
 Technology peripherals
AI
How does the digital intelligence business field respond to the challenges of decision-making intelligence technology? Answers from three experts
Technology peripherals
AI
How does the digital intelligence business field respond to the challenges of decision-making intelligence technology? Answers from three experts
How does the digital intelligence business field respond to the challenges of decision-making intelligence technology? Answers from three experts

In recent years, with the changes in advertisers' needs and the development of related technologies, computational economics theory, game theory and artificial intelligence technology have been increasingly applied to advertising auction mechanisms and delivery strategies.
The significance of decision-making intelligence in business scenarios has gradually become more prominent. Every product display that users see, every advertising bid by merchants, and every traffic allocation on the platform are supported by huge and complex decision-making intelligence.
The goal of these actions is to optimize the user shopping experience, make the decision-making process of advertising more intelligent, and at the same time allow advertisers and media to achieve long-term prosperity on the platform. Advertisers hope to maximize marketing effects with limited resource investment, and platforms hope to build a better ecosystem. However, the complexity of the traffic environment, the competitive environment formed by other competing advertisements, and the huge complexity of the combination of variables such as bids, target groups, resource locations, and delivery time in the advertising strategy make the calculation and execution of the optimal advertising strategy full of challenges. challenge.
How to solve these problems? How is the goal of maximizing benefits broken down? These important issues related to decision-making intelligence are also of greatest concern to researchers and practitioners in the field.
In order to deeply explore the theme of "Decision Intelligence in Digital Intelligence Business Scenarios", Alimama Boxian Society and Heart of Machines recently invited Professor Deng Xiaotie from Peking University and Cai Shaowei from the Chinese Academy of Sciences Researchers and Alimama CTO Zheng Bo, three senior scholars and experts in the field, launched a series of theme sharings.
The following is the theme sharing content of Professor Deng Xiaotie, Researcher Cai Shaowei, and Teacher Zheng Bo. The Heart of the Machine has compiled it without changing the original meaning.
Professor Deng Xiaotie: Several latest research advances in computational economics
Today I will briefly introduce computational economics, which is a research field with a long history. It dates back to 1930. Later computational economics started from another perspective and turned economics into calculations. The previous computational economics was to do economic research through calculations. This time I will talk about the ideas.

When we think about economics from a computational perspective, there are several main key issues: The first is optimization. Machine learning is all about optimization, from which we can Saw a lot of optimization systems. After optimization, there is another issue called equilibrium. In the past, when we did computational economics, we did it from the perspective of planned economy. But at that time, there was also a school that worked on the development of developing countries from the World Bank. They made plans for developing countries. The idea of optimizing input and output is developed. Calculating equilibrium from a computational perspective can be a very difficult problem, so a concept called computable general equilibrium has emerged.
Recently, we can see more and more dynamic systems, because many things in this world are not in a state of equilibrium, and the balanced scene is particularly prominent in digital economic activities. , including things at the economic level, such as pricing. In the digital economy, transaction data and price fluctuations are visible every second. We can clearly see the changes in the data, instead of just counting the economic data after a year has passed.
There is much more within the entire framework of computational economics. Every economic entity must optimize, and the fixed point of their joint game is equilibrium. Platforms will also play a game of equilibrium, especially Internet advertising platforms. Advertisers come to the platform and distribute their ads through the platform and media. For the media, it is necessary to provide advertising positions and use their own attraction to a certain type of people. For the platform, what we need to think about is how to better match everyone’s interests. As the largest advertising platform in China, Alimama also faces the problem of game equilibrium. It needs to arrange the interests of all parties to maximize social benefits and maximize the benefits of mechanism design.

We can talk about optimization from three perspectives.
The first is the issue of characterization of economic intelligence. Many machine learning things are written as optimization problems, such as how to use machine learning methods to calculate constraints, including constraints in some environments.
Under incomplete information, many conditions are unknown. The original economics cannot consider such complex things, such as what is the benefit function of the game opponent and the strategy space of the game opponent. What is it, what are the game opponents, and imperfect information are also very important in describing economic activities.
Many assumptions can describe incomplete information, such as the economic man knowing the opponent's benefit function, constraints and other various information. There is common knowledge about each other's benefit functions: we know distribution. But where did this distribution come from? This brings us into the realm of machine learning: why does the player tell each other and us what it knows? In view of these, there are some very reasonable questions in terms of calculation angle.
Game dynamics, this is the third step of computational economics. From the perspective of the economics of the real economy, many activities have evolved and developed over 6,000 years, and everyone slowly plays the game until equilibrium is achieved. In the digital economy, it will be a big challenge to reach equilibrium all at once.
Advertising platform optimization is what Alimama does. We have talked about so many difficult computing tasks, when will we be able to do them well? In the case of single parameters, existing theories can support it, but there is no ready-made definition in theory for how to achieve multi-parameters.
A very important point is that the entire economics system has been established, but when economics is used on the Internet, there will be a big flaw - it is static. Everyone must know that things in the industry are not static. For example, the "Double Eleven" promotion will create many challenges. How to design the price of red envelopes and how to build these things based on known market models have become important issues in computational economics today. Challenges: One is approximate solution optimization, one is equilibrium planning, and the other is platform competition dynamics.

Approximate calculation is very difficult. The equilibrium solution we know can be calculated to one-third at most, with an error rate of 33% at most. , which is 33% different from the optimal, so the equilibrium calculation is indeed difficult. Automatic design methodology and hidden opponent model learning are the frameworks in this area, and they are all related to information capacity.

The other is to play against unknown opponents in the market. We have to consider at least two companies and build a model to design the game between them. It is all monotonous and not all the information is known. Based on the known information, we look at market fluctuations and price design changes. Based on this, we design an optimization model of implicit functions and use machine learning methods for analysis.
The sequence of multi-party cognition brings us the cognitive level of the game. In recent years, several studies have discussed many reasons why first-price auctions are better than second-price auctions. Myerson developed a theory of optimal auctions assuming that everyone knows everyone's value distribution, but we don't actually know the public knowledge. Our own research is considered from another perspective. The starting point is that there is no a priori common knowledge, and the original assumption of establishing Myerson's optimal auction theory using the probabilistic method is abandoned.
In the absence of this set of basic assumptions about auction equilibrium, how can the optimal solution achieve equilibrium? It can be found that the generalized one-price auction revenue is equal to Myerson. Here, we should deal with the value distribution announced by the buyer with the optimal benefit as the goal. The Myerson optimal return designed by the seller is equivalent to the expected auction return of the generalized one-price auction.
The final conclusion is that Myerson and GFP are equivalent, they are better than VCG, but they are equivalent in the case of IID, Symmetric BNE and GSP are also equivalent.
Another concept used in computational economics is Markov game, a game in a dynamic environment, especially the problem of solving infinite rounds of games. We dealt with the problem from three directions: first, we made rational simplifications for the calculation and limited the goal to approximate solutions; second, we used the time discount rate to ensure the convergence of the infinite round income; third, we made mathematical analysis Stage summation limits the changes in the strategy in different rounds to the changes in one round. In this way, the difficulty of infinite summation can be overcome.
We further simplify the computational difficulty in the application of Markov games. There is a clear Markov reward analysis for the design of the consensus mechanism, and it tells a good story. According to the rules of mechanism design, it is right if most people support it. But it was later discovered that majority support did not guarantee economic security.

Our latest work is to use Insightful mining Equilibrium to overcome the problems in the design process of the digital economy, and use far-sighted strategies to achieve optimal results. It is the structure of the Markov game that forms the Markov reward process, adding a cognitive level, from the honest mining pool, the selfish mining pool, and then crosses another level to reach the result of the visionary mining pool.
Similarly, many Internet companies have to deal with dynamic things rather than static things. Today’s world economics is no longer the economics of the past. In addition, machine learning methodologies and Game theory is closely integrated. We have thus overcome the situation of being able to deal only with static economics and evolved to being able to deal with dynamic situations.
Researcher Cai Shaowei: An efficient method for solving large-scale sparse combinatorial optimization problems
Hello everyone, the topic I share today is large-scale Efficient methods for sparse combinatorial optimization. The core of many decision-making problems involves combinatorial optimization problems, and people are very concerned about how to choose an appropriate combination of solutions to achieve goal optimization.
There are two main types of methods for solving combinatorial optimization: one is heuristic methods, including heuristic search and heuristic construction. For example, the greedy algorithm that is often used can be regarded as a heuristic. One type of construction, the greedy criterion is heuristics; the other is an exact algorithm represented by branch-and-bound (brand-and-bound).
The advantage of the heuristic method is that it is not sensitive to scale, so it can solve large-scale problems approximately. The disadvantage is that it is often not known how far the obtained dissociation optimal solution is. , or you may have found the optimal solution, but you don't know it. Branch And Bound is complete. If you give it enough time to calculate and stop, you can find the optimal solution and prove that it is the optimal solution. However, this method comes at a cost and is sensitive to scale, because this type of algorithm explodes exponentially and is often not suitable for large-scale problems.
Whether it is searching or constructing, the heuristic algorithm framework is mostly very simple. It mainly depends on how the heuristic is designed and which criteria it should be based on. The branch and bound method mainly focuses on how to make "bounds". If you read the papers, you will find that many Branch And Bound papers are doing bounding technology. How to make the bounds tighter can better prune the solution space.
Later I thought, can we combine these two? In other words, it can not only remain insensitive to scale, but also add bounding technology. It is easy to think that you can use preprocessing methods, or do Heuristics first and then Branch And Bound, and use the Heuristics results as the initial solution, etc. We propose a new approach in this regard - nested iteration in Heuristics and Branch And Bound.

To put it simply, this method first does a rough Heuristic solving to find a preliminary result. Generally speaking, upper and lower bounds are required for bounding. Heuristics will roughly obtain a lower bound, and then design a function for the upper bound. Assuming that the problem is relatively large and includes many elements, we can eliminate some to make the problem smaller. Then be more refined and continue doing Heuristic solving, which may improve the lower bound. On this basis, the algorithm can do some more bounding and continue to be nested. So this algorithm becomes a semi-exact algorithm, and it is possible to prove that this is the optimal solution, because at a certain step it is found that the problem space is small enough, and it does not require Heuristic solving but can be solved directly and accurately. In addition, if the optimal solution is not found, you can also know where the optimal solution interval is.

Next, we will give two examples to explain this method.
The first one is the "maximum group problem". Clique is a very classic concept in graph theory. In a graph, there are subgraphs connected by edges between points, which is called a clique. The maximum clique problem is to find the largest clique. If you give it a weight and assign a weight to each vertex, the maximum weighted clique problem is to find the clique with the largest total weight. In the example below, there are four groups and three groups respectively. The weight of the three groups is larger, which is the maximum weighted group in this picture.
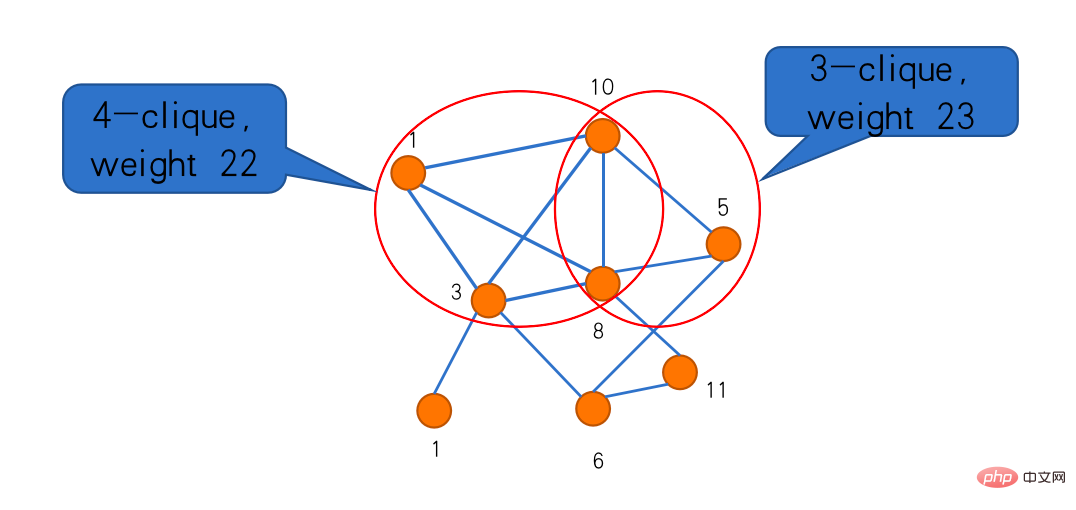
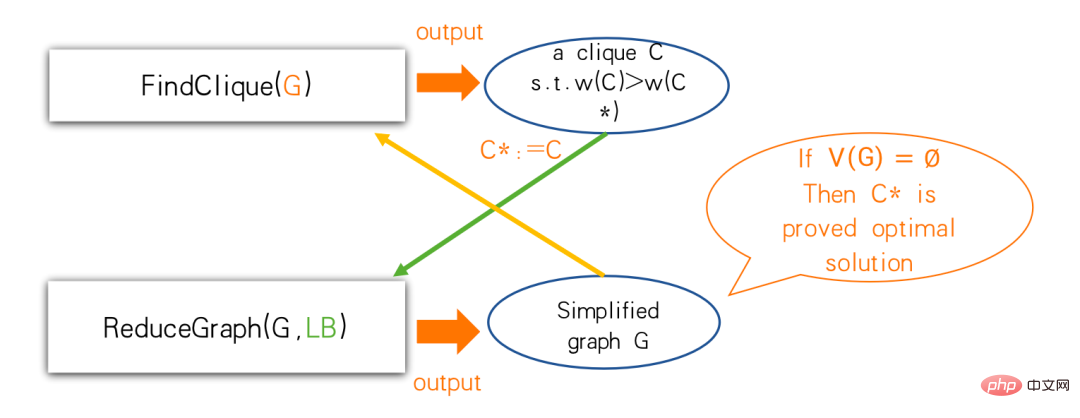
To do this according to this framework, we need two sub-algorithms, one for heuristic solving, called FindClique in the group, and the other It is a simplification algorithm called ReduceGraph. We can use FindClique to find a clique that is better than what we found before. When this better group reaches the Reduce Graph, what we know is: the largest group is at least this big. Simplification is also done at this step. If the graph becomes empty after simplification, then the found cluster is the optimal solution; if it does not become empty, then you can reduce some points and go back to adjust the algorithm for finding the cluster. The algorithm here is not necessarily a fixed algorithm and can change dynamically.
One of our work chose the "construct and cut" method, which can be understood as a multiple greedy algorithm.
The effect of multiple greedy constructions is that each greedy construction can be very fast and can start from different starting points, and if during a certain construction process After calculating, no matter how much the current group expands, it is impossible to exceed the previously found group, we can stop. The ultimate goal is to find a group that is larger than before. Whether the heuristic should be made more refined and how to adjust the order depends on the scale of the graph. It is like peeling an onion. Peel it to a certain layer and then refine it to have a larger Focus on finding better teams. When the graph cannot be simplified any more, we can use precise algorithms such as Branch And Bound. After finding a group, according to our method, we need to do bounding and throw away some points. The method is to estimate the size of the group that the points can develop, and there can be different solutions to solve it.
These two boundary estimation techniques are used as examples, and you can use different techniques to do it. In terms of experiments, you can refer to the table below to compare methods such as FastWClq, LSCC BMS, and MaxWClq. The time required to achieve the same accuracy differs by more than ten or even hundreds of times.

Let’s look at the second question: "Graph coloring problem". The so-called coloring is to apply a color to each point of the graph. Two adjacent points cannot be the same color. The graph coloring problem discusses the minimum number of colors that can be used to color a graph. The minimum number of colors is called the color number of the graph. The graph coloring problem has many applications, especially allocating resources without conflicts.
The general idea of this problem is the same - heuristic solution plus some bounding technology. The difference is that the graph coloring problem does not require a subset. Since the entire graph needs to be colored, there is no concept of "throwing it away forever". Each point must be returned in the end, and this point must have a color. The reduce here is to decompose the graph into Kernel and Margin:

There is a very simple rule, or it is related to independent sets. If I know this The minimum number of colors that the graph needs to use is the color lower bound (denoted as ℓ), and then the independent set of ℓ-degree bound can be found. The degrees of the points in this independent set are all smaller than ℓ, so it is called ℓ-degree bound. If you find such an independent set, you can safely move it to the Margin. If the solution of kernel is found, we can easily merge the margin into it. If kernel is the optimal solution, the combination must also be the optimal solution. This rule can be used iteratively.

Let’s look at an example. The four gray points in this example are kernels. You can see that at least 4 colors are needed. The three points next to it are placed on the edge. Since the degrees of the three points are smaller than 4, we can safely move these three points to the side and ignore them for now. Then I found that the remaining subgraph cannot be decomposed. It is already very hard-core and can be solved directly. The hard core of sparse graphs is generally not large, so exact algorithms can be considered for solution. If you find the core, it is known that the core uses at least four colors. For the points on the edge, the degree of each point is less than 4. How can you leave a color for it? Just go through it in linear time. .

Until the end, the margin of each peel must be retained, and the layer must be clearly marked. This is related to the first question. Slightly different place. We need to use additional data structures to retain these edge maps. After the last unmovable Kernel is accurately solved, we can use the reverse order method to first merge the last Margin and retain the optimality according to the previous rules. If the Kernel is optimal, merging an edge will still be optimal. If you go back all the way, the solution to the original image must also be optimal.
When this problem becomes framed, all that remains is to consider how to find lower bound and upper bound. The general idea of the algorithm is: at the beginning, the kernel is the original image, and the maximum clique algorithm needs to be used to find a lower bound; after peeling off the edges, the greedy graph coloring algorithm can be used to find an upper bound.

There are actually three algorithms used here. In practice, it is common to use combination punching methods, specifically kernel coloring. When the image is relatively large, we may use some greedy or faster method to do it, and finally it may become an accurate algorithm to do it. Throughout the process, lower bound and upper bound are global. If these two are equal, you can stop.

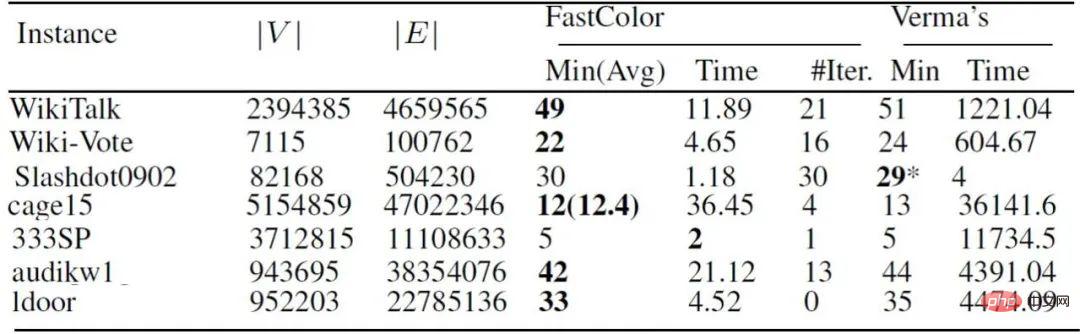
#The above picture is the experimental result. It can be seen that in the sparse The effect on the large picture is better, 97 out of 144 can prove the optimal solution in one minute. Compared with similar algorithms, the comparison time of our algorithm is also faster. There are special methods on relatively sparse large graphs that can quickly solve the problem. People used to think that NP-hard problems with millions of vertices must take a long time to solve. In fact, if these graphs are large but have certain characteristics, we can still solve them in seconds and minutes.
Alimama CTO Zheng Bo: Alimama’s continuously upgraded decision-making intelligence technology system
Hello everyone, as the technical leader of Alimama, I will share this from an industry perspective Alimama has made progress in decision-making intelligence technology in the past few years.
Founded in 2007, Alimama is the core commercialization department of Alibaba Group, which is the online advertising department. After more than ten years of development, Alimama has created influential products such as "Search Advertising Taobao Express". In 2009, it launched display advertising and Ad Exchange advertising trading platforms. In 2014, the data management platform Damopan appeared. , started global marketing in 2016.

From a technical point of view, around 2015 and 2016, Alimama fully embraced deep learning, from the intelligent marketing engine OCPX to self-research The core algorithm for CTR prediction, the MLR model, continues to evolve with deep learning methods. In 2018, the deep learning framework X-Deep Learning was open sourced. In 2019, the Euler graph learning framework was open sourced, and super recommendations for information flow products were also launched. "People find goods" evolved into "goods find people." Beginning in 2020, Alimama launched live-streaming advertising, and also began to launch interactive incentive ads, such as the interactive game "Double Eleven" Stacking Cat, which is played more frequently. The curvature space learning framework was also open sourced this year.
In 2022, Alimama made a major upgrade to the entire advertising engine. The advertising engine platform EADS and the multimedia production and understanding platform MDL are both online; in terms of consumer privacy protection, Alimama’s privacy computing technology capabilities have been certified by the China Academy of Information and Communications Technology. Looking back at Alimama’s development over the past fifteen years, we can see that we are a company that engages in computational advertising.
What are the advantages of Alimama? In the very professional e-commerce field, we have a very strong understanding of users and e-commerce, and the business scenarios are also very rich. In addition to the traditional search and recommendation, we also have digital business scenarios such as live broadcast promotion, interaction, and new forms. Dabble. In addition, our customer base is among the largest in the world, with millions of merchants being advertisers on Alimama’s platform. These customers have a lot of needs. In addition to business needs for operations, there are also various ecological roles involved, such as anchors, experts, agents, and service providers. They are active in this platform in different roles.

We also have a lot of research on AI. Here we introduce the characteristics of advertising scene algorithm technology. As shown above, the inverted funnel structure on the left is very familiar to many students who do search or recommendation. This part of advertising is very similar to search recommendation, including advertising recall, rough sorting, fine sorting, and scoring of mechanism strategies, involving a large amount of AI such as information retrieval. Technology, especially recall models such as matching TDM, all use deep learning technology.
This includes decision-making intelligence. Since the platform contains many roles, each with its own game relationship, decision-making intelligence comes in handy between multi-party relationships and optimized balance. User experience, traffic cost, expected revenue, budget control, and cross-domain integration all need to be balanced.
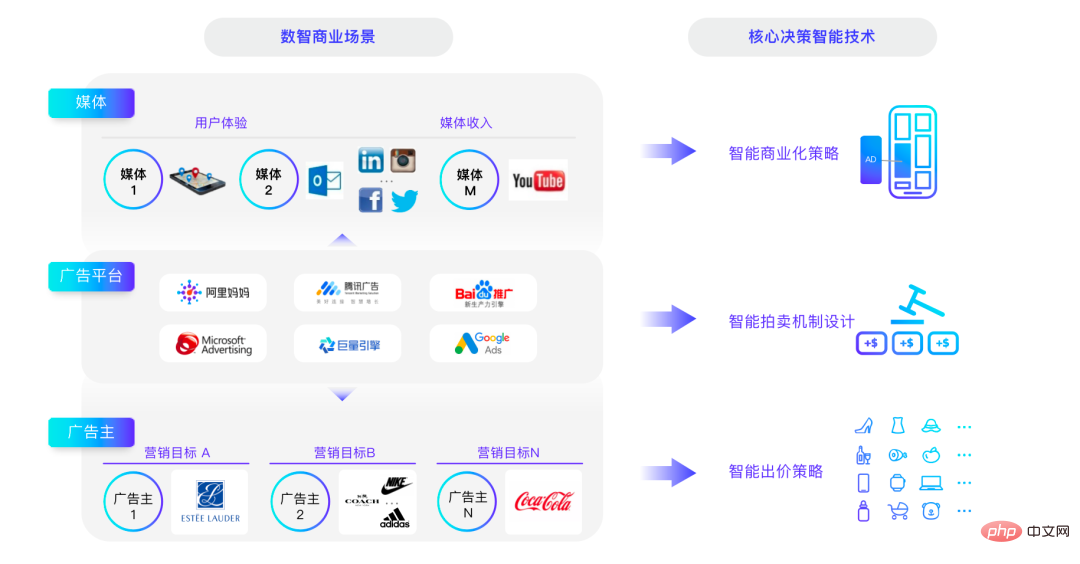
#Here I will talk about three typical game players. There are many players on the platform, and there are three main categories: media, advertisers, and advertising platforms.
The core technologies of these three parts can be summarized as follows: from the media perspective, focus on releasing which media resources can best balance user experience and commercial revenue; from the advertiser’s perspective, what should be optimized and how to use the smallest Achieve marketing goals at a cost. So, what is the biggest goal of an advertising platform? In the long run, the lower-level goal of the advertising platform is to make the entire platform more prosperous. Making money is only a short-term matter, and making the platform prosperous in the long term is the ultimate goal. Therefore, the platform must balance the relationship between all parties and allow players from all parties to It's nice to play on the platform.
The optimization goals of the advertising platform involve many mechanism designs. Today I will briefly talk about the three directions of smart auction mechanism design, smart bidding strategy, and smart commercialization strategy. I will mainly talk about Alimama’s work in this regard in the past few years in a popular science way for everyone to discuss.

Intelligent auction mechanism design.
# Let’s first talk about the design of intelligent auction mechanism. This is a very interesting topic. Many seniors and experts have won the Nobel Prize in Economics. The classic auction mechanisms we are talking about all appeared before the 1970s. At that time, online advertising had not yet appeared, and everyone studied a lot about the optimization of single auctions or static auctions. These mechanisms are usually single-target and for a single auction.
Whether it is an advertising platform or a media, it is necessary to balance user experience and advertising revenue. A typical industry problem is multi-objective optimization. If there are many businesses involved on the platform, different businesses may There is platform strategy and will in it, and this is also a multi-objective optimization.
From the beginning, classic auction theory was used, such as using GSP or UGSP for traffic distribution and pricing. The industry gradually evolved to deep learning to solve this problem. These classic algorithms use formulas to calculate some parameters that the platform optimizes for a certain goal. With the tools of deep learning, the design of the auction mechanism itself is also a decision-making problem. It is an algorithm for solving decision-making problems, but the production decision-making algorithm is also decision-making problem.
Three years ago, we designed a Deep GSP auction mechanism based on deep learning, which was improved on the premise of satisfying the good nature of the mechanism; the effect of the platform, the so-called good nature of the mechanism refers to incentives Compatible, advertisers don’t need to make money through cutting corners or using black and white methods. They can truly express their wishes and get the traffic that meets the bid. Deep GSP maintains the incentive compatibility property and replaces the original static formula with a learnable deep network. This is the first stage of work.
In the second stage, we calculated many parameters in the auction mechanism network through training and optimization. But in fact, in the entire process, in addition to parameter calculation, sorting, and advertising distribution processes, they are an integral part of the entire system. Some modules are actually non-differentiable, such as the sorting module, so it is difficult for a deep learning network to simulate it. In order to design the auction mechanism end-to-end, we model the differentiable part of the auction process into the neural network, so that the gradient can be reversed. Conduction makes model training more convenient.

Smart bidding strategy.
Next let’s talk about smart bidding strategy, which is the most important tool used by advertisers to adjust effects or game. Centralized distribution cannot express demands, but there is a way to express them in advertising scenarios. Bidding products are divided into three development stages:
The initial classic solution is also the oldest bidding method. It is hoped that the budget will be spent more smoothly and the effect will be more guaranteed. At the beginning, the industry adopted Similar to the PID control algorithm, this is a very simple algorithm and the effect is relatively limited.
In 2014 and 2015, after AlphaGo defeated humans, we saw the power of reinforcement learning. Smart bidding is a very typical sequence decision-making problem. During the budget cycle, whether the previous spending is good or not will affect the subsequent bidding decision. This is the strength of reinforcement learning, so in the second stage we used bidding based on reinforcement learning. , through MDP modeling, directly use reinforcement learning to do this.
The third stage evolved into the SORL platform, which is characterized by the inconsistency between the offline simulation environment and the online environment in reinforcement learning. We conduct interactive learning directly in an online environment, which is an example of the union of engineering design and algorithm design. After SORL was launched, it largely solved the problem of reinforcement learning's strong dependence on the simulation platform.
Other technical features include the engineering infrastructure part, including the training framework of the smart bidding model, the integrated flow and batch control system, and the multi-channel delivery graphical online engine. The engineering system and algorithm are equally important. The closer and more real-time it is to the trading center, the better feedback it can get. For smart bidding, the more advanced the engineering infrastructure is, the better it can help advertisers achieve better results.
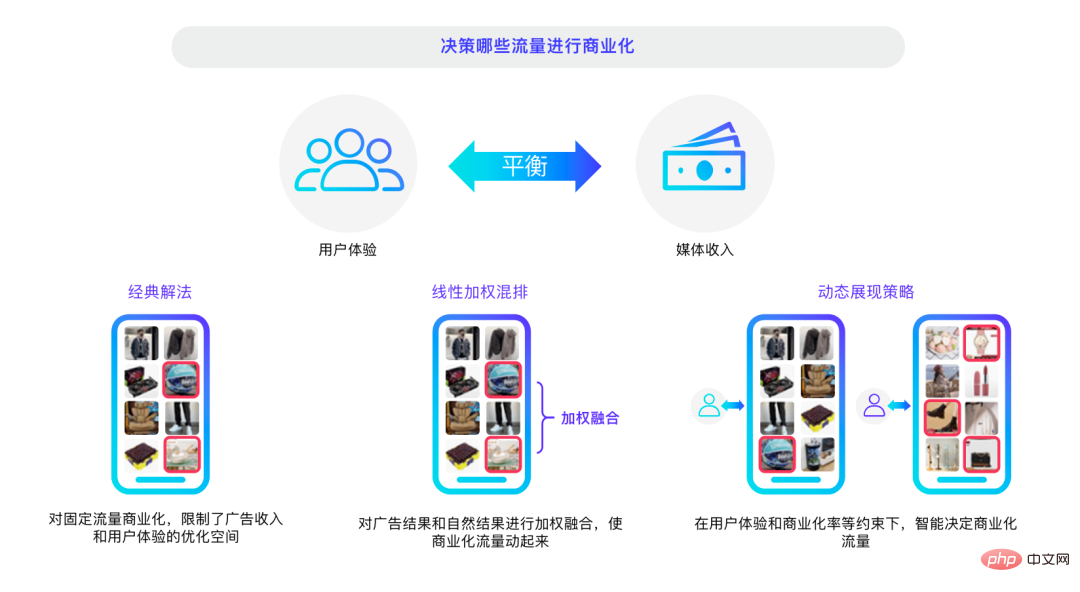
Smart commercialization strategy.
#Finally, let’s talk about the intelligent commercialization strategy related to media. In terms of commercialization strategy optimization, the initial attempt was to weightedly integrate advertising results and natural results, then mix them and select them according to different situations. Unreasonable commercialization mechanisms are very harmful to user experience, and everyone is beginning to realize this problem. In the past year or two, dynamic display strategies have gradually become popular. With the development of deep learning and other technologies, we can balance user experience and commercial revenue by optimizing decision-making algorithms, and balance user experience with global traffic.
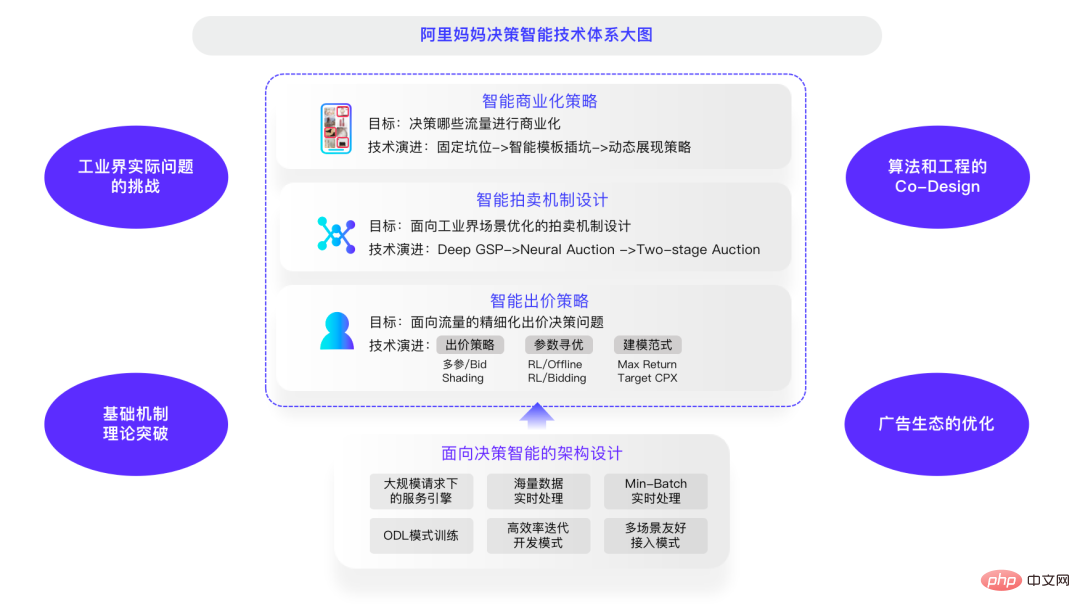
Overall, in these three major aspects, Alimama has formed a decision-making intelligent system diagram, which is divided into three levels: intelligent auction The mechanism is the bridge in the middle. The problem solved by the intelligent commercialization strategy is what kind of resource auction is the most efficient and can best balance the user experience and commercial revenue. The intelligent bidding strategy is a decision-making process for refined bidding for traffic. Through bidding Parameter optimization, reinforcement learning parameter optimization based on the real environment, or optimization using modeling paradigms such as Target CPX and Max Return.
Faced with the current multi-round auctions and high-frequency auctions, many basic theories need to be further broken. When it comes to theoretical breakthroughs in basic mechanisms, Teacher Deng is an expert in this field, and we look forward to working with him to conduct cutting-edge research in this area. From the perspective of challenges in practical engineering problems, the actual environment requires results to be returned in 200 milliseconds, so there needs to be some balance between efficiency and effect. I have experienced this after working in the industry for a long time.
The optimization of the advertising ecology is relatively independent. The ultimate goal of the platform is for the ecology to thrive and develop peacefully. If these are done well, can the ecology meet expectations? I don't think there may be a direct equation between the two. Regarding ecological optimization, there are still many theoretical and practical problems that need to be solved, which I hope friends in the industry can discuss and solve together in the future.
In the past three years, Alimama has published nearly 20 papers in top international conferences (NeurIPS, ICML, KDD, WWW, etc.) in the field of decision-making intelligence, and has cooperated with Peking University, Shanghai Jiao Tong University, The Chinese Academy of Sciences, Zhejiang University and many other universities and research institutions have cooperated, and the relevant results have received widespread attention and follow-up from industry and academia. In this field, we have achieved technological development from following to gradually leading the industry.
Compared to deep learning, decision intelligence has not received much attention in the industry and academia, so I would like to take this opportunity to let everyone know more about this field. This field is very interesting and interesting. Prospective. The above is Alimama’s thinking and work on decision-making intelligence. I hope to share it with friends in the industry and academia. We can discuss it more in the future and strive to form some breakthrough developments in theoretical research on decision-making intelligence and practical applications in the industry.
The above is the detailed content of How does the digital intelligence business field respond to the challenges of decision-making intelligence technology? Answers from three experts. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
Methods and steps for using BERT for sentiment analysis in Python
Jan 22, 2024 pm 04:24 PM
BERT is a pre-trained deep learning language model proposed by Google in 2018. The full name is BidirectionalEncoderRepresentationsfromTransformers, which is based on the Transformer architecture and has the characteristics of bidirectional encoding. Compared with traditional one-way coding models, BERT can consider contextual information at the same time when processing text, so it performs well in natural language processing tasks. Its bidirectionality enables BERT to better understand the semantic relationships in sentences, thereby improving the expressive ability of the model. Through pre-training and fine-tuning methods, BERT can be used for various natural language processing tasks, such as sentiment analysis, naming
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent space embedding: explanation and demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) is the process of mapping high-dimensional data to low-dimensional space. In the field of machine learning and deep learning, latent space embedding is usually a neural network model that maps high-dimensional input data into a set of low-dimensional vector representations. This set of vectors is often called "latent vectors" or "latent encodings". The purpose of latent space embedding is to capture important features in the data and represent them into a more concise and understandable form. Through latent space embedding, we can perform operations such as visualizing, classifying, and clustering data in low-dimensional space to better understand and utilize the data. Latent space embedding has wide applications in many fields, such as image generation, feature extraction, dimensionality reduction, etc. Latent space embedding is the main
 Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
Understand in one article: the connections and differences between AI, machine learning and deep learning
Mar 02, 2024 am 11:19 AM
In today's wave of rapid technological changes, Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL) are like bright stars, leading the new wave of information technology. These three words frequently appear in various cutting-edge discussions and practical applications, but for many explorers who are new to this field, their specific meanings and their internal connections may still be shrouded in mystery. So let's take a look at this picture first. It can be seen that there is a close correlation and progressive relationship between deep learning, machine learning and artificial intelligence. Deep learning is a specific field of machine learning, and machine learning
 Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Super strong! Top 10 deep learning algorithms!
Mar 15, 2024 pm 03:46 PM
Almost 20 years have passed since the concept of deep learning was proposed in 2006. Deep learning, as a revolution in the field of artificial intelligence, has spawned many influential algorithms. So, what do you think are the top 10 algorithms for deep learning? The following are the top algorithms for deep learning in my opinion. They all occupy an important position in terms of innovation, application value and influence. 1. Deep neural network (DNN) background: Deep neural network (DNN), also called multi-layer perceptron, is the most common deep learning algorithm. When it was first invented, it was questioned due to the computing power bottleneck. Until recent years, computing power, The breakthrough came with the explosion of data. DNN is a neural network model that contains multiple hidden layers. In this model, each layer passes input to the next layer and
 AlphaFold 3 is launched, comprehensively predicting the interactions and structures of proteins and all living molecules, with far greater accuracy than ever before
Jul 16, 2024 am 12:08 AM
AlphaFold 3 is launched, comprehensively predicting the interactions and structures of proteins and all living molecules, with far greater accuracy than ever before
Jul 16, 2024 am 12:08 AM
Editor | Radish Skin Since the release of the powerful AlphaFold2 in 2021, scientists have been using protein structure prediction models to map various protein structures within cells, discover drugs, and draw a "cosmic map" of every known protein interaction. . Just now, Google DeepMind released the AlphaFold3 model, which can perform joint structure predictions for complexes including proteins, nucleic acids, small molecules, ions and modified residues. The accuracy of AlphaFold3 has been significantly improved compared to many dedicated tools in the past (protein-ligand interaction, protein-nucleic acid interaction, antibody-antigen prediction). This shows that within a single unified deep learning framework, it is possible to achieve
 Improved RMSprop algorithm
Jan 22, 2024 pm 05:18 PM
Improved RMSprop algorithm
Jan 22, 2024 pm 05:18 PM
RMSprop is a widely used optimizer for updating the weights of neural networks. It was proposed by Geoffrey Hinton et al. in 2012 and is the predecessor of the Adam optimizer. The emergence of the RMSprop optimizer is mainly to solve some problems encountered in the SGD gradient descent algorithm, such as gradient disappearance and gradient explosion. By using the RMSprop optimizer, the learning rate can be effectively adjusted and the weights adaptively updated, thereby improving the training effect of the deep learning model. The core idea of the RMSprop optimizer is to perform a weighted average of gradients so that gradients at different time steps have different effects on weight updates. Specifically, RMSprop calculates the square of each parameter
 How to use CNN and Transformer hybrid models to improve performance
Jan 24, 2024 am 10:33 AM
How to use CNN and Transformer hybrid models to improve performance
Jan 24, 2024 am 10:33 AM
Convolutional Neural Network (CNN) and Transformer are two different deep learning models that have shown excellent performance on different tasks. CNN is mainly used for computer vision tasks such as image classification, target detection and image segmentation. It extracts local features on the image through convolution operations, and performs feature dimensionality reduction and spatial invariance through pooling operations. In contrast, Transformer is mainly used for natural language processing (NLP) tasks such as machine translation, text classification, and speech recognition. It uses a self-attention mechanism to model dependencies in sequences, avoiding the sequential computation in traditional recurrent neural networks. Although these two models are used for different tasks, they have similarities in sequence modeling, so
