
 Technology peripherals
AI
Cui Peng, Tsinghua University: Trustworthy intelligent decision-making framework and practice
Technology peripherals
AI
Cui Peng, Tsinghua University: Trustworthy intelligent decision-making framework and practice
Cui Peng, Tsinghua University: Trustworthy intelligent decision-making framework and practice


1. A trusted intelligent decision-making framework
First of all, I would like to share with you a trusted intelligent decision-making framework. .
1. Decisions that are more important than predictions
In many actual scenarios, decisions are more important than predictions . Because the purpose of prediction itself is not just to predict what the future will look like, but to influence some key behaviors and decisions in the present through prediction.
In many fields, including the field of business sociology, decision-making is very important, such as continuous business growth (Continual business growth), discovery of new business opportunities (New business opportunity), etc., how to better support the final decision-making through data drive is a part of the work in the field of artificial intelligence that cannot be ignored.

2. Decision-making everywhere

Decision-making scenarios are everywhere. The well-known recommendation system, which recommends a product to a user, actually makes a selection decision among all products. Pricing algorithms in e-commerce, such as logistics service pricing, etc., how to set a reasonable price for a service; in medical scenarios, which drugs or treatments should be recommended according to the patient’s symptoms, these are all interventional Decision-making scenarios.
3. Common decision-making methods 1: Use the simulator to make decisions
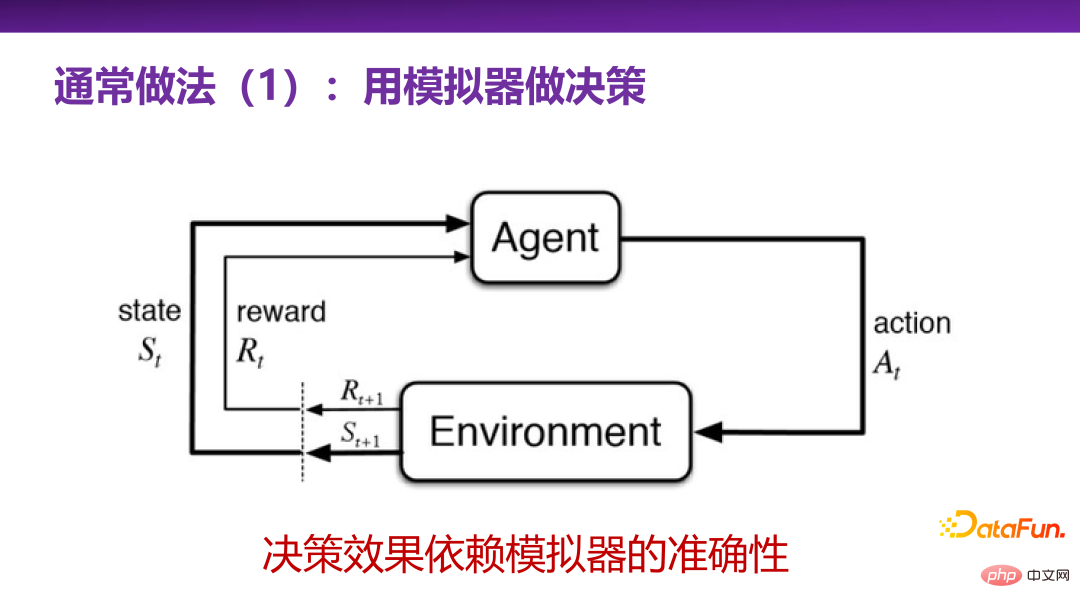
But the effect of decision-making depends on the accuracy of the prediction space, whether the prediction is accurate or not. Although in the prediction space, the target was hit 10 times, when applied to actual life or products, the number of hits was 0, which means that the prediction space is inaccurate. So far, the most confident scenario in prediction tasks is to make predictions under the assumption of independent and identical distribution, that is, the test distribution and the training distribution are the same distribution. There are many powerful predictions at present. Model (prediction model) can solve practical problems well. This tells us: Whether the prediction accuracy is good or not depends to some extent on whether the distribution of test data and training data in the actual scenario satisfies independent and identical distribution.
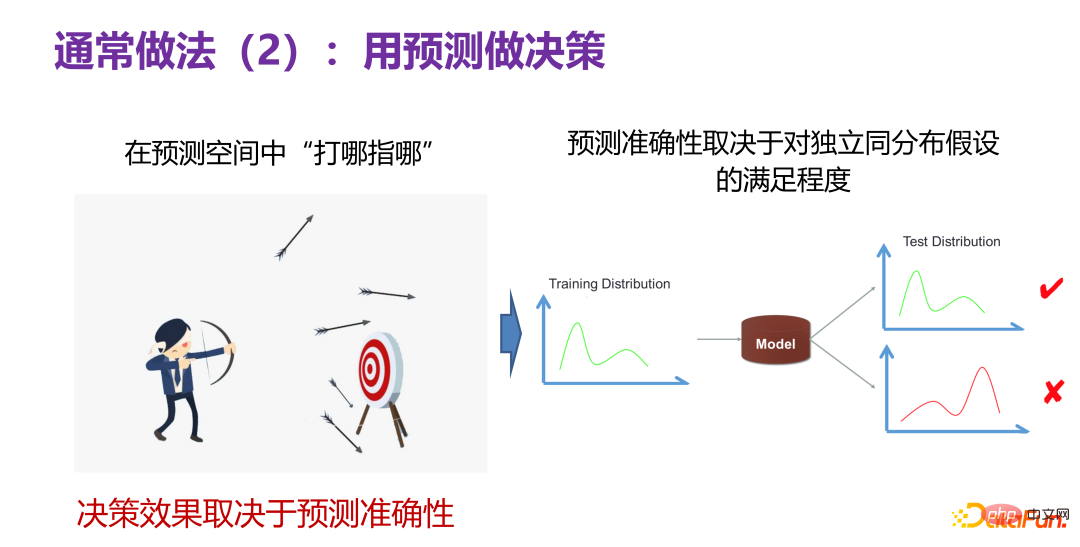
#Continue to think deeply about the accuracy of predictions. Assume that a prediction model is constructed based on historical data P(X,Y), and then explore the benefits brought by some different key behaviors, that is, shooting multiple arrows as mentioned above to see which one has the largest number of targets. Breaking it down, it can be divided into two different situations.
The first category is to optimize the value of a given decision variable. If you know in advance which of the input variables X is a better decision variable, for example, if price is a decision variable in What happens after the value is obtained.
The other type is to seek the optimal decision variables and optimize their values. It is not known in advance which one of The value predicted by the prediction model is good.
Based on this premise assumption, when changing the value of the decision variable, P(X) is actually changed, that is, if P(X) changes, P(X,Y) will definitely change. , then the assumption of independent and identical distribution itself is not valid, which means that the prediction is actually very likely to fail. Therefore, if the decision-making problem is solved in a predictive manner, it will trigger the problem of out-of-distribution generalization, because changing the value of the decision variable will inevitably cause a distribution shift. In the case of distribution deviation, how to make predictions belongs to the category of prediction problems of out-of-distribution generalization, and is not the topic of today's article. If the prediction problem of out-of-distribution generalization can be solved in the prediction field, using prediction to make decisions is also one of the feasible paths. However, the current use of ID (In-Distribution) or direct prediction (direct prediction) methods to make decisions is theoretically invalid and problematic.
5. The decision-making problem is a causal category
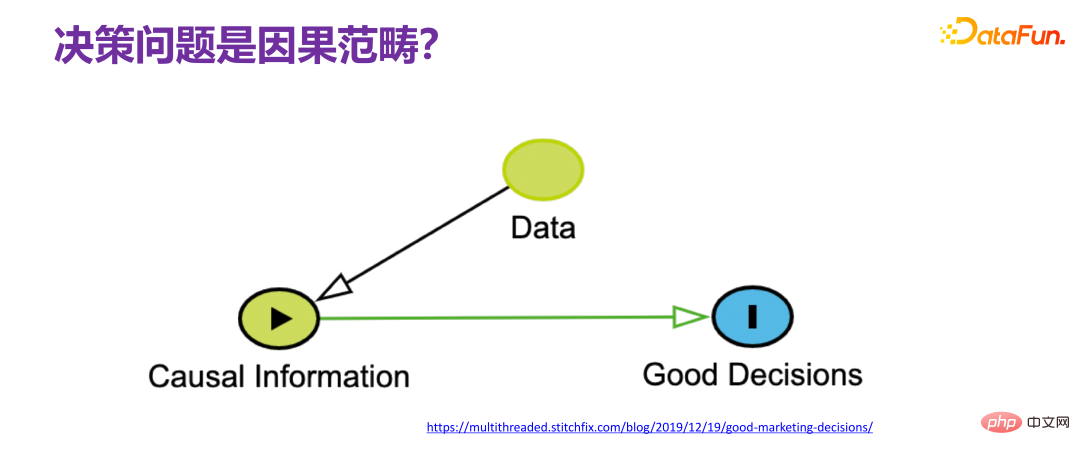
##When talking about decision-making issues, we usually directly link the decision-making issue with cause and effect. The so-called decision-making means what kind of decision to make. We must ask why such a decision is made. It is obvious that there is a cause-and-effect chain. Many scholars in the academic world The consensus is that to solve decision-making problems, causation cannot be avoided, that is, we must obtain sufficient causal information from observable data and understand the relevant causal mechanism. ), and then design some strategies for final decision-making based on the causal mechanism. If we can understand the entire process thoroughly, we can perfectly restore the entire causal mechanism, so decision-making is not a problem, because it is actually equivalent to having a God's perspective, and there is no challenge in decision-making.
6. A framework description of decision-making
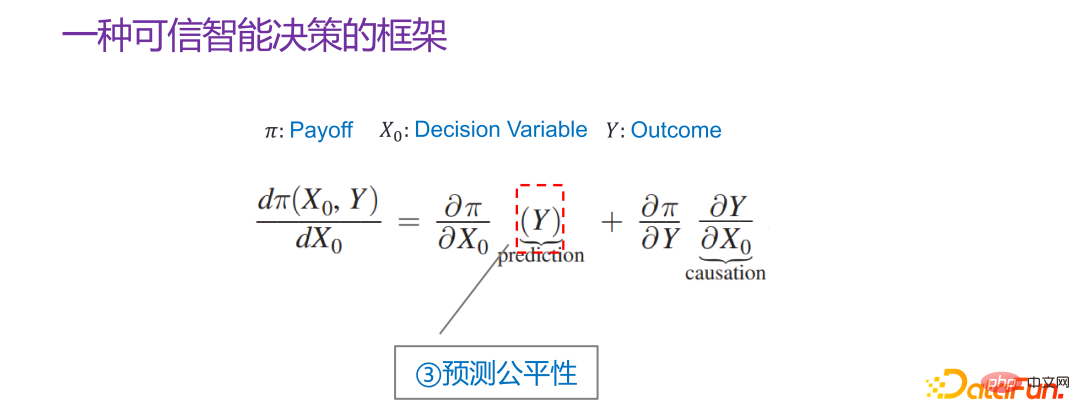
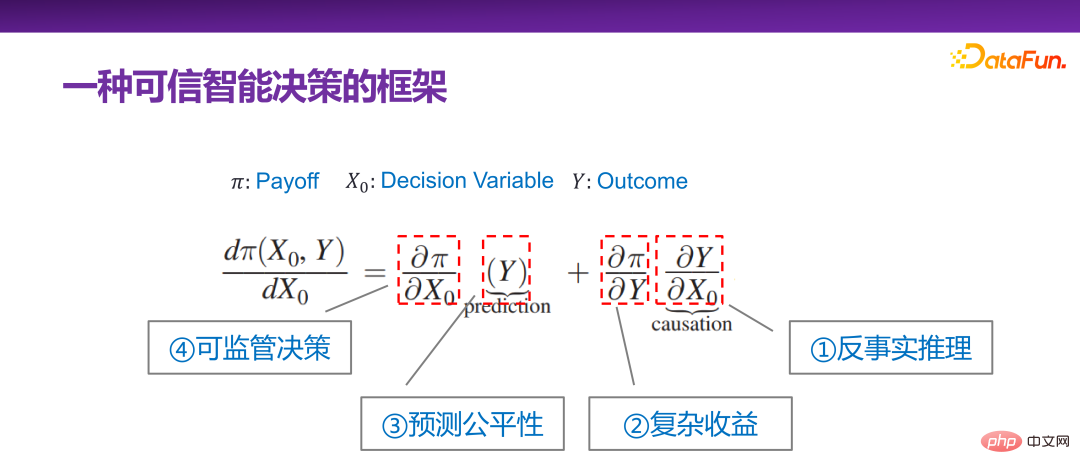
## As early as 2015, Jon Kleinberg Published in a paper: Decision-making problems cannot only be solved by causal mechanisms, that is, not all decision-making problems require causal mechanisms to solve. Jon Kleinberg is a well-known professor at Cornell University. The famous hits algorithm, six-degree style theory, etc. are all Jon Kleinberg's research results. Jon Kleinberg published a paper on decision-making problems in 2015, "Prediction Policy Problems"[1]. He believed that some decision-making problems are prediction strategy problems, and to prove this argument, he gave a framework description of decision-making, as shown in the figure below.
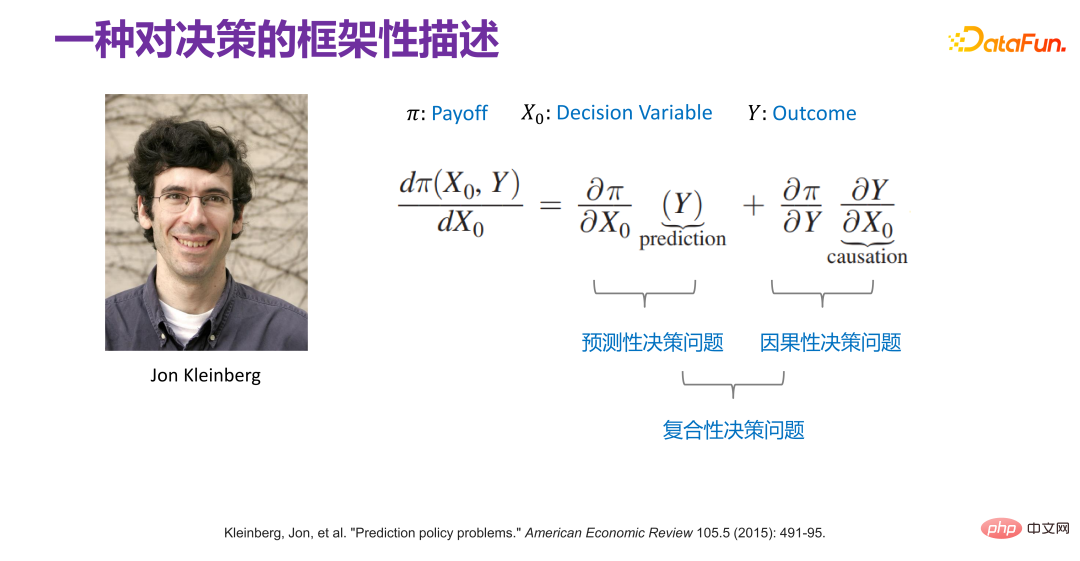
##Π is the payoff function, x0 is the decision variable (Decision Variable), Y is the result (Outcome) due to the decision variable ), Π is actually a function of x0 and Y. Then how x0 changes, Π is the largest, you can find such a derivative: 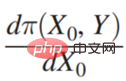 Then expand it is: After
Then expand it is: After 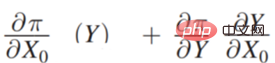 is expanded, depending on whether Y and
is expanded, depending on whether Y and
7. Two cases of decision-making scenarios

As shown in the figure above, there are two decision-making scenarios, where x#0 is the decision variable, and the definitions in the two scenarios are respectively different.
# First look at the scene case on the left. Whether or not you need to bring an umbrella has nothing to do with whether it rains, that is, x0 has nothing to do with Y, so bring it to In 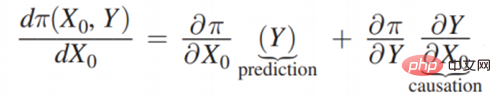 , that is:
, that is: 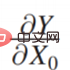 is 0, then:
is 0, then: 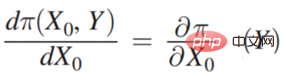 Then the final income will be different if it predicts whether it will rain. So this example is clearly a prediction decision.
Then the final income will be different if it predicts whether it will rain. So this example is clearly a prediction decision.
#The case on the right is that if you are a chief, whether you want to pay someone to dance to pray for rain actually depends largely on "Dancing to the God" "Whether it is possible to pray for rain or not, and whether it has a causal effect.  on the right side of the equation, if it can be predicted whether it will rain or not, then:
on the right side of the equation, if it can be predicted whether it will rain or not, then: 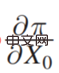 is 0, that is, there is actually no relationship between the income (whether it rains or not) and the decision variable (whether to jump or not). Then this is not a predictive decision, but a purely causal decision.
is 0, that is, there is actually no relationship between the income (whether it rains or not) and the decision variable (whether to jump or not). Then this is not a predictive decision, but a purely causal decision.
Through the above two actual decision-making case scenarios, decision-making problems can be divided into two categories: predictive decision-making and causal decision-making, and the framework of decision-making problems given by Jon Kleinberg, Also a good illustration of the compartmentalization of decisions.
8. The complexity of decision-making

Jon Kleinberg’s paper One point of view given is that for predictive decision-making problems, it only matters whether the prediction is good or not. The causal mechanism is not necessarily necessary. Predictive models are very useful in decision-making scenarios and have good expressive ability for decision-making problems. They can put A lot of situations come together. But the actual complexity of decision-making is beyond previous understanding of forecast scenarios. In most cases, when solving prediction problems, we just try our best (best effort), try to use more complex models and more data, hoping to improve the final accuracy, that is, best effort model (best effort model) .
#But there are far more constraints in decision-making scenarios than predictions. Decision-making is actually the last mile. The final decision will indeed affect all aspects, affect many stakeholders, and involve very complex social and economic factors. For example, in the same loan, whether there is discrimination against people of different genders and different regions is a typical issue of algorithmic fairness. Big data is familiar, and the same product has different prices for different people, which is also a problem. In recent years, everyone has a deep understanding of information cocooning, which is to continuously recommend a user based on the user's interests or interests in a relatively narrow spectrum, which will form an information cocooning room. If things go on like this, some bad cultural and social phenomena will appear. Therefore, when making decisions, more factors must be considered to make credible decisions.
9. A framework for credible intelligent decision-making
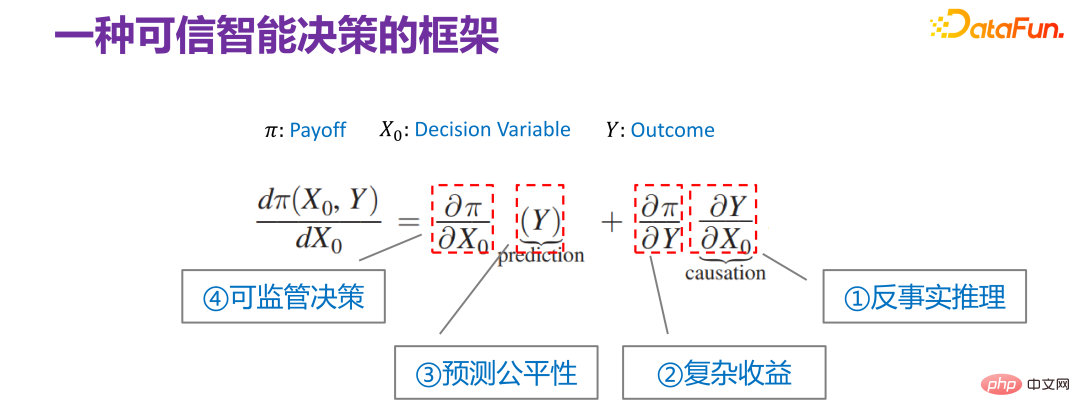
Continue to interpret the decision-making problem framework given by Jon Kleinberg from the perspective of decision-making credibility. Although Jon Kleinberg himself proposed this decision-making problem framework to advocate the effectiveness of the prediction model for decision-making problems, in fact the connotation of the decision-making problem framework is very rich. The following is an explanation of each item of the decision-making problem framework.
First of all is the rightmost item: 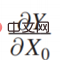
is actually equivalent to the relationship between the income function and the model results. There are simpler scenarios for the relationship between Y and Π. For example, when recommending products, what kind of products are recommended to users and users click on them? The final optimized payoff function is actually the overall click-through rate. This is a scenario where the relationship between the two is relatively simple. However, in actual business, whether from a platform or regulatory perspective, the relationship between Y and Π is very complicated in most cases. For example, in a case that will be discussed later, when optimizing the platform's revenue, you can't just look at the current click-through rate, but also the long-term revenue. When looking at the long-term revenue, the relationship between Y and Π will be relatively complicated, that is, complex revenue. .
The third item is Y. The core task is to make predictions, but if predictions are used to make decisions, and Decision-making scenarios are of social nature, such as affecting personal credit, whether one is admitted to the college entrance examination, whether a prisoner will be released, etc. Then all these so-called predictive tasks require that the prediction must be fair. You cannot use some sensitive dimensional variables, such as gender, race, identity, etc., for prediction.
The fourth item is: 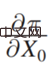
This decision-making problem framework contains scenarios at different levels, and it can also be considered to have the above four different sub-directions. But in general, the above four sub-directions are very related to believable decision-making, that is, if you want to ensure that the character is believable, all aspects of factors must be considered. But generally speaking, it can be expressed uniformly using the framework given by Jon Kleinberg.
#The following will introduce the four sub-directions under the trusted intelligent decision-making framework: counterfactual reasoning, complex benefits, predictive fairness and regulatory decision-making.
2. Counterfactual reasoning in trusted intelligent decision-making
First introduce the information about the trusted intelligent decision-making framework Some thoughts and practices on counterfactual reasoning.

##1. Counterfactual reasoning

There are three scenarios for counterfactual reasoning.
The first is the average effect evaluation of the strategy (Off-Policy Evaluation). For a given policy, we do not want to conduct AB testing because the cost of AB testing is too high. Therefore, evaluating the effect of the policy on offline data is equivalent to testing the entire population. Or evaluate all samples, such as an overall effect evaluation for all user groups. The second is the individual effect evaluation of the strategy (Counterfactual Prediction), which is to predict the effect of the strategy at an individual level. It is not an overall platform strategy, but after a certain intervention is carried out for an individual, there will be What kind of effect. The third is Policy Optimization, that is, how tochoose the intervention with the best effect for an individual. Different from individual effect prediction, individual effect prediction is to first know how to intervene, and then predict the effect after intervention; strategy optimization is to not know in advance how to intervene, but to find out how to achieve the best effect after intervention.
2. Strategy average effect evaluation
(1) Overview of the problem framework for strategy average effect evaluation
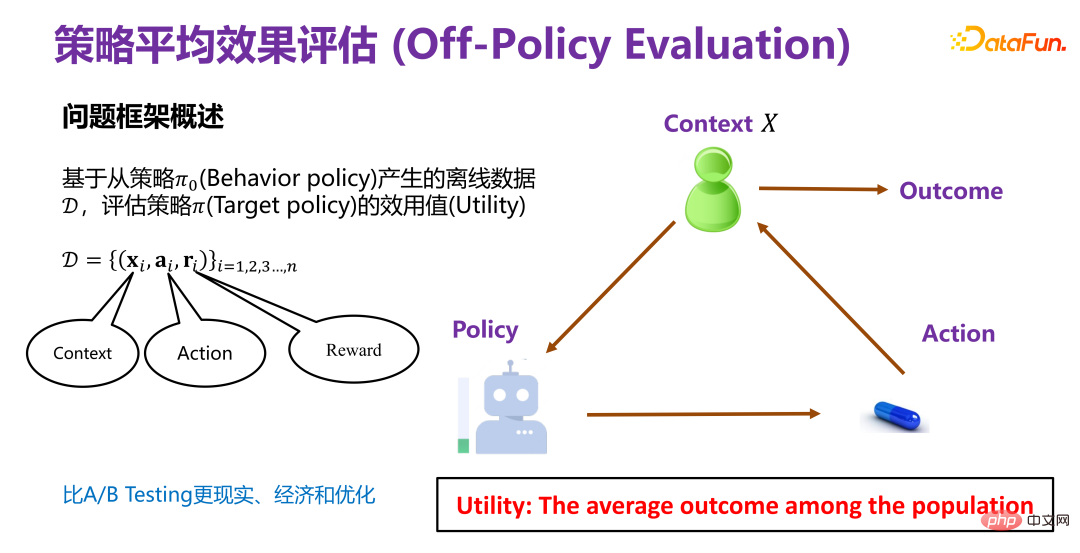
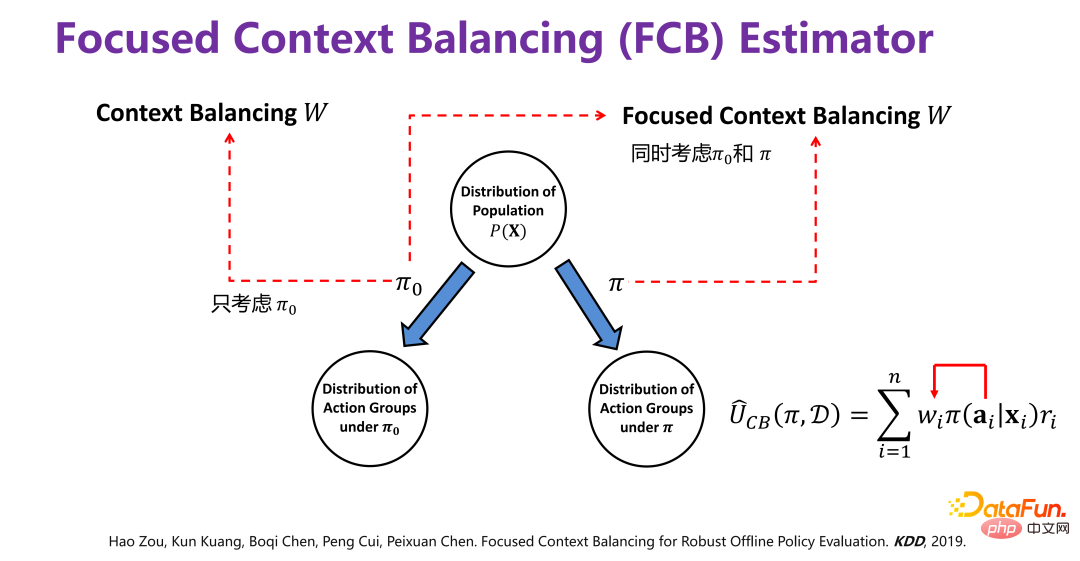
The average effect evaluation of the strategy is based on the behavior policy Π0(Behavior policy ) generates offline data D to evaluate the utility value (Utility) of the policy Π (Target policy).
Π0 is an existing strategy, such as the recommendation strategy that has been used in existing recommendation systems.
The offline data D generated under the existing strategy contains at least three dimensions, as shown in the figure above, x i is the background information (Context), such as the attributes of users and products in the recommendation system; a#i is the behavior, such as recommendations Whether a certain product in the system has been exposed to the user; ri is the final result (reward), such as whether the user finally clicked or purchased the product in the recommendation system.
#Evaluate the utility value (Utility) of a new policy Π (Target policy) based on historical data. So the overall framework is that in a certain context, a certain strategy (policy) will have a corresponding behavior or intervention variable (treatment). When this intervention variable (treatment) is triggered, it will produce corresponding results. Among them, the utility value (Utility) is the aforementioned payoff. Under the premise of simplification, the utility value is the sum of the results generated by all users, or the average effect.
(2) Existing methods for evaluating the average effect of strategies

The traditional strategy average effect evaluation method is based on the result prediction method (Direct Method). Given xi under the new policy (policy), for the subject, it is recommended to expose or not expose, that is, the corresponding behavior must be predicted if it is performed. Exposure, whether the end user will buy or click, is the final result (reward). But please note that reward is actually a prediction function, which is obtained through historical data. The joint distribution of x, a and r in the historical data was actually generated under Π0. Now the data distribution generated by Π is changed, and then the joint distribution prediction model generated under Π0 is used. model) to make predictions, it is obvious that this is an OOD (Out-of-Distribution) problem. If an OOD prediction model is used later, the data distribution offset problem may be alleviated. If an ID (In-Distribution) prediction model is used , in principle there will definitely be problems. This is the traditional method of evaluating the average effectiveness of strategies.
Another method is based on causal inference and introduces the propensity score. The core idea is to use the triplet (xi, ai, ri) under the original strategy under the new strategy , what kind of weight should be used to weight the final result. The weight should be the ratio of the probability of exposure (ai) of xi under the new strategy to the probability of exposure (ai) of xi under the original strategy given xi, that is, under the new strategy, the result corresponding to a triplet A coefficient for weighting. The most difficult part of this approach is that under the original strategy, after xi is given, the probability distribution corresponding to ai is actually unknown, because the original strategy may be very complex, or it may be a superposition of multiple strategies, and there is no way to reveal it. The corresponding distribution must be accurately described, so it needs to be estimated, then there will be a problem of whether the estimation is accurate, and the estimated value is on the denominator, which will cause the distribution variance of the entire method to be very large. In addition, there are problems in using the estimation of the propensity score (propensity score). It is assumed that the function of the propensity index (propensity score) is linear or non-linear, what form it is, whether the estimation is accurate, etc.
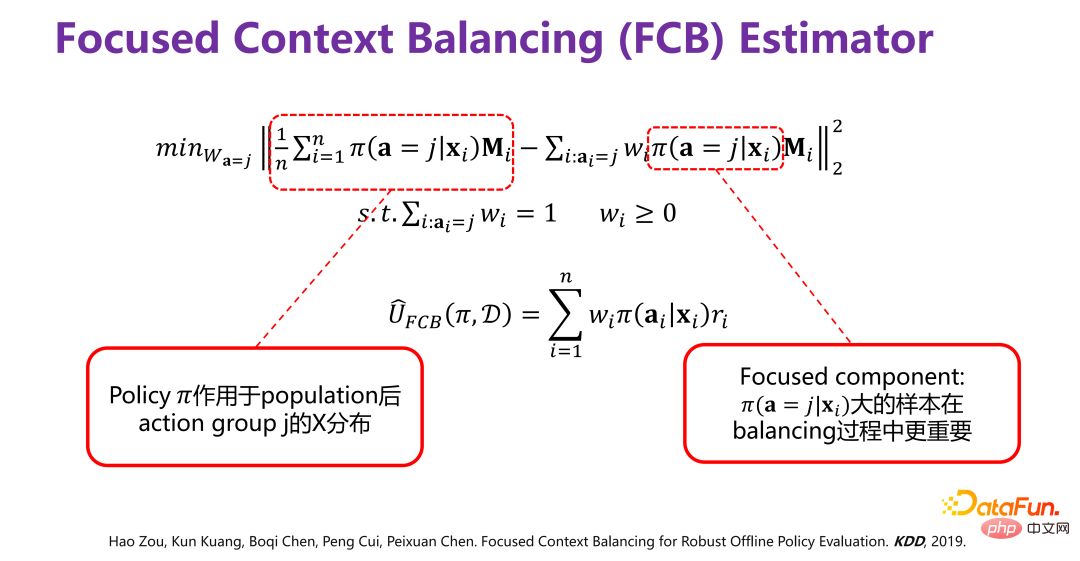
(3) New method for strategy average effect evaluation: FCB estimator
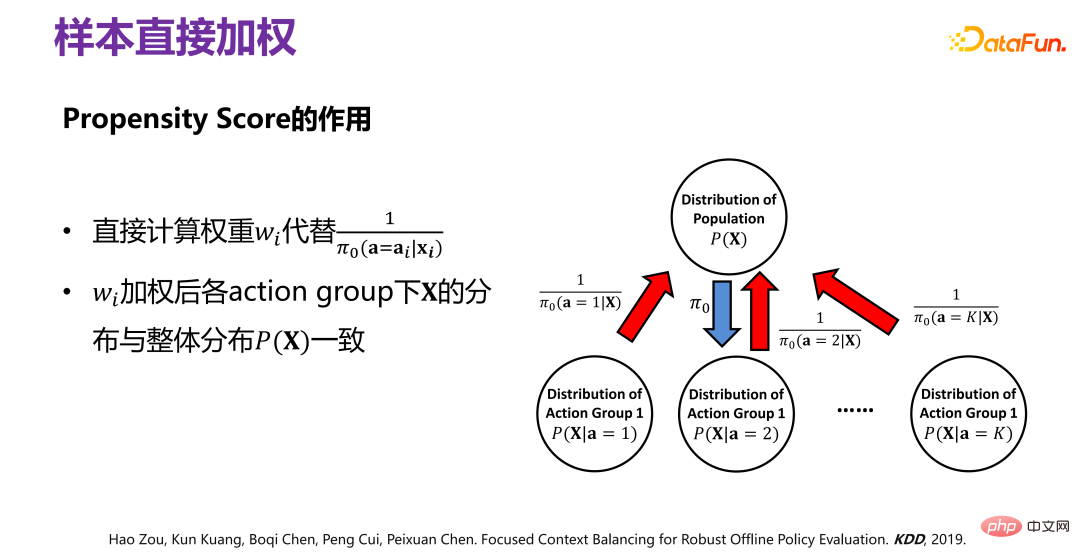
Drawing on the directly confounder balancing of Causality, a method of directly weighting samples is proposed, so that after weighting, the distribution P(X|# in each corresponding action group) can be guaranteed. ##ai) is consistent with P(X) on the whole.
Historical data is generated under the given Π0. To remove the reason Π0 Distribution deviation (bias) caused by, the specific method is shown in the figure above. The original data distribution P(X), under the action of Π0, is equivalent to changing P( X) is divided into several sub-distributions P(X|a=1), P(X|a=2), P(X|a=3),..., P(X|a=K), that is, different A subset of behavior corresponding to P(X) is an unbiased distribution. Each behavior group has a bias caused by Π0. To remove the bias, you can By reweighting the historical data generated by Π0, all sub-distributions after weighting are close to the original distribution P(X), that is, the samples are directly weighted.
Predicting the final effect of a new strategy based on historical data requires two steps. The first step is to remove the bias caused by the original strategy Π0 by directly weighting the samples as mentioned above. The second step is to predict the effect of the new strategy Π, that is, to estimate the final effect based on the deviation caused by the new strategy Π, so it is necessary to add the deviation caused by the new strategy Π 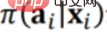
therefore:
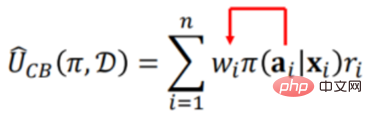
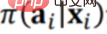
is equivalent to adding the deviation of the new strategy, so that the final result of a new strategy can be predicted Effect. The specific method will not be described in detail, but you can refer to the paper [2].
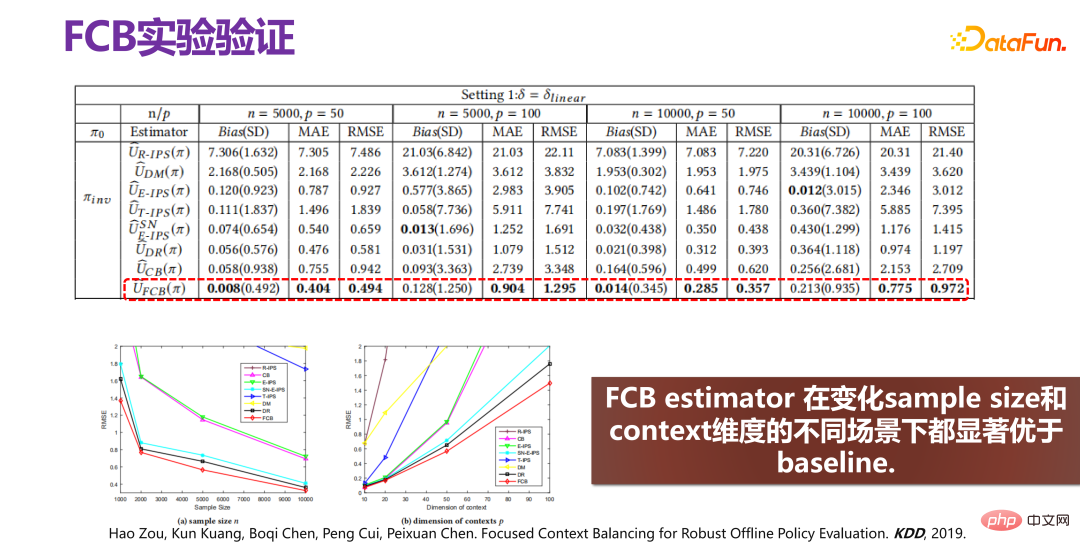
The final improvement effect of the new method FCB Estimator is as shown in the figure above. The effect is very obvious, whether in terms of bias or RMSE, the relative improvement is about 15%-20%. FCB Estimator is significantly better than baseline in different scenarios with varying sample size and context dimensions. Related papers were published in KDD 2019 [2].
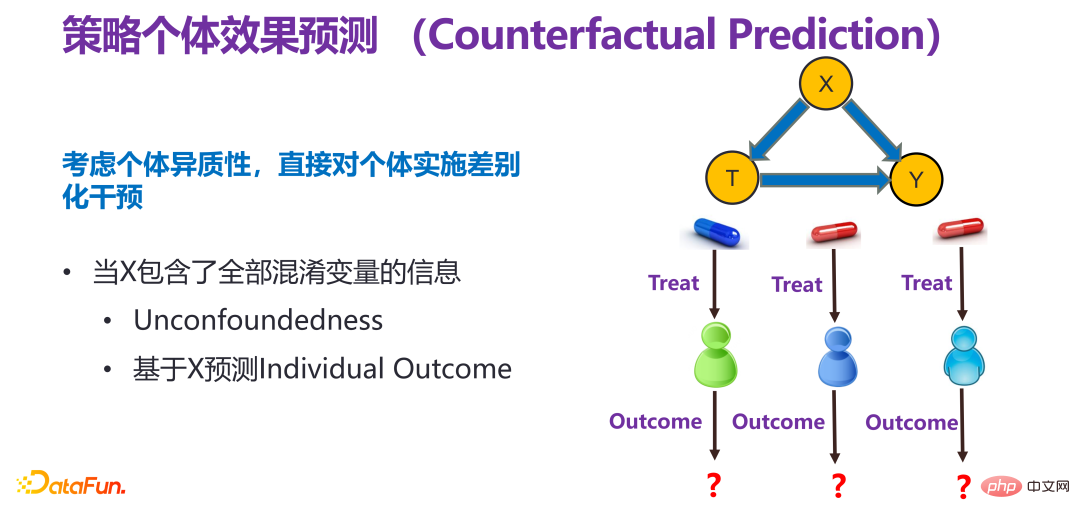
3. Strategy individual effect prediction
(1) Overall description of strategy individual effect prediction
Strategic Individual effect prediction is to fully consider individual heterogeneity and directly implement differentiated intervention for individuals, that is, respect individual will and implement different interventions for different individuals.
(2) Limitations of existing methods
The commonly used method for predicting individual effect of strategies is to directly predict and model individuals, that is, based on historical observation data: 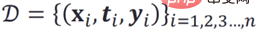 Then train to get the counterfactual prediction model:
Then train to get the counterfactual prediction model: 
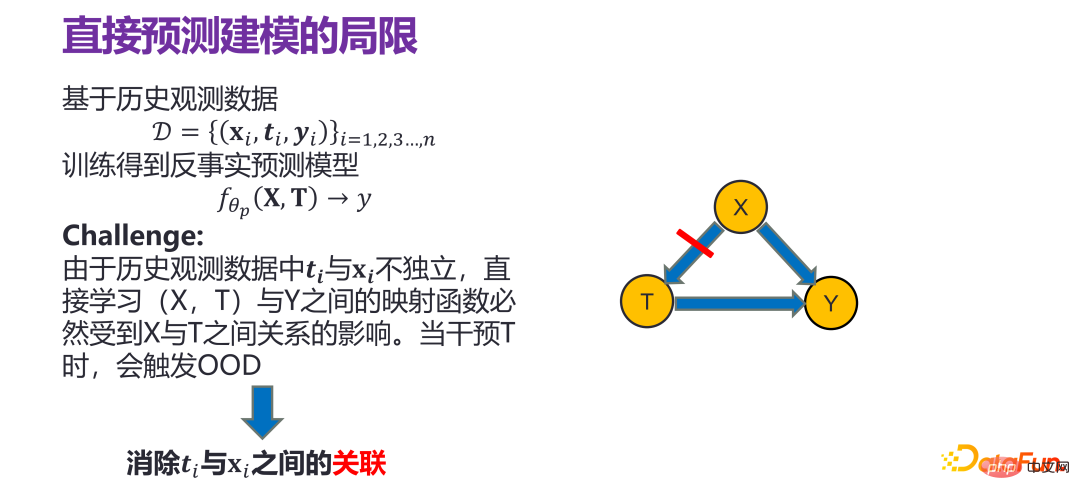
If you do regression analysis or similar models directly under the distribution of historical data, yes problematic. Because ti and xi in historical observation data are not independent, directly learn the direct mapping between (X, T) and Y The function must be affected by the relationship between #i, for example, ti should be equal to 0. When intervening with T, for example, ti must be changed If it becomes 1, it actually no longer obeys the original historical distribution, which means that the ID (In-Distribution) prediction model constructed under the historical data distribution is invalid and triggers OOD (Out-of-Distribution). Therefore, when constructing the so-called prediction model, it is necessary to eliminate the correlation between X and T, and estimate the impact of X on Y and the impact of T on Y respectively. Influence, in this case, if T is intervened or changed, it has nothing to do with Distribution) problem.
The traditional approach is to use sample re-weighting (Sample Re- weighting) method to remove the association between X and T, there are two methods: (1) inverse propensity score weighting, (2) variable balancing. However, these methods have limitations: they are only suitable for simple types of intervention variable (treatment) scenarios, binary or discrete values. In real application scenarios, such as recommendation systems, the intervening variable (treatment) has a high dimension, and products are recommended to users. What is recommended is a bundle, that is, recommendations are made from many products. When the dimension of the intervening variable (treatment) is very high, using traditional methods to directly correlate the initial intervening variable (raw treatment) and the confounding variable (confounder) X is very complex, and even the sample space is not enough to support the high dimension. The intervening variable (treatment).

(3) New method for predicting the individual effect of strategies: VSR
If it is assumed that the high-dimensional intervening variable (treatment) has a low-dimensional latent variable structure, that is, the high-dimensional intervening variable (treatment) is not randomly generated in principle. For example, in a recommendation system, a given recommendation In the product bundle recommended by the strategy, there are various relationships between the products and products, and there is a low-dimensional hidden variable structure, that is, the recommended product list is determined by several factors.
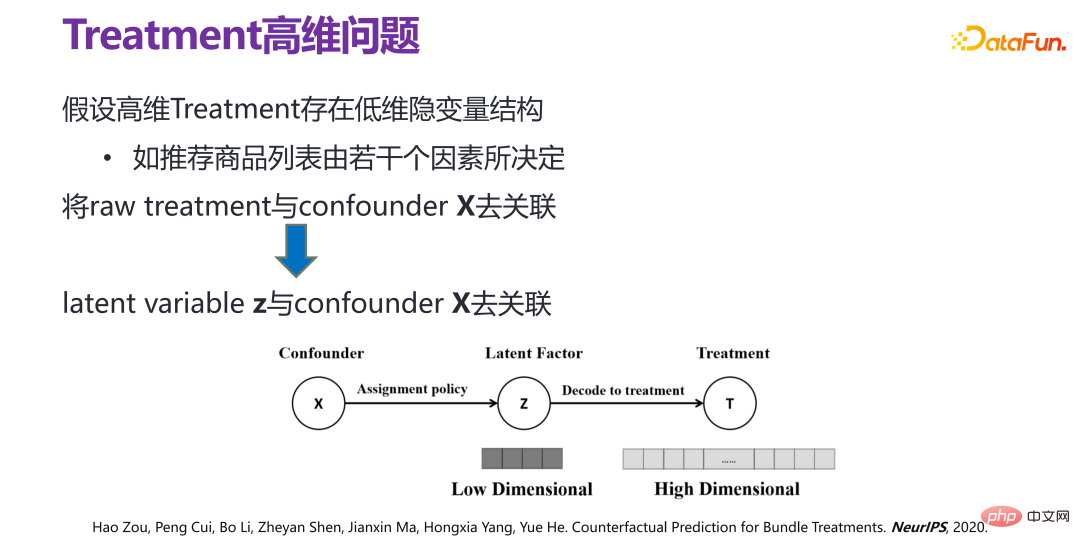 If there is a latent variable z under the high-dimensional intervening variable (treatment), the problem can actually be transformed into a relationship between x and z De-correlation, that is, de-correlation with latent factors. In this way, bundle treatment can be achieved with limited sample space.
If there is a latent variable z under the high-dimensional intervening variable (treatment), the problem can actually be transformed into a relationship between x and z De-correlation, that is, de-correlation with latent factors. In this way, bundle treatment can be achieved with limited sample space.
Therefore, a new method VSR is proposed. In the VSR method, the first step is to learn the latent variable z (latent variable z) of the high-dimensional intervention variable (treatment), that is, using a variational autoencoder (VAE) for learning; then the weight function w ( x, z), decorrelate x and z through sample reweighting; finally, directly use the regression model (regression model) under the reweighted correlation distribution to get a more ideal A prediction model for the individual effect of strategies.
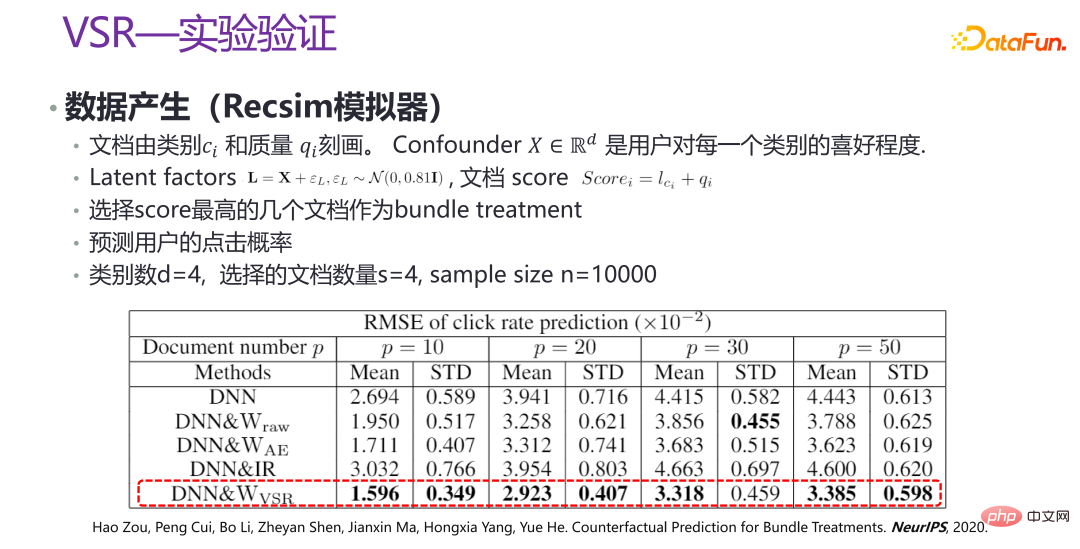
##The picture above is an experiment of the new method VSR Verification is to generate some data through the Recsim simulator and some artificially simulated data in some scenarios for verification. It can be seen that under different values of p, the performance of VSR is relatively stable, which is greatly improved compared to other methods. Related papers were published in NeurIPS 2020 [3].
4. Strategy Optimization
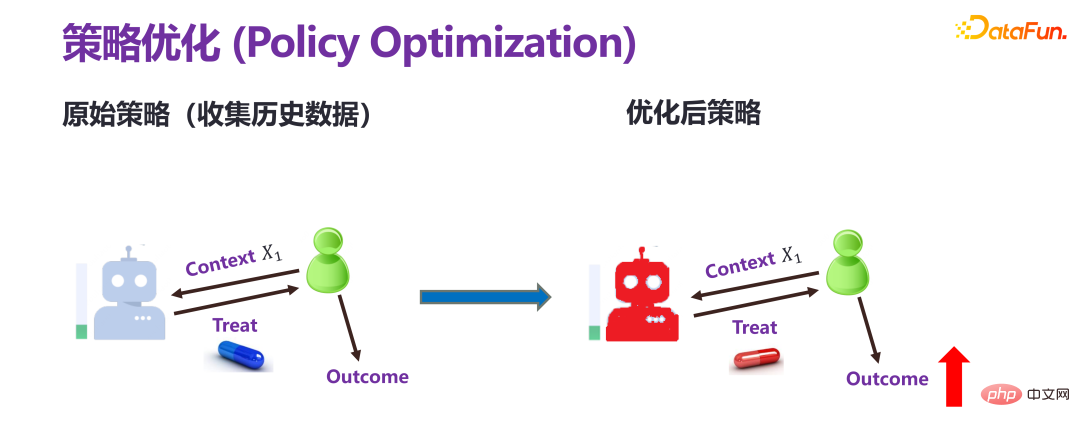
##Strategy Optimization is fundamentally different from the previous two types of predictive evaluation. Predictive evaluation is to give a strategy (policy) or personalized intervention (individual treatment) in advance to predict the final result. Strategy optimization, also called strategy learning, has only one goal: getting bigger results. For example, if income is to increase, what kind of intervention should be implemented.
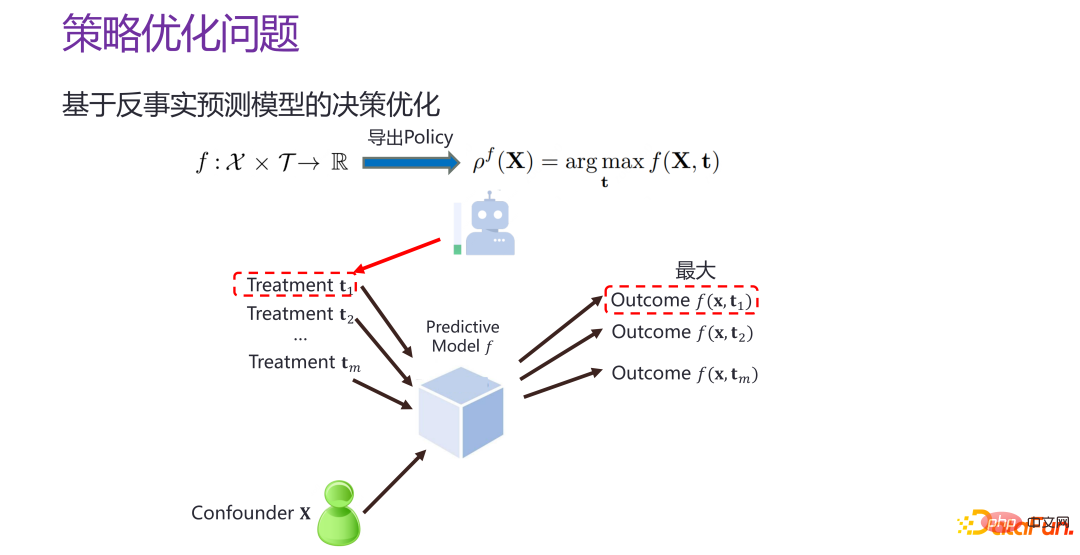
If there is now a counterfactual individual-level prediction model f, that is, the strategic individual Effect prediction model f, that is, given xi and ti, the corresponding results can be estimated, and then the T is traversed, and when t takes any value, the value of f is the largest. It is equivalent to constructing a better prediction space and "targeting where to hit" in the prediction space.
#But there is a problem in reducing the policy optimization problem to the construction of a prediction model for the individual effect of the policy. The goal of individual effect prediction of strategies, as mentioned above, is actually equivalent to given an intervention, hoping that the error between the counterfactual predicted situation and the real situation is as small as possible, and for all given interventions, we hope to compare precise. The goal of strategy optimization is to find the pf point away from the real situation From God's perspective, the smaller the distance between the results of optimal decision-making, the better. It is not a question of predicting the individual effects of strategies in the entire space, but whether a region close to the optimal point can be found, and whether it can be accurately predicted. Best point. Strategy optimization and strategy individual effect prediction have different goals, and there are obvious differences.


Therefore, a new method of strategic optimization, OOSR, is proposed, with the purpose of strengthening intervention areas with better results prediction and optimization efforts, rather than optimizing in the entire space. Therefore, when doing optimization and doing outcome-oriented weighting, the closer the current intervention is to the given optimal solution that has been trained, the stronger the optimization will be. .
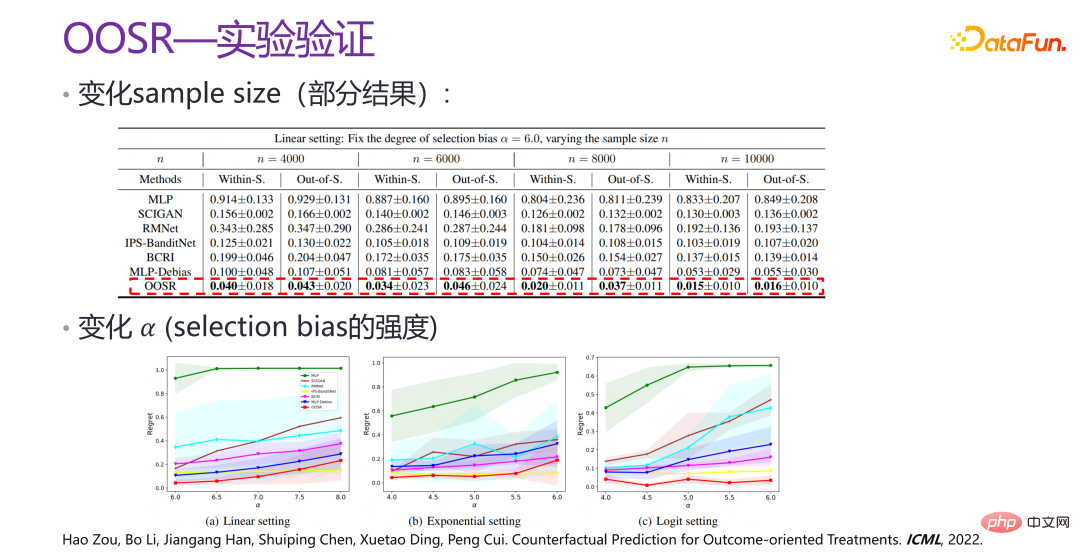
The above picture is the experimental verification of OOSR. It can be seen that improvement from all angles They are all very obvious, with several times improvement, and after changing the intensity of the selection bias, the effect is still very good. Related papers were published in ICML 2022 [4].
5. Summary of counterfactual reasoning
3. Complex benefits in trusted intelligent decision-making



, consider a scenario such as a recommendation system, where users hope that recommended products or information will be purchased or clicked, and some incentives will also be implemented, such as price reductions, or red envelope feedback, etc. There are many similar business operation strategies. Although sales have increased in the short term and the improvement effect is significant, in the long term there has not been a very significant change. That is to say, a lot of commercial stimulation does not turn things you don’t want to buy into people you want to buy, but the original total demand in a month. The quantity is 4 pieces, so I bought all 4 pieces at once due to this price reduction. Therefore, when optimizing the model, we should not only consider short-term benefits, but also consider both short-term and long-term benefits to optimize strategies together. 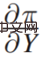

 ##If you want There are two very important aspects of taking into account both short-term and long-term benefits and jointly optimizing strategies. First, we need to have a deeper understanding of consumer choice models. When a user is given, there is no way to get a real consumer choice model. It needs to be continuously explored through research and mining. One is to explore the consumer choice model, and the other is to explore what happens under the consumer choice model. Maximize long-term gains, short-term gains, and the balance between the two. The work in this area is shown in the two figures above, so I won’t go into details here.
##If you want There are two very important aspects of taking into account both short-term and long-term benefits and jointly optimizing strategies. First, we need to have a deeper understanding of consumer choice models. When a user is given, there is no way to get a real consumer choice model. It needs to be continuously explored through research and mining. One is to explore the consumer choice model, and the other is to explore what happens under the consumer choice model. Maximize long-term gains, short-term gains, and the balance between the two. The work in this area is shown in the two figures above, so I won’t go into details here.
Judging from the final effect, as shown in the figure above, there is a significant increase in income in many real-life scenarios. Related papers were published in NeurIPS 2022 [5].
4. Predictive fairness in trusted intelligent decision-making

If predictions are to participate in decision-making, especially social-oriented decisions, the fairness of the predictions must be taken into consideration .

Regarding fairness, the traditional methods are DP and EO, which require the acceptance probability of men and women It is equal, or the predictive ability for men and women is the same, which are relatively classic indicators. But DP and EO cannot essentially solve the issue of fairness.
#For example, in the case of university admissions, theoretically the admission rates of boys and girls in each department should be the same, but in practice it will be generally found that the admission rates of girls The admission rate is low, which is actually a kind of Simpson's paradox. University admission is essentially a fair case, but when detected by the DP indicator, it will be considered unfair. In fact, DP is not a very perfect fairness indicator.


#EO Model In essence, gender does participate in decision-making, but in an unfair scenario, if there is a perfect predictor for both men and women, it is considered fair. This shows that the discrimination rate of EO is insufficient.

The concept of conditional fairness was proposed in 2020. Conditional fairness does not absolutely ensure that the final result is independent of sensitive attributes, but that given certain fairness variables, the final result is considered fair if it is independent of sensitive attributes. For example, major selection is fair and a fair variable, because it can be decided by students’ subjective initiative, and there is no fairness issue.
This brings many benefits. From the perspective of prediction, there is actually a trade-off between fairness and prediction. That is, the stronger the fairness requirement, the fewer predictive variables will be available. For example, under the EO framework, as long as a variable is on the link from gender to outcome decision-making, it cannot be used. If used, many variables will actually have very high prediction efficiency, but cannot make predictions. However, under conditional fairness, given a fairness variable, the prediction efficiency can be guaranteed to be available regardless of whether it is on the link or not.
#Under this framework, the DCFR algorithm model is designed and proposed, as shown in the following three figures.


 #
#
The figure below shows the experimental verification of the DCFR algorithm. On the whole, the DCFR algorithm can achieve a better compromise between prediction and fairness. From the perspective of Pareto optimality, the upper left curve is actually better. Related papers were published in KDD 2020 [6].
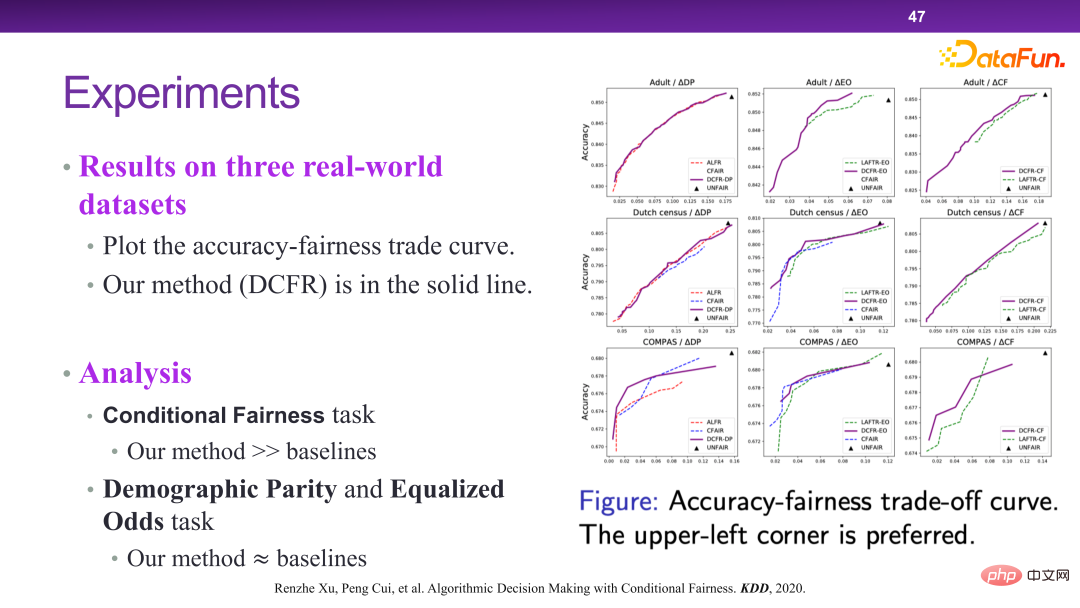
##5. Regulatory decision-making in trusted intelligent decision-making
Finally, there are supervisory decisions in trusted intelligent decision-making.

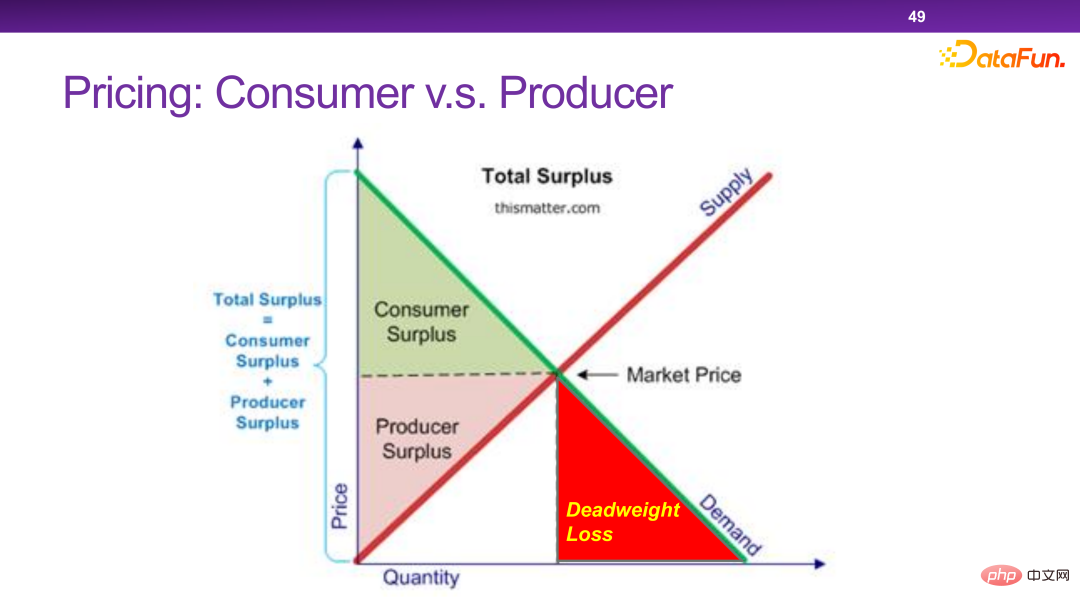
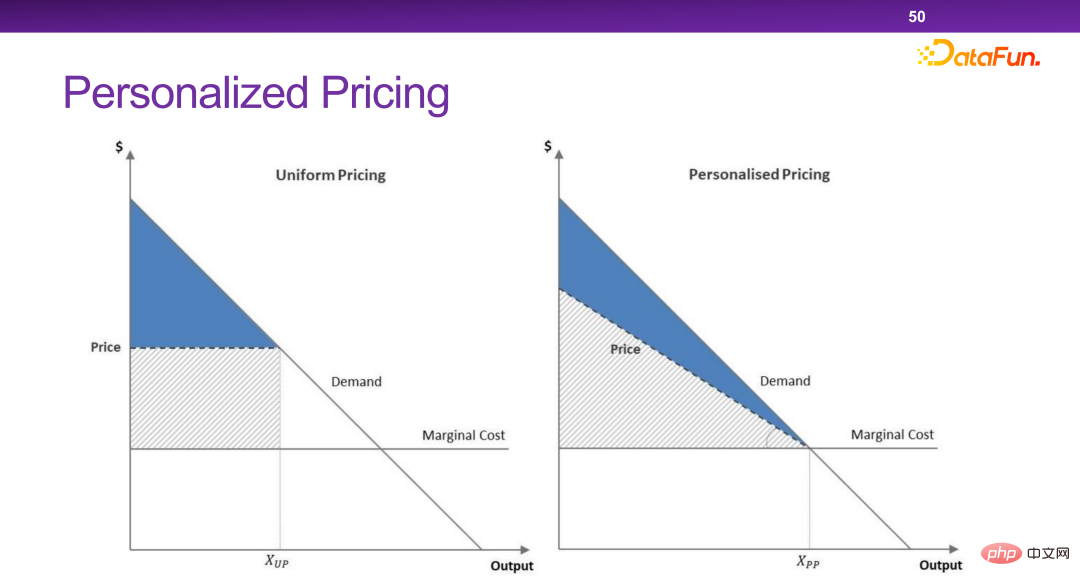
##Now The platform has many personalized pricing mechanisms. In essence, personalized pricing can maximize the total efficiency and total surplus of society. But in some extreme cases, merchants will take away all the surplus without leaving any surplus for users. This is something we don’t want to see.



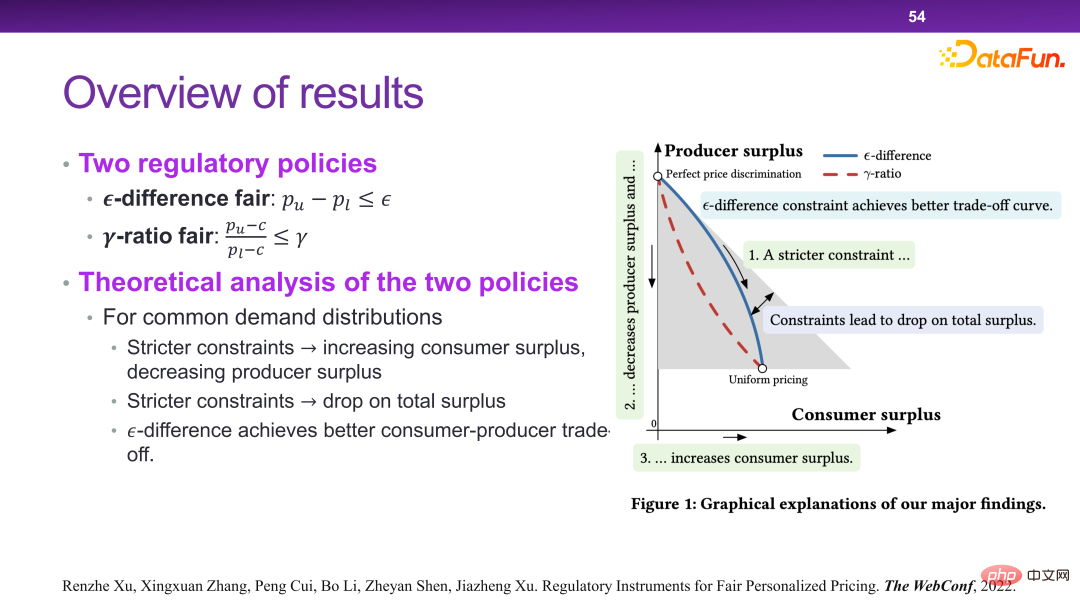
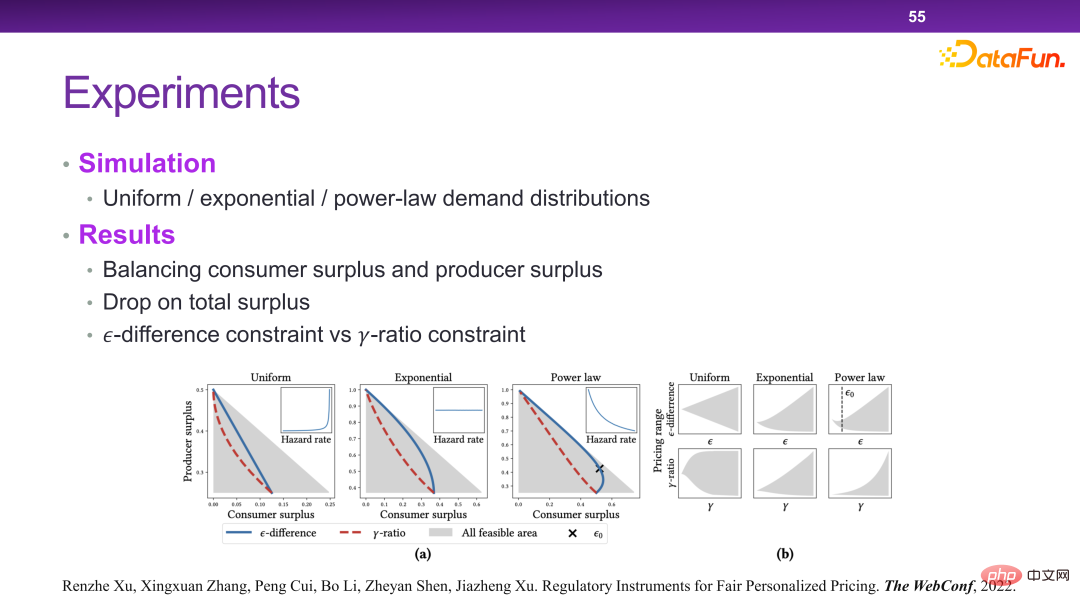
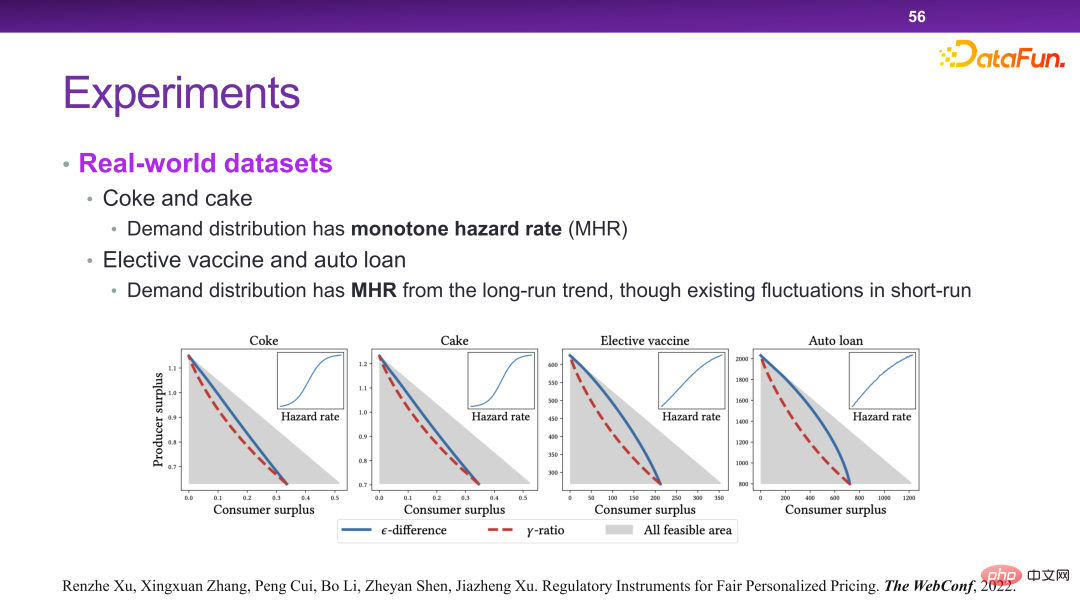 6. Summary of credible intelligent decision-making
6. Summary of credible intelligent decision-making
PS: For many technical details involved in this article, you can refer to the recent papers published by Cui Peng’s team in the direction of trusted intelligent decision-making. [1] Jon Kleinberg, Jens Ludwig, Sendhil Mullainathan, Ziad Obermeyer. Prediction Policy Problems. AER, 2015. [2] Hao Zou, Kun Kuang, Boqi Chen, Peng Cui, Peixuan Chen. Focused Context Balancing for Robust Offline Policy Evaluation. KDD, 2019. [3] Hao Zou, Peng Cui, Bo Li, Zheyan Shen, Jianxin Ma, Hongxia Yang, Yue He. Counterfactual Prediction for Bundle Treatments. NeurIPS, 2020. [4] Hao Zou, Bo Li, Jiangang Han, Shuiping Chen, Xuetao Ding, Peng Cui. Counterfactual Prediction for Outcome-oriented Treatments. ICML, 2022 . [5] Renzhe Xu, Xingxuan Zhang, Bo Li, Yafeng Zhang, Xiaolong Chen, Peng Cui. Product Ranking for Revenue Maximization with Multiple Purchases. NeurIPS, 2022. [6] Renzhe Xu, Peng Cui, Kun Kuang, Bo Li, Linjun Zhou, Zheyan Shen and Wei Cui. Algorithmic Decision Making with Conditional Fairness. KDD , 2020. [7] Renzhe Xu, Xingxuan Zhang, Peng Cui, Bo Li, Zheyan Shen, Jiazheng Xu. Regulatory Instruments for Fair Personalized Pricing. WWW, 2022. 7. References
The above is the detailed content of Cui Peng, Tsinghua University: Trustworthy intelligent decision-making framework and practice. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
