

I really like what some netizens said:
"This kid is really not good, let's get another one."
Google really did this.
After seven years of development, TensorFlow was finally defeated by Meta's PyTorch, to a certain extent.
Seeing something was wrong, Google quickly asked for another one - "JAX", a brand new machine learning framework.

As you all know about the recently super popular DALL·E Mini, its model is programmed based on JAX, thus making full use of the advantages brought by Google TPU.
In 2015, TensorFlow, the machine learning framework developed by Google, came out.
At that time, TensorFlow was just a small project of Google Brain.
No one expected that TensorFlow would become very popular as soon as it came out.
Big companies like Uber and Airbnb are using it, as are national agencies like NASA. And they are all used on their most complex projects.
As of November 2020, TensorFlow has been downloaded 160 million times.
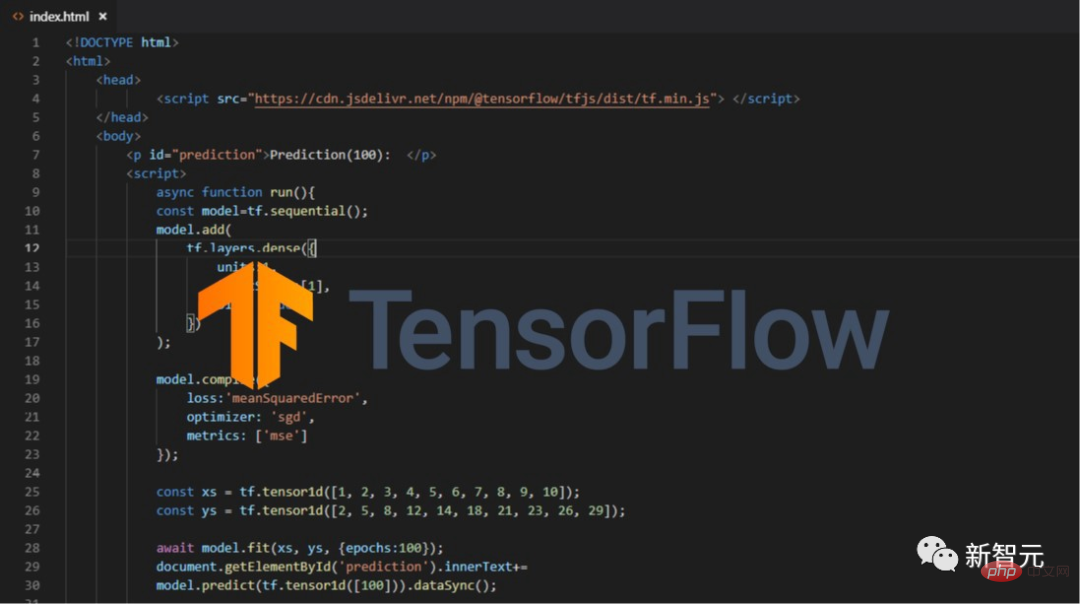
#However, Google does not seem to care much about the feelings of so many users.
The strange interface and frequent updates make TensorFlow increasingly unfriendly to users and increasingly difficult to operate.
Even within Google, they feel that this framework is going downhill.
In fact, it is really helpless for Google to update so frequently. After all, this is the only way to keep up with the rapid iteration in the field of machine learning.
As a result, more and more people joined the project, causing the entire team to slowly lose focus.
The shining points that originally made TensorFlow the tool of choice have been buried in so many factors and are no longer taken seriously.
This phenomenon is described by Insider as a "cat-and-mouse game." The company is like a cat, and the new needs that emerge through constant iteration are like mice. Cats should always be alert and ready to pounce on mice.

#This dilemma is unavoidable for companies that are the first to enter a certain market.
For example, as far as search engines are concerned, Google is not the first. Therefore, Google can learn from the failures of its predecessors (AltaVista, Yahoo, etc.) and apply it to its own development.
Unfortunately, when it comes to TensorFlow, Google is the one who is trapped.
It is precisely because of the above reasons that developers who originally worked for Google gradually lost confidence in their old employer.
The ubiquitous TensorFlow in the past has gradually declined, losing to Meta’s rising star-PyTorch.

In 2017, the beta version of PyTorch was open sourced.
In 2018, Facebook’s Artificial Intelligence Research Laboratory released a full version of PyTorch.
It is worth mentioning that PyTorch and TensorFlow are both developed based on Python, while Meta pays more attention to maintaining the open source community and even invests a lot of resources.
Moreover, Meta is paying attention to Google’s problems and believes that it cannot repeat the same mistakes. They focus on a small set of features and make them the best they can be.
Meta is not following in Google’s footsteps. This framework, first developed at Facebook, has slowly become an industry benchmark.
A research engineer at a machine learning start-up company said, "We basically use PyTorch. Its community and open source are the best. Not only do you answer all questions, but the examples given are also very practical."

Faced with this situation, Google developers, hardware experts, cloud providers, and anyone related to Google machine learning all said the same thing in interviews. They believe that TensorFlow has lost the hearts of developers.
After a series of open and covert struggles, Meta finally gained the upper hand.
Some experts say that Google’s opportunity to continue to lead machine learning in the future is slowly disappearing.
PyTorch has gradually become the tool of choice for ordinary developers and researchers.
Judging from the interaction data provided by Stack Overflow, there are more and more questions about PyTorch on developer forums, while questions about TensorFlow have been at a standstill in recent years.
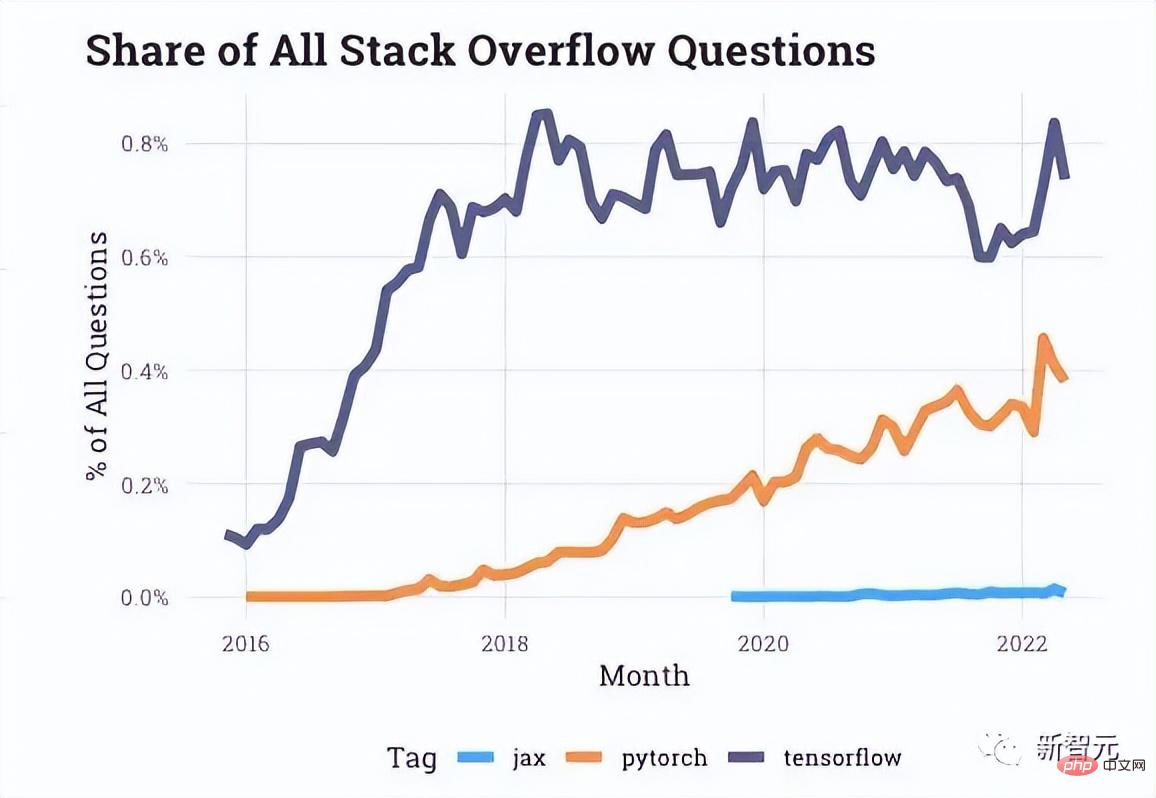
Even companies such as Uber mentioned at the beginning of the article have also turned to PyTorch.
In fact, every subsequent update of PyTorch seems to be a slap in the face of TensorFlow.
Just when TensorFlow and PyTorch were fighting in full swing, a "small dark horse research team" within Google began to work on developing a brand new framework. TPU can be used more conveniently.

In 2018, a paper titled "Compiling machine learning programs via high-level tracing" brought the JAX project to the surface. The authors were Roy Frostig and Matthew James. Johnson and Chris Leary.

From left to right are these three great gods
Then, Adam Paszke, one of the original authors of PyTorch, also joined JAX full-time in early 2020 team.

#JAX provides a more direct way to deal with one of the most complex problems in machine learning: multi-core processor scheduling problem.
According to the application situation, JAX will automatically combine several chips into a small group, rather than letting one go alone.
The advantage of this is that as many TPUs as possible can respond in a moment, thereby burning our "alchemy universe".
In the end, compared to the bloated TensorFlow, JAX solved a major problem within Google: how to quickly access the TPU.
The following is a brief introduction to Autograd and XLA that constitute JAX.
Autograd is mainly used for gradient-based optimization and can automatically distinguish Python and Numpy code.
It can be used to handle a subset of Python, including loops, recursion, and closures, and it can also perform derivatives of derivatives.
In addition, Autograd supports backpropagation of gradients, which means that it can effectively obtain the gradient of a scalar-valued function relative to an array-valued parameter, as well as forward mode differentiation, and both can be used arbitrarily combination.
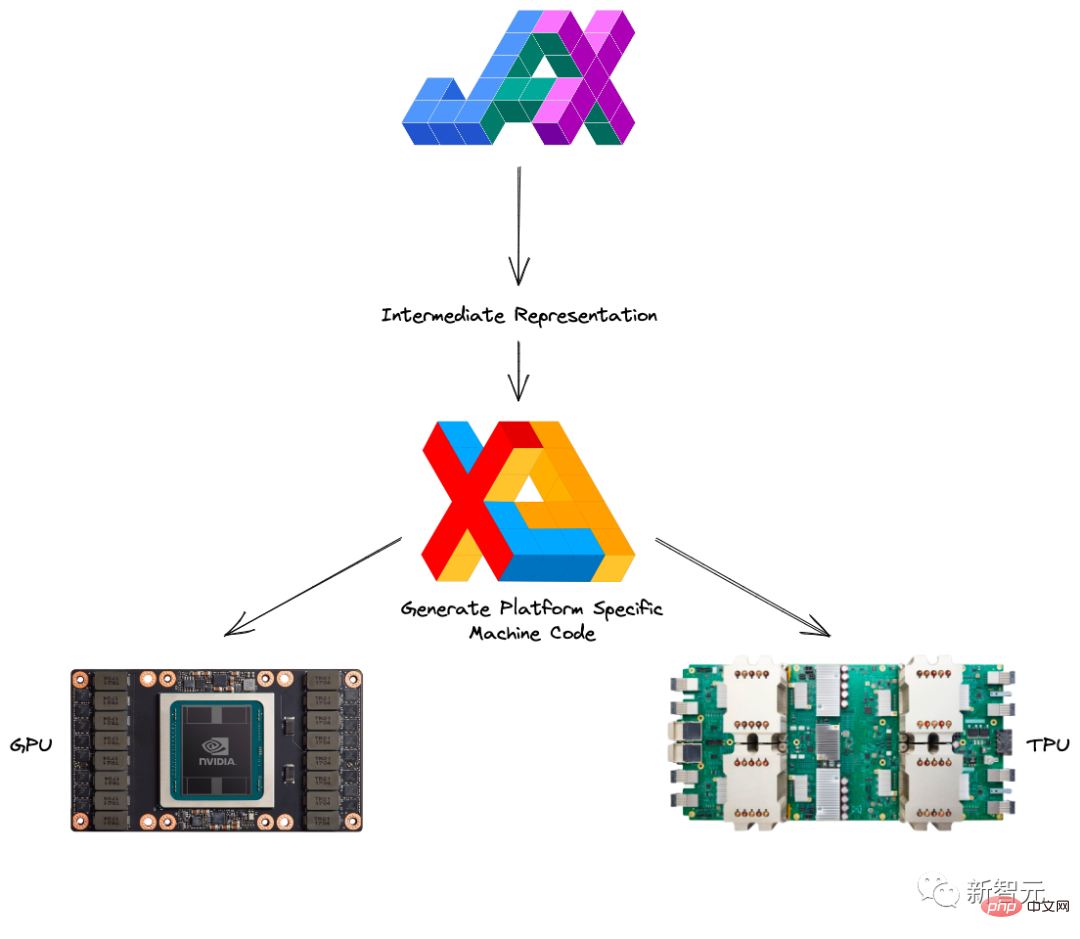
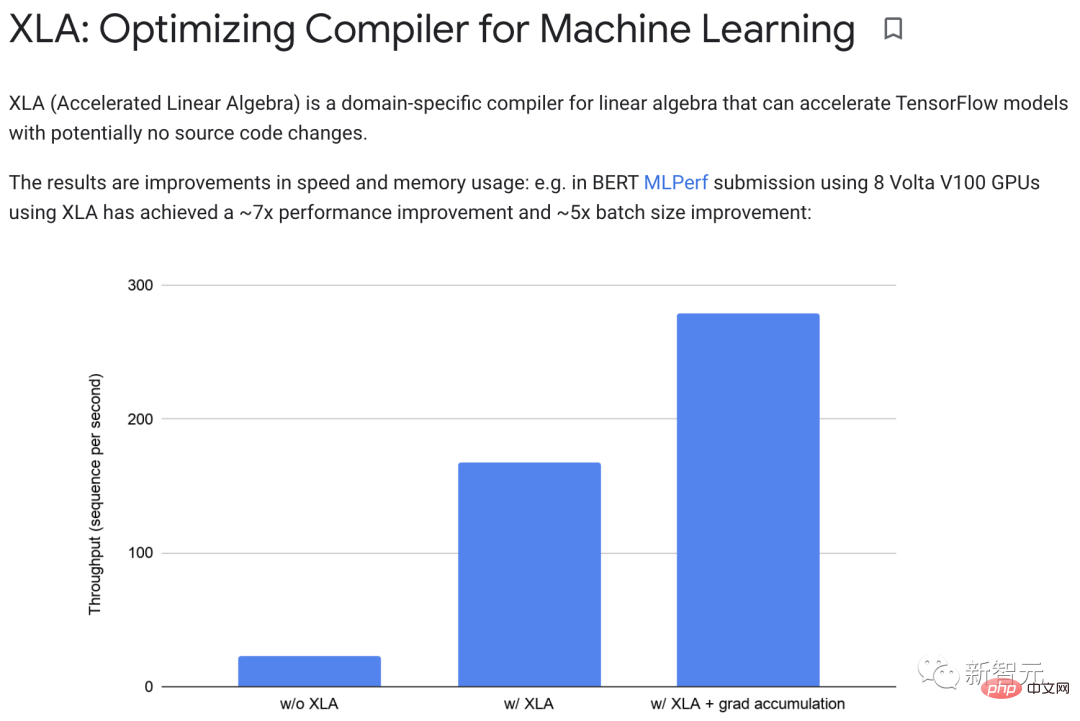
XLA (Accelerated Linear Algebra) can accelerate TensorFlow models without changing the source code.
When a program is running, all operations are performed individually by the executor. Each operation has a precompiled GPU kernel implementation to which executors are dispatched.
For example:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">def</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">model_fn</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span>, <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>):<br><span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">return</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">tf</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">reduce_sum</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">x</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">+</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">y</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">*</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">z</span>)
When running without XLA, this part starts three cores: one for multiplication, one for addition, and one for subtraction.
XLA can achieve optimization by "merging" addition, multiplication and subtraction into a single GPU core.
This fusion operation does not write the intermediate values generated by the memory into the y*z memory x y*z; instead, it "streams" the results of these intermediate calculations directly to the user, while completely Saved in GPU.
In practice, XLA can achieve approximately 7x performance improvement and approximately 5x batch size improvement.
In addition, XLA and Autograd can be combined in any way, and you can even use the pmap method to program with multiple GPU or TPU cores at once.
By combining JAX with Autograd and Numpy, you can get an easy-to-program and high-performance machine learning system for CPU, GPU and TPU.
Obviously, Google has learned its lesson this time. In addition to fully rolling out its own products, it is also particularly active in promoting the construction of an open source ecosystem.
In 2020, DeepMind officially entered the embrace of JAX, and this also announced the end of Google itself. Since then, various open source libraries have emerged in endlessly.


Looking at the entire "infighting", Jia Yangqing said that in the process of criticizing TensorFlow, the AI system believed that Pythonic scientific research was all need.
But on the one hand, pure Python cannot achieve efficient software and hardware co-design, on the other hand, the upper-level distributed system still requires efficient abstraction.
And JAX is looking for a better balance. Google's pragmatism that is willing to subvert itself is worth learning.

causact The author of the R package and related Bayesian analysis textbook said he was pleased to see Google transition from TF to JAX, a cleaner solution.

As a rookie, although Jax can learn from the advantages of the two old predecessors, PyTorch and TensorFlow, sometimes he may be a latecomer. It also brings disadvantages.

First of all, JAX is still too "young". As an experimental framework, it is far from reaching the standards of a mature Google product.
In addition to various hidden bugs, JAX still depends on other frameworks for some issues.
For loading and preprocessing data, you need to use TensorFlow or PyTorch to handle most of the settings.
Obviously, this is still far from the ideal "one-stop" framework.

Secondly, JAX is highly optimized mainly for TPU, but when it comes to GPU and CPU, it is much worse.
On the one hand, Google’s organizational and strategic chaos from 2018 to 2021 resulted in insufficient funds for research and development to support GPUs, and low priority in dealing with related issues.
At the same time, they are probably too focused on making their own TPUs share more of the cake in AI acceleration. Naturally, cooperation with NVIDIA is very lacking, let alone improving details such as GPU support. Problem.
On the other hand, Google’s own internal research, needless to say, is all focused on TPU, which causes Google to lose a good feedback loop on GPU usage.
In addition, longer debugging time, not being compatible with Windows, the risk of not tracking side effects, etc., all increase the threshold and friendliness of Jax.
Now, PyTorch is almost 6 years old, but it does not have the decline that TensorFlow showed back then.
It seems that Jax still has a long way to go if he wants to catch up with the latecomers.
The above is the detailed content of Beaten by PyTorch! Google dumps TensorFlow, bets on JAX. For more information, please follow other related articles on the PHP Chinese website!
 What's going on when I can't connect to the network?
What's going on when I can't connect to the network?
 connectionresetSolution
connectionresetSolution
 How to optimize a single page
How to optimize a single page
 How to buy and sell Bitcoin on Huobi.com
How to buy and sell Bitcoin on Huobi.com
 How to solve 500 internal server error
How to solve 500 internal server error
 press any key to restart
press any key to restart
 How to implement jsp paging function
How to implement jsp paging function
 Introduction to parametric modeling software
Introduction to parametric modeling software
 How to execute a shell script
How to execute a shell script








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



