
 Technology peripherals
AI
Accelerating autonomous vehicle development and verification: A closer look at DRIVE Replicator synthetic data generation technology
Technology peripherals
AI
Accelerating autonomous vehicle development and verification: A closer look at DRIVE Replicator synthetic data generation technology
Accelerating autonomous vehicle development and verification: A closer look at DRIVE Replicator synthetic data generation technology

At the GTC conference held in September, NVIDIA product manager Gautham Sholingar gave a complete introduction to NVIDIA's latest developments in long-tail scenario training over the past year under the title "Synthetic Data Generation: Accelerating the Development and Verification of Self-Driving Vehicles" Progress and related experiences, specifically exploring how developers can use DRIVE Replicator to generate diverse synthetic datasets with accurate ground-truth data labels to accelerate the development and validation of autonomous vehicles. The lecture was full of useful information and aroused widespread attention and discussion in the industry. This article summarizes and organizes the essence of this sharing to help everyone better understand DRIVE Replicator and the synthetic data generation of autonomous driving perception algorithms.

Figure 1
Over the past year, NVIDIA has been using DRIVE Replicator to generate data for training autonomous driving perception algorithms. Positive progress has been made on synthetic datasets. Figure 1 shows some of the long-tail scenario challenges that NVIDIA is currently solving:
- The first row on the left shows vulnerable road users (VRUs) near the reversing camera. VRU is an important object class for any autonomous driving perception algorithm. In this case, we focus on detecting children near the reversing fisheye camera. Since data collection and data labeling in the real world is quite challenging, this is an important security use case.
- The middle picture in the first row shows accident vehicle detection. Autonomous driving perception algorithms need exposure to rare and uncommon scenes to help make object detection algorithms reliable. There are very few accident vehicles in real-world datasets. DRIVE Replicator helps train such networks by helping developers create unexpected events (such as car rollovers) under various environmental conditions.
- The picture on the right side of the first row shows traffic sign detection. In other cases, manually labeling data is time-consuming and error-prone. DRIVE Replicator helps developers generate datasets of hundreds of traffic signs and traffic lights in a variety of environmental conditions and quickly train networks to solve diverse real-world problems.
- Finally, there are many objects that are not common in urban environments, such as specific traffic props and certain types of vehicles. DRIVE Replicator helps developers increase the frequency of these rare objects in datasets and help augment real-world data collection with targeted synthetic data.
The above functions are being implemented through NVIDIA DRIVE Replicator.
Understand DRIVE Replicator and its associated ecosystem
DRIVE Replicator is part of the DRIVE Sim tool suite and can be used for autonomous driving simulation.
DRIVE Sim is NVIDIA's leading self-driving car simulator built on Omniverse, which can perform physically accurate sensor simulation on a large scale. Developers can run repeatable simulations on a workstation and then scale to batch mode in the data center or cloud. DRIVE Sim is a modular platform built on powerful open standards such as USD, allowing users to introduce their own functionality through Omniverse extensions.
DRIVE Sim includes multiple apps including DRIVE Replicator. DRIVE Replicator mainly provides a series of functions focused on the generation of synthetic data for training and algorithm verification of autonomous vehicles. DRIVE Sim and DRIVE Constellation also support full-stack autonomous driving simulation at all levels, including software-in-the-loop, hardware-in-the-loop, and other in-the-loop simulation tests (models, plants, humans, and more).
The difference between DRIVE Sim and traditional autonomous driving simulation tools is that when creating synthetic data sets, traditional autonomous driving simulation tools are often combined with professional game engines to restore sufficiently realistic scenes. However, for autonomous driving simulation, this is far from enough, and core requirements including physical accuracy, repeatability, and scale need to be addressed.

Figure 2
Before further introducing DRIVE Replicator, let me first introduce several related concepts (Figure 2). Especially Omniverse, to help everyone better understand the underlying technical support related to DRIVE Replicator.
First, learn about Omniverse, NVIDIA’s engine for large-scale simulations. Omniverse is built on USD (Universal Scene Description, an extensible universal language for describing virtual worlds) developed by Pixar. USD is a single source of truth-value data for the entire simulation and all aspects of the simulation (including sensors, 3D environment). These scenes built entirely through USD allow developers to have hierarchical access to every element in the simulation, and generate diverse data for subsequent generation. lay the foundation for a specialized synthetic data set.
Second, Omniverse provides real-time ray tracing effects to support sensors in DRIVE Sim. RTX is one of NVIDIA's important advances in computational graphics, leveraging an optimized ray tracing API that focuses on physical accuracy to ensure complex behavior of cameras, lidar, millimeter-wave radar and ultrasonic sensors such as multiple Reflections, multipath effects, rolling shutter, and lens distortion) are natively modeled.
Third, NVIDIA Omniverse is an easily scalable open platform designed for virtual collaboration and physically accurate real-time simulation. It can run workflows in the cloud or data center and achieve multi-GPU and node parallelism. Rendering and data generation.
Fourth, Omniverse and DRIVE Sim adopt open and modular designs, and a huge partner ecosystem has been formed around this platform. These partners can provide 3D materials, sensors, vehicle and traffic models, verification tools, etc.
Fifth, the core of Omniverse collaboration is Nucleus. Nucleus has data storage and access control functions, and it can serve as a backend for multiple users. Centralized content repository with DRIVE Sim to decouple runtime from content, improve version control, and create a single reference point for all footage, scenes, and metadata.
DRIVE Sim is a platform. NVIDIA adopts an ecological cooperation approach to build the platform, allowing partners to contribute to this universal platform. At present, DRIVE Sim has established a huge partner ecosystem, covering 3D assets, environmental sensor models, verification and other fields. With the DRIVE Sim SDK, partners can easily introduce their own sensor, traffic and vehicle dynamics models and extend their core simulation capabilities. Developers can not only write extensions in Omniverse and easily add new features, but also enjoy the benefits of developing on a common platform - Omniverse has connected several key partners who provide important work related to autonomous driving development flow.
How to use DRIVE Replicator to generate synthetic data sets and true value data
Next, I will explain how the above contents are combined, and the five main tasks of DRIVE Replicator to generate synthetic data. Steps (Figure 3): Content - DRIVE Sim Runtime - Sensing - Randomization - Data Writers.
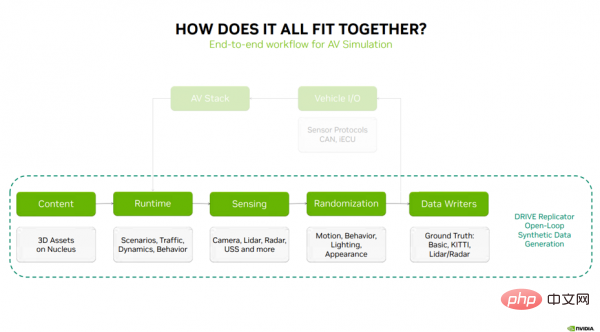
Figure 3
The first step in the simulation process is the 3D content and materials stored on the Nucleus server. These assets are passed to DRIVE Sim Runtime, the core technology for executing scenarios, traffic models, vehicle dynamics and behavior. DRIVE Sim Runtime can be used with RTX ray tracing-based cameras, lidar, millimeter wave radar and perception technology from the USS. The next step is to introduce variety into the data through randomization of motion, behavior, lighting, and appearance. For closed-loop simulation, the next step is to connect the simulation to the autonomous driving stack through vehicle I/O, which typically consists of sensor protocols, CAN messages, and a virtual ECU (which sends important information to the autonomous driving stack to close the loop).
For synthetic data generation, this is an open loop process that sends randomized sensor data to data writers, and these data writers can output for training autonomous driving perception The truth label of the algorithm. The above steps represent a complete workflow for synthetic data generation.
- Content (content)
As mentioned above, the first step in the simulation process is the 3D content and materials stored on the Nucleus server . Where does this content come from? How to get it? What are the standards or requirements?
Over the past few years, NVIDIA has worked with multiple content partners to build a vast ecosystem of 3D asset providers, including vehicles, props, pedestrians, vegetation and 3D environments, ready to be used in DRIVE Sim used in.
One thing to note is that even if you obtain these assets from the market, it does not mean that you can start simulation work. You also need to make these assets ready for simulation, and this is SimReady Useful place.
An important part of the expansion is working with 3D asset providers and providing them with the tools they need to ensure that certain conventions, naming, asset rigging, Semantic labels and physical properties.
SimReady Studio helps content providers convert their existing assets into simulation-ready USD assets that can be loaded onto DRIVE Sim, including 3D environments, dynamic assets and static props.
So, what is SimReady? You can think of it as a converter that helps ensure that 3D assets in DRIVE Sim and Replicator are ready to support end-to-end simulation workflows. SimReady has several key elements, including:
- Each asset must follow a set of conventions regarding orientation, naming, geometry, etc. to ensure consistency;
- Semantic tags and a well-defined ontology for annotating each element of the asset. This is crucial for generating ground-truth labels for perception;
- Support for rigid body physics and dynamics makes the generated datasets look realistic and closes the gap between simulation and reality from a kinematic perspective;
- The next step is to ensure the asset follows specific materials and naming conventions to ensure the asset is ready for RTX ray tracing and produces realistic responses to active sensors such as lidar, millimeter wave radar and ultrasonic sensors;
- Another common aspect is rigging 3D assets to enable lighting changes, door actuation, pedestrian walking operations, etc.;
- The last part is performance optimization for real-time high-fidelity sensor simulation.
Based on the above understanding, let’s take a look at the process of how to use SimReady studio to obtain assets that can be used in DRIVE Sim.
Assume that this process starts with purchasing assets from the 3D market. The first step is to import this asset into SimReady Studio. This can also be done in bulk, or by batch importing multiple assets to complete this step.
After importing, the material names of these content assets will be updated, and their material properties will also be updated, expanding to include properties such as reflectivity and roughness.
This is important to ensure physically realistic rendering data quality, and to ensure that the material system interacts with all RTX sensor types, not just those operating in the visible spectrum.
The next step involves updating semantic tags and tags. Why is this step important? Having the right labels means the data generated using the asset can be used to train AV algorithms. Additionally, DRIVE Sim and Omniverse use Nucleus as a central asset repository. There are thousands of content assets on Nucleus, and having searchable tags with associated thumbnails will help new users find an asset more easily.
Next, start defining the collision volume and geometry of the object and observe how the content asset behaves from a physical perspective. The object's physical and mass properties are then modified to create the desired behavior.
The final step in the entire process is to validate assets to ensure that these content assets adhere to the correct conventions. Simulation-ready USD assets can now be saved and re-imported into NVIDIA Omniverse and DRIVE Sim. The biggest advantage of building a scene via USD is that all metadata created in the previous steps is transferred with the final asset and is hierarchically linked to the USD of the main object, laying the foundation for subsequent generation of diverse synthetic datasets.
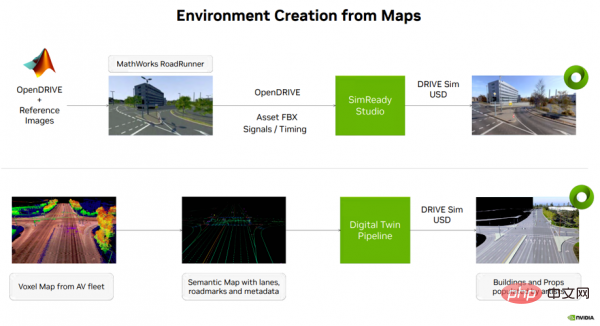
Figure 4
Back to self-driving car simulation content creation, there are usually several ways to create an environment from map data (see Figure 4). One option is to use MathWorks' Roadrunner tool to create a 3D environment on an open NVIDIA DRIVE map (multimodal map platform). The output of this step, along with semantic map information, signal timing, etc., is then transferred to SimReady Studio, where the 3D environment can be converted into a USD asset that can be loaded onto DRIVE Sim.
Another option is to use voxel map data from a self-driving fleet and extract semantic map information such as lanes, road signs, and other metadata. This information is created via a digital twin, resulting in a USD asset that can be loaded onto DRIVE Sim.
The above two types of USD environments will be used to support end-to-end (E2E) simulation testing of autonomous vehicles and synthetic data generation workflows.
- DRIVE Sim Runtime
Next I will introduce you to the second step of simulation - DRIVE Sim Runtime, which lays the foundation for our DRIVE Replicator The basis for all features in . used to generate synthetic datasets.
DRIVE Sim Runtime is an open, modular and extensible component. What does this mean in practice (see Figure 5)?
First, it is built on scenes, where developers can define the specific position, movement, and interaction of objects in the scene. These scenarios can be defined in Python or using the scenario editor UI and saved for later use.
Second, it supports integration with custom vehicle dynamics packages via the DRIVE Sim SDK, either as a step in the process or as a co-simulation with DRIVE Sim 2.0.
Third, traffic model. DRIVE Sim has a rich vehicle model interface, and with the help of the Runtime, developers can introduce their own vehicle dynamics or configure existing rules-based traffic models.
Fourth, the action system, which contains a rich library of predefined actions (such as lane changes), time triggers that can be used to create scenes of interactions between different objects, etc.
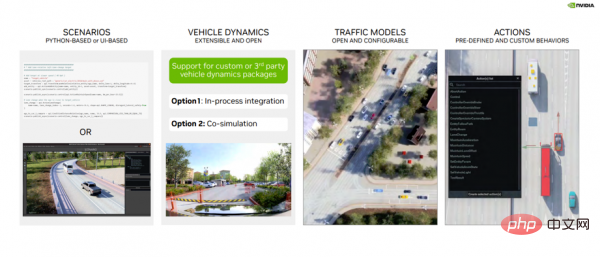
Figure 5
Let’s briefly review the previous content: the first step of the simulation process, after SimReady conversion, simulation Ready 3D content and assets are stored on the Nucleus server. In the second step, these materials are passed to DRIVE Sim Runtime, which is the core technology for executing scenarios, traffic models, vehicle dynamics and behavior, laying the foundation for all subsequent functions to generate synthetic data sets.
- Sensing
Before generating data, sensors need to be used to set up the target test vehicle. Using the Ego Configurator tool, developers can select specific vehicles and add them to the scene.
In addition, developers can also move vehicles in the scene and add sensors to the vehicles. The Ego configurator tool supports universal and Hyperion 8 sensors.
After adding the sensor to the vehicle, developers can also change parameters such as FOV, resolution, sensor name, and intuitively configure sensor locations on the vehicle.
Users can also view previews from the sensor POV and visualize the field of view in a 3D environment before creating data generation scenes.
This tool can help developers quickly prototype different configurations and visualize the coverage achieved by sensing tasks.
- Randomization (domain randomization)
Now let’s briefly introduce the fourth step of the simulation process, domain randomization, how to pass motion and behavior , randomization of lighting and appearance to introduce variety into the data.
This involves another way of creating scenes, using Python. DRIVE Replicator's Python API allows developers to query the open NVIDIA DRIVE Map and place a range of static and dynamic assets in a context-aware manner. Some randomizers will focus on how to teleport an autonomous vehicle from one point to the next, how to generate objects around the autonomous vehicle, and generate different synthetic datasets from this. These complex-sounding operations are easily accomplished because the user has direct control over the USD scene and all objects in that environment.
Another important step when creating synthetic datasets for training is the ability to introduce changes in the appearance of the 3D scene. The powerful functions of USD were also mentioned above. For example, scenarios built through USD allow developers to have hierarchical access to every element in the simulation. SimReady's API uses USD to quickly set up features in a scene.
Let’s look at an example (see Figure 6): the road surface is a little wet, but when we set different parameters, the wetness level of the road surface will change. We can make similar changes to aspects such as solar azimuth and solar altitude to generate realistic datasets under a range of environmental conditions.
Another takeaway is the ability to enable lighting and appearance changes, all of which are available through the SimReady API and USD.

Figure 6
#One of the main advantages of DRIVE Sim is the RTX sensor workflow, which supports a variety of sensors (see Figure 7 ), including universal and off-the-shelf models for cameras, lidar, conventional radar and USS. In addition, DRIVE Sim offers full support for the NVIDIA DRIVE Hyperion sensor suite, allowing users to begin algorithm development and validation work in a virtual environment.
In addition, DRIVE Sim has a powerful and versatile SDK that enables partners to use NVIDIA’s ray tracing API to implement complex sensor models while protecting their IP and proprietary algorithms. This ecosystem has grown over the years, and NVIDIA is working with partners to bring new types of sensors, such as imaging radar, FMCW lidar, and more, into DRIVE Sim.

Figure 7
- Data Writers
Now, the focus shifts to generating ground truth data and how to visualize this information. This involves the last step in the simulation flow, the data writer. In this process, randomized sensor data is sent to data writers, which output ground truth labels used to train autonomous driving perception algorithms.
The data writer is a Python script used to generate ground truth labels required for training autonomous driving perception algorithms.
NVIDIA DRIVE Replicator comes with template writers such as base writer and KITTI writer.
The base writer covers a wide range of real-world data labels, including object classes, tight and loose bounding boxes in 2D and 3D, semantic and instance masks, depth output, occlusions, normals, and more.
Similarly, there are lidar/normal radar writers that can be used to export laser point cloud data to numpy arrays, or to any relevant custom format along with bounding boxes, semantics and object labels .
These writers provide examples for developers to configure their own writers based on custom markup formats and extend their data generation efforts.
Finally, I would like to introduce to you an exciting software, Replicator Insight created by the Omniverse team.
Replicator Insight is a standalone application built on Omniverse Kit that can be used to inspect rendered synthetic datasets and overlay various ground truth labels for training.
Replicator Insight supports all synthetic data generation use cases, including DRIVE, Isaac, and Omniverse Replicator.
Let’s look at an example (see Figure 8): Users can load data generated by DRIVE Replicator in this visualization tool and turn on and off different truth labels for different object categories in the scene.
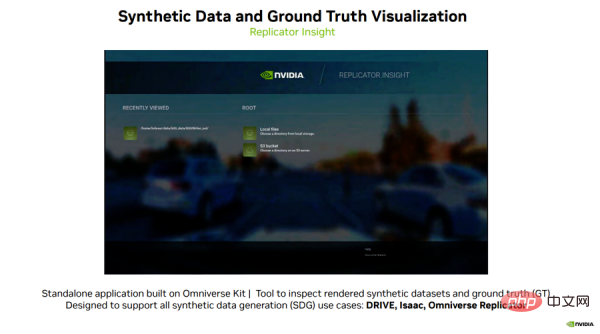
Figure 8
With this visualization tool, users can play videos, comb through data sets, and even view depth and RGB data and compare between different views.
Users can also change parameters such as playback frame rate and depth range, or quickly visualize data sets before self-driving car training.
This will help developers easily understand new truth label types and parse complex data sets.
Overall, this is a powerful tool that allows users to gain new insights every time they look at data, whether it is real or synthetic.
Summary
The above summarizes the latest development of DRIVE Replicator in the past year, and shares how developers can use DRIVE Replicator to generate diverse synthetic data sets and accurate ground truth data tags to accelerate the development and validation of autonomous vehicles. NVIDIA has made exciting progress in generating high-quality sensor data sets for a variety of real-world use cases, and we look forward to further communication with you!
The above is the detailed content of Accelerating autonomous vehicle development and verification: A closer look at DRIVE Replicator synthetic data generation technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
