
 Technology peripherals
AI
ChatGPT: the fusion of powerful models, attention mechanisms and reinforcement learning
Technology peripherals
AI
ChatGPT: the fusion of powerful models, attention mechanisms and reinforcement learning
ChatGPT: the fusion of powerful models, attention mechanisms and reinforcement learning

This article mainly introduces the machine learning model that powers ChatGPT. It will start with the introduction of large language models, delve into the revolutionary self-attention mechanism that enables GPT-3 to be trained, and then delve into reinforcement learning from human feedback. is the new technology that makes ChatGPT outstanding.
Large Language Model
ChatGPT is a type of machine learning natural language processing model for inference, called a large language model (LLM). LLM digests large amounts of text data and infers relationships between words in the text. Over the past few years, these models have continued to evolve as computing power has advanced. As the size of the input data set and parameter space increases, the capabilities of LLM also increase.
The most basic training of a language model involves predicting a word in a sequence of words. Most commonly, this is observed for next token prediction and masking language models.
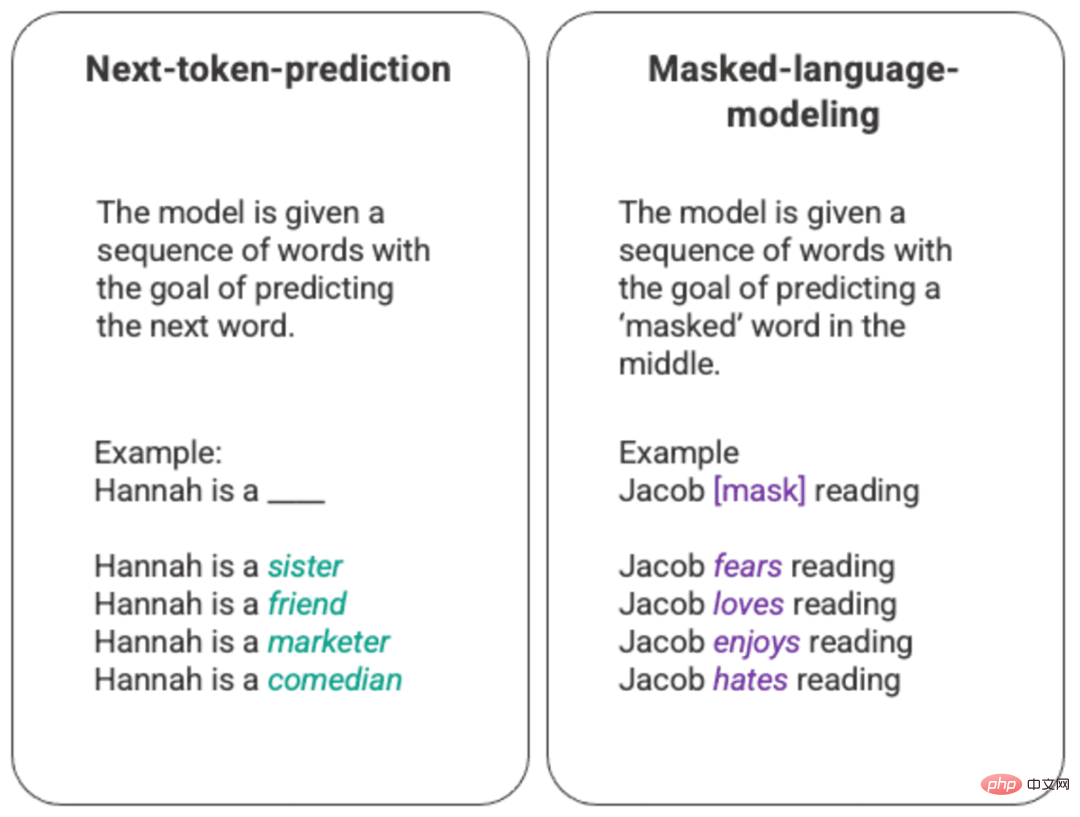
Generated next token prediction and arbitrary example of masked language model
In this basic ranking technique, usually through long short memory (LSTM) ) model, which fills in the gaps with the statistically most likely words given the environment and context. This sequential modeling structure has two main limitations.
- The model cannot give more weight to some surrounding words than others. In the example above, while "reading" may be most commonly associated with "hate", in the database "Jacob" is probably an avid reader and the model should value "Jacob" more than "Jacob" Read” and choose “love” over “hate”.
- Input data are processed individually and sequentially, rather than as a whole corpus. This means that when training an LSTM, the window of context is fixed and only extends beyond a single input for a few steps in the sequence. This limits the complexity of the relationships between words and the meanings that can be drawn.
To deal with this problem, in 2017, a team at Google Brain introduced converters. Unlike LSTM, the transformer can process all input data simultaneously. Using a self-attention mechanism, the model can assign different weights to different parts of the input data relative to any position in the language sequence. This feature enables large-scale improvements in injecting meaning into LLM and the ability to handle larger data sets.
GPT and Self-Attention
The Generative Pretrained Transformer (GPT) model was first launched by OpenAI in 2018 and is called GPT -1. These models continued to evolve in GPT-2 in 2019, GPT-3 in 2020, and most recently, InstructGPT and ChatGPT in 2022. Before incorporating human feedback into the system, the biggest advances in GPT model evolution were driven by achievements in computational efficiency, which allowed GPT-3 to train on significantly more data than GPT-2, giving it a greater Diverse knowledge base and ability to perform a wider range of tasks.

Comparison of GPT-2 (left) and GPT-3 (right).
All GPT models utilize a transformer structure, which means they have an encoder to process the input sequence and a decoder to generate the output sequence. Both the encoder and decoder feature multi-headed self-attention mechanisms, allowing the model to weight various parts of the sequence differently to infer meaning and context. Additionally, the encoder utilizes masked language models to understand the relationships between words and produce more understandable responses.
The self-attention mechanism that drives GPT works by converting a token (a text fragment, which can be a word, a sentence, or other text grouping) into a vector that represents the importance of the token in the input sequence. . To do this, this model:
- 1. Create a
query,key, andvaluevector for each token in the input sequence. - 2. Calculate the similarity between the
queryvector in step 1 and thekeyvector of each other tag by taking the dot product of the two vectors. - 3. Generate normalized weights by inputting the output of step 2 into a
softmaxfunction. - 4. By multiplying the weight produced in step 3 with the
valuevector of each token, a final vector is produced that represents the importance of the token in the sequence.
The "multi-head" attention mechanism used by GPT is an evolution of self-attention. Instead of executing steps 1-4 all at once, the model iterates this mechanism multiple times in parallel, each time generating a new query, key, and valueLinear projection of vector. By extending self-attention in this way, the model is able to grasp sub-meanings and more complex relationships in the input data.

Screenshot generated from ChatGPT.
Although GPT-3 introduces significant advances in natural language processing, it is limited in its ability to align with user intent. For example, GPT-3 might produce the following output:
- are not helpful, meaning they do not follow explicit instructions from the user.
- Contains hallucinations that reflect non-existent or incorrect facts.
- Lack of interpretability makes it difficult for humans to understand how the model arrived at a specific decision or prediction.
- Contains harmful or offensive content and harmful or biased content that spreads misinformation.
Innovative training methods are introduced in ChatGPT to offset some of the inherent problems of standard LLM.
ChatGPT
ChatGPT is a derivative of InstructGPT that introduces a novel method of incorporating human feedback into the training process to make the model The output is better integrated with the user's intent. Reinforcement learning from human feedback (RLHF) is described in depth in openAI's 2022 paper "Training language models to follow instructions with human feedback" and is briefly explained below.
Step 1: Supervised Fine-Tuning (SFT) Model
The first development involved fine-tuning the GPT-3 model, employing 40 contractors to create a supervised training dataset where the input has a known output for the model to learn from. Input or prompts are collected from actual user input to the open API. The tagger then writes appropriate responses to the prompts, creating a known output for each input. The GPT-3 model is then fine-tuned using this new, supervised dataset to create GPT-3.5, also known as the SFT model.
To maximize the diversity of the prompts dataset, only 200 prompts can come from any given user ID, and any prompts sharing long common prefixes are removed. Finally, all tips containing personally identifiable information (PII) were removed.
After aggregating the prompt information from the OpenAI API, labelers were also asked to create prompt information samples to fill those categories with very few real sample data. Categories of interest include:
- General Tips:Any random inquiries.
- Minor tips: Instructions containing multiple query/answer pairs.
- User-based prompts: Correspond to the specific use case requested for the OpenAI API.
When generating a response, taggers are required to do their best to infer what the user's instructions were. This document describes the three main ways in which prompts can request information.
- Direct: "Tell me about..."
- Few words: Give these two stories example, write another story about the same topic.
- Continuation: Give the beginning of a story and complete it.
A compilation of prompts from the OpenAI API and handwritten prompts from labellers, resulting in 13,000 input/output samples for use in supervised models.
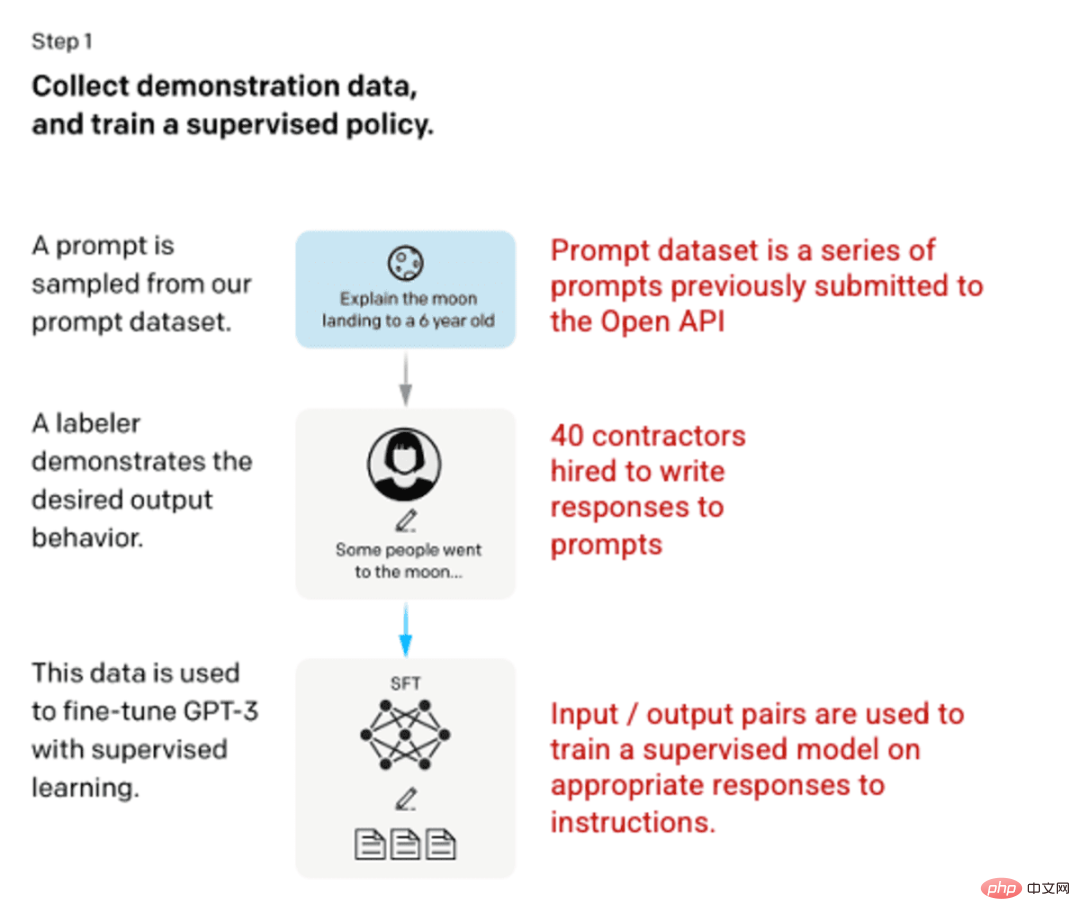
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
Step 2: Reward Model
After training the SFT model in step 1, the model produces better prompts for users , consistent response. The next improvement came in the form of training reward models, where the input to the model is a sequence of cues and responses, and the output is a scaled value called the reward. A reward model is required in order to take advantage of Reinforcement Learning, where the model learns to produce outputs that maximize its reward (see step 3).
To train the reward model, labelers provide 4 to 9 SFT model outputs for a single input prompt. They were asked to rank these outputs from best to worst, creating output-ranked combinations as follows:

Example of response-ranked combinations.
Including each combination in the model as a separate data point leads to overfitting (the inability to infer what is beyond the data seen). To solve this problem, the model is built using each set of rankings as a separate batch of data points.
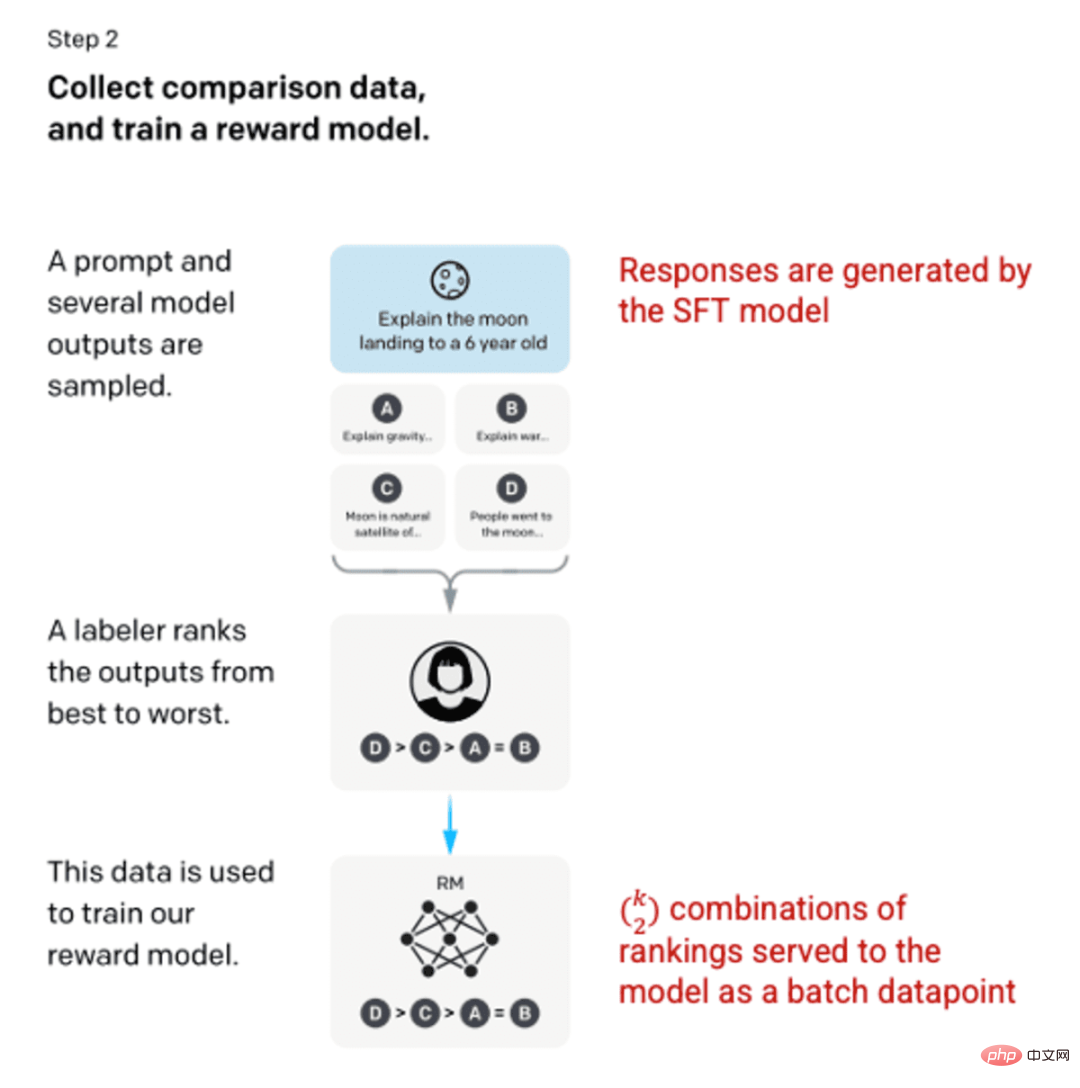
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
Step 3: Reinforcement Learning Model
In the final stage, the model is presented with a random prompt and a response is returned. The response is generated using the "policy" learned by the model in step 2. The policy represents the strategy the machine has learned to use to achieve its goal; in this case, maximizing its reward. Based on the reward model developed in step 2, a scaled reward value is then determined for the cue and response pairs. The rewards are then fed back into the model to develop the strategy.
In 2017, Schulman et al. introduced Proximal Policy Optimization (PPO), a method for updating the model’s policy as each response is generated. PPO incorporates the Kullback-Leibler (KL) penalty in the SFT model. KL divergence measures the similarity of two distribution functions and penalizes extreme distances. In this case, using KL penalty can reduce the distance of the response from the output of the SFT model trained in step 1 to avoid over-optimizing the reward model and deviating too much from the human intent dataset.
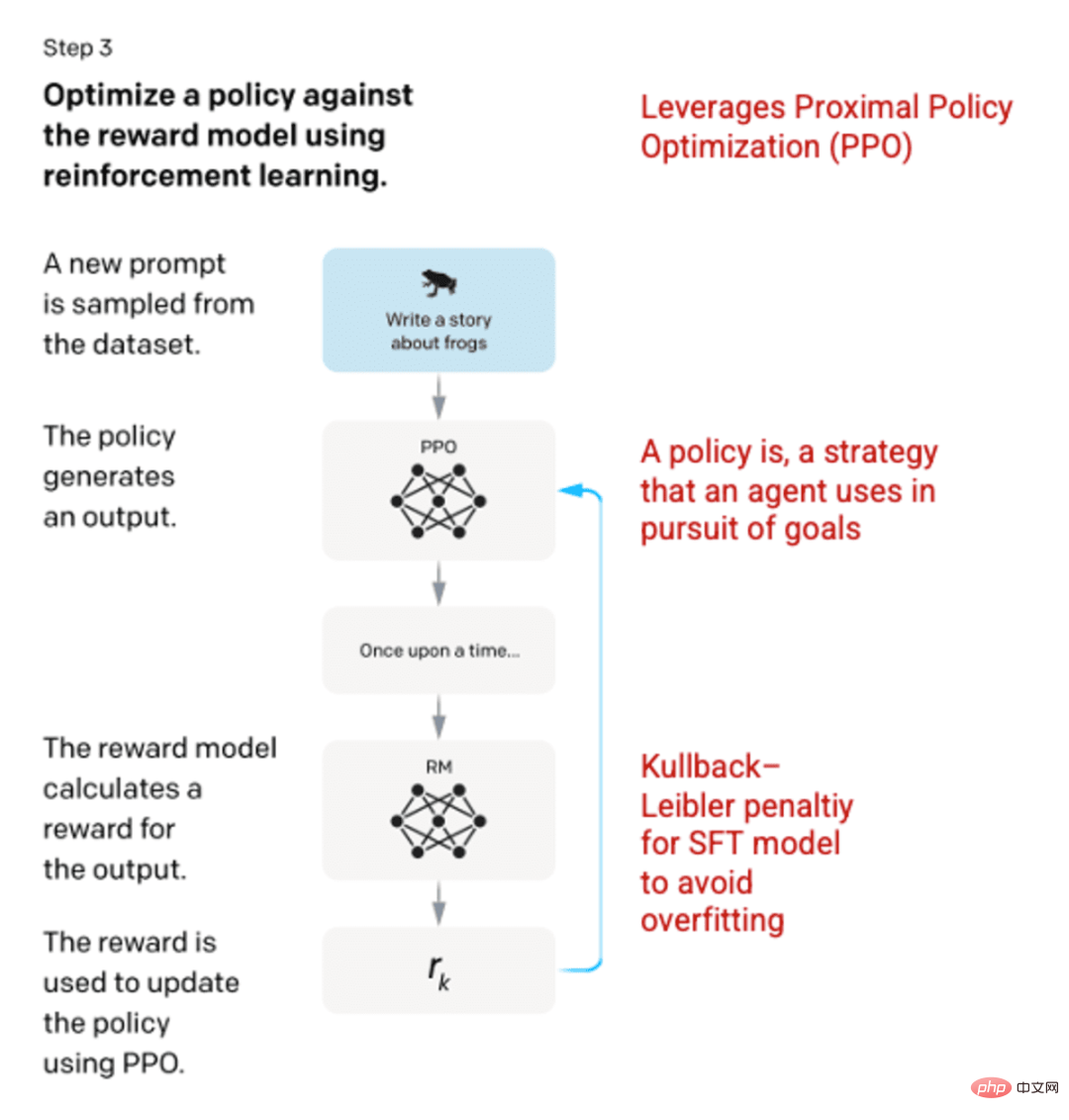
Image (left) inserted from "Training language models to follow instructions with human feedback" OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (Right) Additional context added in red.
Steps 2 and 3 of the process can be iterated over and over again, although this is not yet widely done in practice.

Screenshot generated from ChatGPT.
Evaluation of the model
The evaluation of the model is performed by reserving a test set that the model has not seen during training. On the test set, a series of evaluations are conducted to determine whether the model performs better than its predecessor, GPT-3.
Usefulness: The model’s ability to infer and follow user instructions. Labelers preferred InstructGPT's output to GPT-3 85±3% of the time.
Authenticity: The tendency of the model to hallucinate. When evaluated using the TruthfulQA dataset, the PPO model produces outputs with a small increase in both truthfulness and informativeness.
Harmlessness: A model’s ability to avoid inappropriate, derogatory, and slanderous content. Harmlessness is tested using the RealToxicityPrompts data set. The test was conducted under three conditions.
- Instructions provide respectful responses: Resulting in a significant reduction in harmful reactions.
- Instructions provide reactions without any settings regarding respect: No noticeable change in harmfulness.
- Guidance Provides Harmful Reactions: Reactions are actually significantly more harmful than the GPT-3 model.
For more information on the methods used to create ChatGPT and InstructGPT, please read the original paper "Training language models to follow instructions with human feedback" published by OpenAI, 2022 https://arxiv .org/pdf/2203.02155.pdf.
Screenshot generated from ChatGPT.
The above is the detailed content of ChatGPT: the fusion of powerful models, attention mechanisms and reinforcement learning. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
In the fields of machine learning and data science, model interpretability has always been a focus of researchers and practitioners. With the widespread application of complex models such as deep learning and ensemble methods, understanding the model's decision-making process has become particularly important. Explainable AI|XAI helps build trust and confidence in machine learning models by increasing the transparency of the model. Improving model transparency can be achieved through methods such as the widespread use of multiple complex models, as well as the decision-making processes used to explain the models. These methods include feature importance analysis, model prediction interval estimation, local interpretability algorithms, etc. Feature importance analysis can explain the decision-making process of a model by evaluating the degree of influence of the model on the input features. Model prediction interval estimate
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
 Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
Is Flash Attention stable? Meta and Harvard found that their model weight deviations fluctuated by orders of magnitude
May 30, 2024 pm 01:24 PM
MetaFAIR teamed up with Harvard to provide a new research framework for optimizing the data bias generated when large-scale machine learning is performed. It is known that the training of large language models often takes months and uses hundreds or even thousands of GPUs. Taking the LLaMA270B model as an example, its training requires a total of 1,720,320 GPU hours. Training large models presents unique systemic challenges due to the scale and complexity of these workloads. Recently, many institutions have reported instability in the training process when training SOTA generative AI models. They usually appear in the form of loss spikes. For example, Google's PaLM model experienced up to 20 loss spikes during the training process. Numerical bias is the root cause of this training inaccuracy,
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 Machine Learning in C++: A Guide to Implementing Common Machine Learning Algorithms in C++
Jun 03, 2024 pm 07:33 PM
Machine Learning in C++: A Guide to Implementing Common Machine Learning Algorithms in C++
Jun 03, 2024 pm 07:33 PM
In C++, the implementation of machine learning algorithms includes: Linear regression: used to predict continuous variables. The steps include loading data, calculating weights and biases, updating parameters and prediction. Logistic regression: used to predict discrete variables. The process is similar to linear regression, but uses the sigmoid function for prediction. Support Vector Machine: A powerful classification and regression algorithm that involves computing support vectors and predicting labels.
 SearchGPT: Open AI takes on Google with its own AI search engine
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI takes on Google with its own AI search engine
Jul 30, 2024 am 09:58 AM
Open AI is finally making its foray into search. The San Francisco company has recently announced a new AI tool with search capabilities. First reported by The Information in February this year, the new tool is aptly called SearchGPT and features a c
