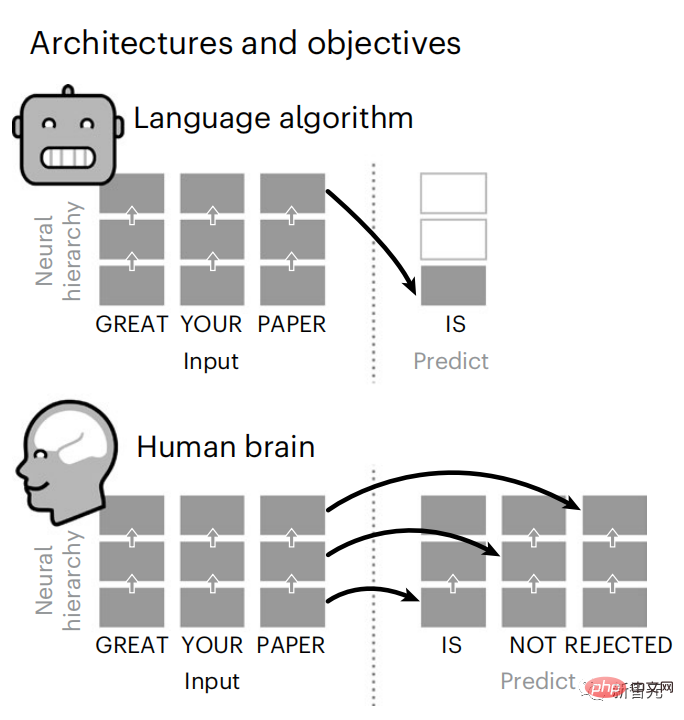
Experimental results
The above is the detailed content of Brain hierarchical prediction makes large models more efficient!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Quantile regression for time series probabilistic forecasting
May 07, 2024 pm 05:04 PM
Do not change the meaning of the original content, fine-tune the content, rewrite the content, and do not continue. "Quantile regression meets this need, providing prediction intervals with quantified chances. It is a statistical technique used to model the relationship between a predictor variable and a response variable, especially when the conditional distribution of the response variable is of interest When. Unlike traditional regression methods, quantile regression focuses on estimating the conditional magnitude of the response variable rather than the conditional mean. "Figure (A): Quantile regression Quantile regression is an estimate. A modeling method for the linear relationship between a set of regressors X and the quantiles of the explained variables Y. The existing regression model is actually a method to study the relationship between the explained variable and the explanatory variable. They focus on the relationship between explanatory variables and explained variables
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 How to use MySQL database for forecasting and predictive analytics?
Jul 12, 2023 pm 08:43 PM
How to use MySQL database for forecasting and predictive analytics?
Jul 12, 2023 pm 08:43 PM
How to use MySQL database for forecasting and predictive analytics? Overview: Forecasting and predictive analytics play an important role in data analysis. MySQL, a widely used relational database management system, can also be used for prediction and predictive analysis tasks. This article will introduce how to use MySQL for prediction and predictive analysis, and provide relevant code examples. Data preparation: First, we need to prepare relevant data. Suppose we want to do sales forecasting, we need a table with sales data. In MySQL we can use
 What is the difference between AI inference and training? do you know?
Mar 26, 2024 pm 02:40 PM
What is the difference between AI inference and training? do you know?
Mar 26, 2024 pm 02:40 PM
If I want to sum up the difference between AI training and reasoning in one sentence, I think "one minute on stage, ten years off stage" is the most appropriate. Xiao Ming has been dating his long-cherished goddess for many years and has quite a lot of experience in the techniques and tips for asking her out, but he is still confused about the mystery. Can accurate predictions be achieved with the help of AI technology? Xiao Ming thought over and over again and summarized the variables that may affect whether the goddess accepts the invitation: whether it is a holiday, the weather is bad, too hot/cold, in a bad mood, sick, he has another appointment, relatives are coming to the house... ..etc. The picture weights and sums these variables. If it is greater than a certain threshold, the goddess must accept the invitation. So, how much weight do these variables have, and what are the thresholds? This is a very complex question and difficult to pass
 Learning cross-modal occupancy knowledge: RadOcc using rendering-assisted distillation technology
Jan 25, 2024 am 11:36 AM
Learning cross-modal occupancy knowledge: RadOcc using rendering-assisted distillation technology
Jan 25, 2024 am 11:36 AM
Original title: Radocc: LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation Paper link: https://arxiv.org/pdf/2312.11829.pdf Author unit: FNii, CUHK-ShenzhenSSE, CUHK-Shenzhen Huawei Noah's Ark Laboratory Conference: AAAI2024 Paper Idea: 3D Occupancy Prediction is an emerging task that aims to estimate the occupancy state and semantics of 3D scenes using multi-view images. However, due to the lack of geometric priors, image-based scenarios
 Microsoft 365 enables Python in Excel
Sep 22, 2023 pm 10:53 PM
Microsoft 365 enables Python in Excel
Sep 22, 2023 pm 10:53 PM
1. Enabling Python in Excel Python in Excel is currently in the testing phase. If you want to use this feature, please make sure it is the Windows version of Microsoft 365, join the Microsoft 365 preview program, and select the Beta channel. Click [File] > [Account] in the upper left corner of the Excel page. You can find the following information on the left side of the page: After completing the above steps, open a blank workbook: click the [Formula] tab, select [Insert Python] - [Python in Excel]. Click [Trial Preview Version] in the pop-up dialog box. Next, we can start to experience the wonderful uses of Python! 2,
 Musk is optimistic and OpenAI is entering. Is Tesla's long-term value a robot?
May 27, 2023 pm 02:51 PM
Musk is optimistic and OpenAI is entering. Is Tesla's long-term value a robot?
May 27, 2023 pm 02:51 PM
Technology geek Musk and his Tesla have always been at the forefront of global technological innovation. Recently, at Tesla's 2023 shareholder meeting, Musk once again disclosed more ambitious plans for future development, including cars, energy storage, and humanoid robots. Musk seems very optimistic about humanoid robots and believes that Tesla's long-term value in the future may lie in robots. It is worth mentioning that OpenAI, the parent company of ChatGPT, has also invested in a Norwegian robotics company with the intention of building the first commercial robot EVE. The competition between Optimus and EVE has also triggered a craze for the concept of humanoid robots in the domestic secondary market. Driven by the concept, which links in the humanoid robot industry chain will benefit? What are the investment targets? Laying out automobiles, energy storage, and humanoid robots as global technologies
 How to implement a simple student test score prediction system using Java?
Nov 04, 2023 am 08:44 AM
How to implement a simple student test score prediction system using Java?
Nov 04, 2023 am 08:44 AM
How to implement a simple student test score prediction system using Java? With the development of education, students' test scores have always been regarded as one of the important indicators to measure students' learning outcomes. However, for students, knowing their own test score predictions is a very useful tool in allowing them to understand how they will perform on subsequent tests and develop study strategies accordingly. This article will introduce how to use Java to implement a simple student test score prediction system. First, we need to collect students' historical test score data. us
