

Python writing poetry solitaire program

Poetry Corpus
First, we use a Python crawler to crawl poems and create a corpus. The crawled pages are as follows:
Crawled poems
Since this article is mainly to try to show the ideas of the project, therefore, only the crawled There are 300 Tang poems, 300 ancient poems, 300 Song poems, and selected Song poems on the page, a total of more than 1,100 poems. In order to speed up the crawler, the crawler is implemented concurrently and saved to the poem.txt file. The complete Python program is as follows:
import re
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 爬取的诗歌网址
urls = ['https://so.gushiwen.org/gushi/tangshi.aspx',
'https://so.gushiwen.org/gushi/sanbai.aspx',
'https://so.gushiwen.org/gushi/songsan.aspx',
'https://so.gushiwen.org/gushi/songci.aspx'
]
poem_links = []
# 诗歌的网址
for url in urls:
# 请求头部
headers = {: 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
content = soup.find_all('div', class_="sons")[0]
links = content.find_all('a')
for link in links:
poem_links.append('https://so.gushiwen.org'+link['href'])
poem_list = []
# 爬取诗歌页面
def get_poem(url):
#url = 'https://so.gushiwen.org/shiwenv_45c396367f59.aspx'
# 请求头部
headers = {: 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
poem = soup.find('div', class_='contson').text.strip()
poem = poem.replace(' ', '')
poem = re.sub(re.compile(r"([sS]*?)"), '', poem)
poem = re.sub(re.compile(r"([sS]*?)"), '', poem)
poem = re.sub(re.compile(r"。([sS]*?)"), '', poem)
poem = poem.replace('!', '!').replace('?', '?')
poem_list.append(poem)
# 利用并发爬取
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(get_poem, url) for url in poem_links]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
# 将爬取的诗句写入txt文件
poems = list(set(poem_list))
poems = sorted(poems, key=lambda x:len(x))
for poem in poems:
poem = poem.replace('《','').replace('》','')
.replace(':', '').replace('“', '')
print(poem)
with open('F://poem.txt', 'a') as f:
f.write(poem)
f.write('
')This program crawls more than 1,100 poems and saves the poems to the poem.txt file to form our poetry corpus. Of course, these poems cannot be used directly, and the data needs to be cleaned. For example, some poems have irregular punctuation, some are not poems, but are just the preface of poems, etc. This process requires manual operation, although it is a little troublesome, but for the subsequent phrasing of the poems The effect is also worth it.
Poetry segmentation
With the poetry corpus, we need to segment the poems. The standard for segmentation is: according to the ending. ? ! For segmentation, this can be achieved using regular expressions. After that, write the poems with good sentences into a dictionary: the key (key) is the pinyin of the first word of the sentence, and the value (value) is the poem corresponding to the pinyin, and save the dictionary as a pickle file. The complete Python code is as follows:
import re
import pickle
from xpinyin import Pinyin
from collections import defaultdict
def main():
with open('F://poem.txt', 'r') as f:
poems = f.readlines()
sents = []
for poem in poems:
parts = re.findall(r'[sS]*?[。?!]', poem.strip())
for part in parts:
if len(part) >= 5:
sents.append(part)
poem_dict = defaultdict(list)
for sent in sents:
print(part)
head = Pinyin().get_pinyin(sent, tone_marks='marks', splitter=' ').split()[0]
poem_dict[head].append(sent)
with open('./poemDict.pk', 'wb') as f:
pickle.dump(poem_dict, f)
main()We can take a look at the contents of the pickle file (poemDict.pk):

Contents of the pickle file (part)
Of course, one pinyin can correspond to multiple poems.
Poetry Solitaire
Read the pickle file, write a program, and run the program as an exe file. In order to avoid errors when compiling the exe file, we need to rewrite the init.py file of the xpinyin module, copy all the code of the file to mypinyin.py, and replace the following code in the code
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
'Mandarin.dat')is rewritten as
data_path = os.path.join(os.getcwd(), 'Mandarin.dat')
so that we complete the mypinyin.py file. Next, we need to write the code for poetry solitaire (Poem_Jielong.py). The complete code is as follows:
import pickle
from mypinyin import Pinyin
import random
import ctypes
STD_INPUT_HANDLE = -10
STD_OUTPUT_HANDLE = -11
STD_ERROR_HANDLE = -12
FOREGROUND_DARKWHITE = 0x07 # 暗白色
FOREGROUND_BLUE = 0x09 # 蓝色
FOREGROUND_GREEN = 0x0a # 绿色
FOREGROUND_SKYBLUE = 0x0b # 天蓝色
FOREGROUND_RED = 0x0c # 红色
FOREGROUND_PINK = 0x0d # 粉红色
FOREGROUND_YELLOW = 0x0e # 黄色
FOREGROUND_WHITE = 0x0f # 白色
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
# 设置CMD文字颜色
def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool
# 重置文字颜色为暗白色
def resetColor():
set_cmd_text_color(FOREGROUND_DARKWHITE)
# 在CMD中以指定颜色输出文字
def cprint(mess, color):
color_dict = {
: FOREGROUND_BLUE,
: FOREGROUND_GREEN,
: FOREGROUND_SKYBLUE,
: FOREGROUND_RED,
: FOREGROUND_PINK,
: FOREGROUND_YELLOW,
: FOREGROUND_WHITE
}
set_cmd_text_color(color_dict[color])
print(mess)
resetColor()
color_list = ['蓝色','绿色','天蓝色','红色','粉红色','黄色','白色']
# 获取字典
with open('./poemDict.pk', 'rb') as f:
poem_dict = pickle.load(f)
#for key, value in poem_dict.items():
#print(key, value)
MODE = str(input('Choose MODE(1 for 人工接龙, 2 for 机器接龙): '))
while True:
try:
if MODE == '1':
enter = str(input('
请输入一句诗或一个字开始:'))
while enter != 'exit':
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('无法接这句诗。
', '红色')
MODE = 0
break
else:
cprint('
机器回复:%s'%random.sample(poem_dict[tail], 1)[0], random.sample(color_list, 1)[0])
enter = str(input('你的回复:'))[:-1]
MODE = 0
if MODE == '2':
enter = input('
请输入一句诗或一个字开始:')
for i in range(10):
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('------>无法接下去了啦...', '红色')
MODE = 0
break
else:
answer = random.sample(poem_dict[tail], 1)[0]
cprint('(%d)--> %s' % (i+1, answer), random.sample(color_list, 1)[0])
enter = answer[:-1]
print('
(*****最多展示前10回接龙。*****)')
MODE = 0
except Exception as err:
print(err)
finally:
if MODE not in ['1','2']:
MODE = str(input('
Choose MODE(1 for 人工接龙, 2 for 机器接龙): '))Now the structure of the entire project is as follows (the Mandarin.dat file is copied from the folder corresponding to the xpinyin module):
Project file
Switch to the folder and enter the following command to generate the exe file:
pyinstaller -F Poem_jielong.py
The generated exe file is Poem_jielong.exe, located in the dist folder of this folder. In order for the exe to run successfully, the poemDict.pk and Mandarin.dat files need to be copied to the dist folder.
Test run
Run the Poem_jielong.exe file, the page is as follows:
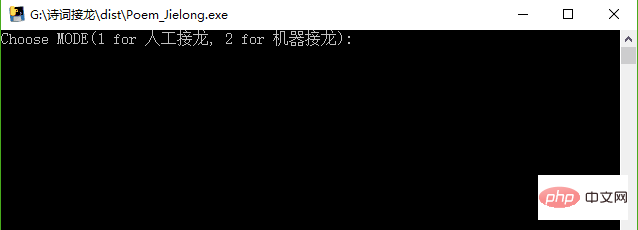
exe file start page
This project There are two modes of Poetry Solitaire. One is manual Solitaire, where you first enter a poem or a word, and then the computer replies with a sentence. You reply with a sentence and are responsible for the rules of Poetry Solitaire; the other mode is machine Solitaire, where you Enter a poem or a word first, and the machine will automatically output the following Solitaire poems (up to 10).Test the manual Solitaire mode first:
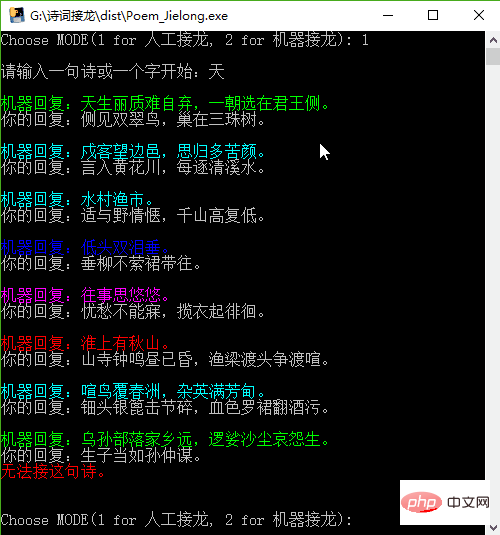
artificial Solitaire
Then test the machine Solitaire mode:
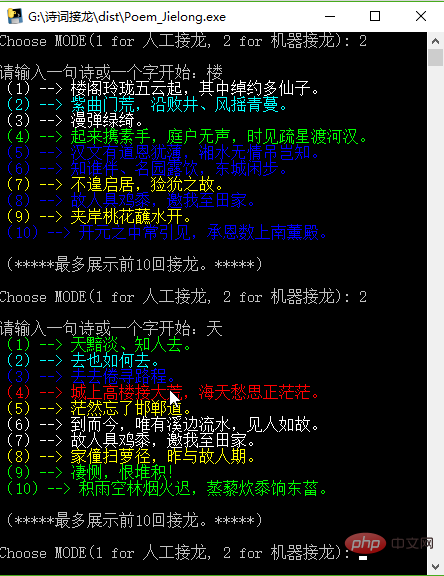
The above is the detailed content of Python writing poetry solitaire program. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
MySQL has a free community version and a paid enterprise version. The community version can be used and modified for free, but the support is limited and is suitable for applications with low stability requirements and strong technical capabilities. The Enterprise Edition provides comprehensive commercial support for applications that require a stable, reliable, high-performance database and willing to pay for support. Factors considered when choosing a version include application criticality, budgeting, and technical skills. There is no perfect option, only the most suitable option, and you need to choose carefully according to the specific situation.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.
 HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, high-level scalable Python database HadiDB (hadidb) is a lightweight database written in Python, with a high level of scalability. Install HadiDB using pip installation: pipinstallhadidb User Management Create user: createuser() method to create a new user. The authentication() method authenticates the user's identity. fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 Does mysql need the internet
Apr 08, 2025 pm 02:18 PM
Does mysql need the internet
Apr 08, 2025 pm 02:18 PM
MySQL can run without network connections for basic data storage and management. However, network connection is required for interaction with other systems, remote access, or using advanced features such as replication and clustering. Additionally, security measures (such as firewalls), performance optimization (choose the right network connection), and data backup are critical to connecting to the Internet.
 Can mysql workbench connect to mariadb
Apr 08, 2025 pm 02:33 PM
Can mysql workbench connect to mariadb
Apr 08, 2025 pm 02:33 PM
MySQL Workbench can connect to MariaDB, provided that the configuration is correct. First select "MariaDB" as the connector type. In the connection configuration, set HOST, PORT, USER, PASSWORD, and DATABASE correctly. When testing the connection, check that the MariaDB service is started, whether the username and password are correct, whether the port number is correct, whether the firewall allows connections, and whether the database exists. In advanced usage, use connection pooling technology to optimize performance. Common errors include insufficient permissions, network connection problems, etc. When debugging errors, carefully analyze error information and use debugging tools. Optimizing network configuration can improve performance
 Does mysql need a server
Apr 08, 2025 pm 02:12 PM
Does mysql need a server
Apr 08, 2025 pm 02:12 PM
For production environments, a server is usually required to run MySQL, for reasons including performance, reliability, security, and scalability. Servers usually have more powerful hardware, redundant configurations and stricter security measures. For small, low-load applications, MySQL can be run on local machines, but resource consumption, security risks and maintenance costs need to be carefully considered. For greater reliability and security, MySQL should be deployed on cloud or other servers. Choosing the appropriate server configuration requires evaluation based on application load and data volume.
