

Improve AI end-to-end performance through customized operator fusion

Graph optimization plays an important role in reducing the time and resources used by training and inference of AI models. An important function of graph optimization is to fuse operators that can be fused in the model, thereby improving computing efficiency by reducing memory usage and data transfer in low-speed memory. However, it is very difficult to implement a back-end solution that can provide various operator fusions, resulting in very limited operator fusions that can be used by AI models on actual hardware.
The Composable Kernel (CK) library aims to provide a set of back-end solutions for operator fusion on AMD GPUs. CK uses the general-purpose programming language HIP C and is completely open source. Its design concepts include:
- High performance & high productivity: The core of CK is a set of carefully designed, highly optimized, and reusable basic modules. All operators in the CK library are implemented by combining these basic modules. Reusing these basic modules greatly shortens the development cycle of back-end algorithms while ensuring high performance.
- Proficient in current AI problems and quickly adapt to future AI problems: CK aims to provide a complete set of AI operator back-end solutions, which makes complex operator fusion possible. Because this allows the entire backend to be implemented using CK without relying on external operator libraries. CK's reusable basic modules are sufficient to implement various operators and their fusion required by common AI models (machine vision, natural language processing, etc.). When emerging AI models require new operators, CK will also provide the required basic modules.
- A simple but powerful tool for AI system experts: CK All operators are implemented using HIP C templates. AI system experts can customize the properties of these operators through instantiation templates, such as data type, meta-operation type, tensor storage format, etc. This usually only requires a few lines of code.
- Friendly HIP C interface: HPC algorithm developers have been pushing the frontier of AI computing acceleration. An important design concept of CK is to make it easier for HPC algorithm developers to contribute to AI acceleration. Therefore, all core modules of CK are implemented in HIP C instead of Intermediate Representation (IR). HPC algorithm developers can write algorithms directly in the form of C code they are familiar with, without having to write a Compiler Pass for a specific algorithm, as is the case with IR-based operator libraries. Doing so can greatly improve the iteration speed of the algorithm.
- Portability: Today’s graph optimization using CK as the backend will be able to be ported to all future AMD GPUs, and will eventually be ported to AMD CPUs [2].
- CK source code: https://github.com/ROCmSoftwarePlatform/composable_kernel
Core Concept
CK introduces two concepts to improve the productivity of back-end developers:
1. The groundbreaking introduction of "Tensor Coordinate Transformation" Reduce the complexity of writing AI operators. This research pioneered the definition of a set of reusable Tensor Coordinate Transformation basic modules, and used them to re-express complex AI operators (such as convolution, group normalization reduction, Depth2Space, etc.) in a mathematically rigorous way into The most basic AI operators (GEMM, 2D reduction, tensor transfer, etc.). This technology allows algorithms written for basic AI operators to be directly used on all corresponding complex AI operators without having to rewrite the algorithm.
2. Tile-based programming paradigm: Developing the back-end algorithm for operator fusion can be seen as first disassembling each pre-fusion operator (independent operator) into many "Small piece" data operations, and then combine these "small piece" operations into fused operators. Each such "small block" operation corresponds to an original independent operator, but the data being operated is only a part (tile) of the original tensor, so such "small block" operation is called a Tile Tensor Operator. The CK library contains a set of highly optimized implementations of Tile Tensor Operator, and all AI independent operators and fusion operators in CK are implemented using them. Currently, these Tile Tensor Operators include Tile GEMM, Tile Reduction and Tile Tensor Transfer. Each Tile Tensor Operator has implementations for GPU thread blocks, warps and threads.
Tensor Coordinate Transformation and Tile Tensor Operator together form the reusable basic module of CK.
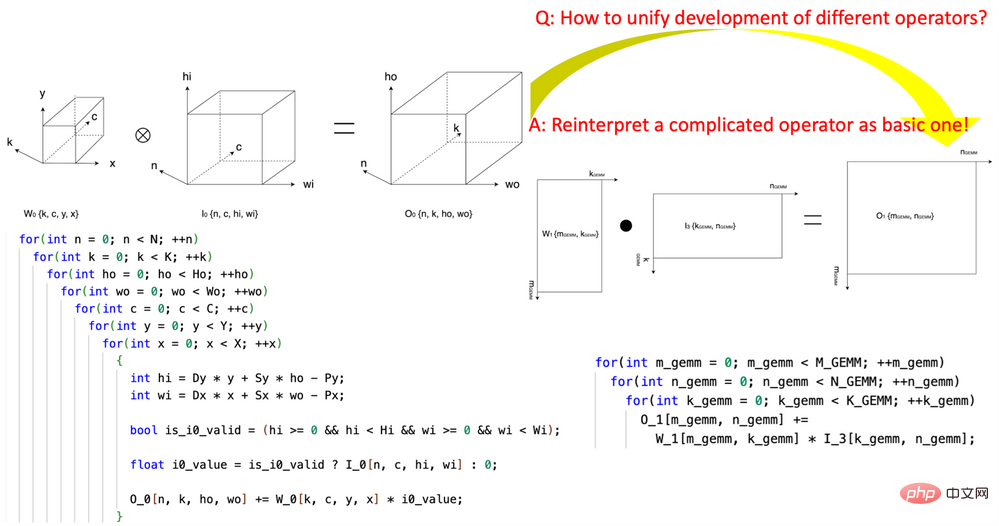
Figure 1, using CK’s Tensor Coordinate Transformation basic module to express the convolution operator into a GEMM operator
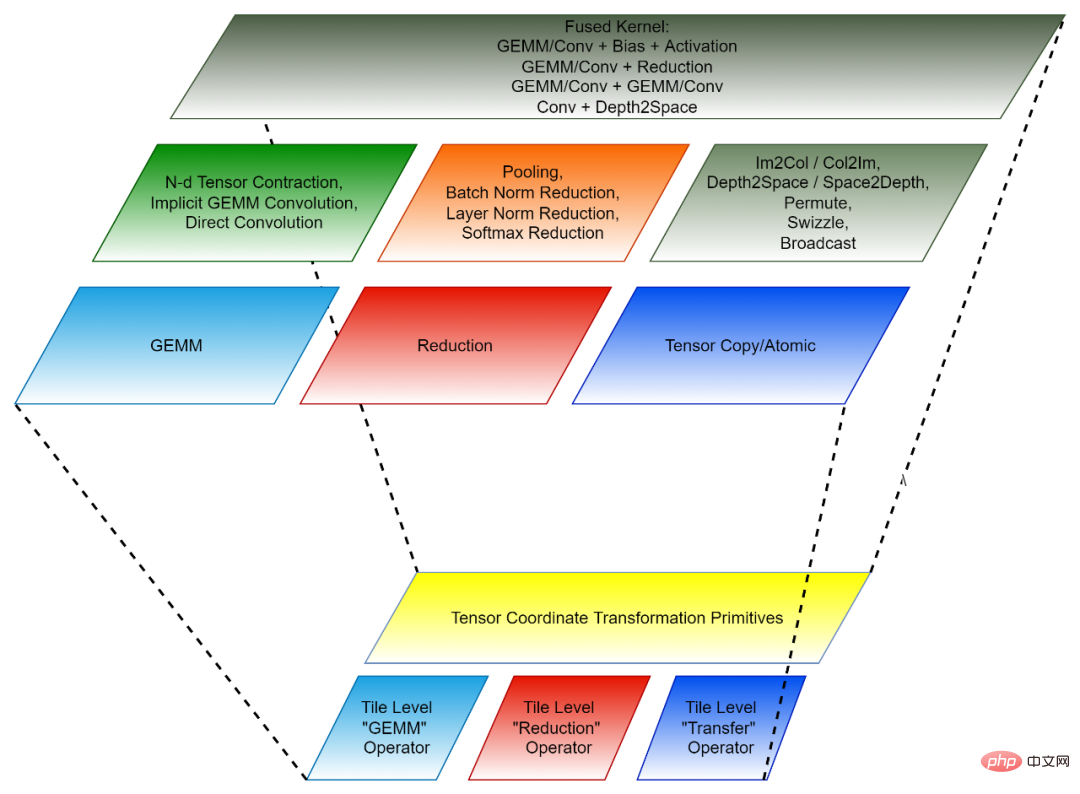
Figure 2, the composition of CK (bottom: reusable basic modules; top: independent operators and fusion operators)
Code structure
The CK library structure is divided into four layers, from bottom to top: Templated Tile Operator, Templated Kernel and Invoker, Instantiated Kernel and Invoker and Client API [3]. Each layer corresponds to different developers.
- #AI system expert: "I need a back-end solution that provides high-performance independent and fusion operators that I can use directly." The Client API and Instantiated Kernel and Invoker used in this example [4] provide pre-instantiated and compiled objects to meet the needs of this type of developer.
- AI system expert: "I do state-of-the-art graph optimization work for an open source AI framework. I need a high-performance kernel that can provide all the fusion operators required for graph optimization. Back-end solutions. At the same time, I also need to customize these kernels, so a black-box solution like "accept it or discard it" cannot meet my needs." The Templated Kernel and Invoker layers satisfy this type of developer. For example, in this example [5], developers can use the Templated Kernel and Invoker layer to instantiate the required FP16 GEMM Add Add FastGeLU kernel.
- HPC algorithm expert: “My team develops high-performance back-end algorithms for the AI models that are constantly iterating within the company. We have HPC algorithm experts on the team, but we still hope to use complex Using and improving highly optimized source code provided by hardware vendors increases our productivity and allows our code to be ported to future hardware architectures. We hope to do this without having to share our code with hardware vendors this point". The Templated Tile Operator layer can help this type of developer. For example, in this code [6], the developer uses Templated Tile Operator to implement the GEMM optimization pipeline.
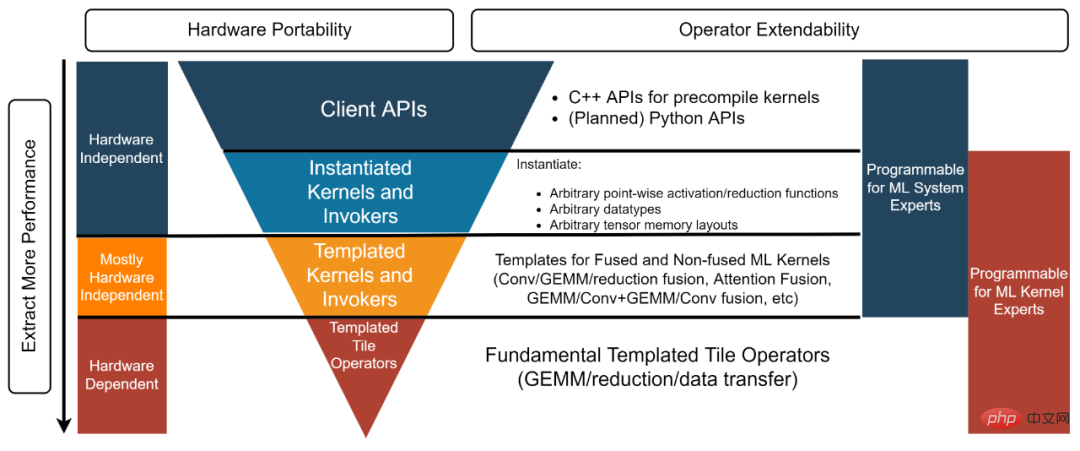
##Figure 3, CK library four-layer structure
End-to-end model inference based on AITemplate CKMeta’s AITemplate [7] (AIT) is an AI inference system that unifies AMD and Nvidia GPUs. AITemplate uses CK as its backend on AMD GPUs, using CK's Templated Kernel and Invoker layer.
AITemplate CK achieves state-of-the-art inference performance on multiple important AI models on the AMD Instinct™ MI250. The definition of most advanced fusion operators in CK is driven by the vision of the AITemplate team. Many fusion operator algorithms are also jointly designed by the CK and AITemplate teams.
This article compares the performance of several end-to-end models on AMD Instinct MI250 and similar products [8]. All performance data of the AMD Instinct MI250 AI model in this article were obtained using AITemplate[9] CK[10].
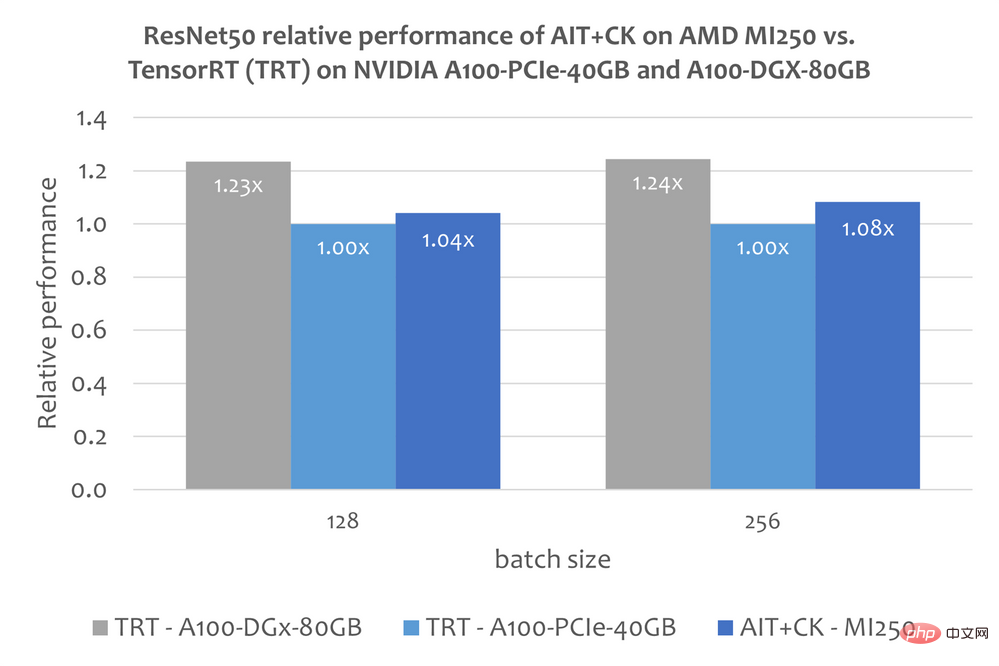
ExperimentalResNet-50
The image below shows AIT on AMD Instinct MI250 Performance comparison of CK with TensorRT v8.5.0.12 [11] (TRT) on A100-PCIe-40GB and A100-DGX-80GB. The results show that AIT CK on AMD Instinct MI250 achieved a 1.08x acceleration compared to TRT on A100-PCIe-40GB.
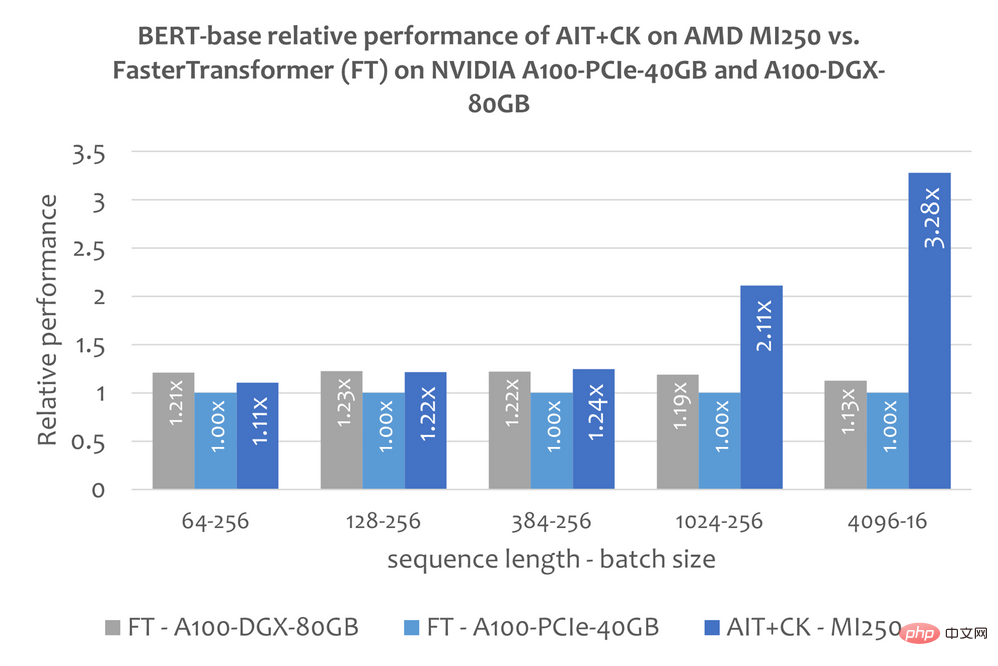
BERT
A Batched GEMM Softmax GEMM fusion operator template implemented based on CK can completely eliminate the transfer of intermediate results between the GPU Compute Unit (Compute Unit) and HBM. By using this fusion operator template, many problems in the attention layer that were originally bandwidth bound have become computational bottlenecks (compute bound), which can better utilize the computing power of the GPU. This CK implementation is deeply inspired by FlashAttention [12] and reduces more data handling than the original FlashAttention implementation.
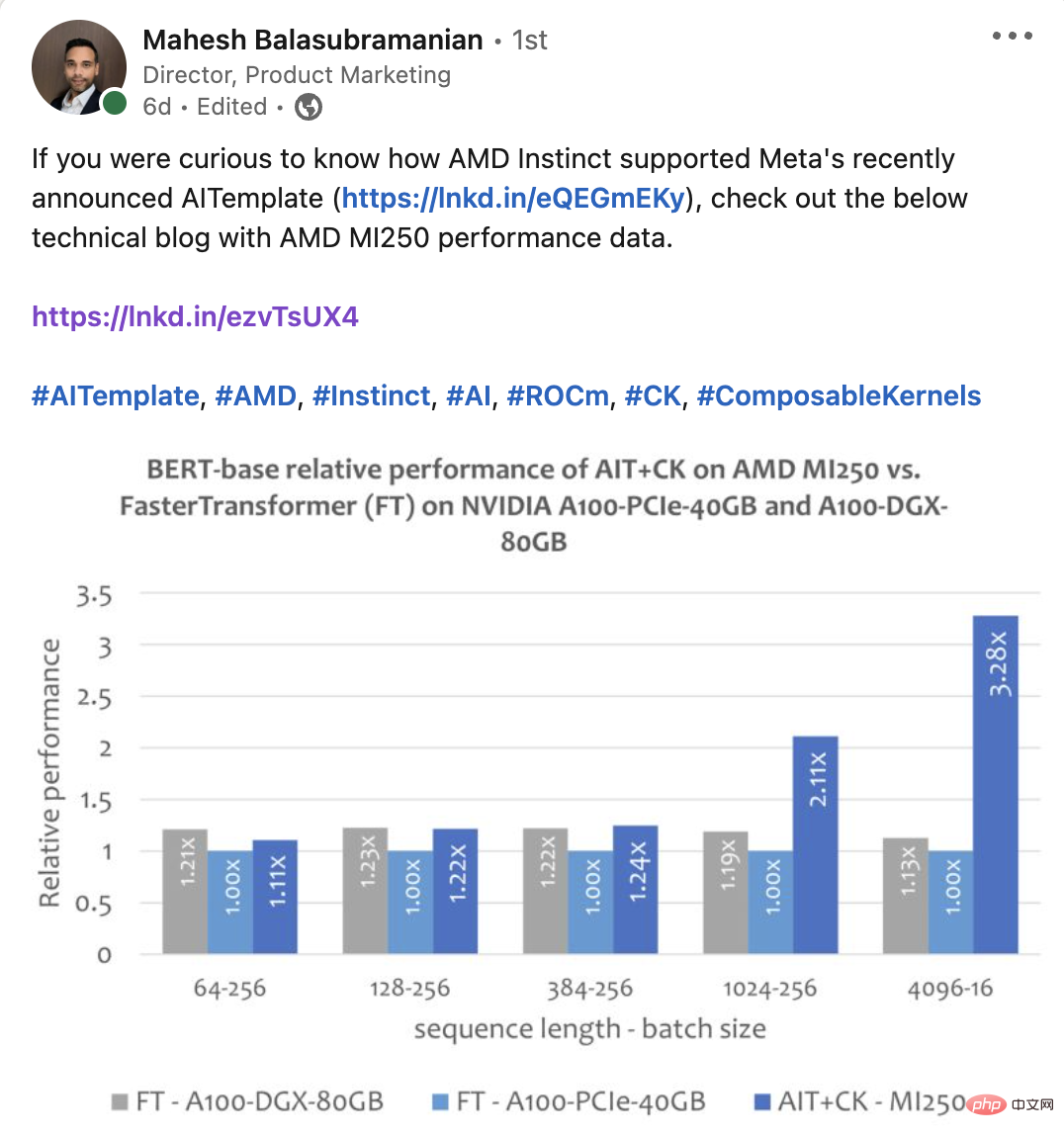
The following figure shows AIT CK on AMD Instinct MI250 with FasterTransformer v5.1.1 bug fix [13] (FT) on A100-PCIe-40GB and A100-DGX-80GB Performance comparison of Bert Base model (uncased). FT runs out of GPU memory at Batch 32 on A100-PCIe-40GB and A100-DGX-80GB when Sequence is 4096. Therefore, when Sequence is 4096, this article only shows the results of Batch 16. The results show that AIT CK on AMD Instinct MI250 achieves 3.28x FT acceleration compared to FT on A100-PCIe-40GB, and 2.91x FT speedup compared to A100-DGX-80GB.
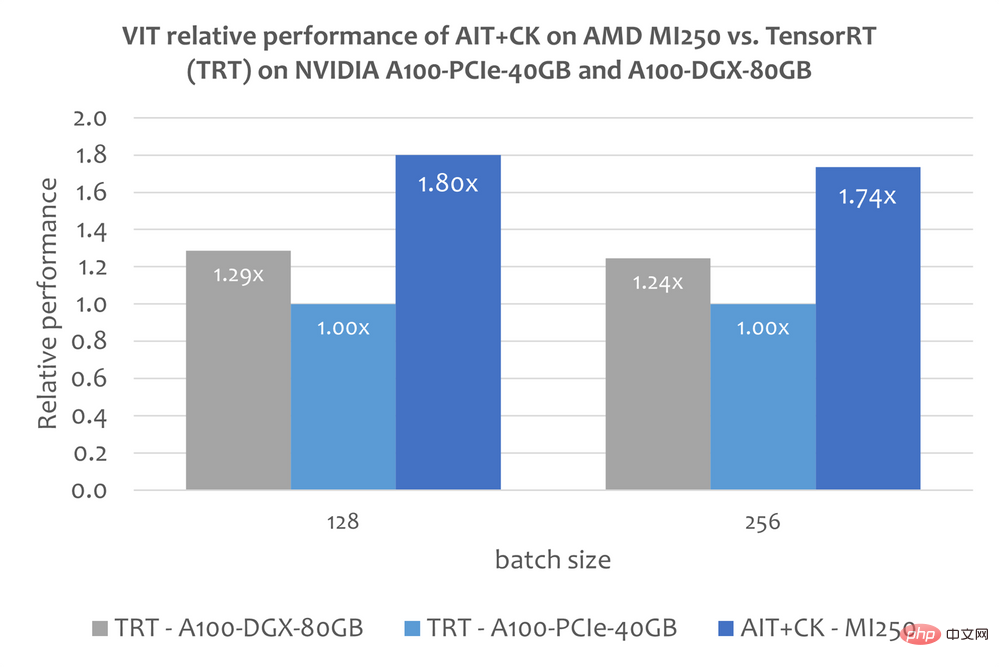
Vision Transformer (VIT)
The image below shows the AMD Instinct Performance comparison of AIT CK on MI250 with Vision Transformer Base (224x224 image) of TensorRT v8.5.0.12 (TRT) on A100-PCIe-40GB and A100-DGX-80GB. The results show that AIT CK on AMD Instinct MI250 achieves a 1.8x speedup compared to the TRT on A100-PCIe-40GB, and a 1.4x speedup compared to the TRT on A100-DGX-80GB.
##Stable Diffusion
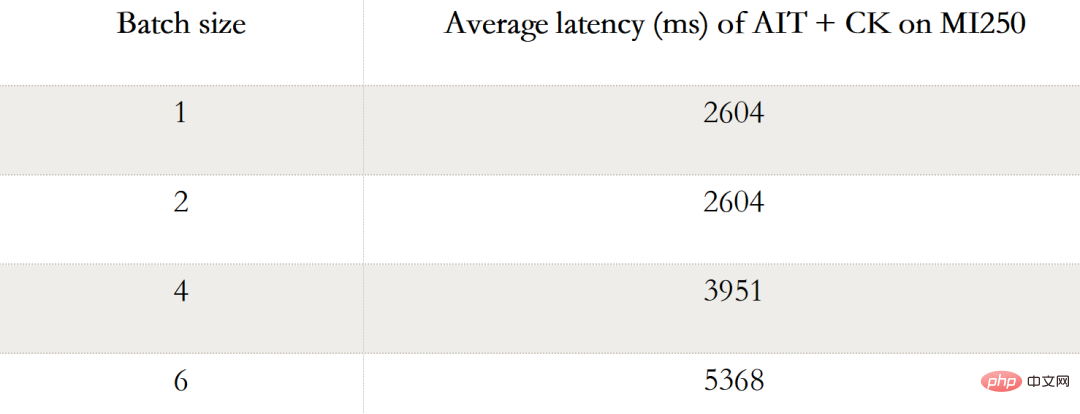
End-to-end Stable Diffusion
The following table shows the performance data of AIT CK Stable Diffusion end-to-end (Batch 1, 2, 4, 6) on AMD Instinct MI250. When Batch is 1, only one GCD is used on MI250, while in Batch 2, 4, and 6, both GCDs are used.
UNet in Stable Diffusion
#However, this article does not yet talk about using TensorRT to run Stable Diffusion end-to-end Public information about the end model. But this article "Make stable diffusion 25% faster using TensorRT" [14] explains how to use TensorRT to accelerate the UNet model in Stable Diffusion. UNet is the most important and time-consuming part of Stable Diffusion, so the performance of UNet roughly reflects the performance of Stable Diffusion.
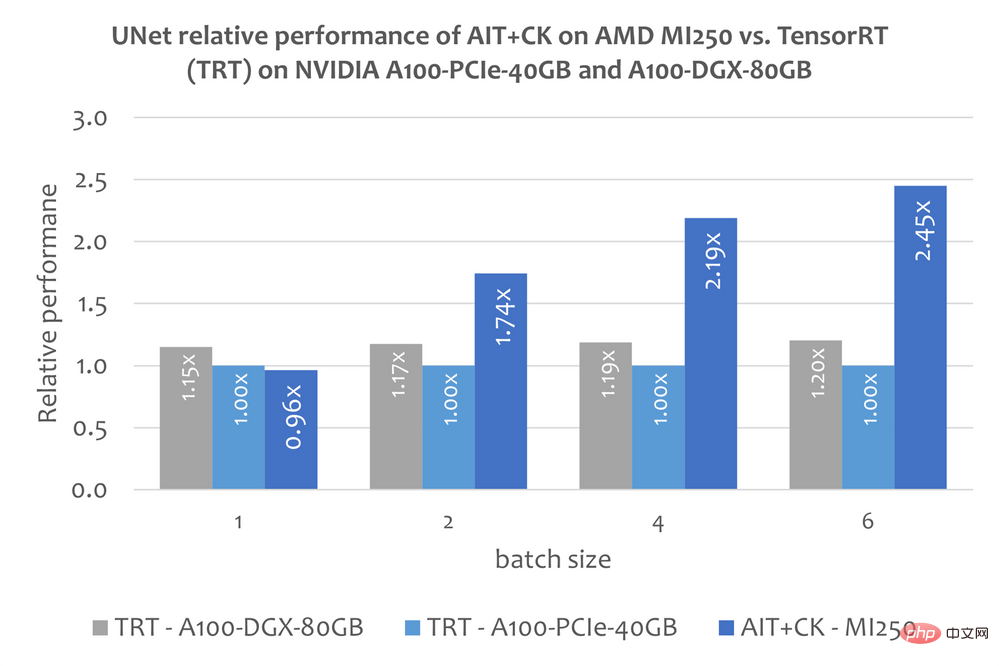
The graph below shows the performance of AIT CK on AMD Instinct MI250 versus UNet on A100-PCIe-40GB and A100-DGX-80GB with TensorRT v8.5.0.12 (TRT) Compare. The results show that AIT CK on AMD Instinct MI250 achieves a 2.45x speedup compared to the TRT on A100-PCIe-40GB, and a 2.03x speedup compared to the TRT on A100-DGX-80GB.
More information
##ROCm webpage: AMD ROCm™ Open Software Platform | AMD##ROCm Information Portal: AMD Documentation - Portal
AMD Instinct Accelerators: AMD Instinct™ Accelerators | AMD
AMD Infinity Hub: AMD Infinity Hub | AMD
Endnotes:
##1. Chao Liu is PMTS Software Development Engineer at AMD. Jing Zhang is SMTS Software Development Engineer at AMD. Their postings are their own opinions and may not represent AMD's positions, strategies, or opinions. Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied. GD-5
2.CK for CPU is in early development phase. 3.C APIs for now, Python APIs are under planning. 4.Example of CK “Client API” for GEMM Add Add FastGeLU fused operator. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 5.Example of CK “Templated Kernel and Invoker” of GEMM Add Add FastGeLU fuse operator. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 6.Example of using CK “Templated Tile Operator” primitives to write a GEMM pipeline. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 7.Meta’s AITemplate GitHub repository. https://github.com/facebookincubator/AITemplate 8.MI200-71: Testing Conducted by AMD MLSE 10.23.22 using AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate, commit f940d9b) Composable Kernel https://github.com/ROCmSoftwarePlatform/composable_kernel, commit 40942b9) with ROCm™5.3 running on 2x AMD EPYC 7713 64-Core Processor server with 4x AMD Instinct MI250 OAM (128 GB HBM2e) 560W GPU with AMD Infinity Fabric™ technology vs. TensorRT v8.5.0.12 and FasterTransformer (v5.1.1 bug fix) with CUDA® 11.8 running on 2x AMD EPYC 7742 64-Core Processor server with 4x Nvidia A100-PCIe-40GB (250W) GPU and TensorRT v8.5.0.12 and FasterTransformer (v5.1.1 bug fix) with CUDA® 11.8 running on 2xAMD EPYC 7742 64-Core Processor server with 8x NVIDIA A100 SXM 80GB (400W) GPU. Server manufacturers may vary configurations, yielding different results. Performance may vary based on factors including use of latest drivers and optimizations. 9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e 10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795... 11.TensorRT GitHub repository. https://github.com/NVIDIA/TensorRT 12.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. https://arxiv.org/abs/2205.14135 13.FasterTransformer GitHub repository. https://github.com/NVIDIA/FasterTransformer 14.Making stable diffusion 25% faster using TensorRT. https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/ 15.During their time in AMD
The above is the detailed content of Improve AI end-to-end performance through customized operator fusion. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 How to turn off win10gpu shared memory
Jan 12, 2024 am 09:45 AM
How to turn off win10gpu shared memory
Jan 12, 2024 am 09:45 AM
Friends who know something about computers must know that GPUs have shared memory, and many friends are worried that shared memory will reduce the number of memory and affect the computer, so they want to turn it off. Here is how to turn it off. Let's see. Turn off win10gpu shared memory: Note: The shared memory of the GPU cannot be turned off, but its value can be set to the minimum value. 1. Press DEL to enter the BIOS when booting. Some motherboards need to press F2/F9/F12 to enter. There are many tabs at the top of the BIOS interface, including "Main, Advanced" and other settings. Find the "Chipset" option. Find the SouthBridge setting option in the interface below and click Enter to enter.
 Do I need to enable GPU hardware acceleration?
Feb 26, 2024 pm 08:45 PM
Do I need to enable GPU hardware acceleration?
Feb 26, 2024 pm 08:45 PM
Is it necessary to enable hardware accelerated GPU? With the continuous development and advancement of technology, GPU (Graphics Processing Unit), as the core component of computer graphics processing, plays a vital role. However, some users may have questions about whether hardware acceleration needs to be turned on. This article will discuss the necessity of hardware acceleration for GPU and the impact of turning on hardware acceleration on computer performance and user experience. First, we need to understand how hardware-accelerated GPUs work. GPU is a specialized
 News says AMD will launch new RX 7700M / 7800M laptop GPU
Jan 06, 2024 pm 11:30 PM
News says AMD will launch new RX 7700M / 7800M laptop GPU
Jan 06, 2024 pm 11:30 PM
According to news from this site on January 2, according to TechPowerUp, AMD will soon launch notebook graphics cards based on Navi32 GPU. The specific models may be RX7700M and RX7800M. Currently, AMD has launched a variety of RX7000 series notebook GPUs, including the high-end RX7900M (72CU) and the mainstream RX7600M/7600MXT (28/32CU) series and RX7600S/7700S (28/32CU) series. Navi32GPU has 60CU. AMD may make it into RX7700M and RX7800M, or it may make a low-power RX7900S model. AMD is expected to
 Beelink EX graphics card expansion dock promises zero GPU performance loss
Aug 11, 2024 pm 09:55 PM
Beelink EX graphics card expansion dock promises zero GPU performance loss
Aug 11, 2024 pm 09:55 PM
One of the standout features of the recently launched Beelink GTi 14is that the mini PC has a hidden PCIe x8 slot underneath. At launch, the company said that this would make it easier to connect an external graphics card to the system. Beelink has n
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 AMD FSR 3.1 launched: frame generation feature also works on Nvidia GeForce RTX and Intel Arc GPUs
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 launched: frame generation feature also works on Nvidia GeForce RTX and Intel Arc GPUs
Jun 29, 2024 am 06:57 AM
AMD delivers on its initial March ‘24 promise to launch FSR 3.1 in Q2 this year. What really sets the 3.1 release apart is the decoupling of the frame generation side from the upscaling one. This allows Nvidia and Intel GPU owners to apply the FSR 3.
