
 Technology peripherals
AI
A100 implements a 3D reconstruction method without 3D convolution, and only takes 70ms for each frame reconstruction
Technology peripherals
AI
A100 implements a 3D reconstruction method without 3D convolution, and only takes 70ms for each frame reconstruction
A100 implements a 3D reconstruction method without 3D convolution, and only takes 70ms for each frame reconstruction

Reconstructing 3D indoor scenes from pose images is usually divided into two stages: image depth estimation, followed by depth merging and surface reconstruction. Recently, several studies have proposed a series of methods that perform reconstruction directly in the final 3D volumetric feature space. Although these methods have achieved impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments.
Now, researchers from institutions such as Niantic and UCL are trying to reuse traditional methods and focus on high-quality multi-view depth prediction, finally using simple and off-the-shelf depth fusion methods. Highly accurate 3D reconstruction.

- ##Paper address: https://nianticlabs.github .io/simplerecon/resources/SimpleRecon.pdf
- GitHub address: https://github.com/nianticlabs/simplerecon
- Paper home page: https://nianticlabs.github.io/simplerecon/
This research uses powerful image first A 2D CNN is carefully designed based on the experiment as well as the plane scan feature quantity and geometric loss. The proposed method SimpleRecon achieves significantly leading results in depth estimation and allows online real-time low-memory reconstruction.
As shown in the figure below, SimpleRecon’s reconstruction speed is very fast, taking only about 70ms per frame.
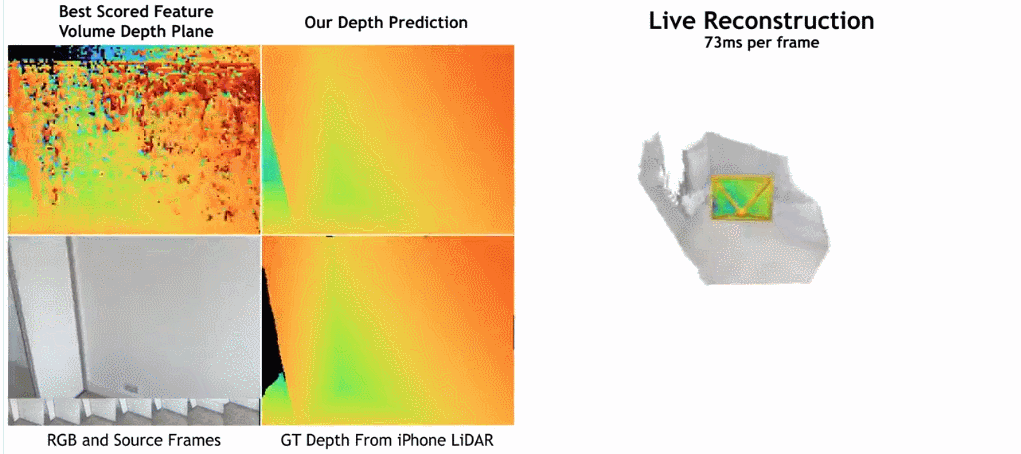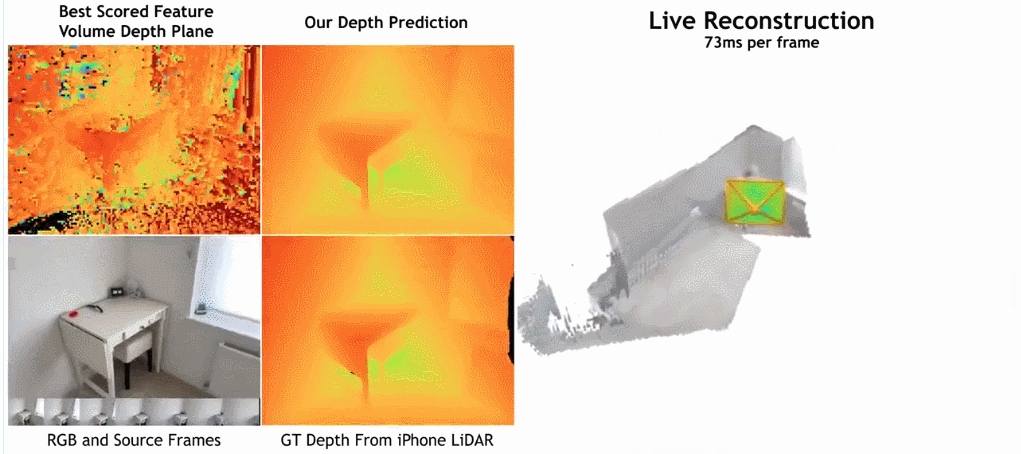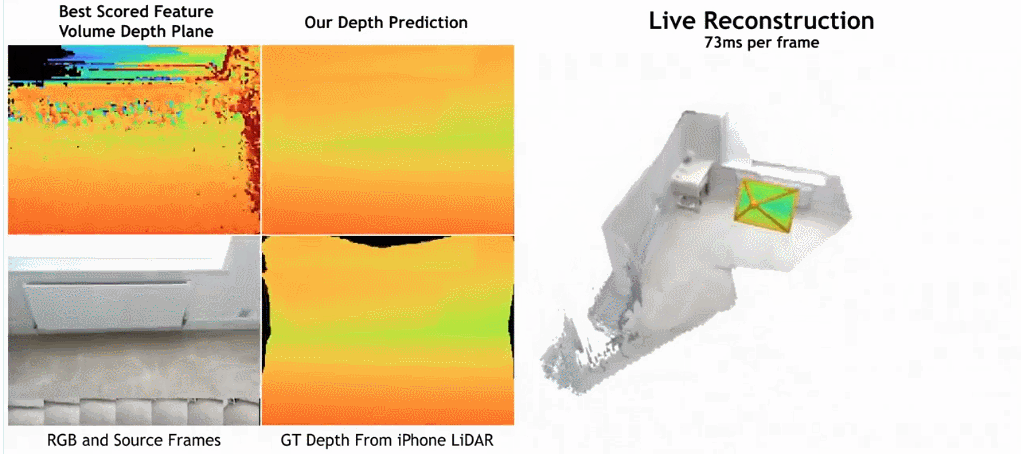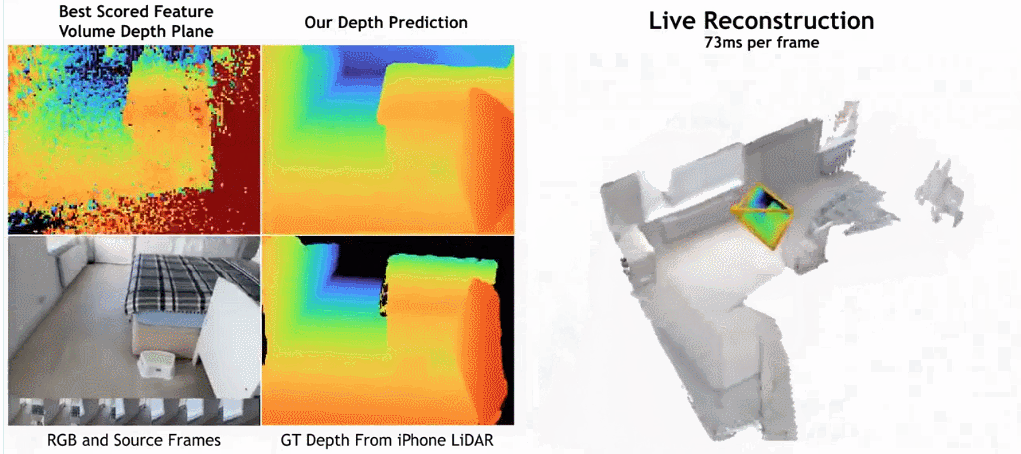
The comparison results between SimpleRecon and other methods are as follows:


The depth estimation model is located at the intersection of monocular depth estimation and planar scanning MVS. Researchers use cost volume (cost volume) to increase the depth prediction encoder-decoder. Architecture, as shown in Figure 2. The image encoder extracts matching features from the reference and source images as input to the cost volume. A 2D convolutional encoder-decoder network is used to process the output of the cost volume, which is augmented with image-level features extracted by a separate pre-trained image encoder.
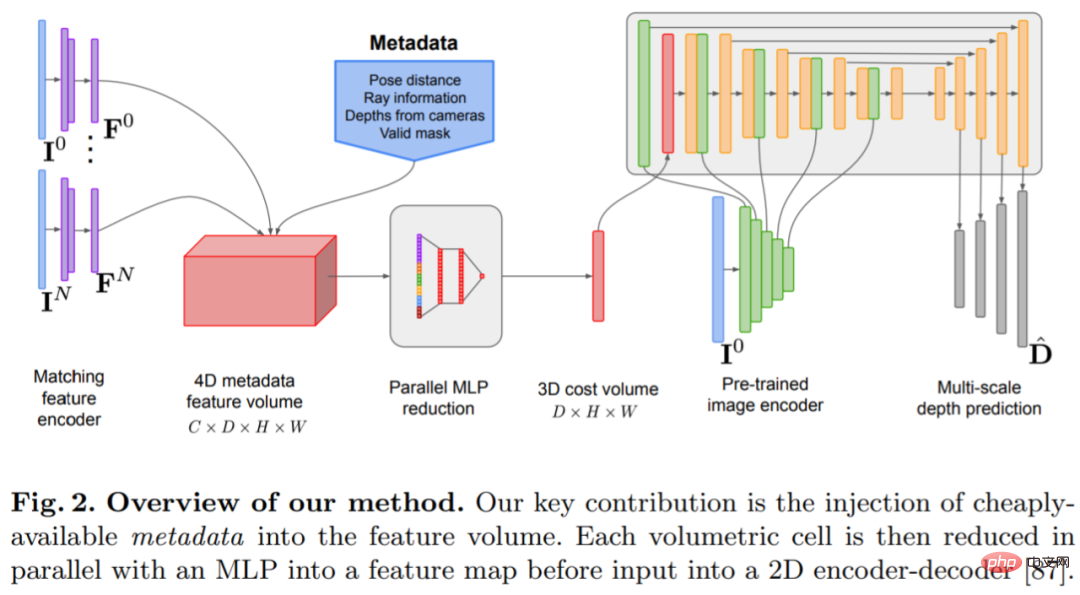
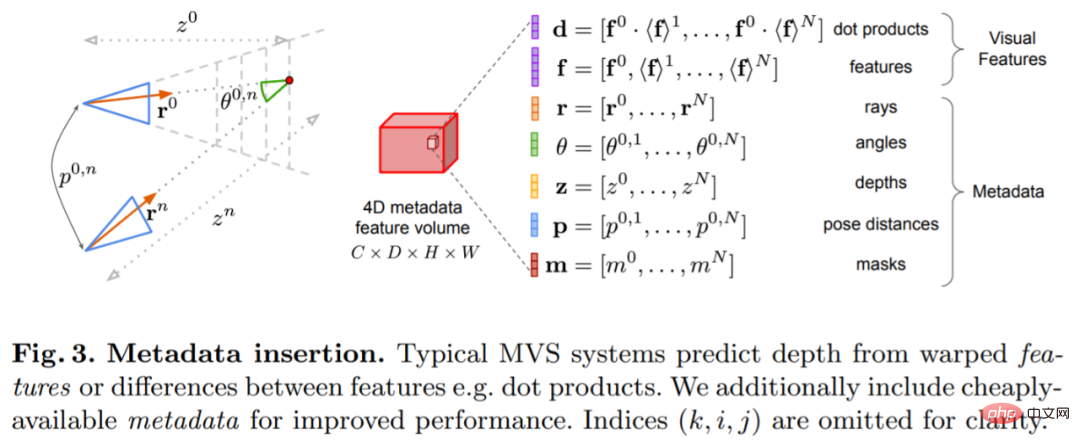
The key to this research is to inject existing metadata into the cost volume along with typical deep image features to allow network access to useful information, such as geometry and relative camera pose information. Figure 3 shows the feature volume construction in detail. By integrating this previously untapped information, our model is able to significantly outperform previous methods in depth prediction without expensive 4D cost volumes, complex temporal fusion, and Gaussian processes.
The study was implemented using PyTorch and used EfficientNetV2 S as the backbone, which has a decoder similar to UNet. In addition, they also used ResNet18 The first 2 blocks were used for matching feature extraction, the optimizer was AdamW, and it took 36 hours to complete on two 40GB A100 GPUs.
Network architecture designThe network is implemented based on the 2D convolutional encoder-decoder architecture. When building such a network, research has found that there are some important design choices that can significantly improve depth prediction accuracy, mainly including:
Baseline cost volume fusion: Although the RNN-based temporal fusion method are often used, but they significantly increase the complexity of the system. Instead, the study makes cost volume fusion as simple as possible and finds that simply adding the dot product matching costs between the reference view and each source view can give results that are competitive with SOTA depth estimation.
Image encoder and feature matching encoder: Previous research has shown that image encoder is very important for depth estimation, both in monocular and multi-view estimation. For example, DeepVideoMVS uses MnasNet as the image encoder, which has relatively low latency. The study recommends using a small but more powerful EfficientNetv2 S encoder, which significantly improves depth estimation accuracy, although this comes at the cost of an increased number of parameters and a 10% reduction in execution speed.
Fusing multi-scale image features to cost volume encoder: In 2D CNN-based depth stereo and multi-view stereo, image features are usually combined with cost volume output on a single scale. Recently, DeepVideoMVS proposes to stitch deep image features at multiple scales, adding skip connections between image encoders and cost volume encoders at all resolutions. This is helpful for LSTM-based fusion networks, and the study found that it is also important for their architecture.
Experiments
This study trained and evaluated the proposed method on the 3D scene reconstruction dataset ScanNetv2. Table 1 below uses the metrics proposed by Eigen et al. (2014) to evaluate the depth prediction performance of several network models.
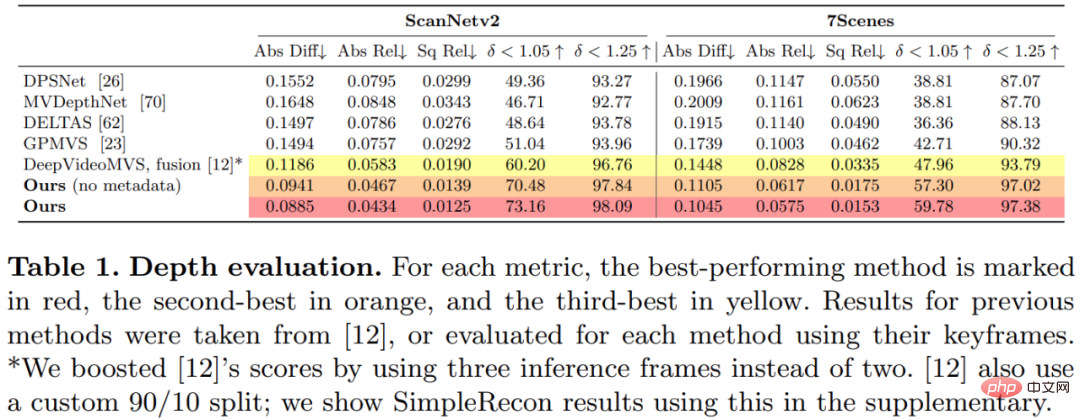
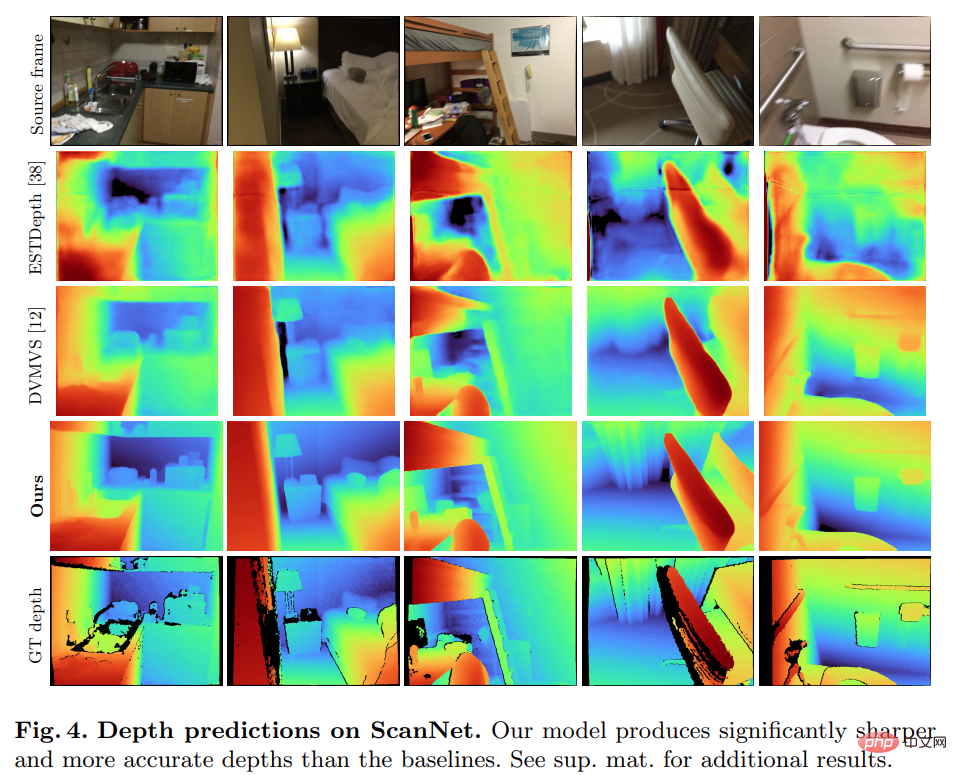
Surprisingly, the model proposed in this study does not use 3D convolution, but outperforms all baseline models in depth prediction indicators. Furthermore, baseline models that do not use metadata encoding also perform better than previous methods, indicating that a well-designed and trained 2D network is sufficient for high-quality depth estimation. Figures 4 and 5 below show qualitative results for depth and normal.

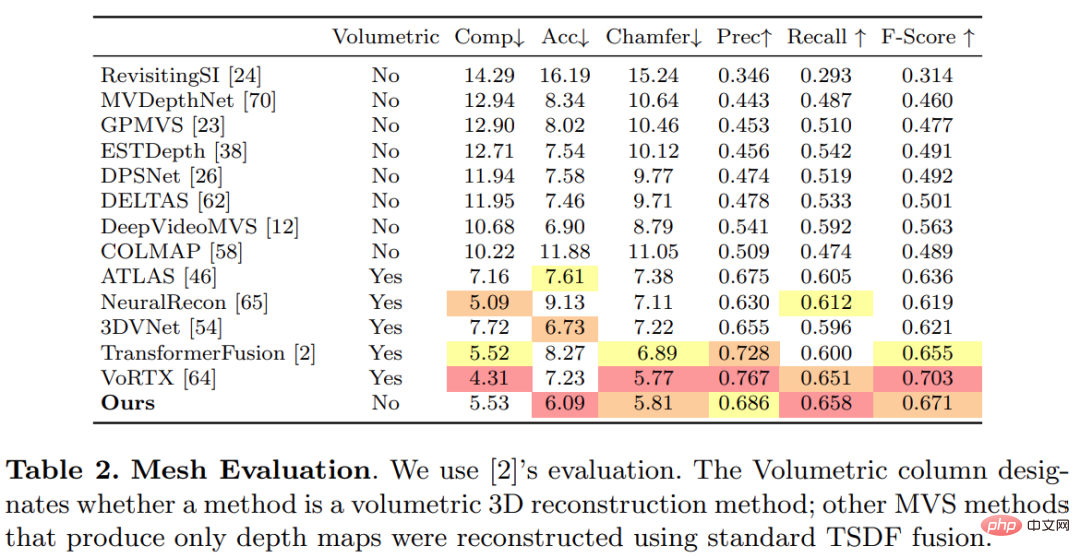
This study used the standard protocol established by TransformerFusion for 3D reconstruction evaluation. The results are shown in Table 2 below. .
For online and interactive 3D reconstruction applications, reducing sensor latency is critical. Table 3 below shows the ensemble computation time per frame for each model given a new RGB frame.

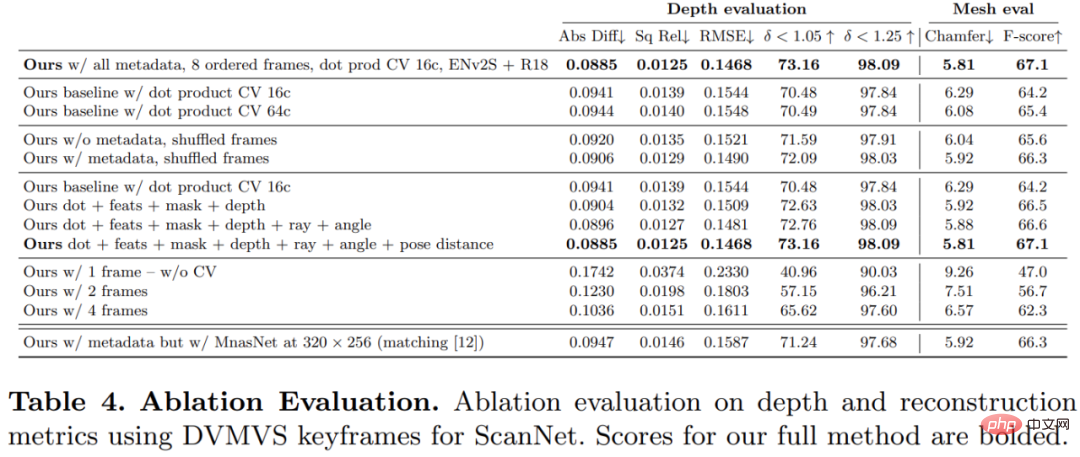
In order to verify the effectiveness of each component in the method proposed in this study, the researcher conducted an ablation experiment, and the results are shown in Table 4 below.
Interested readers can read the original text of the paper to learn more about the research details.
The above is the detailed content of A100 implements a 3D reconstruction method without 3D convolution, and only takes 70ms for each frame reconstruction. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



![WLAN expansion module has stopped [fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN expansion module has stopped [fix]
Feb 19, 2024 pm 02:18 PM
WLAN expansion module has stopped [fix]
Feb 19, 2024 pm 02:18 PM
If there is a problem with the WLAN expansion module on your Windows computer, it may cause you to be disconnected from the Internet. This situation is often frustrating, but fortunately, this article provides some simple suggestions that can help you solve this problem and get your wireless connection working properly again. Fix WLAN Extensibility Module Has Stopped If the WLAN Extensibility Module has stopped working on your Windows computer, follow these suggestions to fix it: Run the Network and Internet Troubleshooter to disable and re-enable wireless network connections Restart the WLAN Autoconfiguration Service Modify Power Options Modify Advanced Power Settings Reinstall Network Adapter Driver Run Some Network Commands Now, let’s look at it in detail
 How to solve win11 DNS server error
Jan 10, 2024 pm 09:02 PM
How to solve win11 DNS server error
Jan 10, 2024 pm 09:02 PM
We need to use the correct DNS when connecting to the Internet to access the Internet. In the same way, if we use the wrong dns settings, it will prompt a dns server error. At this time, we can try to solve the problem by selecting to automatically obtain dns in the network settings. Let’s take a look at the specific solutions. How to solve win11 network dns server error. Method 1: Reset DNS 1. First, click Start in the taskbar to enter, find and click the "Settings" icon button. 2. Then click the "Network & Internet" option command in the left column. 3. Then find the "Ethernet" option on the right and click to enter. 4. After that, click "Edit" in the DNS server assignment, and finally set DNS to "Automatic (D
 Fix 'Failed Network Error' downloads on Chrome, Google Drive and Photos!
Oct 27, 2023 pm 11:13 PM
Fix 'Failed Network Error' downloads on Chrome, Google Drive and Photos!
Oct 27, 2023 pm 11:13 PM
What is the "Network error download failed" issue? Before we delve into the solutions, let’s first understand what the “Network Error Download Failed” issue means. This error usually occurs when the network connection is interrupted during downloading. It can happen due to various reasons such as weak internet connection, network congestion or server issues. When this error occurs, the download will stop and an error message will be displayed. How to fix failed download with network error? Facing “Network Error Download Failed” can become a hindrance while accessing or downloading necessary files. Whether you are using browsers like Chrome or platforms like Google Drive and Google Photos, this error will pop up causing inconvenience. Below are points to help you navigate and resolve this issue
 Fix: WD My Cloud doesn't show up on the network in Windows 11
Oct 02, 2023 pm 11:21 PM
Fix: WD My Cloud doesn't show up on the network in Windows 11
Oct 02, 2023 pm 11:21 PM
If WDMyCloud is not showing up on the network in Windows 11, this can be a big problem, especially if you store backups or other important files in it. This can be a big problem for users who frequently need to access network storage, so in today's guide, we'll show you how to fix this problem permanently. Why doesn't WDMyCloud show up on Windows 11 network? Your MyCloud device, network adapter, or internet connection is not configured correctly. The SMB function is not installed on the computer. A temporary glitch in Winsock can sometimes cause this problem. What should I do if my cloud doesn't show up on the network? Before we start fixing the problem, you can perform some preliminary checks:
 What should I do if the earth is displayed in the lower right corner of Windows 10 when I cannot access the Internet? Various solutions to the problem that the Earth cannot access the Internet in Win10
Feb 29, 2024 am 09:52 AM
What should I do if the earth is displayed in the lower right corner of Windows 10 when I cannot access the Internet? Various solutions to the problem that the Earth cannot access the Internet in Win10
Feb 29, 2024 am 09:52 AM
This article will introduce the solution to the problem that the globe symbol is displayed on the Win10 system network but cannot access the Internet. The article will provide detailed steps to help readers solve the problem of Win10 network showing that the earth cannot access the Internet. Method 1: Restart directly. First check whether the network cable is not plugged in properly and whether the broadband is in arrears. The router or optical modem may be stuck. In this case, you need to restart the router or optical modem. If there are no important things being done on the computer, you can restart the computer directly. Most minor problems can be quickly solved by restarting the computer. If it is determined that the broadband is not in arrears and the network is normal, that is another matter. Method 2: 1. Press the [Win] key, or click [Start Menu] in the lower left corner. In the menu item that opens, click the gear icon above the power button. This is [Settings].
 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 Check network connection: lol cannot connect to the server
Feb 19, 2024 pm 12:10 PM
Check network connection: lol cannot connect to the server
Feb 19, 2024 pm 12:10 PM
LOL cannot connect to the server, please check the network. In recent years, online games have become a daily entertainment activity for many people. Among them, League of Legends (LOL) is a very popular multiplayer online game, attracting the participation and interest of hundreds of millions of players. However, sometimes when we play LOL, we will encounter the error message "Unable to connect to the server, please check the network", which undoubtedly brings some trouble to players. Next, we will discuss the causes and solutions of this error. First of all, the problem that LOL cannot connect to the server may be
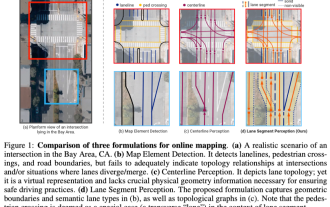 ICLR'24 new ideas without pictures! LaneSegNet: map learning based on lane segmentation awareness
Jan 19, 2024 am 11:12 AM
ICLR'24 new ideas without pictures! LaneSegNet: map learning based on lane segmentation awareness
Jan 19, 2024 am 11:12 AM
Written above & The author’s personal understanding of maps as key information for downstream applications of autonomous driving systems is usually represented by lanes or center lines. However, the existing map learning literature mainly focuses on detecting geometry-based topological relationships of lanes or sensing centerlines. Both methods ignore the inherent relationship between lane lines and center lines, that is, lane lines bind center lines. Although simply predicting two types of lanes in one model are mutually exclusive in the learning objective, this paper proposes lanesegment as a new representation that seamlessly combines geometric and topological information, thus proposing LaneSegNet. This is the first end-to-end mapping network that generates lanesegments to obtain a complete representation of road structure. LaneSegNet has two levels
