

In recent years, large-scale multi-modal training based on Transformer has led to improvements in state-of-the-art technology in different fields, including vision, language, and audio. Especially in computer vision and image language understanding, a single pre-trained large model can outperform an expert model for a specific task.
However, large multimodal models often use modality or dataset-specific encoders and decoders, and result in involved protocols accordingly. For example, such models often involve different stages of training different parts of the model on their respective datasets, with dataset-specific preprocessing, or transferring different parts in a task-specific manner. This pattern and task-specific components can lead to additional engineering complexity and challenges when introducing new pre-training losses or downstream tasks.
Therefore, developing a single end-to-end model that can handle any modality or combination of modalities will be an important step towards multi-modal learning. In this article, researchers from Google Research (Google Brain team) in Zurich will focus mainly on images and text.

##Paper address: https://arxiv.org/pdf/2212.08045.pdf
Many key unifications accelerate the process of multimodal learning. First, it has been proven that the Transformer architecture can serve as a general backbone and perform well on text, visuals, audio, and other domains. Second, many papers explore mapping different modalities into a single shared embedding space to simplify the input/output interface, or to develop a single interface for multiple tasks. Third, alternative representations of modalities allow the utilization in one domain of neural architectures or training procedures designed in another domain. For example, [54] and [26,48] represent text and audio respectively, which are processed by rendering these forms as images (spectrograms in the case of audio).
This article will explore multi-modal learning of text and images using purely pixel-based models. The model is a separate visual Transformer that processes visual input or text, or both together, all rendered as RGB images. All modalities use the same model parameters, including low-level feature processing; that is, there are no modality-specific initial convolutions, tokenization algorithms, or input embedding tables. The model is trained with only one task: contrastive learning, as popularized by CLIP and ALIGN. Therefore the model is called CLIP-Pixels Only (CLIPPO).
On the main tasks of CLIP designed for image classification and text/image retrieval, CLIPPO also performs similarly to CLIP despite not having a specific tower modality (similarity in the 1- Within 2%). Surprisingly, CLIPPO can perform complex language understanding tasks without requiring any left-to-right language modeling, masked language modeling, or explicit word-level losses. Especially on the GLUE benchmark, CLIPPO outperforms classic NLP baselines such as ELMO BiLSTM attention. Additionally, CLIPPO also outperforms pixel-based mask language models and approaches BERT's scores.
Interestingly, CLIPPO also achieves good performance on VQA when simply rendering images and text together, despite having never been pretrained on such data. An immediate advantage of pixel-based models compared to conventional language models is that no predetermined vocabulary is required. As a result, the performance of multilingual retrieval is improved compared to equivalent models using classic tokenizers. Finally, the study also found that in some cases the previously observed modal gaps were reduced when training CLIPPO.
Method OverviewCLIP has emerged as a powerful and scalable paradigm for training multi-purpose vision models on datasets. Specifically, this approach relies on image/alt-text pairs, which can be automatically collected from the web at scale. As a result, textual descriptions are often noisy and may consist of single keywords, sets of keywords, or potentially lengthy descriptions. Using this data, two encoders are jointly trained, namely a text encoder embedding alt-text and an image encoder embedding the corresponding image in a shared latent space. The two encoders are trained using a contrastive loss that encourages the embeddings of corresponding images and alt-texts to be similar while being different from the embeddings of all other images and alt-texts.
Once trained, such an encoder pair can be used in a variety of ways: it can classify a fixed set of visual concepts by textual descriptions (zero-shot classification); the embedding can be used to retrieve a given textual description. images, and vice versa; alternatively, the visual encoder can be transferred to downstream tasks in a supervised manner by fine-tuning on a labeled dataset or by training the head on a frozen image encoder representation. In principle, the text encoder can be used as an independent text embedding. However, it is reported that no one has conducted in-depth research on this application. Some studies cited low-quality alt-text, resulting in weak language modeling performance of the text encoder. .
Previous work has shown that image and text encoders can be implemented with a shared transformer model (also called a single tower model, or 1T-CLIP), where images are embedded using patch embedding, Tokenized text is embedded using a separate word embedding. Except for modality-specific embeddings, all model parameters are shared between the two modalities. While this type of sharing typically results in performance degradation on image/image-to-language tasks, it also reduces the number of model parameters by half.
CLIPPO takes this idea one step further: text input is rendered on a blank image and is then processed entirely as an image, including the initial patch embedding (see Figure 1). Through comparative training with previous work, a single visual transformer model is generated that can understand images and text through a single visual interface, and provides a solution that can be used to solve image, image-language and pure language understanding tasks. Single representation.
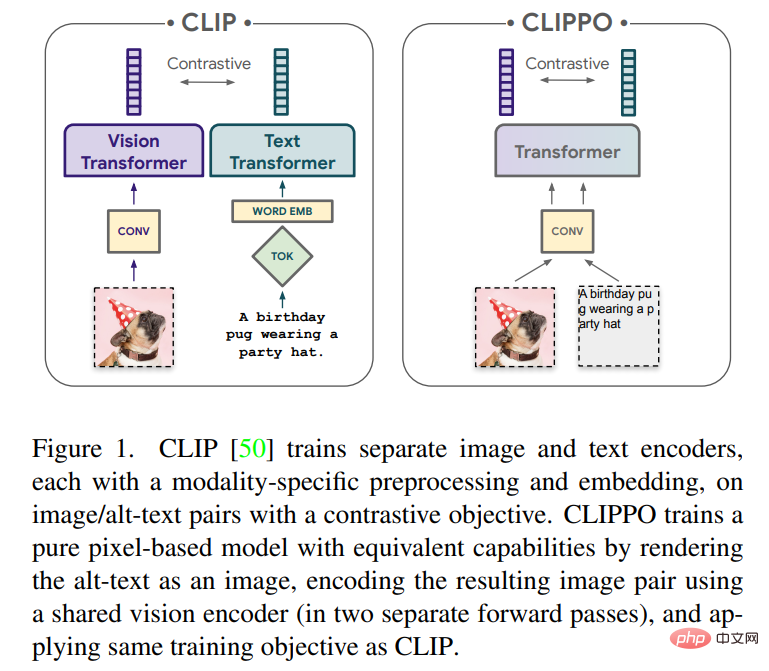
In addition to multimodal versatility, CLIPPO alleviates common difficulties in text processing, namely developing appropriate tokenizers and vocabularies. This is particularly interesting in the context of massive multilingual settings, where text encoders have to handle dozens of languages.
It can be found that CLIPPO trained on image/alt-text pairs performs on par with 1T-CLIP on public image and image language benchmarks, and on the GLUE benchmark with the powerful Baseline language model competition. However, since alt-texts are of lower quality and are generally not grammatical sentences, learning language understanding from alt-texts alone is fundamentally limited. Therefore, language-based contrast training can be added to image/alt-texts contrast pre-training. Specifically, consecutive sentence pairs sampled from a text corpus, translated sentence pairs in different languages, post-translated sentence pairs, and sentence pairs with missing words need to be taken into account.
Visual and visual-language understanding
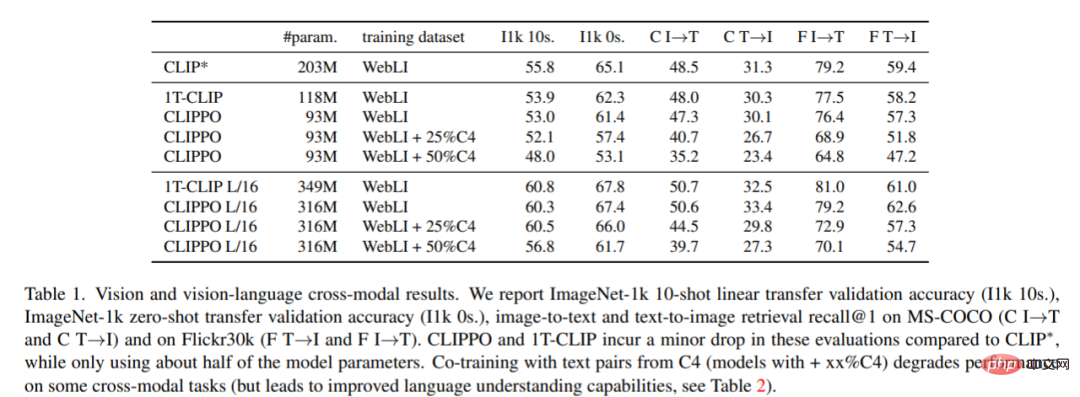
Image classification and retrieval. Table 1 shows the performance of CLIPPO, and it can be seen that CLIPPO and 1T-CLIP produce an absolute decrease of 2-3 percentage points compared to CLIP*.
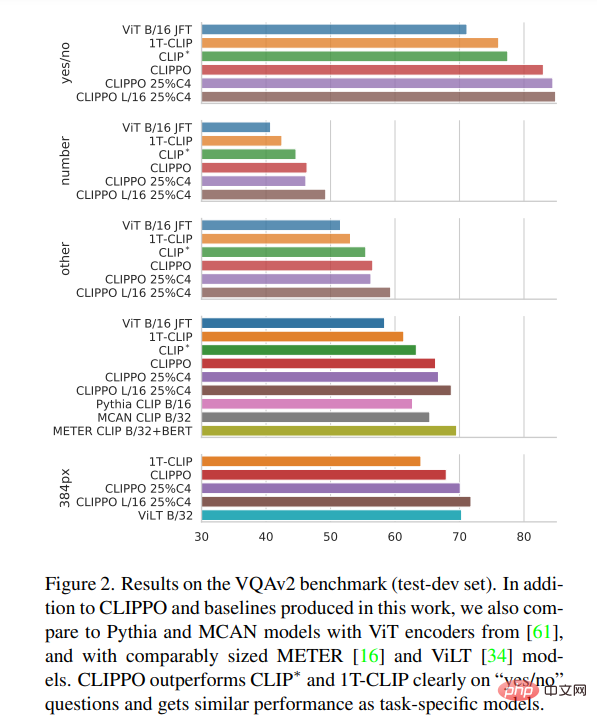
VQA. The VQAv2 scores of the model and baseline are reported in Figure 2 . It can be seen that CLIPPO outperforms CLIP∗, 1T-CLIP, and ViT-B/16, achieving a score of 66.3.
Multi-language vision - language understanding
Figure 3 shows that CLIPPO Retrieval performance comparable to these baselines is achieved. In the case of mT5, using additional data can improve performance; leveraging these additional parameters and data in a multilingual context will be an interesting future direction for CLIPPO.
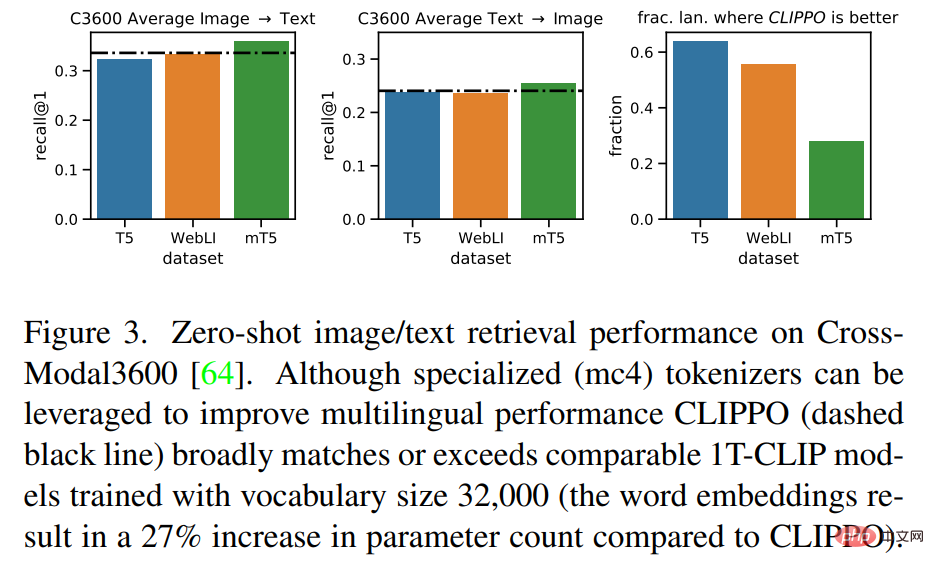
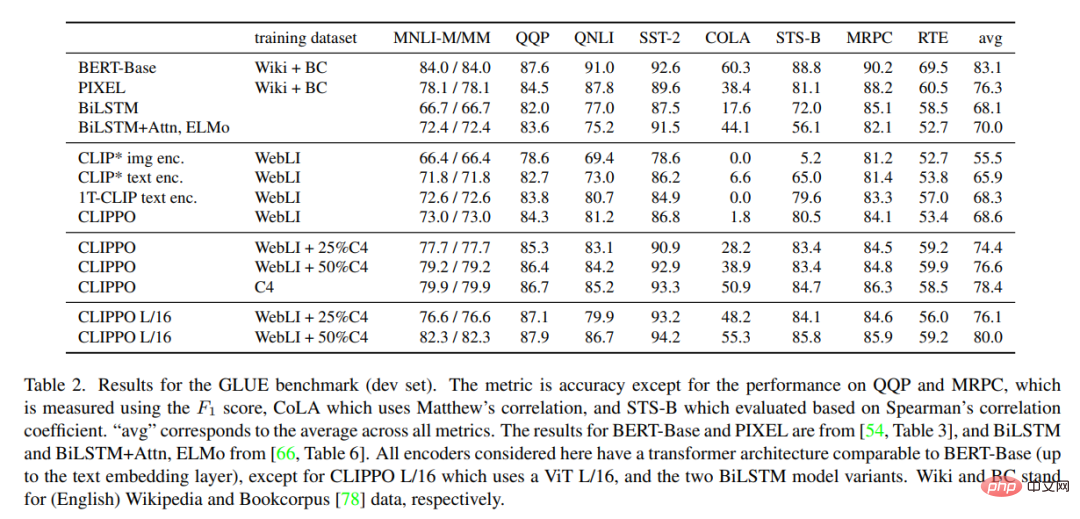
Table 2 shows the GLUE benchmark results for CLIPPO and baseline. It can be observed that CLIPPO trained on WebLI is competitive with the BiLSTM Attn ELMo baseline which has deep word embeddings trained on a large language corpus. Furthermore, we can see that CLIPPO and 1T-CLIP outperform language encoders trained using standard contrastive language vision pre-training.
For more research details, please refer to the original paper.
The above is the detailed content of The parameters are halved and as good as CLIP. The visual Transformer realizes the unification of image and text starting from pixels.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



