

Just input a line of text to generate a 3D dynamic scene?
Yes, some researchers have already done it. It can be seen that the current generation effect is still in its infancy and can only generate some simple objects. However, this "one-step" method still attracts the attention of a large number of researchers:

In a recent article In the paper, researchers from Meta proposed for the first time MAV3D (Make-A-Video3D), a method that can generate three-dimensional dynamic scenes from text descriptions.

Specifically, the method uses 4D dynamic Neural Radiation Fields (NeRF) to optimize the consistency of scene appearance, density, and motion by querying a text-to-video (T2V) diffusion-based model. The dynamic video output generated by the provided text can be viewed from any camera angle or angle and can be synthesized into any 3D environment.
MAV3D does not require any 3D or 4D data, the T2V model is trained only on text-image pairs and unlabeled videos.


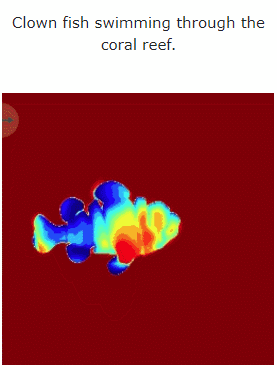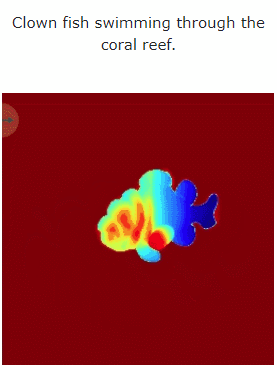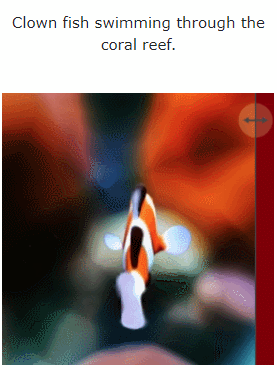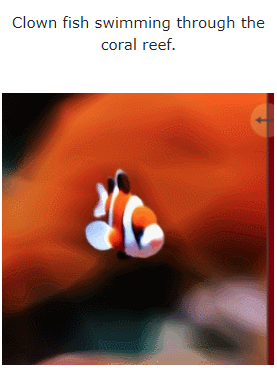


Method
From a higher level, given a text prompt p, research can fit a 4D representation that simulates the appearance of the scene matching the prompt at any point in space and time. Without paired training data, the study cannot directly supervise the output of 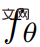 ; however, given a sequence of camera poses
; however, given a sequence of camera poses 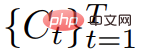 You can render the image sequence from
You can render the image sequence from 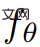
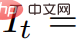
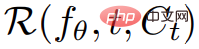 and stack them into a video V. The text prompt p and video V are then passed to the frozen and pre-trained T2V diffusion model, which scores the authenticity and prompt alignment of the video and uses SDS (Score Distillation Sampling) to calculate the update direction of the scene parameter θ .
and stack them into a video V. The text prompt p and video V are then passed to the frozen and pre-trained T2V diffusion model, which scores the authenticity and prompt alignment of the video and uses SDS (Score Distillation Sampling) to calculate the update direction of the scene parameter θ .
The above pipeline can be counted as an extension of DreamFusion, adding a temporal dimension to the scene model and using a T2V model instead of a text-to-image (T2I) model for supervision. However, achieving high-quality text-to-4D generation requires more innovation:
See the picture below for specific instructions:
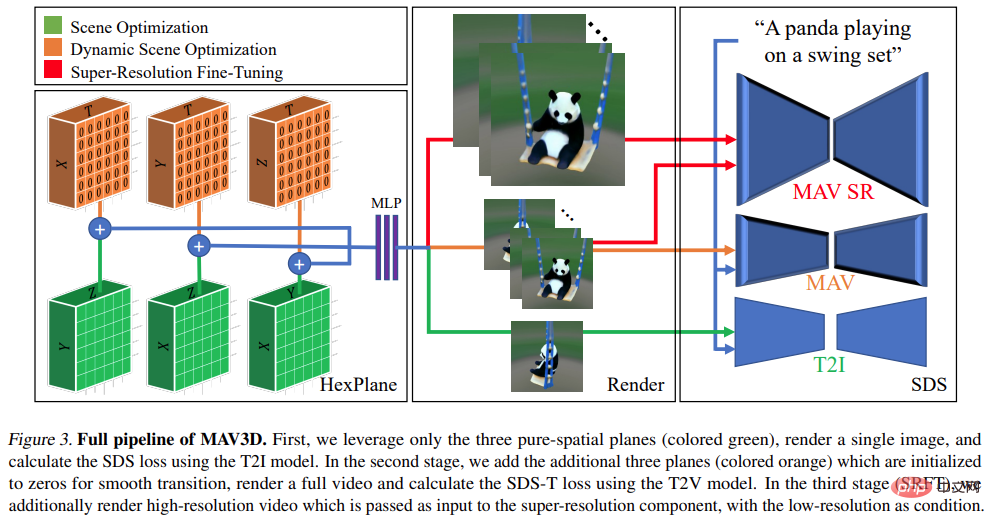
In the experiment, the researchers evaluated MAV3D's ability to generate dynamic scenes from text descriptions. First, the researchers evaluated the effectiveness of the method on the Text-To-4D task. It is reported that MAV3D is the first solution to this task, so the research developed three alternative methods as baselines. Second, we evaluate simplified versions of the T2V and Text-To-3D subtask models and compare them with existing baselines in the literature. Third, comprehensive ablation studies justify the method design. Fourth, experiments describe the process of converting dynamic NeRF to dynamic meshes, ultimately extending the model to Image-to-4D tasks.
Metrics
Study to evaluate generated videos using CLIP R-Precision, which measures text and generated scenes consistency between. The reported metric is the accuracy of retrieving the input prompt from the rendered frame. We used the ViT-B/32 variant of CLIP and extracted frames at different views and time steps, and also used four qualitative metrics by asking human raters for their preferences across two generated videos, respectively. are: (i) video quality; (ii) fidelity to text prompts; (iii) amount of activity; (iv) realism of movement. We evaluated all baselines and ablations used in text prompt segmentation.
Figure 1 and Figure 2 are examples. For more detailed visualizations, see make-a-video3d.github.io.

Results
Table 1 shows Comparison to baseline (R - accuracy and human preference). Human reviews are presented as the percentage of votes favoring the baseline majority compared to the model in a specific environment.
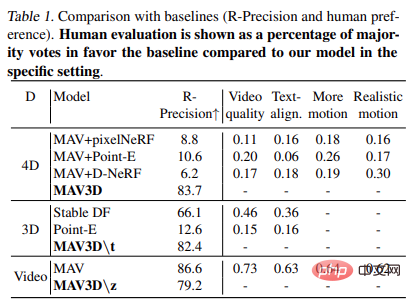
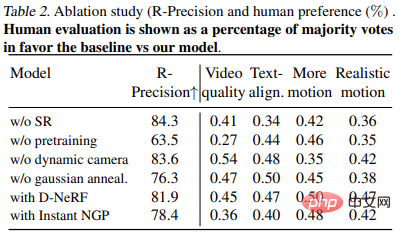
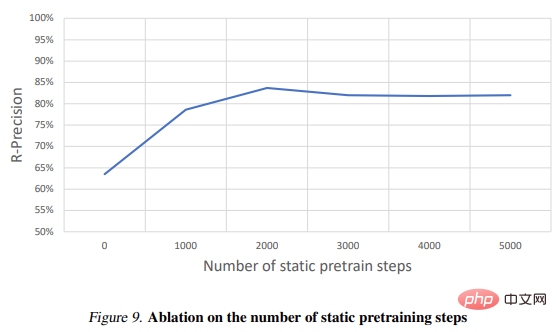
Table 2 shows the results of the ablation experiment:
Real-time rendering
Applications such as virtual reality and games that use traditional graphics engines require a standard format, Such as texture mesh. HexPlane models can be easily converted into animated meshes as shown below. First, a simple mesh is extracted from the opacity field generated at each time t using the marching cube algorithm, followed by mesh extraction (for efficiency) and removal of small noisy connected components. The XATLAS algorithm is used to map mesh vertices to a texture atlas, with the texture initialized using the average HexPlane color in a small sphere centered at each vertex. Finally, the textures are further optimized to better match some example frames rendered by HexPlane using differentiable meshes. This will produce a collection of texture meshes that can be played back in any off-the-shelf 3D engine.
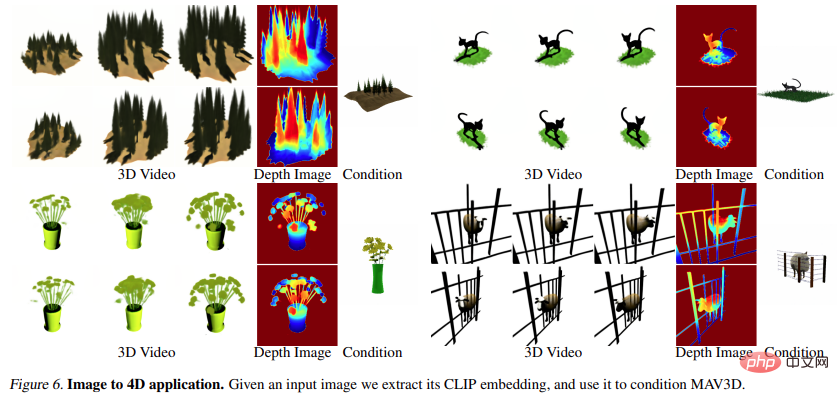
Image to 4D
Figure 6 and Figure 10 show the method that can be generated from a given input image Depth and motion, resulting in 4D assets.



The above is the detailed content of A line of text generates a 3D dynamic scene: Meta's 'one step” model is quite powerful. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



