
 Technology peripherals
AI
Achieving efficient and realistic ultra-large-scale city rendering: combining NeRF and feature grid technology
Technology peripherals
AI
Achieving efficient and realistic ultra-large-scale city rendering: combining NeRF and feature grid technology
Achieving efficient and realistic ultra-large-scale city rendering: combining NeRF and feature grid technology

Neural Radiation Field (NeRF) purely based on MLP often suffers from under-fitting in large-scale scene blur rendering due to limited model capacity. Recently, some researchers have proposed to geographically divide the scene and use multiple sub-NeRFs to model each area separately. However, the problem caused by this is that as the scene gradually expands, the training cost becomes linear with the number of sub-NeRFs. expand.
Another solution is to use voxel feature grid representation, which is computationally efficient and scales naturally to large scenes with increasing grid resolution. However, feature meshes often only achieve suboptimal solutions due to fewer constraints, producing some noise artifacts in rendering, especially in areas with complex geometry and textures.
In this article, researchers from the Chinese University of Hong Kong, Shanghai Artificial Intelligence Laboratory and other institutions propose a new framework to achieve high-fidelity rendering of urban (Ubran) scenes. Taking into account computational efficiency at the same time, it was selected for CVPR 2023. This study uses a compact multi-resolution ground feature plane representation to roughly capture the scene and supplements it with position-encoded inputs through a NeRF branch network for rendering in a jointly learned manner. This approach integrates the advantages of the two approaches: under the guidance of the feature grid representation, lightly weighted NeRF is enough to present a realistic new perspective with details; the jointly optimized ground feature plane can be further refined to form a more accurate and more detailed Compact feature space, output more natural rendering results.

- ##Paper address: https://arxiv.org/ pdf/2303.14001.pdf
- Project homepage: https://city-super.github.io/gridnerf/
The picture below is an example result of the research method on the real-world Ubran scene, giving people an immersive urban roaming experience:

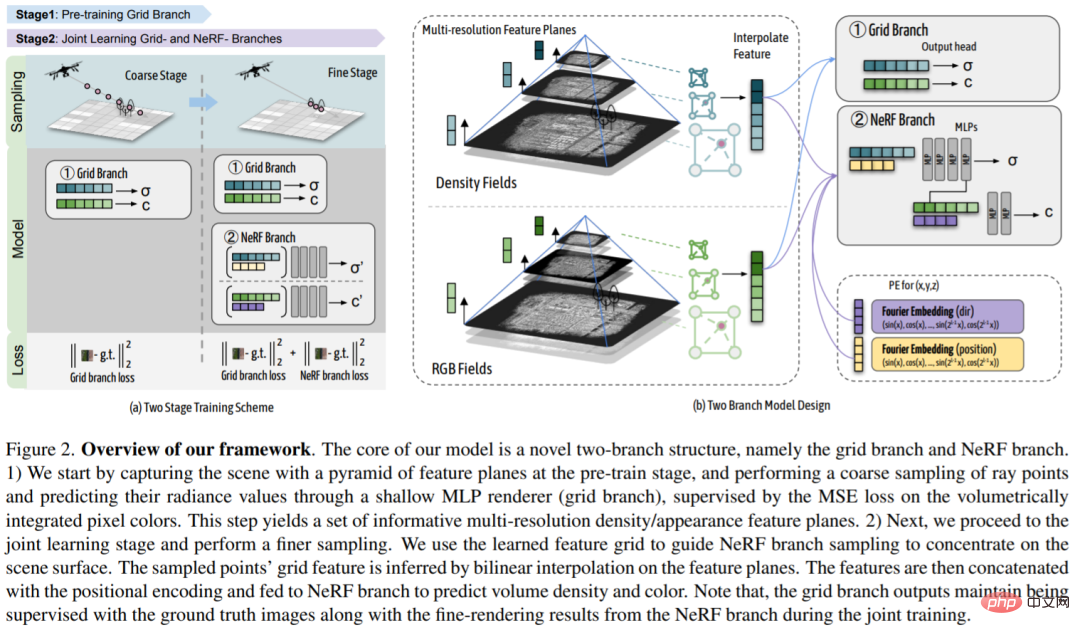
In order to effectively utilize implicit neural representation to reconstruct large urban scenes, this study proposes a dual-branch model architecture that adopts a unified scene representation and integrates explicit voxel grid-based and implicit-based NeRF methods, these two types of representations can complement each other.
The target scene is first modeled using feature meshes in the pre-training stage to roughly capture the geometry and appearance of the scene. A coarse feature grid is then used to 1) guide NeRF point sampling so that it is concentrated around the scene surface and 2) provide NeRF's positional encoding with additional features about the scene geometry and appearance at the sampled locations. With such guidance, NeRF can efficiently acquire finer details in a greatly compressed sampling space. Furthermore, since coarse-level geometry and appearance information are explicitly provided to NeRF, a lightweight MLP is sufficient to learn the mapping from global coordinates to volume density and color values. In a second joint learning stage, the coarse feature mesh is further optimized via gradients from the NeRF branch and normalized, resulting in more accurate and natural rendering results when applied alone.
The core of this research is a new dual-branch structure, namely the Grid branch and the NeRF branch. 1) The researchers first captured the pyramid scene of the feature plane in the pre-training stage, and roughly sampled the ray points through a shallow MLP renderer (grid branch) and predicted their radiance values by volume-integrated MSE on pixel color Loss supervision. This step generates an information-rich set of multi-resolution density/appearance feature planes. 2) Next, the researchers enter the joint learning stage and perform more refined sampling. The researchers used the learned feature grid to guide NeRF branch sampling to focus on scene surfaces. The grid characteristics of the sampling points are derived through bilinear interpolation on the feature plane. These features are then concatenated with position encoding and fed into the NeRF branch to predict volumetric density and color. Note that during joint training, the output of the grid branch is still supervised using ground truth images as well as fine rendering results from the NeRF branch.
Target scenario: In this work, the study uses a novel grid-guided neural radiation field to perform large urban Scene rendering. The left side of the image below shows an example of a large urban scene spanning a 2.7km^2 ground area captured by over 5k drone images. Studies have shown that NeRF-based methods render results that are blurry and over-smoothed and have limited model capacity, while eigengrid-based methods tend to show noisy artifacts when adapting to large-scale scenes with high-resolution eigengrids. The dual-branch model proposed in this study combines the advantages of both methods and achieves realistic novel view rendering through significant improvements over existing methods. Both branches obtain significant enhancements over their respective baselines.

Experiment
The researchers report the performance of the baseline and the researchers’ methods for comparison. Both qualitatively and quantitatively. Significant improvements can be observed in terms of visual quality and all metrics. The researchers' approach revealed sharper geometries and finer details than purely MLP-based methods (NeRF and Mega-NeRF). In particular, due to NeRF's limited capacity and spectral bias, it is always unable to simulate rapid changes in geometry and color, such as vegetation and stripes on a playground. Although geographically dividing the scene into small regions as shown in the Mega-NeRF baseline helps slightly, the presented results still appear too smooth. On the contrary, guided by the learned feature grid, the sampling space of NeRF is effectively and greatly compressed near the scene surface. Density and appearance features sampled from the ground feature plane explicitly represent scene content, as shown in Figure 3. Although less accurate, it already provides informative local geometry and texture and encourages NeRF's positional encoding to gather missing scene details.

Table 1 below shows the quantitative results:
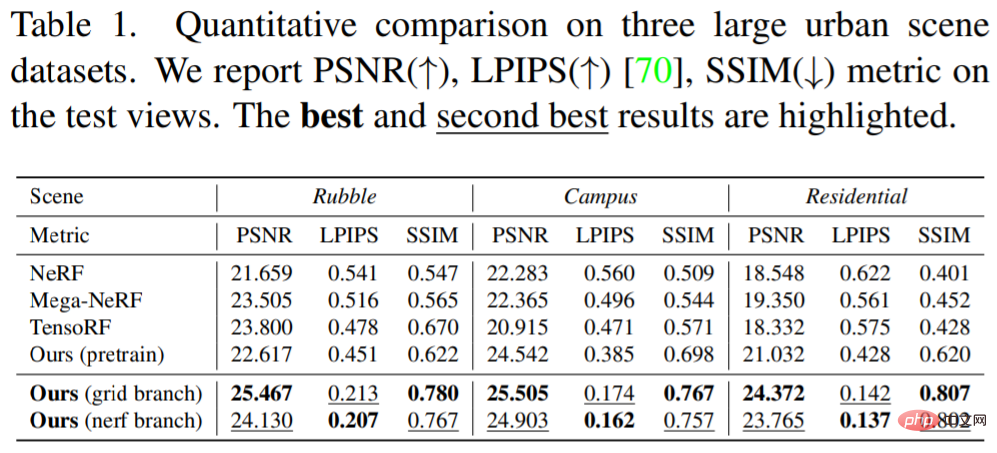
Figure 6 A rapid improvement in rendering fidelity can be observed:

# #For more information, please refer to the original paper.
The above is the detailed content of Achieving efficient and realistic ultra-large-scale city rendering: combining NeRF and feature grid technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to Undo Delete from Home Screen in iPhone
Apr 17, 2024 pm 07:37 PM
How to Undo Delete from Home Screen in iPhone
Apr 17, 2024 pm 07:37 PM
Deleted something important from your home screen and trying to get it back? You can put app icons back on the screen in a variety of ways. We have discussed all the methods you can follow and put the app icon back on the home screen. How to Undo Remove from Home Screen in iPhone As we mentioned before, there are several ways to restore this change on iPhone. Method 1 – Replace App Icon in App Library You can place an app icon on your home screen directly from the App Library. Step 1 – Swipe sideways to find all apps in the app library. Step 2 – Find the app icon you deleted earlier. Step 3 – Simply drag the app icon from the main library to the correct location on the home screen. This is the application diagram
 The role and practical application of arrow symbols in PHP
Mar 22, 2024 am 11:30 AM
The role and practical application of arrow symbols in PHP
Mar 22, 2024 am 11:30 AM
The role and practical application of arrow symbols in PHP In PHP, the arrow symbol (->) is usually used to access the properties and methods of objects. Objects are one of the basic concepts of object-oriented programming (OOP) in PHP. In actual development, arrow symbols play an important role in operating objects. This article will introduce the role and practical application of arrow symbols, and provide specific code examples to help readers better understand. 1. The role of the arrow symbol to access the properties of an object. The arrow symbol can be used to access the properties of an object. When we instantiate a pair
 From beginner to proficient: Explore various application scenarios of Linux tee command
Mar 20, 2024 am 10:00 AM
From beginner to proficient: Explore various application scenarios of Linux tee command
Mar 20, 2024 am 10:00 AM
The Linuxtee command is a very useful command line tool that can write output to a file or send output to another command without affecting existing output. In this article, we will explore in depth the various application scenarios of the Linuxtee command, from entry to proficiency. 1. Basic usage First, let’s take a look at the basic usage of the tee command. The syntax of tee command is as follows: tee[OPTION]...[FILE]...This command will read data from standard input and save the data to
 Explore the advantages and application scenarios of Go language
Mar 27, 2024 pm 03:48 PM
Explore the advantages and application scenarios of Go language
Mar 27, 2024 pm 03:48 PM
The Go language is an open source programming language developed by Google and first released in 2007. It is designed to be a simple, easy-to-learn, efficient, and highly concurrency language, and is favored by more and more developers. This article will explore the advantages of Go language, introduce some application scenarios suitable for Go language, and give specific code examples. Advantages: Strong concurrency: Go language has built-in support for lightweight threads-goroutine, which can easily implement concurrent programming. Goroutin can be started by using the go keyword
 The wide application of Linux in the field of cloud computing
Mar 20, 2024 pm 04:51 PM
The wide application of Linux in the field of cloud computing
Mar 20, 2024 pm 04:51 PM
The wide application of Linux in the field of cloud computing With the continuous development and popularization of cloud computing technology, Linux, as an open source operating system, plays an important role in the field of cloud computing. Due to its stability, security and flexibility, Linux systems are widely used in various cloud computing platforms and services, providing a solid foundation for the development of cloud computing technology. This article will introduce the wide range of applications of Linux in the field of cloud computing and give specific code examples. 1. Application virtualization technology of Linux in cloud computing platform Virtualization technology
 Understanding MySQL timestamps: functions, features and application scenarios
Mar 15, 2024 pm 04:36 PM
Understanding MySQL timestamps: functions, features and application scenarios
Mar 15, 2024 pm 04:36 PM
MySQL timestamp is a very important data type, which can store date, time or date plus time. In the actual development process, rational use of timestamps can improve the efficiency of database operations and facilitate time-related queries and calculations. This article will discuss the functions, features, and application scenarios of MySQL timestamps, and explain them with specific code examples. 1. Functions and characteristics of MySQL timestamps There are two types of timestamps in MySQL, one is TIMESTAMP
 Apple tutorial on how to close running apps
Mar 22, 2024 pm 10:00 PM
Apple tutorial on how to close running apps
Mar 22, 2024 pm 10:00 PM
1. First we click on the little white dot. 2. Click the device. 3. Click More. 4. Click Application Switcher. 5. Just close the application background.
 Google's new research on embodied intelligence: RT-H, which is better than RT-2, is here
Mar 11, 2024 pm 01:10 PM
Google's new research on embodied intelligence: RT-H, which is better than RT-2, is here
Mar 11, 2024 pm 01:10 PM
As large language models such as GPT-4 are increasingly integrated with robotics, artificial intelligence is gradually moving into the real world. Therefore, research related to embodied intelligence has also attracted more and more attention. Among many research projects, Google's "RT" series of robots have always been at the forefront, and this trend has begun to accelerate recently (see "Large Models Are Reconstructing Robots, How Google Deepmind Defines Embodied Intelligence in the Future" for details). In July last year, Google DeepMind launched RT-2, the world's first model capable of controlling robots for visual-language-action (VLA) interaction. Just by giving instructions in a conversational way, RT-2 can identify Swift in a large number of pictures and deliver a can of Coke to her. now,
