

How to use Java crawler to crawl images in batches

Crawling ideas
The acquisition of this kind of image is essentially the download of the file (HttpClient). But because it is not just about getting a picture, there is also a page parsing process (Jsoup).
Jsoup: Parse the html page and get the link to the image.
HttpClient: Request the link of the image and save the image locally.
Specific steps
First enter the homepage analysis, there are mainly the following categories (not all categories here, but these are enough, this is just a learning technique.), Our goal is to obtain pictures under each category.
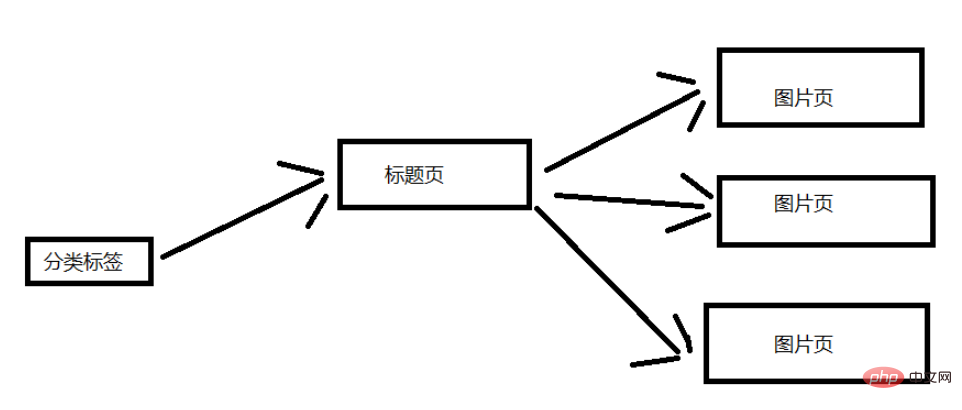
Let’s analyze the structure of the website. I’ll keep it simple here. The picture below shows the general structure. Here, a classification label is selected for explanation. A category tag page contains multiple title pages, and each title page contains multiple image pages. (Dozens of pictures corresponding to the title page)
Specific code
Import the project dependent jar package coordinates or directly download the corresponding jar package, Importing projects is also possible.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>Entity class Picture and tool class HeaderUtil
Entity class: Encapsulate the properties into an object, which makes it easier to call.
package com.picture;
public class Picture {
private String title;
private String url;
public Picture(String title, String url) {
this.title = title;
this.url = url;
}
public String getTitle() {
return this.title;
}
public String getUrl() {
return this.url;
}
}Tool Category: Constantly changing UA (I don’t know if it is useful, but I use my own IP, so it is probably of little use)
package com.picture;
public class HeaderUtil {
public static String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
}Download Category
Multi-threading is really too fast. In addition, I only have one IP and no proxy IP can be used (I don’t know much about it). It is very fast to use multi-threading to block the IP.
package com.picture;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private String referer;
private CloseableHttpClient httpClient;
private Picture picture;
private String filePath;
public SinglePictureDownloader(Picture picture, String referer, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.picture = picture;
this.referer = referer;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(picture.getUrl());
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", HeaderUtil.headers[rand.nextInt(HeaderUtil.headers.length)]);
get.setHeader("referer", referer);
System.out.println(referer);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, picture.getTitle());
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}This is a tool class for obtaining HttpClient connections to avoid the performance consumption of frequently creating connections. (But because I am using a single thread to crawl here, it is not very useful. I can just use one HttpClient connection to crawl. This is because I used multiple threads to crawl at the beginning. But after basically getting a few pictures, it was banned, so it was changed to a single-threaded crawler. So the connection pool stayed.)
package com.m3u8;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}The most important class: parsing page class PictureSpider
package com.picture;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.m3u8.HttpClientUtil;
/**
* 首先从顶部分类标题开始,依次爬取每一个标题(小分页),每一个标题(大分页。)
* */
public class PictureSpider {
private CloseableHttpClient httpClient;
private String referer;
private String rootPath;
private String filePath;
public PictureSpider() {
httpClient = HttpClientUtil.getHttpClient();
}
/**
* 开始爬虫爬取!
*
* 从爬虫队列的第一条开始,依次爬取每一条url。
*
* 分页爬取:爬10页
* 每个url属于一个分类,每个分类一个文件夹
* */
public void start(List<String> urlList) {
urlList.stream().forEach(url->{
this.referer = url;
String dirName = url.substring(22, url.length()-1); //根据标题名字去创建目录
//创建分类目录
File path = new File("D:/DragonFile/DBC/mzt/", dirName); //硬编码路径,需要用户自己指定一个
if (!path.exists()) {
path.mkdir();
rootPath = path.toString();
}
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}
});
}
/**
* 标题分页获取链接
* */
public void page(String url) {
System.out.println("url:" + url);
String html = this.getHtml(url); //获取页面数据
Map<String, String> picMap = this.extractTitleUrl(html); //抽取图片的url
if (picMap == null) {
return ;
}
//获取标题对应的图片页面数据
this.getPictureHtml(picMap);
}
private String getHtml(String url) {
String html = null;
HttpGet get = new HttpGet(url);
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
get.setHeader("referer", url);
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTf-8"); //关闭实体?
}
}
else {
System.out.println(statusCode);
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
private Map<String, String> extractTitleUrl(String html) {
if (html == null) {
return null;
}
Document doc = Jsoup.parse(html, "UTF-8");
Elements pictures = doc.select("ul#pins > li");
//不知为何,无法直接获取 a[0],我不太懂这方面的知识。
//那我就多处理一步,这里先放下。
Elements pictureA = pictures.stream()
.map(pic->pic.getElementsByTag("a").first())
.collect(Collectors.toCollection(Elements::new));
return pictureA.stream().collect(Collectors.toMap(
pic->pic.getElementsByTag("img").first().attr("alt"),
pic->pic.attr("href")));
}
/**
* 进入每一个标题的链接,再次分页获取图片的链接
* */
private void getPictureHtml(Map<String, String> picMap) {
//进入标题页,在标题页中再次分页下载。
picMap.forEach((title, url)->{
//分页下载一个系列的图片,每个系列一个文件夹。
File dir = new File(rootPath, title.trim());
if (!dir.exists()) {
dir.mkdir();
filePath = dir.toString(); //这个 filePath 是每一个系列图片的文件夹
}
for (int i = 1; i <= 60; i++) {
String html = this.getHtml(url + "/" + i);
if (html == null) {
//每个系列的图片一般没有那么多,
//如果返回的页面数据为 null,那就退出这个系列的下载。
return ;
}
Picture picture = this.extractPictureUrl(html);
System.out.println("开始下载");
//多线程实在是太快了(快并不是好事,我改成单线程爬取吧)
SinglePictureDownloader downloader = new SinglePictureDownloader(picture, referer, filePath);
downloader.download();
try {
Thread.sleep(1500); //不要爬的太快了,这里只是学习爬虫的知识。不要扰乱别人的正常服务。
System.out.println("爬取完一张图片,休息1.5秒。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 获取每一页图片的标题和链接
* */
private Picture extractPictureUrl(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
//获取标题作为文件名
String title = doc.getElementsByTag("h3")
.first()
.text();
//获取图片的链接(img 标签的 src 属性)
String url = doc.getElementsByAttributeValue("class", "main-image")
.first()
.getElementsByTag("img")
.attr("src");
//获取图片的文件扩展名
title = title + url.substring(url.lastIndexOf("."));
return new Picture(title, url);
}
}BootStrap
There is a crawler queue here, but I didn’t even finish crawling the first one. This is because I made a miscalculation and missed the calculation by two orders of magnitude. However, the functionality of the program is correct.
package com.picture;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 爬虫启动类
* */
public class BootStrap {
public static void main(String[] args) {
//反爬措施:UA、refer 简单绕过就行了。
//refer https://www.mzitu.com
//使用数组做一个爬虫队列
String[] urls = new String[] {
"https://www.mzitu.com/xinggan/",
"https://www.mzitu.com/zipai/"
};
// 添加初始队列,启动爬虫
List<String> urlList = new ArrayList<>(Arrays.asList(urls));
PictureSpider spider = new PictureSpider();
spider.start(urlList);
}
}Crawling results

Notes
There is a calculation error here , the code is as follows:
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}The value of i is too large because I made a mistake in calculation. If downloaded according to this situation, a total of 4 * 10 * (30-5) * 60 = 64800 pictures will be downloaded. (Each page contains 30 title pages, and about 5 are advertisements.) I thought at first there were only a few hundred pictures! This is an estimate, but the actual download volume will not be much different from this (there is no order of magnitude difference). So I downloaded for a while and found that only the pictures in the first queue were downloaded. Of course, as a crawler learning program, it is still very qualified.
This program is just for learning. I set the download interval of each picture to 1.5 seconds, and it is a single-threaded program, so the speed will be very slow. But that doesn't matter, as long as the program functions correctly, no one will really wait until the image is downloaded.
It is estimated to take a long time: 64800*1.5s = 97200s = 27h. This is only a rough estimate. It does not take into account other running times of the program, but other times can be basically ignored. .
The above is the detailed content of How to use Java crawler to crawl images in batches. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Square Root in Java
Aug 30, 2024 pm 04:26 PM
Square Root in Java
Aug 30, 2024 pm 04:26 PM
Guide to Square Root in Java. Here we discuss how Square Root works in Java with example and its code implementation respectively.
 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Random Number Generator in Java
Aug 30, 2024 pm 04:27 PM
Random Number Generator in Java
Aug 30, 2024 pm 04:27 PM
Guide to Random Number Generator in Java. Here we discuss Functions in Java with examples and two different Generators with ther examples.
 Armstrong Number in Java
Aug 30, 2024 pm 04:26 PM
Armstrong Number in Java
Aug 30, 2024 pm 04:26 PM
Guide to the Armstrong Number in Java. Here we discuss an introduction to Armstrong's number in java along with some of the code.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
