
 Technology peripherals
AI
Shanghai Digital Brain Research Institute releases DB1, China's first large multi-modal decision-making model, which can achieve rapid decision-making on ultra-complex problems
Technology peripherals
AI
Shanghai Digital Brain Research Institute releases DB1, China's first large multi-modal decision-making model, which can achieve rapid decision-making on ultra-complex problems
Shanghai Digital Brain Research Institute releases DB1, China's first large multi-modal decision-making model, which can achieve rapid decision-making on ultra-complex problems

Recently, Shanghai Digital Brain Research Institute (hereinafter referred to as "Digital Brain Research Institute") launched the first large-scale digital brain multi-modal decision-making model (referred to as DB1), filling the domestic gap in this area and further verifying the The potential of pre-trained models in text, image-text, reinforcement learning decision-making, and operations optimization decision-making. Currently, we have open sourced the DB1 code on Github, project link: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1.
Previously, the Institute of Mathematical Sciences proposed MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) and other multi-intelligence intelligence Body model, through sequence modeling in some large offline models, using the Transformer model has achieved remarkable results in some single/multi-agent tasks, and research and exploration in this direction continues.
In the past few years, with the rise of pre-trained large models, academia and industry have continued to make new progress in the parameter amount and multi-modal tasks of pre-trained models. Large-scale pre-training models are considered to be one of the important paths to general artificial intelligence through in-depth modeling of massive data and knowledge. The Digital Research Institute, which focuses on decision-making intelligence research, innovatively tried to copy the success of the pre-trained model to decision-making tasks and achieved a breakthrough.
Multi-modal decision-making large model DB1
Previously, DeepMind launched Gato, which unifies single-agent decision-making tasks, multi-round dialogues and picture-text generation tasks into one Based on Transformer's autoregressive problem, it has achieved good performance on 604 different tasks, showing that some simple reinforcement learning decision-making problems can be solved through sequence prediction. This verifies the research direction of the Institute of Mathematics in the direction of large decision-making models. Correctness.
This time, the DB1 launched by the Institute of Mathematics Research mainly reproduced and verified Gato, and tried to conduct it from the aspects of network structure and parameter amount, task type and task number. Improvement:
-
#Parameter volume and network structure: DB1 parameter volume reaches 1.21 billion. Try to be as close to Gato as possible in terms of parameters. Overall, the Institute of Numerical Research uses a similar structure to Gato (same number of Decoder Blocks, hidden layer size, etc.), but in FeedForwardNetwork, since the GeGLU activation function will introduce an additional 1/3 of the number of parameters, the Institute of Mathematical Sciences wants to The parameter amount is close to Gato, and the hidden layer state of 4 * n_embed dimensions is transformed into 2 * n_embed dimensional features through the GeGLU activation function. Otherwise, we share embedding parameters on the input and output encoding sides with Gato's implementation. Different from Gato, we adopt the PostNorm solution in selecting layer normalization, and we use mixed-precision calculations in Attention to improve numerical stability.
- Task type and number of tasks: The number of experimental tasks in DB1 reaches 870, which is 44.04% higher than Gato and >=50% higher than Gato. Expert performance is improved by 2.23%. In terms of specific task types, DB1 mostly inherits Gato’s decision-making, image and text tasks, and the number of various tasks remains basically the same. But in terms of decision-making tasks, DB1 has also introduced more than 200 real-life scenario tasks, namely the 100- and 200-node scale traveling salesman problem (TSP). This type of task randomly selects 100-200 geographical locations as nodes in all major cities in China. representation) solution.
It can be seen that the overall performance of DB1 has reached the same level as Gato, and has begun to evolve towards a demand field body that is closer to the actual business, and is well solved The NP-hard TSP problem has not been explored in this direction before by Gato.
 Comparison of DB1 (right) and GATO (left) indicators
Comparison of DB1 (right) and GATO (left) indicators
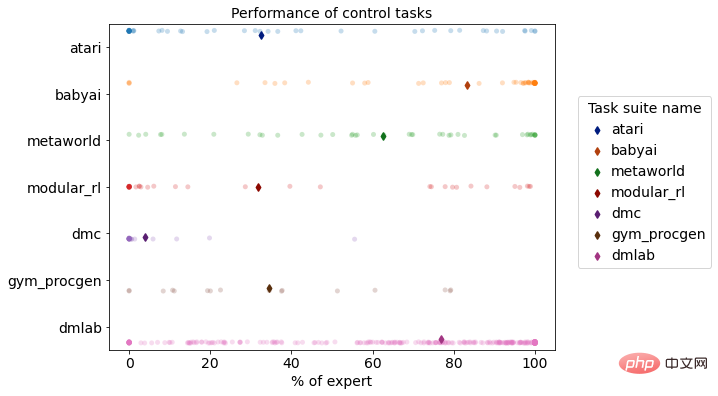
Multi-task performance distribution of DB1 on reinforcement learning simulation environment
Compared with traditional decision-making algorithms, DB1 has good performance in cross-task decision-making capabilities and fast migration capabilities. In terms of cross-task decision-making capabilities and parameter quantities, it has achieved a leap from tens of millions of parameters for a single complex task to billions of parameters for multiple complex tasks, and continues to grow, and has the ability to solve problems in complex business environments. Adequate ability to solve practical problems. In terms of migration capabilities, DB1 has completed the leap from intelligent prediction to intelligent decision-making, and from single agent to multi-agent, making up for the shortcomings of traditional methods in cross-task migration, making it possible to build large models within the enterprise.
It is undeniable that DB1 also encountered many difficulties in the development process. The Institute of Digital Research has made a lot of attempts to provide the industry with large-scale model training and multi-task training data storage. Provide some standard solution paths. Since the model parameters have reached 1 billion parameters and the task scale is huge, and it needs to be trained on more than 100T (300B Tokens) expert data, the ordinary deep reinforcement learning training framework can no longer meet the requirements for rapid training in this situation. To this end, on the one hand, for distributed training, the Institute of Mathematics Research fully considers the computing structure of reinforcement learning, operational optimization and large model training. In a single-machine multi-card or multi-machine multi-card environment, it makes full use of hardware resources and cleverly designs modules. The communication mechanism between the two models maximizes the training efficiency of the model and shortens the training time of 870 tasks to one week. On the other hand, for distributed random sampling, the data indexing, storage, loading and preprocessing required in the training process have also become corresponding bottlenecks. The Institute of Mathematics Research Institute adopted a delayed loading mode when loading the data set to solve the problem of memory limitations and maximize the Make full use of available memory. In addition, after preprocessing the loaded data, the processed data will be cached on the hard disk, so that the preprocessed data can be directly loaded later, reducing the time and resource costs caused by repeated preprocessing.
Currently, leading international and domestic companies and research institutions such as OpenAI, Google, Meta, Huawei, Baidu and DAMO Academy have conducted research on multi-modal large models and There have been some commercialization attempts, including applying it in its own products or providing model APIs and related industry solutions. In contrast, the Institute of Mathematical Sciences focuses more on decision-making issues and supports application attempts in game AI decision-making tasks, operations research optimization TSP solving tasks, robot decision-making control tasks, black-box optimization solving tasks and multi-round dialogue tasks.
Task Performance
Operations Research Optimization: TSP Problem Solving
With Chinese part TSP problem with city as node
Reinforcement learning task video demonstration
DB1 model completed 870 After offline learning of different decision-making tasks, the evaluation results showed that 76.67% of the tasks reached or exceeded 50% expert level. The following is a demonstration of the effects of some tasks.
- Electronic game scenario: DB1 can receive 2D/3D image input and can well complete 2D pixel games such as Atari and Procgen. At the same time, it is also suitable for DMLab. DB1 also showed good performance on 3D image input tasks that are similar to the real world.

##Atari Breakout

DMLab Explore Object Locations

##Procgen DogBall
- Continuous control scenario: In continuous control tasks in the field of robotics, DB1 can also model the policy output of continuous actions and complete it well on simulation tasks.
Metaworld PlateSlide

##ModularRL Cheetah
Text-Image task
- Text generation: Give a text prompt and generate a long text description
- Input prompt: digital brain laboratory is a shanghai based
- Generate result: digital brain laboratory is a shanghai based company and we are looking for a highly skilled and experienced person to join our team in shanghai, china.
we are a digital brain lab and we are looking for a highly skilled and experienced person to join our team in shanghai, china.
This is an opportunity to work for a well known and growing company that is going through a fast growth phase and to have an impact in the market.
This is a full-time, permanent position.
We are looking for a highly skilled, motivated and experienced software engineer who can lead a team of 5-10 in a highly competitive environment - Image description generation: Given an image, generate a corresponding text description

Although the current multi-modal decision-making pre-training model DB1 has achieved certain results, there are still certain limitations, such as: cross-domain task sampling weight sensitivity, cross-domain Difficulties in knowledge transfer, long sequence modeling, strong dependence on expert data, etc. Although there are many challenges, at this stage, it seems that the large multi-modal decision-making model is the key to realizing the decision-making agent from games to wider scenarios, from virtual to reality, autonomous sensing and decision-making in a realistic open dynamic environment, and ultimately achieving a more universal One of the key exploration directions of artificial intelligence. In the future, the Digital Research Institute will continue to iterate the large digital brain decision-making model, access and support more tasks through larger parameter quantities and more effective sequence representations, and combine offline/online training and fine-tuning to achieve cross-domain, cross-modal, and Cross-task knowledge generalization and transfer ultimately provide more versatile, efficient, and lower-cost intelligent decision-making solutions in real-life application scenarios.
The above is the detailed content of Shanghai Digital Brain Research Institute releases DB1, China's first large multi-modal decision-making model, which can achieve rapid decision-making on ultra-complex problems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1205
24
52
1205
24

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
