
 Technology peripherals
AI
The non-invasive multi-modal learning model developed by the Institute of Automation realizes brain signal decoding and semantic analysis
Technology peripherals
AI
The non-invasive multi-modal learning model developed by the Institute of Automation realizes brain signal decoding and semantic analysis
The non-invasive multi-modal learning model developed by the Institute of Automation realizes brain signal decoding and semantic analysis


- ##Paper address: https://ieeexplore.ieee.org/document/10089190
- Code address: https://github.com/ChangdeDu/BraVL
- ##Data address: https:// figshare.com/articles/dataset/BraVL/17024591##too long not to read version
This study
First time Combining brain, visual and language knowledge, through multi-modal learning, it is possible to decode new visual categories from human brain activity records with zero samples. This article also contributes three "brain-picture-text" three-modal matching data sets. The experimental results indicate some interesting conclusions and cognitive insights: 1) Decoding new visual categories from human brain activity is achievable with high accuracy; 2) Using Decoding models that combine visual and linguistic features perform better than models using only one of them; 3) visual perception may be accompanied by linguistic influences to represent the semantics of visual stimuli. These findings not only shed light on the understanding of the human visual system, but also provide new ideas for future brain-computer interface technology. The code and data sets for this study are open source.
Research background
Decoding human visual neural representation is a challenge of important scientific significance, which can reveal the visual processing mechanism and promote the development of brain science and artificial intelligence. However,
current neural decoding methods are difficult to generalize to new categories beyond the training data. There are two main reasons: First, the existing methods do not fully utilize the many features behind neural data. Modal semantic knowledge, and second, there is little available pairing (stimulus-brain response) training data. Research shows that human perception and recognition of visual stimuli are affected by visual features and people’s previous experiences. For example, when we see a familiar object, our brains naturally retrieve knowledge related to that object. As shown in Figure 1 below, cognitive neuroscience research on dual coding theory [9] believes that specific concepts are encoded in the brain both visually and linguistically, where language, as an effective prior experience, helps to shape Representations generated by vision.
Therefore, the author believes that to better decode the recorded brain signals, not only the actual presented visual semantic features should be used, but also richer features related to the visual target object should be used. Decoding is performed by a combination of linguistic semantic features.
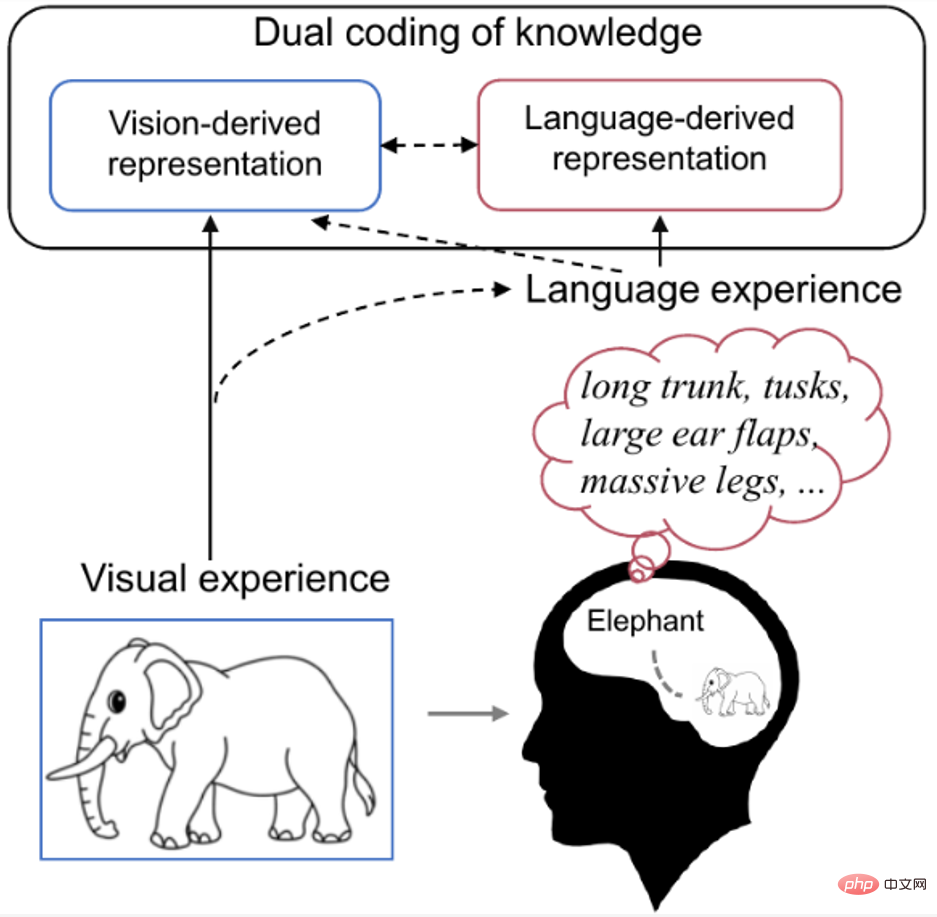
Figure 1. Dual encoding of knowledge in the human brain. When we see pictures of elephants, we will naturally retrieve elephant-related knowledge in our minds (such as long trunks, long teeth, big ears, etc.). At this point, the concept of elephant is encoded in the brain in both visual and verbal form, with language serving as a valid prior experience that helps shape the representation produced by vision. As shown in Figure 2 below, since it is very expensive to collect human brain activities of various visual categories, researchers usually only have very limited brain activities of visual categories. However, image and text data are abundant and can provide additional useful information.
The method in this article can make full use of all types of data (trimodal, bimodal and unimodal) to improve the generalization ability of neural decoding.
Figure 2. Image stimuli, elicited brain activities, and their corresponding text data. We can only collect brain activity data for a few categories, but image and/or text data can easily be collected for almost all categories. Therefore, for known categories, we assume that brain activity, visual images, and corresponding text descriptions are all available for training, whereas for new categories, only visual images and text descriptions are available for training. The test data is brain activity data from new categories.
"Brain-Picture-Text" multi-modal learning
As shown in Figure 3A below, the key to this method is to combine each model The learned distributions are aligned into a shared latent space that contains the essential multi-modal information relevant to the new categories.
Specifically, the author proposesA multi-modal autoencoding variational Bayesian learning framework, where a Mixture-of-Products-of-Experts (MoPoE) model is used to infer a latent encoding to achieve joint generation of all three modalities. In order to learn more relevant joint representations and improve data efficiency when brain activity data is limited, the authors further introduce intra-modal and inter-modal mutual information regularization terms. Furthermore, BraVL models can be trained under various semi-supervised learning scenarios to incorporate additional visual and textual features of large-scale image categories.
In Figure 3B, the authorstrain an SVM classifier from latent representations of visual and textual features of new categories. It should be noted that the encoders E_v and E_t are frozen in this step and only the SVM classifier (gray module) will be optimized.
In the application, as shown in Figure 3C, the input of this method is only the new category of brain signals and does not require other data , so it can be easily applied to large Most neural decoding scenarios. The SVM classifier is able to generalize from (B) to (C) because the underlying representations of these three modalities are already aligned in A.

Figure 3 The “brain-picture-text” three-modal joint learning framework proposed in this article, referred to as BraVL.
In addition, brain signals change from trial to trial, even for the same visual stimulus. To improve the stability of neural decoding, the authors used a stability selection method to process fMRI data. The stability scores of all voxels are shown in Figure 4 below. The author selected the top 15% of voxels with the best stability to participate in the neural decoding process. This operation can effectively reduce the dimensionality of fMRI data and suppress interference caused by noisy voxels without seriously affecting the discriminative ability of brain features.

Figure 4. Voxel activity stability score map of the visual cortex of the brain.
# Existing neural encoding and decoding data sets often only have image stimuli and brain responses. In order to obtain the linguistic description corresponding to the visual concept, the author adopted a semi-automatic Wikipedia article extraction method. Specifically, the authors first create automatic matching of ImageNet classes and their corresponding Wikipedia pages. The matching is based on the similarity between the ImageNet class and the synset word of the Wikipedia title. and their parent categories. As shown in Figure 5 below, unfortunately, this kind of matching can occasionally produce false positives because similarly named classes may represent very different concepts. When constructing the trimodal dataset, in order to ensure high-quality matching between visual features and linguistic features, the authors manually deleted unmatched articles.
Figure 5. Semi-automatic visual concept description acquisition
Experimental results
The author is in multiple Extensive zero-shot neural decoding experiments were conducted on the "Brain-Image-Text" three-modal matching data set. The experimental results are shown in the table below. As can be seen, models using a combination of visual and textual features (V&T) perform much better than models using either of them alone. Notably, BraVL based on V&T features significantly improves the average top-5 accuracy on both datasets. These results suggest that, although the stimuli presented to subjects contain only visual information, it is conceivable that subjects subconsciously invoke appropriate linguistic representations, thereby affecting visual processing.
For each visual concept category, the authors also show the neural decoding accuracy gain after adding text features, as shown in Figure 6 below. It can be seen that for most test classes, the addition of text features has a positive impact, with the average Top-1 decoding accuracy increasing by about 6%.
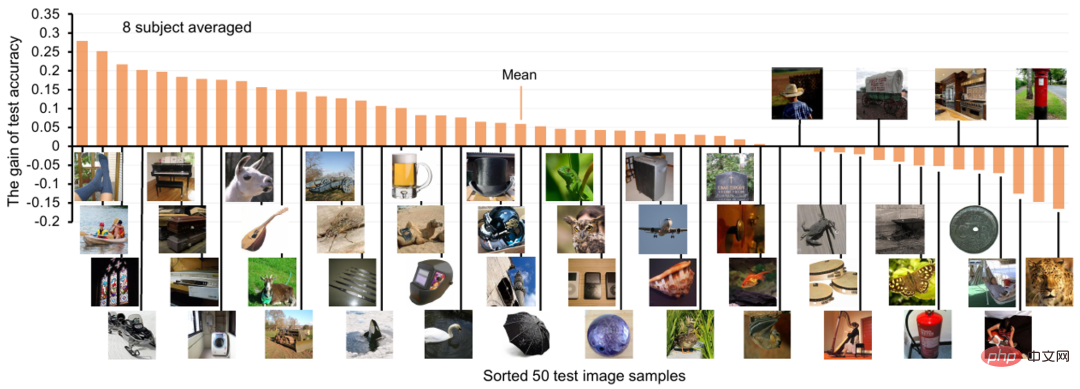
Figure 6. Neural decoding accuracy gain after adding text features
In addition to the neural decoding analysis, the authors also analyzed the contribution of text features in voxel-level neural encoding (predicting the corresponding brain based on visual or text features Voxel activity), the results are shown in Figure 7. It can be seen that for most high-level visual cortex (HVC, such as FFA, LOC and IT), fusing text features on the basis of visual features can improve the prediction accuracy of brain activity, while for most low-level visual cortex (LVC, such as V1, V2 and V3), fusing text features is not beneficial or even harmful.
From the perspective of cognitive neuroscience, our results are reasonable, because it is generally believed that HVC is responsible for processing higher-level semantic information such as category information and motion information of objects. LVC is responsible for processing low-level information such as direction and outline. In addition, a recent neuroscientific study found that visual and linguistic semantic representations are aligned at the boundary of the human visual cortex (i.e., the "semantic alignment hypothesis")[10], and the author's experimental results also support this hypothesis
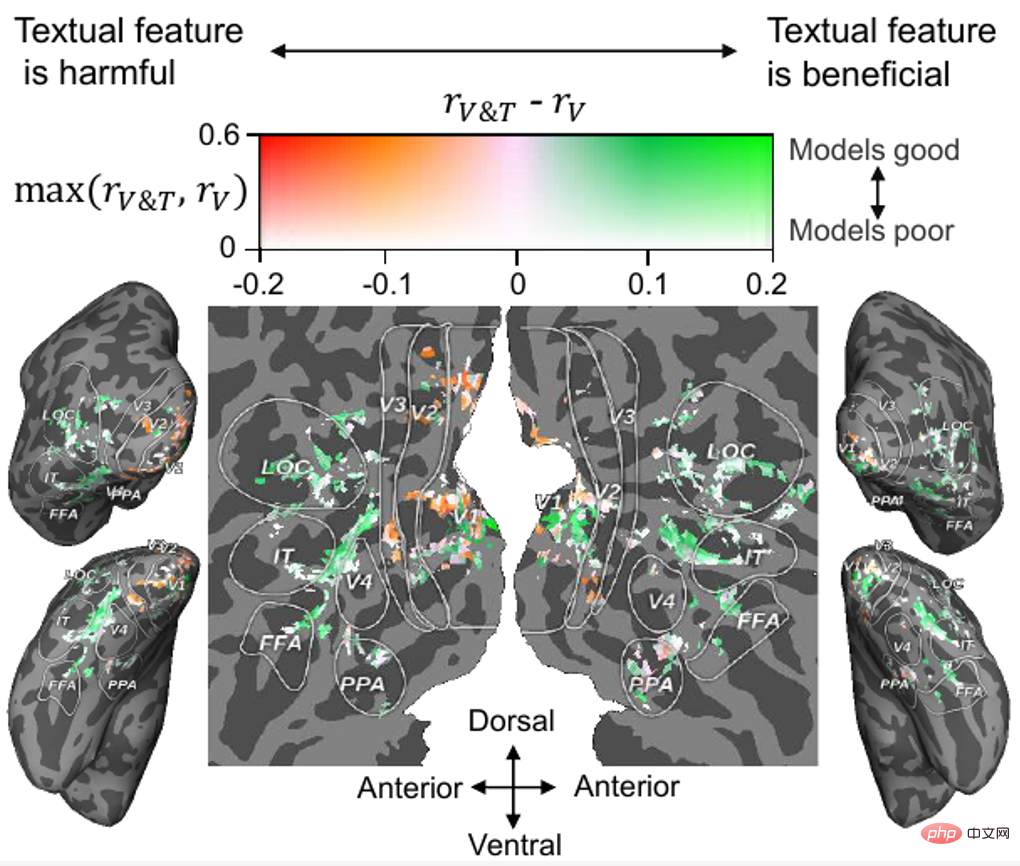
Figure 7. Projection of text feature contributions to visual cortex
For more experimental results, please see the original text.
Overall, this paper draws some interesting conclusions and cognitive insights: 1) Decoding new visual categories from human brain activity is achievable with high accuracy; 2) Decoding models using a combination of visual and linguistic features perform much better than decoding models using either alone; 3) Visual perception may be accompanied by linguistic influences to represent the semantics of visual stimuli; 4) Using natural Language as a concept description has higher neural decoding performance than using class names; 5) Additional data in both unimodality and bimodality can significantly improve decoding accuracy.
Discussion and Outlook
Du Changde, the first author of the paper and a special research assistant at the Institute of Automation, Chinese Academy of Sciences, said: "This work confirms that brain activity, visual images and text The features extracted in the description are effective for decoding neural signals. However, the extracted visual features may not accurately reflect all stages of human visual processing, and better feature sets would be helpful in the completion of these tasks. For example, larger Pre-trained language models (such as GPT-3) are used to extract text features that are more capable of zero-shot generalization. In addition, although Wikipedia articles contain rich visual information, this information is easily obscured by a large number of non-visual sentences. .This problem can be solved by visual sentence extraction or collecting more accurate and rich visual descriptions using models such as ChatGPT and GPT-4. Finally, compared with related studies, although this study used relatively more tri-modal data, Larger and more diverse data sets would be more beneficial. We leave these aspects to future research."
The corresponding author of the paper, researcher He Huiguang of the Institute of Automation, Chinese Academy of Sciences, pointed out: "The method proposed in this article has three potential applications: 1) As a neural semantic decoding tool, this method will be used in a new type of reading semantic information of the human brain. Play an important role in the development of neuroprosthetic devices. Although this application is not yet mature, the method in this article provides a technical foundation for it. 2) By inferring brain activity across modalities, the method in this article can also be used as a neural coding tool, using It is used to study how visual and language features are expressed on the human cerebral cortex, revealing which brain areas have multimodal properties (i.e., are sensitive to visual and language features). 3) The neural decodability of the internal representation of the AI model can be regarded as the model Brain-like level indicators. Therefore, the method in this paper can also be used as a brain-like property evaluation tool to test which model's (visual or language) representation is closer to human brain activity, thus motivating researchers to design more brain-like computing models. 》
Neural information encoding and decoding is a core issue in the field of brain-computer interface. It is also an effective way to explore the principles behind the complex functions of the human brain and promote the development of brain-like intelligence. The neural computing and brain-computer interaction research team of the Institute of Automation has been working in this field for many years and has made a series of research works, which were published in TPAMI 2023, TMI2023, TNNLS 2022/2019, TMM 2021, Info. Fusion 2021, AAAI 2020, etc. The preliminary work was reported in the headlines of MIT Technology Review and won the ICME 2019 Best Paper Runner-up Award.
This research was supported by the Science and Technology Innovation 2030-"New Generation of Artificial Intelligence" major project, the National Foundation Project, the Institute of Automation 2035 Project, and the China Artificial Intelligence Society-Huawei MindSpore Academic Award Fund and Intelligence Support for pedestals and other projects.
About the author
First author: Du Changde, special research assistant at the Institute of Automation, Chinese Academy of Sciences, engaged in research on brain cognition and artificial intelligence, in visual neural information He has published more than 40 papers on encoding and decoding, multi-modal neural computing, etc., including TPAMI/TNNLS/AAAI/KDD/ACMMM, etc. He has won the 2019 IEEE ICME Best Paper Runner-up Award and the 2021 Top 100 Chinese AI Rising Stars. He has successively undertaken a number of scientific research tasks for the Ministry of Science and Technology, the National Foundation for Science and Technology, and the Chinese Academy of Sciences, and his research results were reported in the headlines of MIT Technology Review.

##Personal homepage: https://changdedu.github.io/
Corresponding author: He Huiguang, researcher at the Institute of Automation, Chinese Academy of Sciences, doctoral supervisor, post professor at the University of Chinese Academy of Sciences, distinguished professor at Shanghai University of Science and Technology, outstanding member of the Youth Promotion Association of the Chinese Academy of Sciences, and winner of the commemorative medal for the 70th anniversary of the founding of the People's Republic of China. He has successively undertaken 7 National Natural Fund projects (including key fund and international cooperation projects), 2 863 projects, and national key research plan projects. He has won two second-class National Science and Technology Progress Awards (ranked second and third respectively), two Beijing Science and Technology Progress Awards, the first-class Science and Technology Progress Award of the Ministry of Education, the first Outstanding Doctoral Thesis Award of the Chinese Academy of Sciences, Beijing Science and Technology Rising Star, and the Chinese Academy of Sciences " Lu Jiaxi Young Talent Award", Fujian Province "Minjiang Scholar" Chair Professor. Its research fields include artificial intelligence, brain-computer interface, medical image analysis, etc. In the past five years, he has published more than 80 articles in journals and conferences such as IEEE TPAMI/TNNLS and ICML. He is an editorial board member of IEEEE TCDS, Journal of Automation and other journals, a distinguished member of CCF, and a distinguished member of CSIG.

The above is the detailed content of The non-invasive multi-modal learning model developed by the Institute of Automation realizes brain signal decoding and semantic analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Time Series Forecasting NLP Large Model New Work: Automatically Generate Implicit Prompts for Time Series Forecasting
Mar 18, 2024 am 09:20 AM
Time Series Forecasting NLP Large Model New Work: Automatically Generate Implicit Prompts for Time Series Forecasting
Mar 18, 2024 am 09:20 AM
Today I would like to share a recent research work from the University of Connecticut that proposes a method to align time series data with large natural language processing (NLP) models on the latent space to improve the performance of time series forecasting. The key to this method is to use latent spatial hints (prompts) to enhance the accuracy of time series predictions. Paper title: S2IP-LLM: SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Download address: https://arxiv.org/pdf/2403.05798v1.pdf 1. Large problem background model
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
